Source: Financial Story Collection
Author: Wang Shuran

Image Source: Generated by Wujie AI
Domestic large models collectively submitted their answers.
On August 31, the first batch of 11 domestic large models were approved for launch, including Baidu's "Wenxin Yiyuan," SenseTime's "SenseChat," Zhipu AI's "Zhipu Qingyan," MiniMax's "ABAB," Shanghai Artificial Intelligence Laboratory's Shusheng General Large Model, Douyin's "Yunque," Baichuan Intelligence's "Baichuan," and the Chinese Academy of Sciences' "Zidong Taichu," iFlytek's "Xunfei Xinghuo Cognitive Large Model," Alibaba's "Tongyi Qianwen," and 360 Brain.
Among them, "Wenxin Yiyuan," "SenseChat," and the AI intelligent assistant "Dou Bao" developed by Douyin based on "Yunque," "Zhipu Qingyan," "ABAB" from MiniMax, and "Xunfei Xinghuo Cognitive Large Model" have been open for public testing.
According to First Financial, Alibaba's "Tongyi Qianwen" and 360 Brain are also expected to be open successively in about a week.
Since the "Generative AI" wave led by ChatGPT in February this year, domestic large models have been gearing up. Today, 7 months later, it's time to evaluate the results.
In terms of speed, it is indeed surprising, but what really concerns people is the actual effect.
"Financial Story Collection" has experienced the six large models that have been open for testing from the perspectives of text creation, mathematical calculation, drawing, and information retrieval, and found that these large models can already solve quite a few problems, especially in the aspect of text creation. Of course, there are inevitable flaws, but considering the short period of development, overall it is worth affirming.
It should be noted that the results output by large models have randomness. Even with the same command, the generated content varies each time, so limited experience cannot be used to judge the superiority or inferiority of the model.
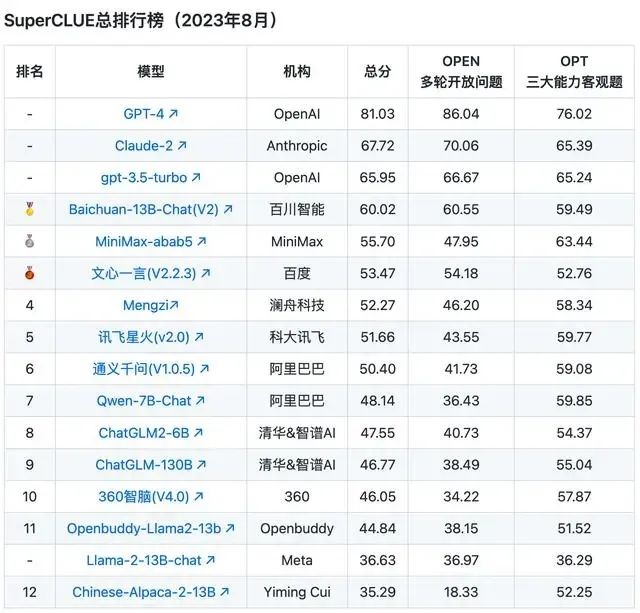
However, the August ranking of large models released by the domestic large model list SuperCLUE can reflect the overall level of these large models. The ranking shows that among domestic large models, Baichuan Intelligence's Baichuan-13B-Chat (V2) took the top spot, followed closely by MiniMax's MiniMax-abab5 and Baidu's Wenxin Yiyuan (V2.2.3).
Text Creation: Quite impressive
Text processing is one of the main directions of these large models, and text-based creation is the highlight, which has always been the hope of liberating productivity.
This experience focused on the ability to write poetry, create titles, brainstorm articles, and polish essays.
First, in terms of writing poetry, these large models generally performed well, and the created poems generally have reasonable semantics and context, rather than just illogical combinations of words.
For example, when the command was "Write a poem containing the keywords 'jianghu,' 'puti,' and 'encounter,'" Wenxin Yiyuan, SenseChat, and MiniMax all performed well, especially mastering the essence of rhyme.

(Left: Wenxin Yiyuan, Middle: SenseChat, Right: MiniMax)
Relatively speaking, Baichuan, Xunfei Xinghuo, Zhipu Qingyan, and Douyin's "Dou Bao" are sometimes not stable in terms of rhyme.

(Left: Xunfei Xinghuo, Right: Zhipu Qingyan)
Second, in terms of creating titles, these large models can also grasp the central idea, although it is not yet realistic to replace human thinking, but they can provide reference.
For example, after inputting the paragraph about "the flow economy and the fake video industry behind the fake short video," Wenxin Yiyuan, Xunfei Xinghuo, Zhipu Qingyan, and Baichuan's results are as follows:

(Top Left: Zhipu Qingyan, Bottom Left: SenseChat, Top Right: Xunfei Xinghuo, Bottom Right: Baichuan)
What is quite surprising is the titles generated by MiniMax, which seem to not only "combine" existing keywords, but also have their own summarization, and some can be used directly: "The repeated ban on fake short videos: revealing the interests and dissemination mechanisms behind it," "The fake short video chaos: the moral dilemma of the 'content is king' era," "Fake short videos: a game to attract attention," "Fake short videos: collusion between platforms, creators, and viewers," "Fake short videos: the distortion of technology and human nature."
It is worth mentioning that during the above experience, Baichuan had a somewhat confusing phenomenon. It seems that it cannot handle "excessive content input" in some cases and will prompt that it cannot answer, and it will only give results after reducing the paragraph. However, when trying another paragraph with more than 1400 words, it can be processed normally, and the reason is unknown.

For example, the above test paragraph had more than 1600 words, and it could only answer after reducing it to more than 1200 words, but when trying another paragraph with more than 1400 words, it could be processed normally, and the reason is unknown.
Third, in terms of polishing articles, the levels of various models are commendable, and it is difficult to distinguish between them.
On the one hand, they can all handle basic issues such as typos, punctuation, and grammar, but the methods of handling them differ.
For example, for the polishing of "From our nature, we are originally delicate and weak," Wenxin Yiyuan will process it into "From our nature, we are originally delicate and weak," while Baichuan, Zhipu Qingyan, and Xunfei Xinghuo tend to handle it more concisely, similar to "We are naturally small and fragile."
However, this processing style is not fixed. For example, for the polishing of "I grew up in the countryside since I was a child, and I love rainy days very much. Every time it rains, I am very excited," Wenxin Yiyuan's processing is more concise, "I grew up in the countryside since I was a child and have a deep love for rainy days"; Xunfei Xinghuo makes simple modifications based on the original expression, "I have been living in the countryside since I was young, and I love rainy days very much. Every time it rains, I am always excited."—It can be seen that AI algorithms have a strong "randomness."
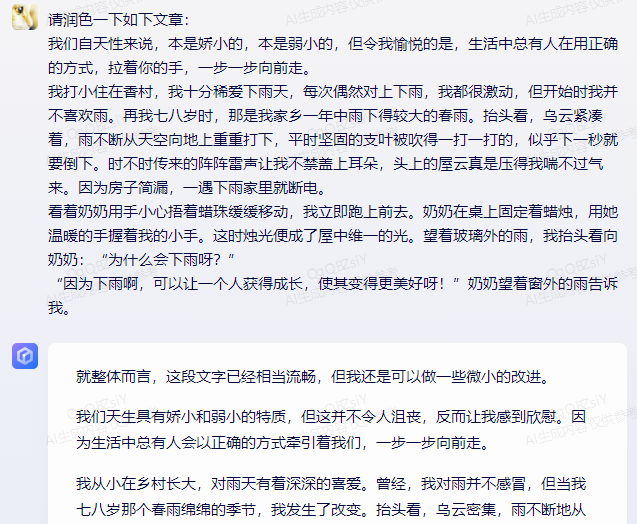
Result from Wenxin Yiyuan
On the other hand, in some semantic understandings, each model's recognition and processing also differ.
Taking the polishing of "Because of the rain, a person can grow and become better!" as an example, Wenxin Yiyuan and Douyin's "Dou Bao" have better processing, both adjusting "rain makes a person grow" to "rain nourishes life or all things," which is obviously more appropriate, while other large models did not make such adjustments.
Fourth, in terms of brainstorming articles, the performance of several large models is quite surprising.
For example, when given the command "Analyze the challenges faced by Zhongxue Gao in entering the low-priced popsicle market," several large models focused on "competition with brands such as Mengniu and Yili," "the impact on the brand image of Zhongxue Gao," and "cost control."
Especially commendable is that Wenxin Yiyuan and Douyin's "Dou Bao" also paid special attention to "the sales channel challenges that Zhongxue Gao will face"—this can completely provide some ideas for the writer.
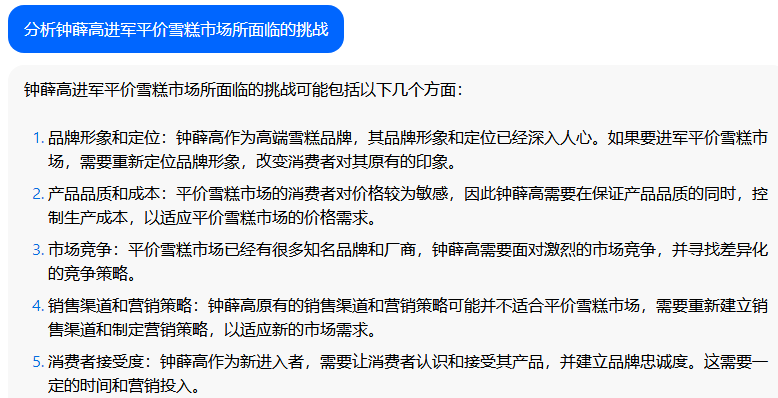
Result from Douyin's "Dou Bao"
However, flaws are inevitable. In the question "Analyze the reasons for Zhongxue Gao's launch of low-priced popsicles," although several large models gave 3-4 analysis angles, some of the angles essentially have the same meaning and all point to "expanding the consumer group and market share," which can be combined.
Taking Wenxin Yiyuan as an example:

This shows that these large models still have a lot of room for improvement in semantic understanding.
In fact, during the experience, there were some quite absurd phenomena in semantic understanding.
For example, in the question "Create a program list for the 2024 Spring Festival Gala that the elderly love to watch," Xunfei Xinghuo, Zhipu Qingyan, Baichuan, SenseChat, and Douyin's "Dou Bao" all included deceased stars such as "Teresa Teng" or "Zhao Lirong."

Result from Xunfei Xinghuo
Another example is in the question "Please write a recipe for 'sauteed ham sausage,'" Zhipu Qingyan, Xunfei Xinghuo, SenseChat, and Douyin's "Dou Bao" all pointed out that the mouse cannot be eaten, while Baichuan was very cooperative and even specifically noted "use abandoned and unused mice," which is quite humorous.

Result from Baichuan
Wenxin Yiyuan is always responsive, and the step of "removing the internal organs of the mouse" is quite amusing.

Result from Wenxin Yiyuan
However, overall, it is worth affirming that these large models can deliver the above results in just 7 months.
Mathematical Calculations: Inconsistent Performance
In answering math questions, "Financial Story Collection" tested 10 junior high school math questions, and the results are as follows: Wenxin Yiyuan, Xunfei Xinghuo, and SenseChat all answered 5 questions correctly, Zhipu Qingyan answered 4 questions correctly, Douyin's "Dou Bao" answered 3 questions correctly, and Baichuan's large model only answered 2 questions correctly.
For example, in the relatively simple question "How many integers are greater than -0.5 and less than 4?" Wenxin Yiyuan and SenseChat answered correctly with 4, while the others were incorrect.
Furthermore, Zhipu Qingyan made multiple mistakes, listing 5 numbers but stating it as 7.
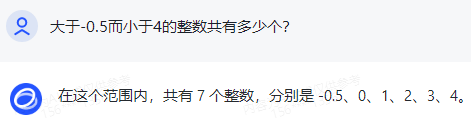
Zhipu Qingyan's result
In answering physics questions and explaining physical phenomena, these large models generally had no problems. "Financial Story Collection" sampled 10 junior high school physics explanation questions, and they were able to answer 9-10 questions correctly.
For example, in the question "Why does the depth of the pool water look shallower than it actually is?" they all correctly answered "principle of refraction."
This may be because the explanation of physical phenomena is more related to text retrieval and summarization, which is essentially text processing, and this aligns with the main direction of the large models.
However, some absurd explanations are inevitable at this stage.
For example, in the question "When a doctor examines a patient, they often burn a small mirror on an alcohol lamp and then place it in the patient's mouth. Why?" Baichuan's large model gave multiple incorrect answers, including the strange explanation that "the mirror will adsorb saliva, and saliva contains rich minerals, which has an auxiliary effect in treating certain diseases."
In terms of physics calculations, these large models generally performed poorly.
In 10 junior high school physics test questions involving different types of physics movements, mass and density, pressure, and electricity, SenseChat's large model performed the best, answering 4 questions correctly, while Wenxin Yiyuan, Baichuan's large model, and Douyin's "Dou Bao" answered 2 questions correctly, and Xunfei Xinghuo and Zhipu Qingyan only answered 1 question correctly.
For example, in the question "If two students pull a force gauge in opposite directions with a force of 200 newtons each, what is the reading on the force gauge?" The answer is 200 newtons, and only SenseChat's large model answered correctly, with the correct solution. Wenxin Yiyuan, Xunfei Xinghuo, Baichuan's large model, and Zhipu Qingyan all gave the answer as 0, while Douyin's "Dou Bao" thought it was 400 newtons.
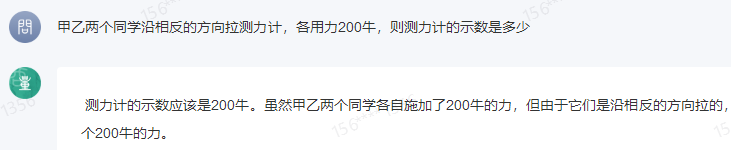
SenseChat's large model result
Similarly, in the question "A student measured the diameter of a steel ball with a ruler and obtained four results: 1.82CM, 1.87CM, 1.68CM, 1.81CM. What should be the diameter of the small ball?" only SenseChat's large model answered correctly with 1.83CM. Wenxin Yiyuan, Baichuan's large model, and Xunfei Xinghuo all answered 1.79CM, Douyin's "Dou Bao" answered 1.825CM, and Zhipu Qingyan's solution was correct, but the final result was calculated incorrectly as 1.82CM.

Zhipu Qingyan's result
However, it should be noted that the results of mathematical calculations by the large models are still inconsistent.
For example, in the diameter question mentioned above, Zhipu Qingyan's first result was the incorrect 1.82CM, but when asked again, it gave the correct answer of 1.83CM. In the force gauge question mentioned above, Xunfei Xinghuo's first answer was the incorrect 0, but when asked again, it answered incorrectly as 400 newtons.
Overall, these large models' performance on math questions with standard answers is not satisfactory.
Drawing Skills: Subpar, High Probability of "Stepping on a Landmine"
Among the 6 large models, only Wenxin Yiyuan and Xunfei Xinghuo currently support drawing.
However, the drawing abilities of these two large models have not yet reached an ideal state, and there is a high probability of "stepping on a landmine."
First, some of the drawings look somewhat "fake" and not realistic enough.
For example, the depictions of "horses" and "scenery" by Wenxin Yiyuan are as follows.

Xunfei Xinghuo's landscape painting is better in terms of artistic conception, but the depiction of the horse is somewhat unrealistic, similar to Wenxin Yiyuan's style.

Second, they still lack understanding of semantics.
For example, in the command "Please draw a painting of Li Qingzhao and Su Shi playing chess," Wenxin Yiyuan's painting only shows one person.
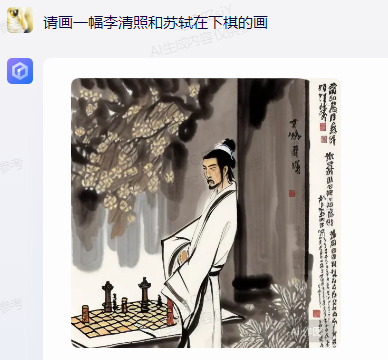
It only added the second person after being prompted, but the position of "Li Qingzhao" playing chess is clearly incorrect.
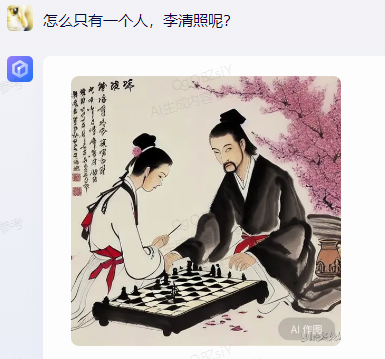
As for Xunfei Xinghuo, although it showed two people, both were male and did not meet the requirements.

After being prompted, it was unable to generate the image again, and this was the case after multiple attempts.

For example, in the command "Draw a bowl of bullfrog noodles," Xunfei Xinghuo's drawing was quite absurd—there is a whole bullfrog in the noodles.

(Left: Wenxin Yiyuan, Right: Xunfei Xinghuo)
Similarly, in the command "Draw a Russian Blue cat sleeping," Xunfei Xinghuo interpreted the Russian Blue cat as a blue-colored cat, while Wenxin Yiyuan, although understanding it correctly, misunderstood the sleeping part.

(Left: Wenxin Yiyuan, Right: Xunfei Xinghuo)
Third, there are still many problems in the depiction of facial and other details by the large models.
For example, the people drawn by Wenxin Yiyuan sometimes have "strabismus" in their eyes, or their faces, hands, and feet are "blurry."

Xunfei Xinghuo also has similar issues, such as the somewhat deformed and eerie feeling of the "shepherd boy's" face in the image below.
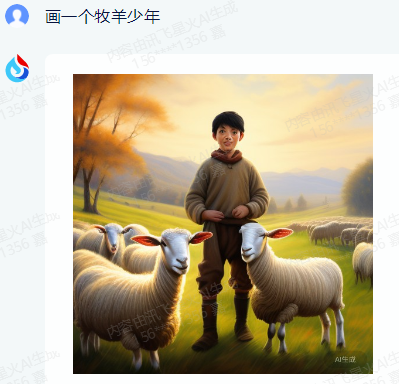
Attempting to guide it to optimize, the result was an even more "disastrous" image:

Of course, there are also some positive aspects. In scenes where too many details are not needed, the works can still be "appreciated."
For example, the landscape paintings provided by the two large models below.

(Left: Wenxin Yiyuan, Right: Xunfei Xinghuo)
Overall, compared to their text abilities, the drawing skills of the large models need more "training." In this process, continuous optimization at the algorithm and data levels is needed, as well as adaptation with human guidance at the command level to fully tap into their potential.
As Baidu's Li Yanhong said, in the future, asking questions is more important than solving problems, and in 10 years, 50% of the world's work may be prompting engineering.
Information Retrieval: Accuracy Needs Improvement
If the large models are used as search tools, they need to reach a satisfactory level in terms of the timeliness, comprehensiveness, and accuracy of information.
The experience found that in some search scenarios, these large models can provide accurate information.
For example, in trap questions such as "Why did Cao Cao marry Lin Daiyu?" and "Why did Zhang Sanfeng kill Zhang Wuji?" and "Why do peanuts grow on trees?" each large model was able to accurately state that these phenomena do not exist.
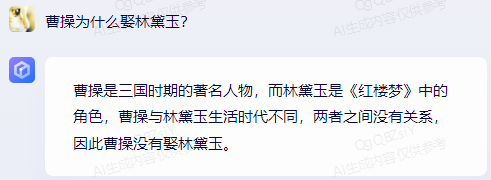
Wenxin Yiyuan's result
Similarly, for specific questions such as "Who proposed the New Three Principles of the People?" and "When was the Battle of Songhu?" and "Who first cultivated hybrid rice?" these large models were also able to answer correctly.
However, in some data statistics aspects, their performance is not ideal.
On the one hand, some large models lack the latest data or lack data reserves in certain specific fields.
For example, when it comes to the annual population growth in China, Wenxin Yiyuan and Xunfei Xinghuo can provide data up to 2022, but Zhipu Qingyan can only retrieve data up to 2020, Baichuan's large model and Douyin's "Dou Bao" can only retrieve data up to 2021, and SenseChat's large model cannot retrieve this type of data at all.
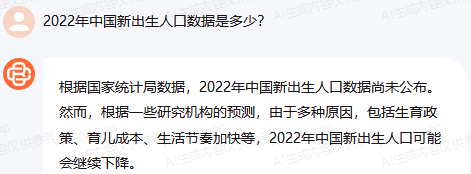
Baichuan's large model result
Similarly, when it comes to the annual GDP of China, Baichuan's large model can only provide data up to 2021, and SenseChat's large model cannot provide any data at all.
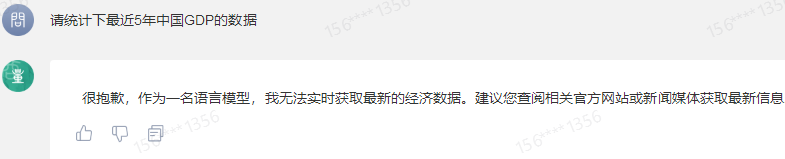
SenseChat's large model result
Furthermore, in some queries related to offline store information, MiniMax's large model, Zhipu Qingyan, Baichuan's large model, and Douyin's "Dou Bao" indicate that they are unable to retrieve the information.
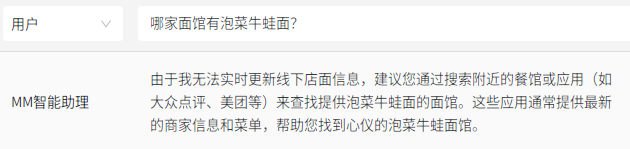
Additionally, some historical information is missing from some of the large models. For example, when asked "When did China successfully detonate its first hydrogen bomb?" both Zhipu Qingyan and Baichuan's large model indicated that they were unable to retrieve the information.
On the other hand, the accuracy of the data is generally lacking.
For example, in the question "Please provide the recent 5 years of China's GDP data," none of the models provided completely accurate data based on the data from the National Bureau of Statistics. Wenxin Yiyuan only had incorrect data for 2021, showing 114.37 billion, while the National Bureau of Statistics reported 114.92 billion.
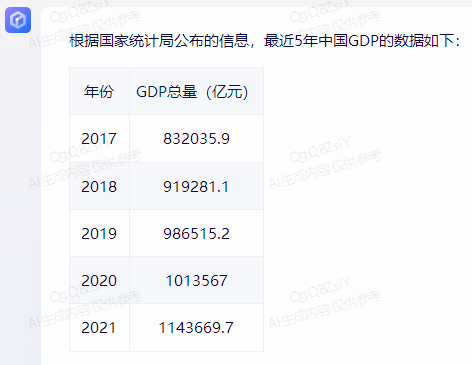
After being prompted and asked again, it made a correction:
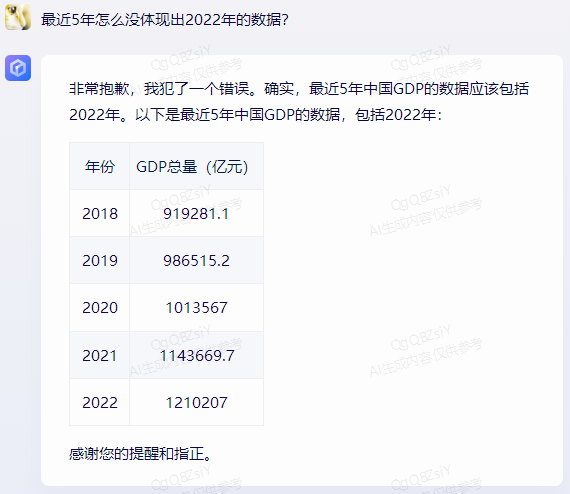
Baichuan's large model, Xunfei Xinghuo, and Douyin's "Dou Bao" provided incorrect data for each year. MiniMax's large model had inconsistent data for 2021 and 2022, while Zhipu Qingyan only had correct data for 2020.
Additionally, among these models, only MiniMax included "2022" in the recent 5 years, while the others defaulted to showing data up to 2021.

MiniMax's result
In fact, the problem of poor accuracy is not limited to data statistics.
For example, in the trap question "Why did Lu Zhishen fight the White Bone Demon three times," only Wenxin Yiyuan, SenseChat's large model, and Douyin's "Dou Bao" correctly stated that it did not exist, while the other models started "making up stories."
Similarly, when asked about the allusion "When parents love their children, they plan for their future," only Wenxin Yiyuan, SenseChat's large model, and Douyin's "Dou Bao" answered correctly. Baichuan's large model believed there was no specific allusion, Xunfei Xinghuo provided the wrong source, and Zhipu Qingyan also got the source wrong.

Douyin's "Dou Bao" result
Furthermore, similar issues arose when querying movie information. In the question "Write a review for the movie 'The Disappearance of Her,' produced by Chen Sicheng," only Wenxin Yiyuan, SenseChat's large model, and Douyin's "Dou Bao" provided descriptions that matched the movie. Baichuan's large model, Xunfei Xinghuo, and Zhipu Qingyan mentioned an actor, Huang Bo, who did not participate in the movie.

Baichuan's large model result
Similar issues arose when evaluating the latest movie "Feng Shen," with only Wenxin Yiyuan providing a correct description of the plot, while the other models mistook it for the previous movie "The Legend of the Condor Heroes." When the command was more specific, such as "The first part of 'Feng Shen: The Rise of Chao Ge' released in 2023," Baichuan's large model, SenseChat's large model, and Xunfei Xinghuo still provided incorrect information, while Zhipu Qingyan and Douyin's "Dou Bao" made corrections.
It can be seen that at the current stage, using the large models for search still leaves much to be desired.
In addition to the four categories of abilities mentioned above, these large models also have cross-language processing capabilities. For example, "I love you" was used as a simple example to test translation between Chinese and French, German, and other languages, and accurate responses were obtained. However, more complex cross-language processing capabilities still need to be further explored.
In conclusion, based solely on the above experience results, the current large models have basically passed the minimum standard in text creation and can still "create" some surprises in certain scenarios, which is quite rare. However, they also resemble a student who excels in some subjects but performs poorly in others, with generally average performance in mathematical and physical aspects and a high probability of errors. Their drawing skills need to be improved, and their information retrieval capabilities are still unstable, making them less reliable to use.
So the question is, in comparison to the current reality, and looking back at the viewpoints that once "glorified" the large models as "the iPhone moment of AI" and "the large models will change the world," is the future constructed by these viewpoints still worth looking forward to?
The answer is undoubtedly yes, "do not underestimate the young and poor"! The answers delivered by the large models today are just the starting point on their long journey. In the days and even hours to come, the large models may be in an endless process of evolution.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







