Source: Leiphone
Author: Huang Nan

In the past few years, there has been a significant change in the parameters of AI models. You Yang pointed out that from January 2016 to January 2021, the parameter volume of AI models increased by 40 times every 18 months; from January 2018 to January 2021, the parameter volume of large AI language models increased by 340 times every 18 months. In comparison, the growth of GPU memory from January 2016 to January 2021 was only 1.7 times every 18 months.
It can be seen that high training costs and long cycles are the most difficult challenges for the development of large models at present.
In response to this issue, You Yang proposed the Colossal-AI system, starting from three levels of efficient memory systems, N-dimensional parallel systems, and large-scale optimization, to minimize data movement under the same device conditions and maximize GPU throughput.
You Yang also pointed out that the current model parameter volume has increased by 100,000 times, but the number of layers has not increased much, which may mean that the current development of AI is no longer in the era of deep learning, but has entered the era of wide learning. In the case of models becoming wider, facing large-scale, long-term GPU training tasks, the core of large model training systems will be how to achieve GPU parallel computing to train large models faster and more cost-effectively.
The following is the content of You Yang's on-site speech, which has been edited and organized by Leiphone without changing the original meaning:
Opportunities and Challenges of Large AI Models
First, show a picture. The horizontal axis of the graph is time, and the vertical axis is the parameter volume of AI models.
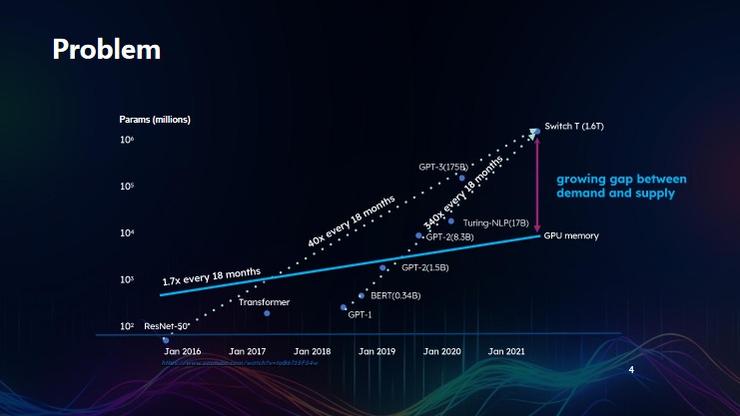
From January 2016 to January 2021, the parameter volume of large AI models increased by approximately 40 times every 18 months; from January 2018 to January 2021, the parameter volume of AI models increased by 340 times every 18 months.
In 2016, the best model at that time was ResNet-50, and today the best model is GPT-4. From an architectural point of view, although OpenAI has not publicly disclosed the architecture of GPT-4, comparing the 50-layer neural network of ResNet-50 with the architecture of GPT-3, which has less than 100 layers, it can be said that the number of layers of AI models has not changed much in recent years.
From ResNet-50 to GPT-4, although the parameter volume has increased by about 100,000 times, each layer has actually become wider. This includes the LLaMA-65B version, which is also a network with several tens of layers.
So it is possible that we are not in the era of deep learning, but have entered an era of wide learning.
It can be seen that since 2019, the Transformer architecture has basically unified the track of large AI models, and the most efficient large AI models currently use the Transformer architecture. The two dashed lines in the graph not only show the trend of changes in the parameter volume of large models, but also reflect the trend of changes in GPU.
Although NVIDIA's stock price has risen many times now, the growth rate of GPU memory, including that of NVIDIA, is far behind the development speed of large models.
Compared with the change in the growth rate of model parameter volume over the past six years, from January 2016 to January 2021, the computing growth rate of NVIDIA GPUs has only increased by 1.7 times every 18 months.
Taking the A100 80G as an example to calculate the memory required for training GPT-3, GPT-3 has approximately 175 billion parameters, rounded to 200 billion for ease of calculation, which is equal to 200 multiplied by 10 to the power of 9. Each single precision occupies 4 bytes, so only the parameters require 800G of memory, and the gradients also occupy 800G of memory. According to the current optimization methods, storing first and second moments and other information all require 800G. In other words, to train a large model that does nothing, it would require at least several terabytes of memory. The 80G memory of a single A100 GPU is far from enough, and the memory overhead also increases with the batch size of intermediate results.
This is also why from the perspective of memory, training large models first requires thousands of GPUs.

Let's take a quantifiable example. PaLM is a large model with 540 billion parameters. According to the current cloud computing market price, training PaLM requires at least 1000 GPUs, with a cost of over 9 million US dollars. Meta has previously stated that LLaMA requires the use of 2000 A100 GPUs and takes three weeks to complete one training session. Based on this calculation, the cost of a single training session for LLaMA is around 5 million US dollars.
However, because training large models is not limited to a single training session, a good large model product may require at least five or six iterations, with the early stages being trial and error. Therefore, according to public channel analysis, the cost of a single training session for GPT-4 is around 60 million US dollars, and it takes at least several months to complete one training session. This is also why even though ChatGPT has been upgraded to the latest version, its underlying model is still the version from September 2021. In other words, from September 2021 to the present, OpenAI has not actually upgraded its product, and the fundamental reason is that the cost of each training session for the model is very high, and the training cycle is very long, so the cost of training large models is very serious.
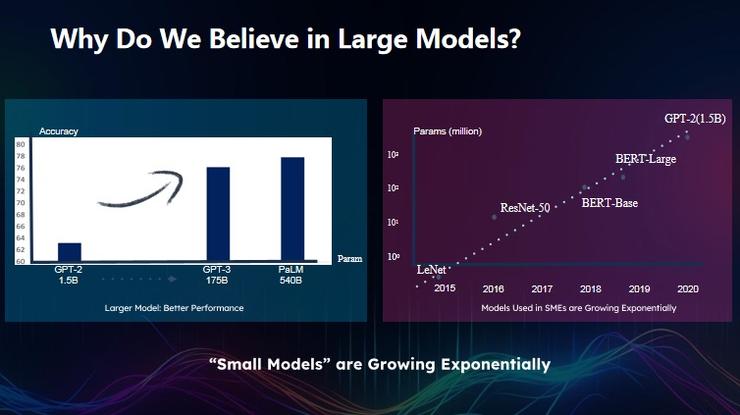
Imagine a scenario: today, we have a large model with 1 trillion parameters and another with 100 billion parameters. Can we use any method to determine which is more effective, the model with 1 trillion parameters or the one with 100 billion parameters? In other words, how much should the model parameter volume increase to achieve better results?
As of today, I think this question cannot be scientifically answered for the time being. There are several reasons for this.
First, training neural networks involves the problem of non-convex optimization. The points where the current training converges are mostly local optima, not global optima. Therefore, it is currently impossible to verify to what extent a neural network has been trained given the existing computational resources.
The second difficulty lies in the fact that large models are often trained for only one or two epochs. In previous CNN models, ResNet was trained for 90 epochs, and even self-supervised learning was trained for 1000 epochs. Therefore, training large models for only one or two epochs is equivalent to passing the dataset only once or twice, and the convergence is even more insufficient. Therefore, in the case of such high training costs, it is difficult for us to verify which is better between a model with 1 trillion parameters and a model with 2 trillion parameters, because their potential has not been fully realized through experiments. Therefore, I believe that today, large AI models are an experimental discipline, and how to efficiently improve the efficiency of this experiment and reduce costs plays a fundamental role in the popularization of the entire industry.
Returning to reality, why is everyone pursuing large models today? From a mathematical logic perspective, the larger the model parameters, the better the performance, this is absolute.
At the same time, costs are also soaring. Currently, training large models requires hundreds, thousands, or even tens of thousands of GPUs. The challenge is how to further reduce the cost of tens of thousands of GPUs.
Twenty years ago, because it relied on the main frequency, all programs were serial. Assuming that the hardware speed is increased by 10 times, without changing a single line of code, the running speed can also be increased by 10 times. But today, if you want to increase the code speed by 10 times, assuming that the hardware has already increased in speed by 10 times, but if the code is not optimized, it is likely that the speed will actually decrease. The reason is that in the case of a larger machine scale, such as the data movement between GPU internal memory and CPU, or the data movement between GPUs, plus the data movement implemented by the server, will occupy most of the time of the entire system, and most of the time will be spent on data movement, making the scalability of the model also not good.
I believe that in the future, a good distributed software and a poor distributed software, on thousands of GPUs, or even 500 GPUs, may differ in speed by 10 times.
How Does Colossal-AI Operate?
Based on the above challenges, we have proposed the large model training system Colossal-AI, which provides optimization methods to reduce the cost of data movement and maximize the scalability efficiency of the model.
A specific data point is that training GPT-3 using the simplest PyTorch costs 10 million US dollars. After optimization by NVIDIA, using Megatron can reduce the cost to 3 million US dollars, and using Colossal-AI can reduce the cost to 1.3 million US dollars. It can be seen that under the same device conditions, minimizing data movement reduces the proportion of data movement to the lowest, and can maximize GPU throughput.

In response to the above issues, Colossal-AI has proposed three levels. Other similar software also includes these three levels.
The first level is memory optimization, ensuring that the memory efficiency of a single GPU and a single server is maximized, which is the foundation.
The second level is N-dimensional parallelism. When we use thousands or tens of thousands of GPUs, the core technology is Parallel Computing. When scaling from 1 GPU to 10 GPUs, because the scale is relatively small, we can easily achieve a 7x speedup. However, when scaling from 10 to 100 GPUs, the speedup may only be 4x, as the communication cost increases with the larger parallel scale. And when scaling from 100 GPUs to 1000 GPUs, due to the further increase in communication cost, the speedup may only be 2x. And when scaling from 1000 GPUs to 10,000 GPUs, if the software is not running well, it may not only fail to speed up, but may even become slower, as the devices spend all their time on higher-density communication.
Next is the optimization issue. I believe that the future development direction of large AI models has two levels. The first level is to make the models more intelligent, to design better structures, such as from BERT to GPT, or from ResNet to BERT, etc., which are constantly trying to change the model structure.
In addition, there is also progress in optimization methods, transitioning from SGD to MOMENTUM, ADAGRAD, and now to ADAM. It is also very important to consider what better optimization methods can increase efficiency by 10 times in the future.
Specifically, in terms of parallel training of large models:
First is data parallelism, which is the simplest and most efficient parallel method. Data parallelism refers to, for example, if there are 10,000 images, processing 1000 images per loop, and if there are 10 machines, each machine is assigned 100 images, and 10 loops can complete the processing of all images.
During data parallelism, aggregation is required. Each machine obtains different gradients with different data, learns different changes on different data, and updates parameter gradients. Finally, the global gradient is calculated, and the current method of summing and averaging has already achieved very good results. Previously, Colossal-AI's LARS method in data parallelism reduced the training time for ImageNet from one hour to one minute for companies such as Google, Meta, Tencent, Sony, etc.
Data parallelism is the most basic and stable. After the data is divided, if there are 10,000 GPUs in the future, it is very likely that several GPUs will crash every few hours. Managing a cluster of 10,000 GPUs is difficult, but the stability of data parallelism lies in the fact that even if a dozen GPUs out of 10,000 crash, the overall result will not change, because it is the sum and average of gradients.
Based on this consideration, I believe that data parallelism is a fundamental infrastructure.
However, data parallelism alone is not enough, because data parallelism assumes that the model must be copied to each GPU or server, and the server or GPU exchanges gradients. But if the GPU has only 80G of memory, a model with trillions of parameters would require tens of terabytes of memory, which cannot be stored in the GPU, so the model needs to be split across different GPUs and then the results aggregated. This method is called model parallelism. Model parallelism includes two types, the first being tensor parallelism, which is model parallelism within layers. For example, GPT-3 has approximately eighty to ninety layers, and each layer is split once, dividing the layer's calculations into multiple parts, calculating one layer and then the next, and so on, this is tensor parallelism.
Another method is Pipeline Parallelism, which is a model parallelism method between data parallelism and tensor parallelism. By constructing several data pipes, each data pipe has different data points, equivalent to dividing a large size into multiple small sizes, and performing pipe calculations in this way. If there are 10 pipes, each pipe represents ten sets of different data, the first pipe calculates the data of the first layer, the second pipe calculates the data of the second layer, and so on, in parallel, similar to building multiple floors with ten construction teams, when the first team is building the first floor of the first building, the second team is building the second floor of the second building, and so on.
The more floors there are, the higher the ratio between the floors and the construction teams, the higher the efficiency, equivalent to 10 construction teams working simultaneously. Each construction team is equivalent to a GPU, each building is equivalent to a pipe, and the number of floors in the building is equivalent to the number of layers in this neural network, this is the core logic of pipeline parallelism.
The industry has already done related work, in addition to Colossal-AI, there are also NVIDIA's TensorRT and Microsoft's DeepSpeed, which are the two companies with the highest technological barriers.
However, the difference between Colossal-AI and the others is that Colossal-AI focuses on the future development direction of large models. It can be seen that the current models are becoming wider, not deeper, so tensor parallelism will become more important, but its biggest drawback is that because it cuts the entire layer, the communication overhead is too high. This is why NVIDIA's CEO specifically mentioned the problem of excessive communication overhead when introducing 3D parallelism at the GTC summit, and it can only be done within a single server. Therefore, Colossal-AI focuses on 2D tensor parallelism and 2.5D tensor parallelism, reducing the computational cost by an order of magnitude.
This means that with 1D tensor parallelism, in a cluster of 10,000 machines, each machine needs to interact with 9999 other machines, while with 2D tensor parallelism, it is divided into various subunits, and each machine only needs to interact with 96 other machines. The core logic is to use local synchronization to replace global synchronization, and to use more local communication to replace global communication, and the most difficult part is the design and scheduling.
3D tensor parallelism is the same, as the complexity of the design increases by an order of magnitude for each additional dimension, resulting in a decrease in communication complexity.
In terms of memory optimization, the memory overhead of training large AI models is very large, even if nothing is done, it requires several terabytes of memory, and if no manual intervention is performed, once it is used, it may require tens or even hundreds of terabytes of memory.
In order to improve the predictive performance of the model, we often need long sequence data, and the essence of current large models is to predict the probability of the next word based on the output of a single word, making long sequences a necessity. In response to this, Colossal-AI has also introduced Sequence Parallelism.
Specifically, after the sequence is split, a serious problem arises: when calculating attention scores, each token needs to evaluate with all other tokens in the global sequence, but after splitting, only some tokens are on each server, and different tokens are also distributed on other servers, so each server needs to interact with other servers during operation.
In other words, if today there are 200 people in a room, and each person has a different snack, and I want each person to taste everyone else's snack, it would require at least 200 squared exchanges for each person to taste everyone else's snack. The simplest way is for everyone to form a circle, each person passes their eaten snack to the person on their right, and receives a snack from the person on their left, requiring only n-1 exchanges, or 199 exchanges to complete. This reduces the overall communication cost.
In summary, the core technology stack for training large AI models currently revolves around parallel computing, because we need to process hundreds, thousands, or tens of thousands of GPU cores and utilize all GPUs in parallel. Data parallelism, tensor parallelism, pipeline parallelism, and sequence data parallelism are the core modules of parallelism.
Currently, in terms of memory optimization, we are in an environment with not many choices, NVIDIA GPUs are the best, and it seems that we have no other better solutions to replace them. However, the downside is that the memory of NVIDIA GPUs is limited, so in this situation, can we consider how to use CPU memory, NVMe memory, the core idea is, if the GPU memory is not enough, move it to the CPU, and if the CPU memory is not enough, move it to NVMe, effectively minimizing data movement, minimizing data movement between CPU and GPU, and maximizing data movement between CPU and NVMe, thereby increasing throughput speed to the highest level.
Colossal-AI is an open-source software, and at the same time, we have also developed a commercial platform. For users without GPUs, they can directly train and deploy their large models on the platform. We also provide various models such as LLaMA, PaLM, GPT, etc., and the fastest model fine-tuning can be completed in just two to three days. Compared to before, when users may have needed several weeks or even months to handle hardware, software, and other infrastructure, efficiency has been greatly improved. At the same time, Colossal-AI also protects user privacy. The platform does not retain or access user data, which is the fundamental difference between Colossal-AI and OpenAI ChatGPT. When we upload data to Google Cloud, many times Google does not touch our data, but OpenAI GPT will analyze it. Risks such as the lack of interpretability of AI models and incomplete training are common. Therefore, in the future, many companies will also train their own large models. What Colossal-AI does is maximize the protection of user privacy while providing tools for training large models.
In terms of performance, Colossal-AI can train models 24 times larger on the same hardware. Compared to DeepSpeed's 3x acceleration, even a low-end server can complete the corresponding model training with the help of Colossal-AI. For example, training LLaMA-65B on Colossal-AI using the same code can directly achieve approximately 50% acceleration.
A simple analogy is that currently, training large models is like mining for gold, NVIDIA sells shovels, and we sell gloves and clothes, maximizing the efficiency of mining for gold.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







