Multicoin Capital partner Kyle Samani elaborated on the 7 reasons why modular blockchains are overrated.
Author: Kyle Samani, Partner at Multicoin Capital
Translator: Luffy, Foresight News
Over the past two years, the scalability debate in blockchain has centered around the "modularization vs. integration" debate.
It is important to note that discussions in cryptocurrency often confuse "single" and "integrated" systems. The technical debate between integrated and modular systems has a long history, spanning over 40 years. The conversation in the cryptocurrency field should be constructed through the same historical lens, and it is far from a new debate.
When considering modularization and integration, the most important design decision blockchain can make is the extent to which it exposes the complexity of the stack to application developers. The clients of blockchain are application developers, so the ultimate design decision should consider their perspective.
Today, modularization is largely hailed as the primary way to expand blockchain. In this article, I will question this assumption from first principles, reveal the cultural myths and hidden costs of modular systems, and share the conclusions I have reached over the past six years of contemplating this debate.
Modular systems increase development complexity
So far, the biggest hidden cost of modular systems is the increased complexity of the development process.
Modular systems significantly increase the complexity that application developers must manage, both in their own application context (technical complexity) and in the context of interacting with other applications (social complexity).
In the context of cryptocurrency, modular blockchain theoretically allows for more specialization, but at the cost of creating new complexity. This complexity (essentially technical and social) is being passed on to application developers, ultimately making application building more difficult.
For example, consider the OP Stack. So far, it seems to be the most popular modular framework. OP Stack forces developers to choose between adopting the Law of Chains (which brings a lot of social complexity) or forking and managing separately. Both choices bring significant downstream complexity to builders. If you choose to fork, will you receive technical support from other ecosystem participants (CEX, fiat gateways, etc.) who must incur costs to comply with new technical standards? If you choose to follow the Law of Chains, what rules and constraints will be imposed on you today and tomorrow?
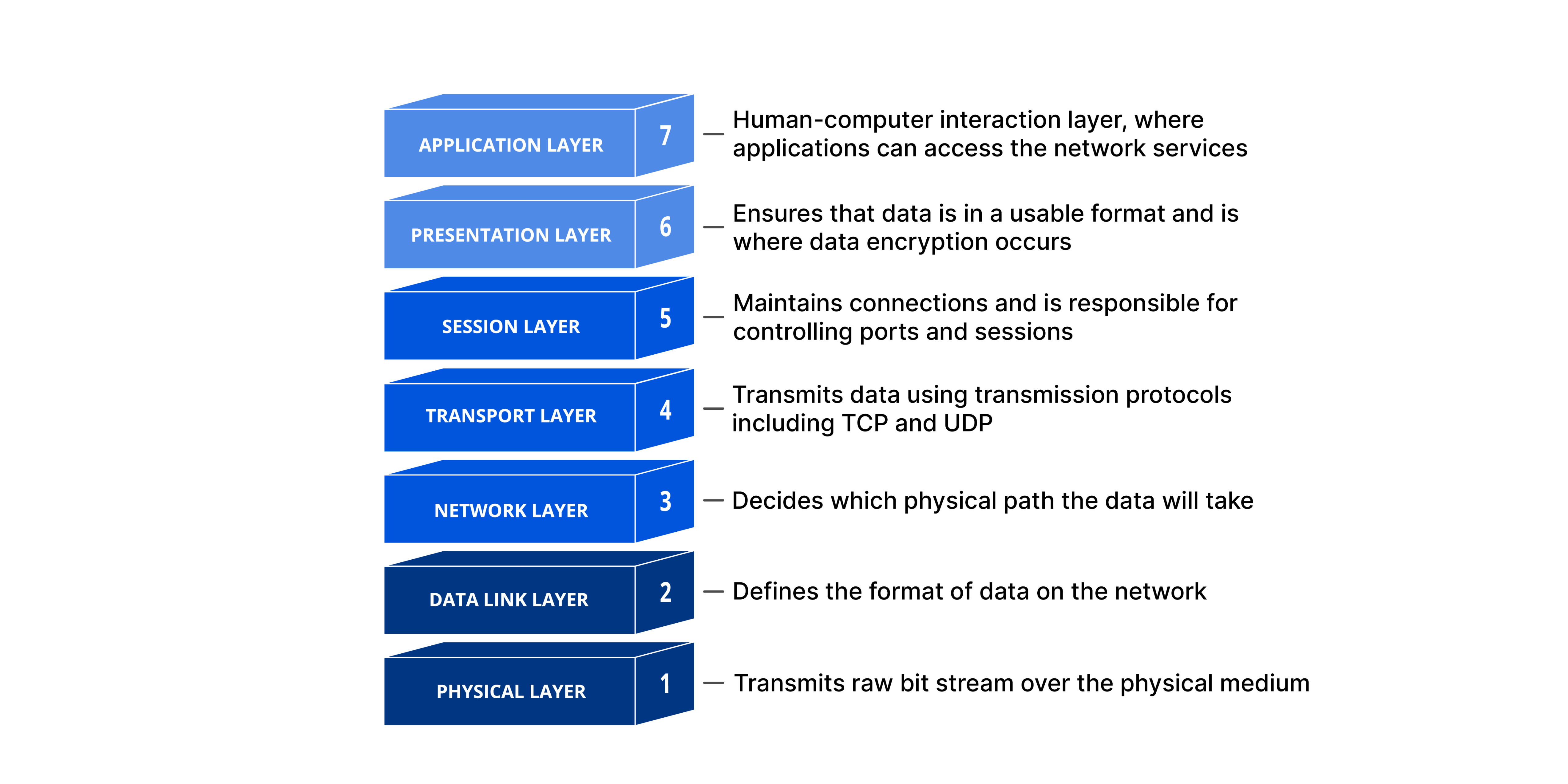
Source: OSI Model
Modern operating systems (OS) are large complex systems containing hundreds of subsystems. Modern operating systems handle layers 2-6 in the above diagram. This is a typical example of integrating modular components to manage the complexity of the stack exposed to application developers. Application developers do not want to deal with anything below layer 7, which is the reason operating systems exist: to manage the complexity of the layers below for application developers to focus on layer 7. Therefore, modularization itself should not be the goal, but rather a means to an end.
Every major software system in the world today—cloud backends, operating systems, database engines, game engines, etc.—is highly integrated and composed of many modular subsystems. Software systems tend to be highly integrated to maximize performance and reduce development complexity. Blockchain is no exception.
By the way, Ethereum is reducing the complexity that emerged during the Bitcoin fork era from 2011-2014. Modularization supporters often emphasize the Open Systems Interconnection (OSI) model, arguing that data availability (DA) and execution should be separated; however, this argument is widely misunderstood. A correct understanding of the current issue leads to the opposite conclusion: OSI is an argument for an integrated system, not a modular system.
Modular chains cannot execute code faster
By design, the common definition of a "modular chain" is the separation of data availability (DA) and execution: a set of nodes is responsible for DA, while another set (or sets) of nodes are responsible for execution. The sets of nodes do not have to have any overlap, but they can.
In practice, separating DA and execution does not fundamentally improve the performance of either; instead, hardware somewhere in the world must perform DA, and hardware somewhere else must perform execution. Separating these functions does not fundamentally speed up either one. While separation can reduce computational costs, it can only do so through centralized execution.
It needs to be reiterated: whether modular or integrated architecture, some hardware somewhere must do the work, and separating DA and execution onto separate hardware does not fundamentally accelerate or increase the total system capacity.
Some people believe that modularization allows multiple EVMs to run in parallel in a Rollup manner, enabling execution to scale horizontally. While this is theoretically correct, this view actually emphasizes the limitations of EVM as a single-threaded processor, rather than the fundamental premise of separating DA and execution in the context of scaling the overall system throughput.
Separate modularization does not increase throughput.
Modularization increases users' transaction costs
By definition, each L1 and L2 is an independent asset ledger with its own state. These separate state fragments can communicate, though with longer transaction delays and more complex situations for developers and users (via cross-chain bridges like LayerZero and Wormhole).
The more asset ledgers there are, the more global state fragments there are for all accounts. This is dreadful for chains and users across multiple chains. State fragmentation can lead to a range of consequences:
- Reduced liquidity, leading to higher transaction slippage;
- More total gas consumption (cross-chain transactions require at least two transactions on at least two asset ledgers);
- Increased duplicate calculations across asset ledgers (thus reducing the overall system throughput): when the price of ETH-USDC changes on Binance or Coinbase, there are arbitrage opportunities on every ETH-USDC pool on all asset ledgers (you can easily imagine a world where there are more than 10 transactions on various asset ledgers whenever the ETH-USDC price changes on Binance or Coinbase. Maintaining price consistency in a fragmented state is extremely inefficient use of block space).
It is important to recognize that creating more asset ledgers significantly increases the costs of all these dimensions, especially those related to DeFi.
The primary input of DeFi is on-chain state (i.e., who owns which assets). When teams launch application chains/Rollups, they naturally create state fragments, which is very detrimental to DeFi, both for the developers managing application complexity (bridges, wallets, latency, cross-chain MEV, etc.) and for users (slippage, settlement delays).
The most ideal condition for DeFi is: assets are issued on a single asset ledger and transactions are conducted within a single state machine. The more asset ledgers there are, the more complexity application developers must manage and the higher the costs users must bear.
Application Rollup does not create new profit opportunities for developers
Supporters of application chains/Rollups believe that incentives will drive application developers to develop Rollups instead of building on L1 or L2, so that applications can capture MEV value themselves. However, this idea is flawed because running application Rollup is not the only way to capture MEV back to the application layer tokens, and in most cases, it is not the best way. Application layer tokens only need to encode logic in smart contracts on the general chain to capture MEV back to their own tokens. Let's consider a few examples:
- Liquidation: If Compound or Aave DAO wants to capture a portion of the MEV flowing to liquidation bots, they only need to update their respective contracts to have a portion of the current fees flowing to liquidators paid to their DAO, without needing a new chain/Rollup.
- Oracle: Oracle tokens can capture MEV by providing back running services. In addition to price updates, oracles can bundle any arbitrary on-chain transactions guaranteed to run immediately after a price update. Therefore, oracles can capture MEV by providing back running services to searchers, block builders, etc.
- NFT minting: NFT minting is rife with flipping bots. This situation can be easily mitigated by simply coding a decreasing profit redistribution. For example, if someone attempts to resell their NFT within two weeks of minting, 100% of the proceeds will revert back to the issuer or DAO. Over time, this percentage may change.
Capturing MEV back to application layer tokens has no universal answer. However, with a little thought, application developers can easily capture MEV back to their own tokens on the general chain. Launching an entirely new chain is unnecessary, and it brings additional technical and social complexity to developers and more wallet and liquidity troubles to users.
Application Rollup does not solve cross-application congestion issues
Many people believe that application chains/Rollups can ensure that applications are not affected by Gas spikes caused by other on-chain activities (such as popular NFT minting). This view is partially correct, but mostly incorrect.
This is a historical issue, fundamentally due to the single-threaded nature of EVM, rather than the lack of separation of DA and execution. All L2s have to pay fees to L1, and L1 fees can increase at any time. Earlier this year, during the memecoin craze, transaction fees on Arbitrum and Optimism exceeded $10 at one point. Recently, Optimism's fees also surged after the launch of Worldcoin.
The only solution to high fee peaks is: 1) maximize L1 DA, 2) granularize the fee market as much as possible:
If L1's resources are constrained, usage peaks in various L2s will be passed on to L1, resulting in higher costs for all other L2s. Therefore, application chains/Rollups cannot be immune to Gas peaks.
The coexistence of numerous EVM L2s is just a crude attempt to localize the fee market. It is better than placing the fee market on a single EVM L1, but it does not solve the core problem. When you realize that the solution is localizing the fee market, the logical endpoint is a fee market for each state (rather than a fee market for each L2).
Other chains have already reached this conclusion. Solana and Aptos naturally localized the fee market. This required a lot of engineering work over the years for their respective execution environments. Most modularization supporters severely underestimate the importance and difficulty of building localized fee market engineering.
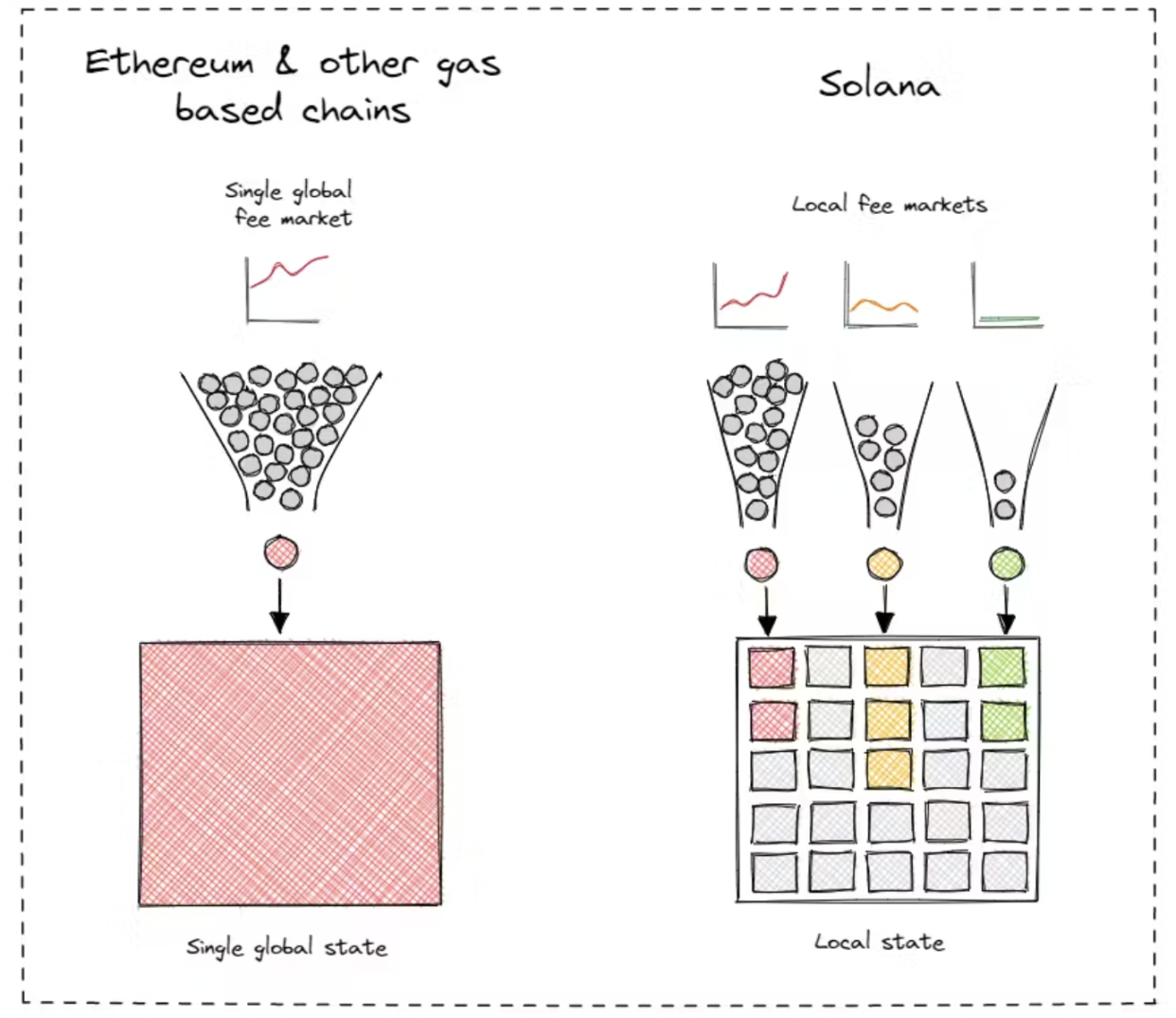
By launching multiple chains, developers cannot unlock real performance benefits. When applications drive increased transaction volume, the costs of all L2 chains are affected.
Flexibility is overrated
Supporters of modular chains believe that modular architecture is more flexible. This statement is obviously true, but is it really important?
For six years, I have been trying to find meaningful use cases for flexibility that a general L1 cannot provide to application developers. So far, apart from three very specific use cases, no one has been able to clearly explain why flexibility is important and how it directly helps with scaling. I have found three specific use cases where flexibility is important:
Utilizing "hot" states in applications. Hot states are temporary submissions to the chain that are necessary for real-time coordination of certain sets of operations but do not exist permanently. Some examples of hot states:
- Limit orders in DEX, such as dYdX and Sei (many limit orders are eventually canceled).
- Real-time coordination and identification of order flow in dFlow (dFlow is a protocol that facilitates decentralized order flow markets between market makers and wallets).
- Oracles like Pyth, which is a low-latency oracle. Pyth operates as an independent SVM chain. Pyth generates so much data that the core Pyth team decided it was best to send high-frequency price updates to a separate chain and bridge the prices to other chains as needed using Wormhole.
Modifying consensus chains. The best example is Osmosis (where all transactions are encrypted before being sent to validators), and Thorchain (which prioritizes transactions within a block based on the fees paid).
Infrastructure that needs to utilize threshold signature schemes (TSS) in some way. Some examples in this area are Sommelier, Thorchain, Osmosis, Wormhole, and Web3Auth.
Except for Pyth and Wormhole, all the examples listed above are built using the Cosmos SDK and run as independent chains. This fully demonstrates the applicability and scalability of the Cosmos SDK for all three use cases: hot states, consensus modifications, and TSS systems.
However, most of the projects in the above three use cases are not applications, they are infrastructure.
Pyth and dFlow are not applications, they are infrastructure. Sommelier, Wormhole, Sei, and Web3Auth are not applications, they are infrastructure. Among them, the only type of user-facing applications is a specific type: DEX (dYdX, Osmosis, Thorchain).
For six years, I have been asking Cosmos and Polkadot supporters about the use cases brought about by the flexibility they provide. I believe there is enough data to make some inferences:
First, infrastructure examples should not exist as Rollups because they either generate too much low-value data (e.g., hot states, where the whole point is that the data is not committed back to L1) or because they perform some function related to state updates on asset ledgers (e.g., all TSS use cases).
Second, the only type of application I have seen benefit from modifying the core system design is DEX. Because DEX is rife with MEV, and a general chain cannot match the latency of CEX. Consensus is the basis for transaction execution quality and MEV, so changes based on consensus naturally bring a lot of innovation opportunities to DEX. However, as mentioned earlier in this article, the primary input for spot DEX is the assets being traded. DEX competes for assets, and therefore for asset issuers. In this framework, independent DEX chains are unlikely to succeed because the primary concern for asset issuers at the time of issuance is not the MEV related to DEX, but the general smart contract functionality and incorporating that functionality into developers' respective applications.
However, derivative DEX does not need to compete for asset issuers; they primarily rely on collateral such as USDC and oracle price feeds, and essentially have to lock up user assets to collateralize derivative positions. Therefore, in terms of the significance of independent DEX chains, they are most likely suitable for derivative-focused DEX such as dYdX and Sei.
Let's consider the current existing general integrated L1 applications, including: games, DeSoc systems (such as Farcaster and Lens), DePIN protocols (such as Helium, Hivemapper, Render Network, DIMO, and Daylight), Sound, NFT exchanges, and so on. These do not particularly benefit from the flexibility brought about by modifying consensus, and each of their asset ledgers has a set of fairly simple, obvious, and common requirements: low fees, low latency, access to spot DEX, access to stablecoins, and access to fiat channels such as CEX.
I believe we now have enough data to some extent to show that the vast majority of user-facing applications have the same general requirements as those listed in the previous paragraph. While some applications can optimize marginal other variables through custom functionality in the stack, the trade-offs brought about by these customizations are usually not worth it (more bridging, less wallet support, less indexing/query program support, reduced fiat channels, etc.).
Launching new asset ledgers is one way to achieve flexibility, but it rarely adds value and almost always brings technical and social complexity, with minimal ultimate benefit for application developers.
Expanding DA does not require re-collateralization
You will also hear modularization supporters talk about re-collateralization in the context of scaling. This is the most speculative argument put forward by modular chain supporters, but it is worth discussing.
It roughly points out that due to re-collateralization (e.g., through systems like EigenLayer), the entire crypto ecosystem can re-collateralize ETH an infinite number of times to empower an infinite number of DA layers (e.g., EigenDA) and execution layers. Therefore, while ensuring the appreciation of ETH value, scalability is addressed from all aspects.
Although there is a huge amount of uncertainty between the current situation and the theoretical future, we naturally assume that all layering assumptions are as effective as advertised.
Currently, Ethereum's DA is approximately 83 KB/s. With the launch of EIP-4844 later this year, that speed can roughly double to about 166 KB/s. EigenDA can add an additional 10 MB/s, but it requires a different set of security assumptions (not all ETH will be re-collateralized to EigenDA).
In comparison, Solana currently offers a DA of approximately 125 MB/s (32,000 shreds per block, 1,280 bytes per shred, 2.5 blocks per second). Solana is much more efficient than Ethereum and EigenDA. Additionally, according to Nielsen's Law, Solana's DA expands over time.
There are many ways to expand DA through re-collateralization and modularization, but these mechanisms are not necessary today and bring significant technical and social complexity.
Building for application developers
After years of contemplation, my conclusion is that modularization itself should not be a goal.
Blockchain must serve its clients (i.e., application developers), so it should abstract the complexity at the infrastructure level so that developers can focus on building world-class applications.
Modularization is great. But the key to building winning technology is figuring out which parts of the stack need to be integrated and which parts are left to others. As it stands, a chain that integrates DA and execution essentially provides a simpler end-user and developer experience and ultimately provides a better foundation for first-class applications.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







