Advantages of LLM
The advantages of LLM include its ability to understand large amounts of data, perform various language-related tasks, and customize results according to user needs.
Author: Yiping, IOSG Ventures
Preface
As large language models (LLM) continue to thrive, we are seeing many projects integrating artificial intelligence (AI) and blockchain. The combination of LLM and blockchain is increasing, and we also see opportunities for the reintegration of AI with blockchain. Notably, zero-knowledge machine learning (ZKML) is worth mentioning.
Artificial intelligence and blockchain are two transformative technologies with fundamentally different characteristics. Artificial intelligence requires powerful computing power, usually provided by centralized data centers. On the other hand, blockchain provides decentralized computing and privacy protection, but performs poorly in tasks requiring large-scale computation and storage. We are still exploring and researching the best practices for integrating artificial intelligence and blockchain, and will also introduce some current "AI + blockchain" integration project cases in the future.
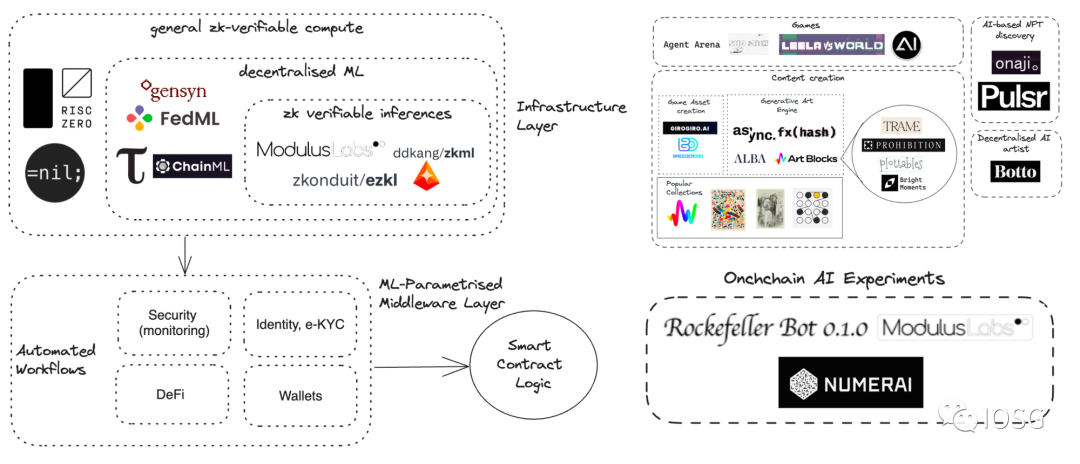
Source: IOSG Ventures
This research report is divided into two parts, and this article is the first part. We will focus on the application of LLM in the field of encryption and discuss the strategies for application implementation.
What is LLM?
LLM (Large Language Model) is a computerized language model composed of an artificial neural network with a large number of parameters (usually in the billions). These models are trained on a large amount of unlabeled text.
Around 2018, the emergence of LLM completely changed the research in natural language processing. Unlike previous methods that required training specific supervised models for specific tasks, LLM, as a general model, performs well on various tasks. Its capabilities and applications include:
Understanding and summarizing text: LLM can understand and summarize large amounts of human language and text data. They can extract key information and generate concise summaries.
Generating new content: LLM has the ability to generate content based on text. By providing a prompt to the model, it can answer questions, generate new text, summaries, or perform sentiment analysis.
Translation: LLM can be used for translation between different languages. They use deep learning algorithms and neural networks to understand the context and relationships between vocabulary.
Predicting and generating text: LLM can predict and generate text based on contextual background, similar to human-generated content, including songs, poems, stories, marketing materials, etc.
Applications in various fields: Large language models have wide applicability in natural language processing tasks. They are used in conversational AI, chatbots, healthcare, software development, search engines, tutoring, writing tools, and many other fields.
The advantages of LLM include its ability to understand large amounts of data, perform various language-related tasks, and customize results according to user needs.
Common Applications of Large Language Models
Due to its outstanding natural language understanding capabilities, LLM has significant potential, and developers mainly focus on the following two aspects:
Providing accurate and up-to-date answers to users based on a large amount of contextual data and content.
Completing specific tasks issued by users using different agents and tools.
It is these two aspects that have led to the explosive development of LLM applications such as chatting with XX. For example, chatting with PDFs, documents, and academic papers.
Subsequently, people have attempted to integrate LLM with various data sources. Developers have successfully integrated platforms such as Github, Notion, and some note-taking software with LLM.
To overcome the inherent limitations of LLM, different tools have been incorporated into the system. The first such tool is a search engine, which provides LLM with the ability to access the latest knowledge. Further progress will integrate tools such as WolframAlpha, Google Suites, and Etherscan with large language models.
Architecture of LLM Apps
The following diagram outlines the process of LLM applications in responding to user queries: First, relevant data sources are transformed into embedding vectors and stored in a vector database. The LLM adapter uses user queries and similarity search to find relevant contexts from the vector database. The relevant contexts are put into prompts and sent to LLM. LLM executes these prompts and generates responses using tools. Sometimes, LLM is fine-tuned on specific datasets to improve accuracy and reduce costs.
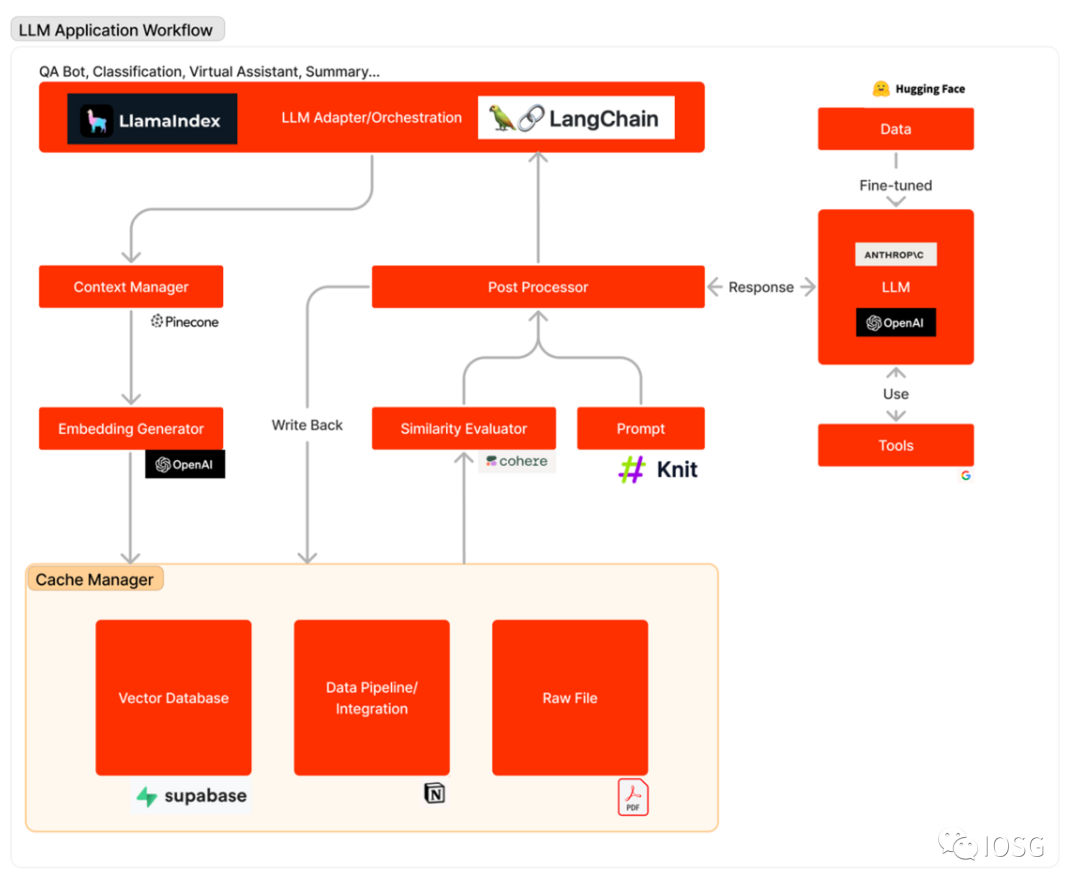
The workflow of LLM applications can be roughly divided into three main stages:
Data preparation and embedding: This stage involves retaining confidential information (such as project memos) for future access. Typically, files are segmented and processed through embedding models, saved in a special type of database called a vector database.
Prompt formulation and extraction: When a user submits a search request (in this case, searching for project information), the software creates a series of prompts input into the language model. The final prompt usually includes prompt templates hardcoded by software developers, effective output examples as few-shot instances, and any necessary data obtained from external APIs and relevant files extracted from the vector database.
Prompt execution and inference: After completing the prompts, they are provided to pre-existing language models for inference, which may include proprietary model APIs, open-source or individually fine-tuned models. At this stage, some developers may also integrate operating systems (such as logging, caching, and validation) into the system.
Introducing LLM into the Field of Encryption
Although the field of encryption (Web3) has some applications similar to Web2, developing excellent LLM applications in the field of encryption requires particular caution.
The encryption ecosystem is unique, with its own culture, data, and integrations. LLM fine-tuned on these encryption-specific datasets can provide superior results at relatively low costs. Although data is abundant, there is a noticeable lack of open datasets on platforms such as HuggingFace. Currently, there is only one dataset related to smart contracts, which contains 113,000 smart contracts.
Developers also face the challenge of integrating different tools into LLM. These tools are different from those used in Web2 and provide LLM with access to transaction-related data, interaction with decentralized applications (Dapps), and the ability to execute transactions. So far, we have not found any Dapp integrations in Langchain.
Although developing high-quality encrypted LLM applications may require additional investment, LLM is naturally suitable for the field of encryption. This field provides rich, clean, and structured data. In addition, Solidity code is usually concise and clear, making it easier for LLM to generate functional code.
In the "second part," we will discuss 8 potential directions in which LLM can help the blockchain field, such as:
Integrating built-in artificial intelligence/LLM functionality into blockchain.
Analyzing transaction records using LLM.
Identifying potential bots using LLM.
Writing code using LLM.
Reading code using LLM.
Assisting the community using LLM.
Tracking the market using LLM.
Analyzing projects using LLM.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





