Although web crawling technology itself is not prohibited, its improper use may lead to legal issues, especially when it involves personal information, privacy, copyright, and unfair competition.
Author: Lawyer Liu Honglin
This year, large-scale AI tools such as GPT and AI painting are hot, and many people are eager to join the AI entrepreneurship boom, with various entrepreneurial projects emerging. High-quality data is crucial for training large AI models. Only with a sufficient amount of data can intelligent and powerful AI tools be trained. After more than 20 years of vigorous development of the Internet in China, can there still be a lack of data? Recently, Lawyer Mankun received inquiries from netizens who were planning to use web crawlers to crawl data from Zhihu to create a Zhihu GPT robot. Isn't that beautiful? But hold on, the legal risks involved cannot be ignored.
Web Crawling: A Double-Edged Sword
Web crawling technology is a method of automatically obtaining data from the Internet through programming. Its name vividly illustrates its working principle: simulating the process of browsing web pages in a web browser to collect and extract data.
Web crawlers are widely used in search engines, data collection, ad filtering, big data analysis, and other fields. As a powerful information collection program, it can significantly improve work efficiency, especially in the collection and organization of massive data.
However, improper use of the technology can also lead to "crawling disasters," causing network congestion, crashes, server failures, and even data security risks. Even the well-known "China Judgments Online" website was not spared.

Image: Reply from the Supreme People's Court on the construction of the "China Judgments Online" website in 2019
Risks of Using Web Crawling Technology
Web crawling as a means of obtaining data is not prohibited by law. However, the manner and purpose of its use determine whether illegal behavior and consequences will arise.
1. Improper Use
Using web crawling technology can result in a large number of visits to a website and frequent extraction of pages and data in a short period. This may cause a sharp increase in the website's bandwidth and server load, affecting its normal operation, and may even lead to crashes or slow responses, disrupting the normal operation of the visited website, and in severe cases, constituting a crime.
For example, in a case where Yang authorized his employee Zhang to develop a credit system software with a "web crawler" function that could link to the Shenzhen residence permit website. In May 2018, the software made a large number of queries to the Shenzhen residence permit system for two consecutive hours, causing the system to malfunction, greatly affecting the daily operation of the Shenzhen Public Security Bureau's population management department. Both individuals were found guilty of damaging computer information systems. [(2019) Yue 0305 Xing Chu 193]
2. Improper Purpose
Compared to the manner of use, how the obtained information and data are used has a greater impact on the nature of web crawling behavior.
Illegal use of crawled data and information mainly includes:
(1) Theft of personal information: Maliciously using web crawling technology to capture personal information from websites may involve infringement of others' privacy and personal information, and in severe cases, may constitute the crime of infringing on citizens' personal information.

(2) Unfair competition in business: Using web crawling technology to obtain competitors' trade secrets, pricing information, user data, etc., and then integrating the data and "moving" it to other platforms to gain a competitive advantage through this convenient means, may lead to unfair competition.
In the "Kumike v. Chelai Unfair Competition Dispute," the court held that the unauthorized use of web crawling technology to access the server backend of the rights holder and illegally obtain and use the rights holder's real-time bus information data was a form of "getting something for nothing" and "feeding on others," and it illegally occupied the intangible property rights of others, undermining their competitive advantage in the market, constituting unfair competition.
(3) Infringement of intellectual property: Crawling content protected by copyright and then using it for unauthorized public dissemination or commercial purposes constitutes infringement of intellectual property rights.


Risks of "Feeding" Crawled Data to Large Models
From the analysis above, it is clear that the risks of using web crawling technology mainly lie in the manner of crawling and the content crawled. Therefore, does controlling the frequency and content of crawling and using publicly available content to train a robot pose no risks?
First, as early as 2018, Zhihu's official account released an "Announcement on the Upgrade of Zhihu User Rights Protection," stating that Zhihu adopts a whitelist system for the use of Zhihu content by third parties, and third parties need to apply through official channels. If crawling behavior violates Zhihu's terms of service, Zhihu may take actions such as banning accounts, IP addresses, or other legal actions.
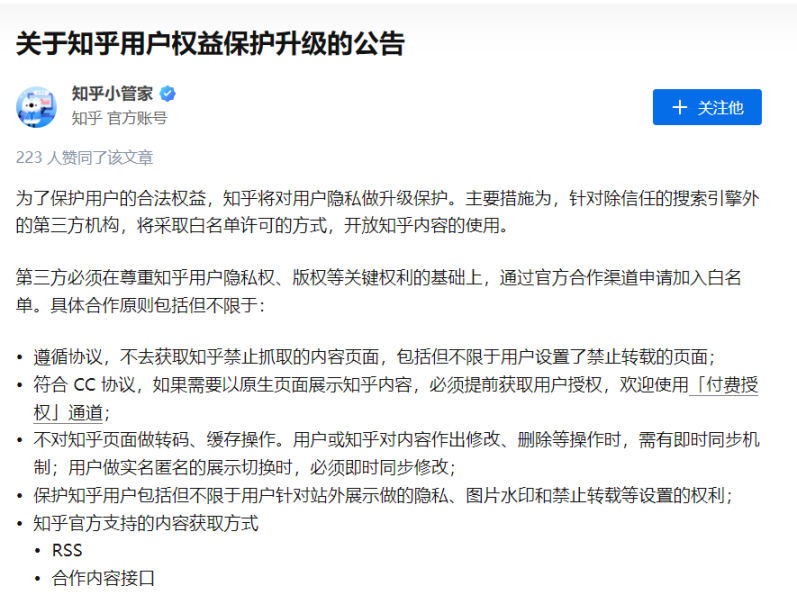
 Excerpt from "Zhihu Institutional Account Usage Guidelines" (Trial)
Excerpt from "Zhihu Institutional Account Usage Guidelines" (Trial)
Second, the content on Zhihu is usually original or authorized by users, and the copyright belongs to the users themselves. Unauthorized crawling and use of this content may involve infringement of Zhihu's copyright and intellectual property rights.

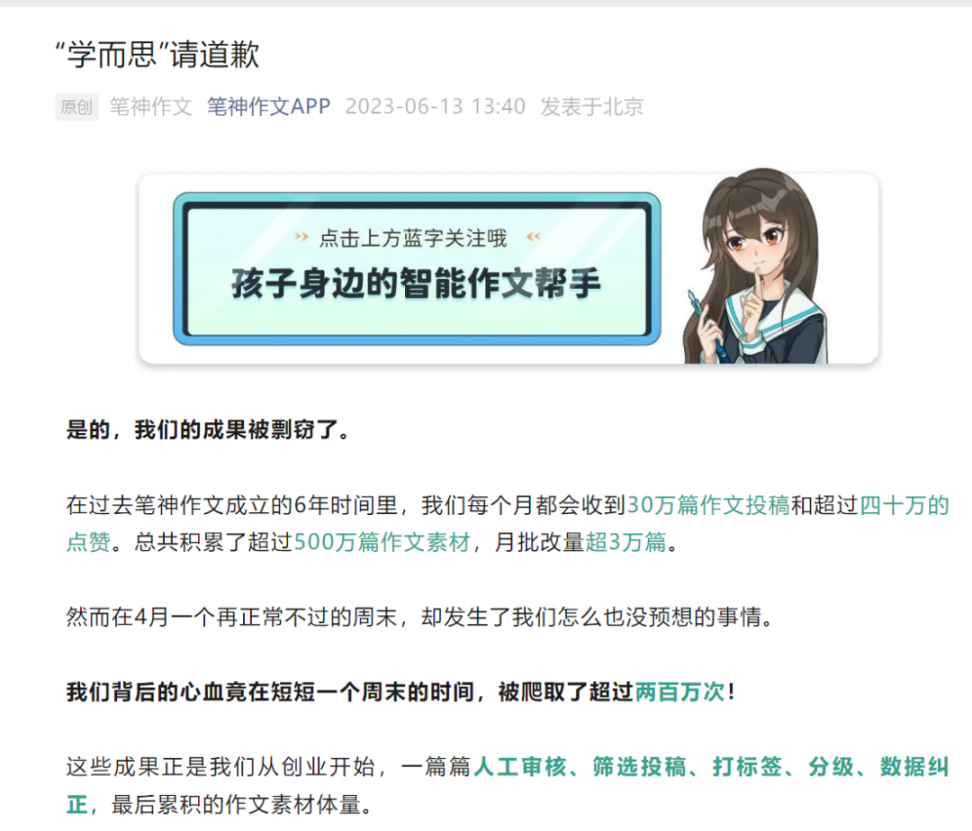
In fact, "data theft" for training large AI models is not an isolated case. Last month, Bishen Essay publicly accused its former partner Xueersi, claiming that Xueersi used web crawling to "steal data" to train its own AI product. Bishen Essay stated that it would resolve the dispute through legal procedures, demanding Xueersi to pay 1 yuan in compensation, issue a public apology, and delete the crawled data.
Conclusion
In the wave of AI entrepreneurship, data has become increasingly important. When facing the temptation of web crawling technology, it should be recognized that although web crawling technology itself is not prohibited, its improper use may lead to legal issues, especially when it involves personal information, privacy, copyright, and unfair competition.
The "Interim Measures for the Management of Generative Artificial Intelligence Services" explicitly states that when processing training data, data and basic models from legal sources should be used. In the process of entrepreneurship, business owners should ensure the legality and ethics of data collection. If you want to use crawled data to train large AI models, you must obtain authorization from the data source in advance and comply with the relevant platform's regulations.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







