大多数人知道小米是中国的手机品牌。那个制造便宜电动滑板车和空气净化器的品牌。并不是你会期待在周一早晨打破主要人工智能推理速度记录的公司。
然而,小米刚刚发布了MiMo-V2.5-Pro-UltraSpeed,这是其万亿参数旗舰的处理模式,达到每秒超过1,000个令牌——在演示中峰值接近1,200。
参数是定义模型思考方式的内部数值权重——参数越多,它能够识别的模式就越复杂。令牌是模型所读写的文本块,平均每个大约相当于三个字母的长度。
小米在一台8个GPU的普通节点上实现了这一点。标准硬件,没有定制芯片。这改变了谁能够在生产中实际部署这种速度的计算。
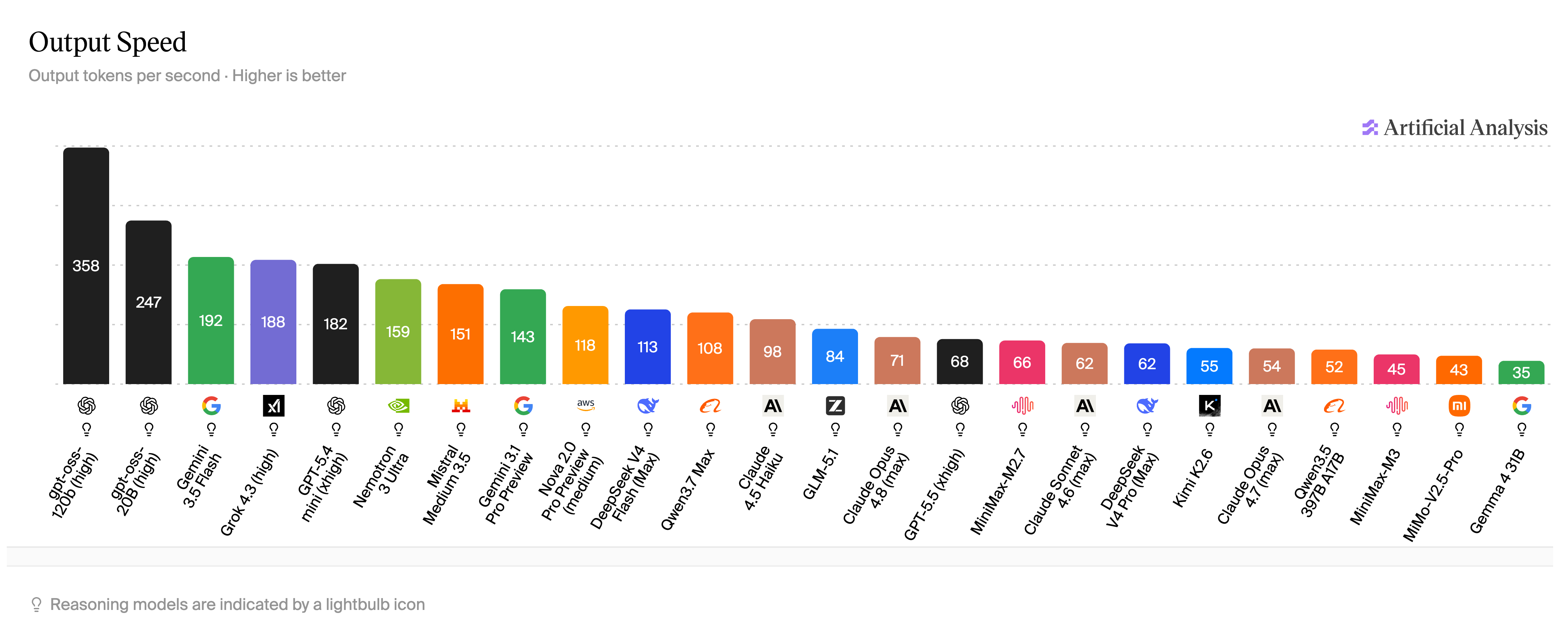
为了将这个数字转化为便于理解的概念:据人工分析,GPT-5.5——大部分ChatGPT用户实际上正在与之交流——的速度是68。Claude Opus 4.6的速度约为71,较低端模型Haiku的速度接近98个令牌每秒。Gemini Flash的速度是192个令牌每秒。MiMo-V2.5-Pro-UltraSpeed的速度是1,000,且该模型在编码基准测试上与Opus相匹配。
Cerebras和Groq围绕着这个问题建立了整个业务。Cerebras设计了一款面积相当于餐盘的晶圆级芯片,配备44GB的片上内存,以消除减缓GPU推理的带宽瓶颈。它在Meta的Llama 3.1 405B模型上达到了每秒969个令牌——这是个令人印象深刻的数字,但这是一个4050亿参数的模型,规模不到MiMo-V2.5-Pro的一半。Groq的定制语言处理单元架构的最高速度在300到750个令牌每秒之间,具体取决于模型。
这两者都不会在你今晚可以从AWS租用的硬件上运行。
小米通过软件独立在普通GPU上实现了这一点——这是一种模型级技巧与名为TileRT的专用推理引擎的结合。
底层到底发生了什么
两种技术驱动了这个速度。第一种技术被称为FP4量化:小米将大多数1万亿参数的专家层缩小至4位,而不是以完整的8位或16位数值精度运行模型。内存占用减少,带宽压力降低,速度提升。问题通常是小幅的质量下降。小米的解决办法非常精准:只有专家层被压缩,其他所有保持全精度。采用这种方法,质量损失被描述为接近零。
第二种是DFlash推测解码。正常推测解码让一个小的草稿模型猜测接下来的几个令牌,然后大型模型并行验证它们。DFlash完全跳过了顺序草稿——它在一次前向传递中填充一个完整的掩码位置块。在编码任务中,大型模型在每轮验证中平均接受8个提出的令牌中的6.3个。这意味着一次确认六个令牌,而不是一次只确认一个。
TileRT将其结合在一起。它保持整个计算管道持续驻留在GPU内部——没有每个操作的启动开销,没有执行间隙。
小米称这种方法为“极端模型系统共同设计”,这个词语非常准确:单靠任何一种技术都无法达到每秒1,000个令牌,但所有方法之间的协同作用可以。
MiMo-V2.5-Pro是一个前沿级别的模型。我们在四月报道了V2.5 Pro的发布——它在大多数编码基准上与Claude Opus相匹配,运行费用大约是每百万个令牌$0.43输入/$0.87输出。Opus的费用是每百万个令牌$5输入/$25输出。
UltraSpeed加速了这个确切的MiMo V2.5 Pro模型,而不是一个简化版本。
足够快的推理改变了你使用模型的方式。你可以并行运行数十条推理路径,而不是等待一个答案。欺诈检测、交易信号生成、实时代理循环——所有这些都有严格的延迟约束,60个令牌每秒无法满足。在每秒1,000个令牌时,它们可以。
小米将这一速度的定价定为标准MiMo-V2.5-Pro价格的三倍,而输出则大约是十倍。API试用将于6月9日至23日进行,基于申请,并优先考虑企业和专业开发者。FP4-DFlash检查点已在Hugging Face上开源以供社区测试。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





