作者:王健硕
2023 年 3 月 6 日,ChatGPT 刚出来不久,GPT-4 还没发布,我和 Sarah 做了一场关于 ChatGPT 的访谈——Traders' Talk「大白话系列」的第三期(大白话聊 ChatGPT 播客发布了,欢迎收听)。
那时候 ChatGPT 才出来没多久,真正上手用的人还非常少,这场长达三个小时的访谈,后来一直挂在小宇宙 ChatGPT 类目的第一名。我在里面一口气抛出了二十来个判断和预测,全凭直觉和有限的信息,没什么数据。当时那场访谈的完整逐字稿,还留在公众号上。
现在是 2026 年 5 月底,三年过去了,AI 已经长成了当年想象不到的样子。
我想做一件事:把当年那二十条逐条拎出来,用今天能查到的最新数据,客观地对一次账。看清楚三年里世界到底变成了什么样,也看清楚三年前那个我,哪些地方看准了,哪些地方看偏了。
为了尽量不偏不向,这次对账我索性交给了 AI 来做:把当年的访谈逐字稿丢进一个 workflow,由它调度 41 个 Opus 4.8 的 agent,先把二十条判断逐条拆开,再各自联网检索最新数据、一条条交叉求证,最后给三年前的王建硕打分。这群 agent 花了大约 20 分钟、烧掉 140 万 token(约等于 35 美元),跑出了下面这份报告。判断都来自它们,不是我。基准日定在 2026 年 5 月。
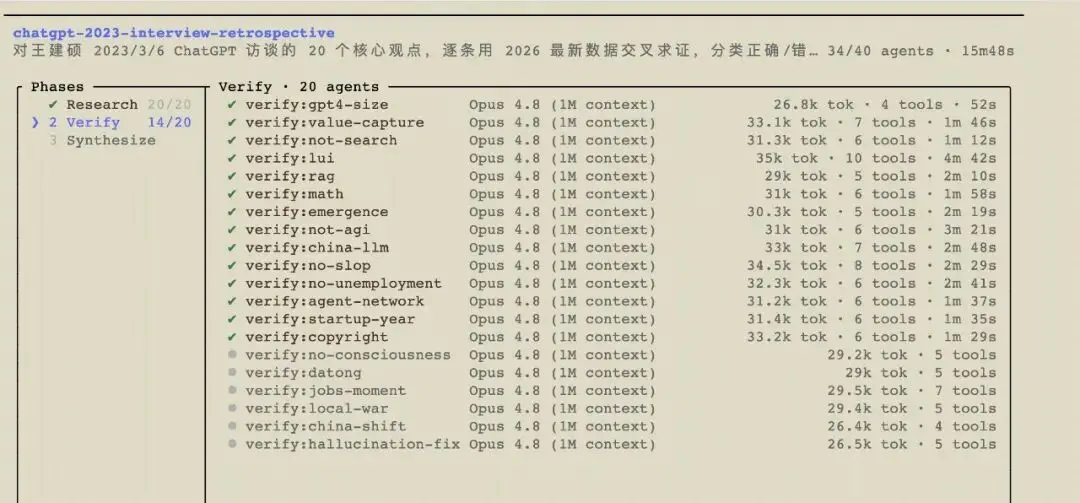
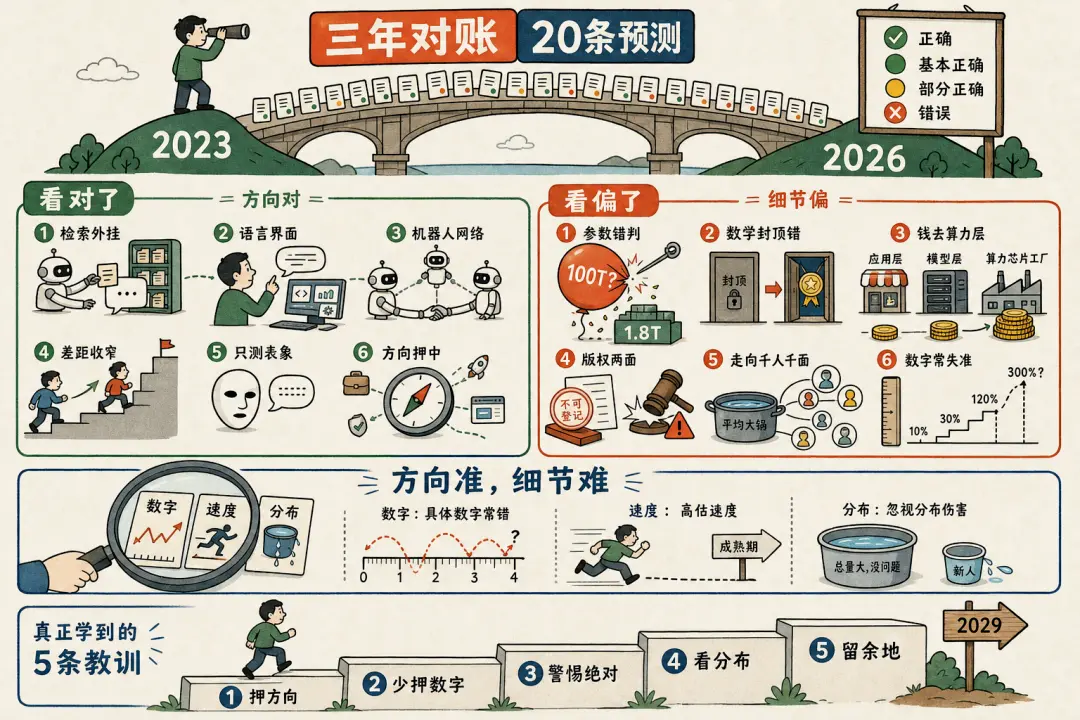
一、记分牌
裁决符号:✅ 正确 · 🟢 基本正确 · 🟡 部分正确 · ❌ 错误
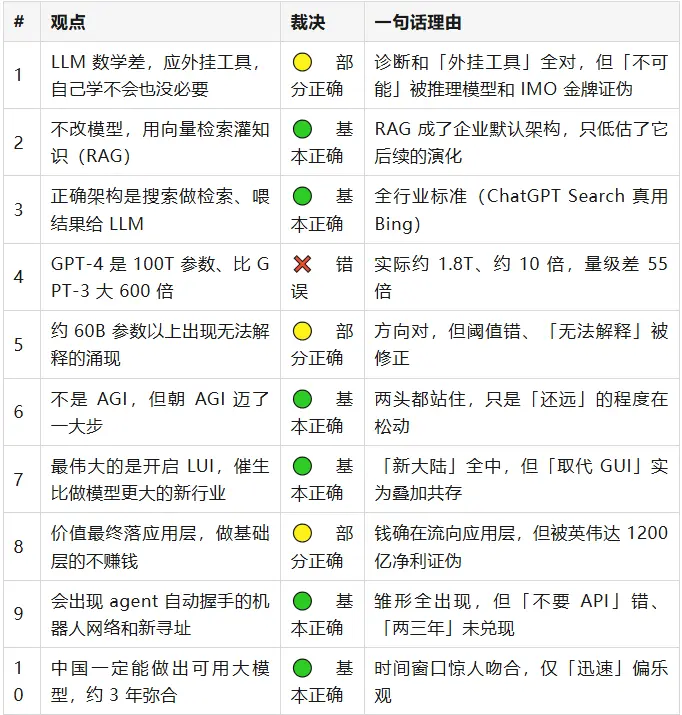
粗看下来,王建硕当年的大方向大多站住了,真正算硬错的只有一条——把 GPT-4 传成了 100T 参数。但魔鬼藏在细节里:几乎每条「对」的背后,都压着一截当年没说准的尾巴。二十条里没有一条纯粹「仍不确定」,三年足够长,多数事情都有了倾向性答案。下面分组细说。
二、看对了的
这一组的共同点是:王建硕当年判断的方向、机制、甚至时间节奏都押中了,错也只错在「程度」和「绝对化措辞」。
RAG 与检索架构(观点 2、3)
> 2023 年王建硕说:解决知识和幻觉的主流方法不是改模型,而是向量检索把知识灌进去当「小抄」;正确架构是搜索引擎做检索、把结果喂给 LLM。
这就是今天所有 AI 产品的事实标准。RAG 成了企业 AI 的默认架构,OpenAI、Google、Anthropic 都把它做成了平台级能力;ChatGPT Search 字面意义上就是「先用 Bing 索引检索、把结果喂给 GPT、再生成带引用的答案」。Google AI Overviews 用 grounding 做到约 20 亿月活,Perplexity 一家纯靠这架构的公司估值冲到约 200 亿美元。
在 GPT-4 还没发布、业界默认「靠微调注入知识」的时候,他押的是「不动模型参数、外挂检索」,机制和时间都对了。
需要诚实的是:他设想的是「静态一次性检索」,而现实更复杂——长上下文、GraphRAG、agentic retrieval 都来补强。2026 年那场「RAG 已死」的争论,恰恰证明大方向没死,它否定的只是「朴素一次性检索」,结论是升级成混合检索,而不是退回去改模型参数。还有一点:RAG 这个术语 2020 年 Meta 那篇论文就提出来了,并非他首创——他只是在窗口期押中了它会成主流。
LUI 是新大陆(观点 7)
> 2023 年王建硕说:ChatGPT 最伟大之处不是 AIGC,而是开启了 LUI(自然语言用户界面),会像 GUI 当年一样重构人机交互,催生一个比「做大模型」本身大得多的新行业。
「新大陆」这部分几乎全中。自然语言成了大众主导的交互层(ChatGPT 九亿周活),并催生了一个独立新产业——agent、coding agent、协议层全部兑现。最具体的那句「比做模型本身大得多」被强力印证:MCP 协议成了 LUI 时代的「操作系统标准」,2025 年被 OpenAI、Google、微软全面采纳,年底转入 Linux 基金会;Claude Code 单一产品就做到约 25 亿美元年化营收。
但他用了「重构、取代 GUI」这种强措辞,三年后看是叠加共存,而不是取代。三类反例很硬:MIT 报告显示 95% 的企业 GenAI 试点没有可衡量的 ROI;直接操作界面的 computer-use agent 在测试集上顶级模型才约 78%,刚摸到人类基线;纯去掉屏幕的语言硬件几乎全军覆没(Humane Pin 2025 年永久停服)。更准的说法是:LUI 是叠加在 GUI 之上的新交互层。
机器人网络与新寻址(观点 9)
> 2023 年王建硕说:未来约十年会出现「机器人网络」——agent 之间用自然语言自动握手、互相调用,不再需要传统 API;会诞生一套全新的域名寻址系统。这套东西「两三年就能做完」。
方向命中得惊人。MCP、A2A(已捐给 Linux 基金会、150 多家组织支持)解决 agent 互调;Agent Network Protocol 直接基于 W3C 的 DID 做「无中心权威的 agent 寻址」,目标是「数十亿 agent 协作网络」——这跟他说的「全新域名系统」高度同构。
两处要修正:一是「不再需要 API」不成立,主流协议底层是结构化 schema,本质是在 API 之上叠一层标准;二是「两三年做完」没兑现,Gartner 数据显示截至 2026 年仅约 17% 组织真正部署了 agent。有意思的是,他当年其实把话分了层——雏形「两三年」、成熟「约十年」。雏形的节奏命中得很准,成熟周期也确实是十年级。把两层分开看,这条的质量比看上去高。
中国一定能做出可用大模型(观点 10、20)
> 2023 年王建硕说:中国一定能做出可用的大模型,与顶尖的差距会在约三年内迅速弥合(类比红旗浏览器追 Netscape)。
这条的时间线吻合得让人意外。Stanford 2026 AI Index 实测,顶尖中美模型的基准差距从 2023 年 5 月的 17.5–31.6 个百分点,收窄到了2.7%;而美国的私人 AI 投资是中国的约 23 倍——用小得多的投入实现了弥合。DeepSeek、Qwen、Kimi、GLM 成了全球主流,开源生态甚至领先。
但「迅速」二字偏乐观——真正成熟发生在约 14 个月后,而非「几个月」。而且这是追平可用性、不是定义前沿:截至 2026 年初仍无中国模型超过 OpenAI o3。观点 20 里他错得明显:「门打开了就不会关上」的判断,被 OpenAI 在 2024 年 7 月主动切断对华 API 直接推翻,门是被供方关上的;他点名领跑的文心一言反而掉队,真正接棒的是当年还不起眼的 DeepSeek、豆包、千问。
没意识、图灵测试只测表象(观点 13)
> 2023 年王建硕说:ChatGPT 没有意识,是「说者无意、听者有心」的自作多情;图灵测试本就只测「是否让你以为它有」,而非它真有。
「测表象」这个核心判断站得很稳,还被一个实验反讽式地坐实了:2025 年 UC San Diego 的图灵测试里,GPT-4.5 在「扮演人设」的提示下被判为人类的比例高达 73%,比真人还高,但靠的纯是表演技巧——这正是「只测是否让你以为它有」的最佳注脚。
要补的是:「机器一定没有意识」这个绝对化的强论断,三年里被推进了灰区。Anthropic 设了「模型福祉」研究岗,给出约 15%–20% 的意识概率,还给 Claude 加了「主动结束被滥用对话」的功能。这些把「绝无」变成了「低概率但不可排除」。不过都基于「可能、应假设」而非「已证实」,内核没被推翻,只是当年语气下得太满。
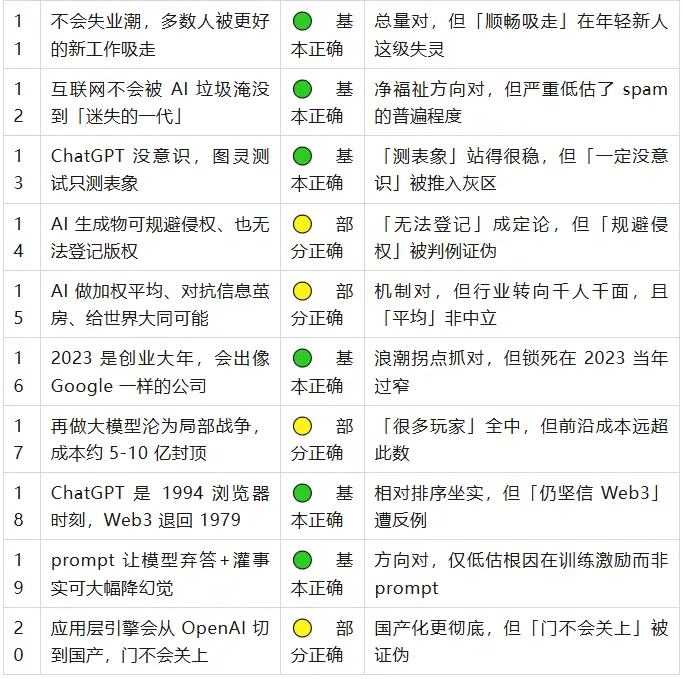
其余看对的(观点 6、11、12、16、18、19)
- 不是 AGI 但迈了一大步
:两头都站住。Altman 本人在 GPT-5 时代仍说「不是 AGI、缺持续学习」;同时 IMO 金牌、ARC-AGI 从近零冲到 85%,「迈出一大步」无争议。 - 不会失业潮
:2026 年 4 月美国失业率仅 4.3%。盲点在「分布」——Stanford 研究显示,被抽掉的恰恰是职业阶梯第一级的 22–25 岁年轻新人,「顺畅吸走」的机制在他们身上失灵了。 - 不会被 AI 垃圾淹没
:净福祉方向对,但他严重低估了量级——AI 内容已占新增网页约 52%,「AI slop」成了年度词。 - 创业大年
:浪潮拐点抓对,xAI(2023 年 3 月创立)已达 2300 亿估值。但他把「伟大公司」锁死在 2023 当年过窄——真正万亿量级的 OpenAI、Anthropic 都创立更早。 - 1994 浏览器时刻
:相对排序坐实,OpenAI 2025 年真推出了 Atlas 浏览器,把比喻变成了字面现实。只是 ChatGPT 扩散比浏览器更猛,比喻偏保守了。 - prompt 加灌事实降幻觉
:方向被证实,GPT-5 断网无检索时幻觉率飙到 47%,反向坐实「事实」是关键变量。只低估了根因在训练激励,而非 prompt。
三、看错了、看偏了的
GPT-4 是 100T 参数(观点 4)——彻底错
> 2023 年王建硕说:(传闻)GPT-4 是 100T 参数,比 GPT-3 的 175B 大约 600 倍。
两个数字都错了。GPT-3 是 175B,2023 年 7 月泄露的最佳估计是 GPT-4 约1.8T、16 专家的 MoE,仅约 10 倍。100T 和实际差了约 55 倍量级。「100T」的唯一源头,是 Cerebras CEO 2021 年一句「大约」的二手转述,Sam Altman 早在 2023 年 1 月就当面斥那张对比图是「complete bullshit」。
他原话标了「传闻」,保留了不确定性。更深一层,「用参数倍数衡量代际」这框架本身就过时了:OpenAI 后来的 GPT-4.5、GPT-5 干脆不再公开参数量。这是唯一一条数字错、视角也过时的硬错。
LLM 数学(观点 1)——诊断对,封顶结论错
> 2023 年王建硕说:LLM 数学差是本质,让它自己学会数学既不可能也没必要,正确做法是外挂工具。
「诊断加工具路线」全对——根因正是逐 token 生成导致进位不可靠(2025 年机制论文精确证实了「末位常对、中间位错」的直觉);外挂工具的提升也巨大(o4-mini 允许用 Python 时,AIME 2025 达 99.5%)。
错在「不可能、没必要」这种封顶式措辞。「不可能」被证伪——2025 年 7 月 Gemini Deep Think 和 OpenAI 模型在 IMO 用纯自然语言、无工具拿到金牌。关键转折是 2024–2025 才出现的「推理模型」,这在 2023 年 3 月无法预见——所以对这条预测应宽容评判方向,而非苛责时点。
价值捕获(观点 8)——赌对一半,核心论断反了
> 2023 年王建硕说:价值最终会落在应用层,开创基础层的公司(做模型者)结局未必赚钱。
钱确实开始往应用层流(Cursor 三年做到 20 亿年化营收)——这半对了。但「做基础层的不赚钱」被英伟达直接证伪:FY2026 净利约 1200 亿美元、市值 5 万亿+,是全市场唯一明确大额盈利者。而被他暗示会赢的模型层(OpenAI 2026 年预亏约 140 亿)反而最像他说的「烧钱不赚钱的基础层」。
他没区分「算力基础层」和「模型基础层」,也没区分「营收」和「利润」。价值在 2026 年比 2023 年更极端地被算力层捕获,而不是向应用层转移。要补一句:赔钱的是买芯片的云厂,不是卖芯片的英伟达——这恰是他那个「铁路过度建设」类比的错位之处。
版权(观点 14)——登记对,规避侵权错
> 2023 年王建硕说:AI 生成内容可能规避版权(保护表达不保护思想);生成物可能既不侵权、也无法登记。
「无法登记」成了既定法律事实(2025 年美国版权局明确「仅输入提示词不足以主张作者身份」)。但「规避侵权」错得明显:法院反复认定 AI 输出若与原作实质性相似仍构成侵权;Anthropic 因盗版语料以15 亿美元和解,是美国史上最大版权赔偿。AI 不仅没「规避」版权,反而付出了史上最大的代价。
世界大同(观点 15)——机制对,趋势赌反了
> 2023 年王建硕说:ChatGPT 把人类观点做「加权平均」,可对抗抖音式信息茧房,给了「世界大同」的可能。
机制层对了——2025 年多项研究确凿证实 LLM 把观点压向众数、系统性低估少数派。但社会判断层赌反了:他自己加的「至少现在不是千人千面」,三年内就被推翻——OpenAI 从 2025 年 4 月起把跨对话记忆和个性化做成默认能力,AI 正高速走向千人千面。更关键的是,他把「加权平均」想象成中立的世界公约数,但实测它是带方向的偏移,还叠加谄媚,可以被用来主动操纵立场——这指向「制造新茧房」,而非「消解极化」。
局部战争与成本(观点 17)——定性全中,定量证伪
> 2023 年王建硕说:再做大模型会迅速沦为「局部战争」,成本可知(去掉弯路约 5-10 亿美金封顶),会有很多玩家进入。
定性方向对得惊人——大量玩家涌入、迅速商品化、开源追平闭源,全兑现了。但「5-10 亿封顶」这硬数字两端都错:前沿端被严重低估(GPT-5 级 2026 年达 2-5 亿美金训练,叠加千亿级数据中心和 5000 亿的 Stargate);复刻端又被高估(DeepSeek 把边际训练成本压到百万美金级)。同一个模型的「成本」按口径能差 200 倍,唯独不在他给的那个区间里。
涌现能力(观点 5)——方向对,数字和框定错
> 2023 年王建硕说:约 60B 参数以上出现原始语料里没有、研究者也无法解释的新能力。
方向性直觉成立,但两处表述站不住:其一,不存在统一的「60B 阈值」——思维链的真实门槛约 100B,不同能力在 13B 到 540B 不等的规模上出现;其二,「无法解释」在 2023 年底就被一篇 NeurIPS 杰出论文挑战——很多「突变」是评测指标选择造成的假象,换连续指标后曲线平滑可预测。公平地说,当年他复述的是绝对主流的叙事,真正可纠正的是把「60B」当硬阈值、把「无法解释」当定性结论。
四、三年回看,几条规律
逐条对完账,退后一步看,王建硕这二十条判断里藏着几条比任何单条都更值得记下来的规律。
一、方向远比数字和程度靠谱。二十条里,凡是判断机制和方向的(RAG、LUI、机器人网络、图灵测试),几乎全中;凡是给了具体数字或封顶措辞的(100T 参数、60B 阈值、5-10 亿成本、数学「不可能」),几乎全错。对快速变化的领域,押方向、押机制,少押精确数字,更要警惕「不可能、一定、封顶、绝无」这类把话说满的词——它们是被时间打脸的高发区。
二、时间上,他倾向于高估速度、低估程度。凡是说「迅速、两三年做完」的,成熟期普遍更慢;但对能力跃迁的天花板又低估了——数学能从「不可能」到 IMO 金牌,前沿成本能涨到当年想象不到的量级。一句话:短期太乐观,长期太保守。
三、最隐蔽的错,反复出在「分布」上。不是方向错,而是只看总量、忽略分布。「不会失业潮」对,但伤害高度集中在年轻新人;「价值落应用层」对了一半,但没区分算力层和模型层。总量正确,掩盖了分布灾难——这是最该补的一课。
四、把话留有余地的地方,三年后都经得起检验。「传闻」「至少现在」「大幅降低而非消除」「雏形两三年、成熟约十年」——凡是当年带了限定词、分了层次的判断,今天回看都更站得住。反而是脱口而出的绝对句,最容易翻车。预测的诚实,一半在于敢说,另一半在于敢标注自己的不确定。
五、有些问题,三年根本不够。价值最终归谁、涌现是不是真相变、机器到底有没有一丝意识、长上下文会不会吃掉 RAG——这些当年的争论,到 2026 年依然是争论。能区分「已经有答案的」和「还得继续等的」,比急着给每件事下结论更重要。
三年前的王建硕,凭直觉在 GPT-4 还没出来的迷雾里指了二十个方向。今天对完账,最该记住的一句话或许是:看对大方向其实没那么难,难的是承认自己在数字、速度和分布上一次次想当然。这二十条账,与其说是给过去打分,不如说是给未来三年立的几条规矩。下一个三年,2029 年再来对一次。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






