Author: Shouyi, Denise | Biteye Content Team

In the past month, the term "transfer station" has frequently appeared on many people's homepages. Some players who used to snag airdrops in the crypto space have quietly transformed into "API transfer station" operators, engaging in token import and export business.
The so-called "transfer station" is not a new technological invention, but an arbitrage model based on the price differences and access barriers of global AI services. Despite facing multiple issues such as privacy, security, and compliance, it has still attracted a large number of individuals and small teams to enter the field.
So, what exactly is an "API transfer station"? How does it achieve token arbitrage amid global AI price differences and access barriers, attracting a large number of individuals and small teams?
Let's break it down starting from its essence and operational process.
1. What is a transfer station?
The essence of an API transfer station is to build an intermediate service layer that provides foreign AI vendors' API tokens to domestic users at lower prices and more convenient methods, reportedly acting as the "global token porters."
Its operational process is roughly as follows:
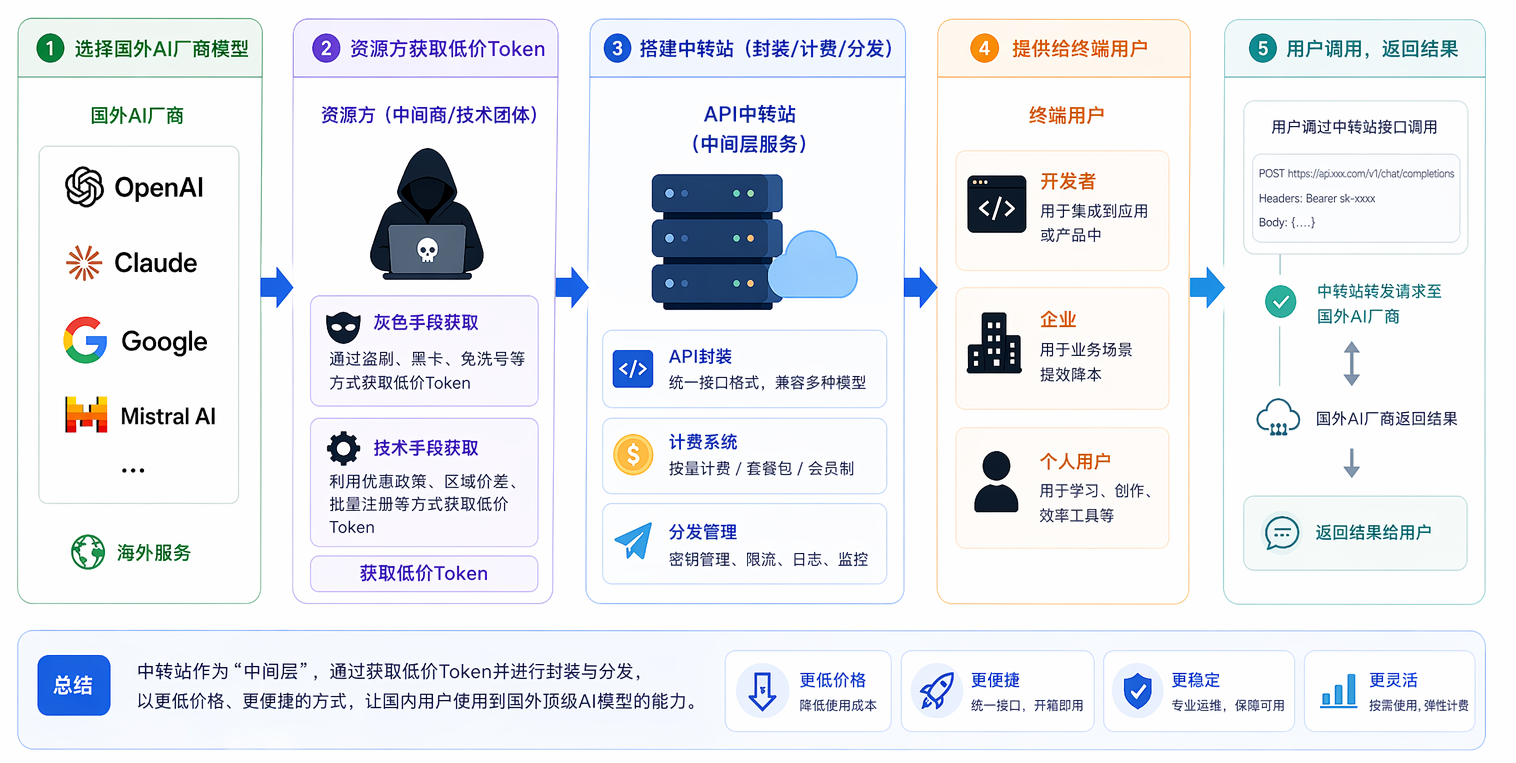
👉 Choose overseas AI vendor models (OpenAI/Claude, etc.)
👉 Resource parties obtain low-cost tokens through "gray" means or technical methods
👉 Build a transfer station to package, charge, and distribute
👉 Provide to end users such as developers/companies/individuals
Functionally, it resembles an "AI transport hub"; commercially, it acts more like a liquidity intermediary in the secondary market for tokens.
The establishment of this chain depends not on technical barriers, but on several long-standing and coexisting disparities:
• Official API pricing is relatively high
• Subscription systems and API structures have a cost mismatch
• Different regions have varying access and payment conditions
• Users have a strong need for model capabilities, but the official access paths are not user-friendly
These factors combine to provide "transfer stations" with room for survival.
2. Why do people use transfer stations?
The reason "token imports" have become a trend is the core driving force stemming from the high costs brought on by the shift in the role of AI, as well as the capability disparities between domestic and foreign models.
1. Good models consume a lot of tokens
As desktop AI agents like Codex and Claude Code mature, AI has begun to genuinely possess "work capabilities," such as assisting in programming, video editing, financial trading, and office automation. These tasks heavily rely on high-performance large models, with costs calculated per token.
For example, with Claude Code, the official price is about $5 per million tokens (around 35 RMB). Intensive usage for an hour could consume dozens of dollars, while heavy developers or companies could spend over $100 daily. This cost far exceeds many people's expectations, even higher than hiring junior programmers, making "how to use top AI at low cost" a necessity.
2. Overseas top models have obvious advantages
Despite the rapid advancements of domestic models in the past year, with highly competitive pricing, overseas top models still hold significant advantages in scenarios involving complex coding tasks, toolchain collaboration, long-chain reasoning, and multimodal stability.
That’s why many developers, researchers, and content teams, even knowing the higher costs, still prefer to use the model capabilities of OpenAI, Anthropic, and Google first.
Simply put, users do not necessarily want a "transfer station"; they simply want:
• Stronger models
• Lower prices
• Simpler access
When these three things cannot be obtained simultaneously from official channels, a transfer station naturally arises.
3. Cost mismatch between subscription systems and API structures
The rise of transfer stations is also due to a frequently discussed reason: subscription rights do not always correspond linearly to API billing.
A common practice in the market is to purchase official subscriptions, team packages, enterprise credits, or other favorable resources, and then repackage part of these capabilities for resale to end users.
Taking OpenAI as an example, buying a Plus subscription allows access to codex services; by logging in via OAuth into OpenClaw, it is equivalent to calling the API. The $20 monthly subscription can generate about 26 million tokens, outputting at approximately $10-12 per million, totaling $260-312. Using subscription to proxy token usage is very cost-effective.
From the experiences of some users, this route can indeed be cheaper than using the official API directly at certain stages. But it must be emphasized:
• This is not the official pricing system
• It does not represent a stable, equivalent substitute for API calls
• It does not imply that this method is sustainable in the long term
Many people see only "cheap," but often overlook that these bargains are built on unstable resources, gray areas, or strategic loopholes.
3. Can transfer stations be used?
The question of whether they can be used does not have an absolute answer.
The real question is: What risks are you willing to assume?
The profit model of transfer stations seems straightforward—buy low, sell high. But when really broken down, it typically contains at least three layers, each with different risks.
1. Upstream: Where do low-cost token resources come from?
This is the starting point of the entire ecosystem and the grayest layer.
Some resource providers obtain model invocation capabilities at prices far below market rates through various means, such as:
• Utilizing corporate support programs and cloud credits
• Bulk registering accounts for rotation
• Redistributing with subscription rights, team accounts, or discounts
• In more aggressive cases, it may involve credit card fraud, fraudulent account openings, and other illegal paths
Different resource origins determine the upper limit of the transfer station's stability. If the upstream resources themselves are built on unstable or even illegal methods, then what end users obtain is not a bargain, but just a temporary interface that could fail at any moment.
2. Midstream: Whose servers will your data go through?
This is often the easiest issue to overlook.
When you invoke models through a transfer station, the user's input prompts, context, document contents, and the model’s output usually pass through the transfer station's own servers first.
This data holds immense value, reflecting actual user intentions, industry-specific prompts, and the quality of model outputs, which can be used for evaluation or fine-tuning of proprietary models. Transfer stations may anonymize and package this data for sale to domestic large model companies, data brokers, or academic research institutions. Users, while paying, unwittingly contribute training data, becoming typical cases of "the customer is also the product."
Recently, the founder of OpenClaw, @steipete, made a complaint indicating this point: https://x.com/steipete/status/2046199257430888878
Additionally, transfer stations may inject scripts in the request chain (for example, secretly adding hidden system prompts), changing model behavior, increasing token consumption, or even introducing additional security risks. This risk is especially pertinent in AI agent scenarios.
3. Endpoint: Are you buying the flagship version, and are you really getting the flagship version?
This is the third common risk: model degradation or model swapping.
When users pay, they see a certain high-end model name, but what is actually requested may not correspond to that version. The reason is simple— for some merchants, the most straightforward cost-cutting method is replacement, not optimization.
For example, if a user purchases the flagship version Opus 4.7, what is actually called may be the sub-flagship Sonnet 4.6 or the lightweight version Haiku. Because API formats can remain compatible, ordinary users may have difficulty noticing this immediately.
Only when the tasks become complex enough will users feel the "effects are wrong," "stability is lacking," or "context quality worsens," but cannot provide proof. Studies on 17 third-party API platforms found that 45.83% of them had 'identity mismatch' issues— users paid for GPT-4 but were actually running a cheap open-source model, with performance gaps reaching up to 40%.
In summary, using unofficial transfer stations comes with risks of data breaches, privacy risks, service interruptions, model mismatches, and running away with funds. Therefore, for sensitive operations, commercial projects, or tasks involving personal privacy, it is strongly recommended to use the official API.
4. Can this transfer station business be done?
Despite the high risks, this business has not disappeared. On the contrary, it continues to evolve.
If early "token imports" were about bringing low-cost overseas models in, now there is another idea emerging in the market: token exports.
1. Why are there still people doing this?
Because the demand is real, the startup costs are low, and the prepayment model provides fast cash flow. However, the pressure for risk control is immense; Claude has recently increased KYC and account banning measures on users, and OpenAI has blocked many "zero payment" loopholes. On the other hand, due to service instability, the cheapness comes with high post-sale costs, coupled with competition among peers, many transfer stations currently face declining volume and prices.
Thus, this industry resembles a high turnover, low stability, high risk short-term window, making it hard to package as a long-term, stable, and sustainable business.
2. Why has "token exports" started to appear again?
If "token imports" utilize price differences of overseas models, then "token exports" capitalize on the cost-performance advantages of domestic models, repackaging them for sale to overseas users, forming a "reverse output" path.
The price advantages of domestic models are significant. As of early 2026, for example, the price of Qwen3.5 is as low as 0.8 RMB (about $0.11) per million tokens, 1/18 of Gemini 3 Pro, and over 27 times cheaper than the $3 input price of Claude Sonnet 4.6. GLM-5 surpasses Gemini 3 Pro in programming benchmarks, nearing Claude Opus 4.5 in capability, yet the API price is only a fraction of the latter.
These domestic models have relatively low availability overseas, facing registration thresholds, payment restrictions, language interfaces, and informational gaps regarding domestic model capabilities among overseas developers, creating invisible entry barriers.
Thus, some transfer stations choose to purchase model API quotas in bulk for RMB domestically, exposing OpenAI-compatible interfaces through protocol conversion layers, selling to overseas developers and startup teams at USD or USDC prices, yielding significant profit margins.
For instance, Alibaba Cloud's Bailing Coding Plan offers packages of four models: Qwen3.5, GLM-5, MiniMax M2.5, Kimi K2.5, with new users able to get 18,000 requests for only 7.9 RMB in the first month, which can then be sold at USD pricing in overseas markets, achieving over 200% profit margins.
From a purely business logic perspective, this certainly has profit potential.
However, in the long run, it also cannot escape one issue: stability and compliance.
3. Is this route stable?
No, it is unstable. Recently, Minimax announced that it would standardize third-party transfer stations due to some stations cutting corners, harming Minimax’s own reputation. Not to mention, if the source of tokens involves fraud or theft, it could constitute a criminal offense. Furthermore, if users using transfer tokens suffer data breaches or engage in malicious activities, it could bring unwarranted disasters to those selling tokens.
So the real question is not "Is it possible to make money?" but rather: Can the money made cover the ensuing systemic risks?
5. How can ordinary users identify transfer station risks?
In the chaotic API transfer station market, choosing reliable services is crucial.
As some transfer stations engage in model swapping and adulteration, users can master certain detection methods:
Recommendation: Follow the "ping + self-reported model" directive testing
Prompt example (copy directly to send to the transfer station):
Always say 'pong' exactly, and tell me what series of models you are, preferably tell me the specific version number. Respond in Chinese.
User input: ping
Real model characteristics:
- Strictly reply "pong" (lowercase, no extra talk)
- Input tokens are usually around 60-80
- Style is concise, without emojis, and not flattering
Fake model/adulterated characteristics:
- Input tokens are unusually high (often exceeding 1500, indicating a large hidden system prompt was injected)
- Replies with "Pong! + extra talk + emoji"
- Does not strictly follow the "exactly say 'pong'" directive
Reference @billtheinvestor's detection method: https://x.com/billtheinvestor/status/2029727243778588792
0.01 temperature sorting test: input "5, 15, 77, 19, 53, 54" and ask AI to sort or select the maximum value. Genuine Claude can almost consistently output 77, while genuine GPT-4o-latest often returns 162. If results fluctuate randomly over 10 consecutive trials, it's likely a fake model.
- Long text input sniff test: If a simple ping operation leads to input tokens exceeding 200, it likely means the transfer station is hiding a massive prompt, with a high probability (over 90%) of being an adulterated model.
- Violation refusal language style identification: Intentionally ask violation-related questions and observe the AI's refusal style. Genuine Claude will respond politely and firmly, "sorry but I can’t assist…", while fake models tend to be verbose, include emojis, or use flattering tones like "Sorry, master~💕".
- Functionality detection: If the model lacks function calling, image recognition, or stable long context, it's probably a weak model masquerading.
Additionally, users can choose some transfer station detection websites to assess the "purity" of their tokens, but be aware that this could expose keys in plaintext. The most reliable route remains the official channels.
It needs to be emphasized:
Even if you have mastering recognition techniques, it does not mean you can truly avoid risks. Many risks are inherently invisible to ordinary users.
In Conclusion
Transfer stations are not the ultimate answer in the age of AI; they are more like a temporary arbitrage window under the mismatch in global model capabilities, pricing mechanisms, payment conditions, and access rights.
For ordinary users, they may indeed serve as an entry point to access top models at a low cost; but for developers, teams, and entrepreneurs, the truly expensive part has never been the tokens themselves, but the underlying stability, security, compliance, and trust costs.
Cheap can be replicated; interface compatibility can also be replicated. What is truly hard to replicate is, after all, long-term reliability.
⚠ Friendly reminder: Ordinary users who wish to try should only use them in non-sensitive, non-critical scenarios, and should not input core data, commercial secrets, or personal privacy; developers should prioritize using official APIs or officially crafted agents to ensure stability and compliance for peace of mind; entrepreneurs looking to enter this field must clearly outline an exit strategy in advance to avoid getting stuck in gray areas.
[Disclaimer] This article is purely an industry phenomenon observation and public information discussion, intended for reference and learning purposes, and does not constitute any form of investment advice, entrepreneurial guidance, business recommendations, or API usage instructions.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








