Author: Deep Tide TechFlow
A paper from Google claiming to "compress AI memory usage to 1/6" triggered a market evaporation of over $90 billion in global storage chip stocks like Micron and SanDisk last week.
However, just two days after the paper was published, the postdoctoral researcher Gao Jianyang from ETH Zurich released an open letter accusing the Google team of testing its competitors with a Python script on a single-core CPU while testing itself with an A100 GPU, and of refusing to correct the issue after being informed before submission. The views reached over 4 million on Zhihu, with the Stanford NLP official account retweeting, shaking both academia and the market.
(For reference: A paper that knocked down storage stocks)
The core question of this controversy is not complex: Did a paper heavily promoted by Google, which directly triggered a panic sell-off in the global chip sector, systematically distort an already published prior work and craft a false performance advantage narrative through deliberately unfair experiments?
What TurboQuant Did: Compressed AI's "Draft Paper" to One-Sixth of Its Original Size
When generating answers, large language models need to write while looking back at previously computed content. These intermediate results are temporarily stored in the GPU memory, known in the industry as "KV Cache" (key-value cache). The longer the conversation, the thicker this "draft paper" becomes, leading to greater memory usage and higher costs.
The core selling point of the TurboQuant algorithm developed by Google's research team is that it compresses this draft paper to one-sixth of its original size, claiming zero loss in accuracy and the highest improvement in inference speed of up to 8 times. The paper was first published on the academic preprint platform arXiv in April 2025, accepted by the top conference ICLR 2026 in January 2026, and repackaged and promoted by Google's official blog on March 24.
Technically, the idea of TurboQuant can be understood simply as: first use a mathematical transformation to "clean" the messy data into a uniform format, then compress it using a pre-computed optimal compression table, and finally correct the computational biases introduced by the compression using a 1-bit error correction mechanism. The independent implementation by the community has verified that its compression effect is basically valid, and the mathematical contributions at the algorithm level are genuinely existent.
The controversy lies not in whether TurboQuant can be used, but in what Google did to prove that it "far surpasses its competitors."
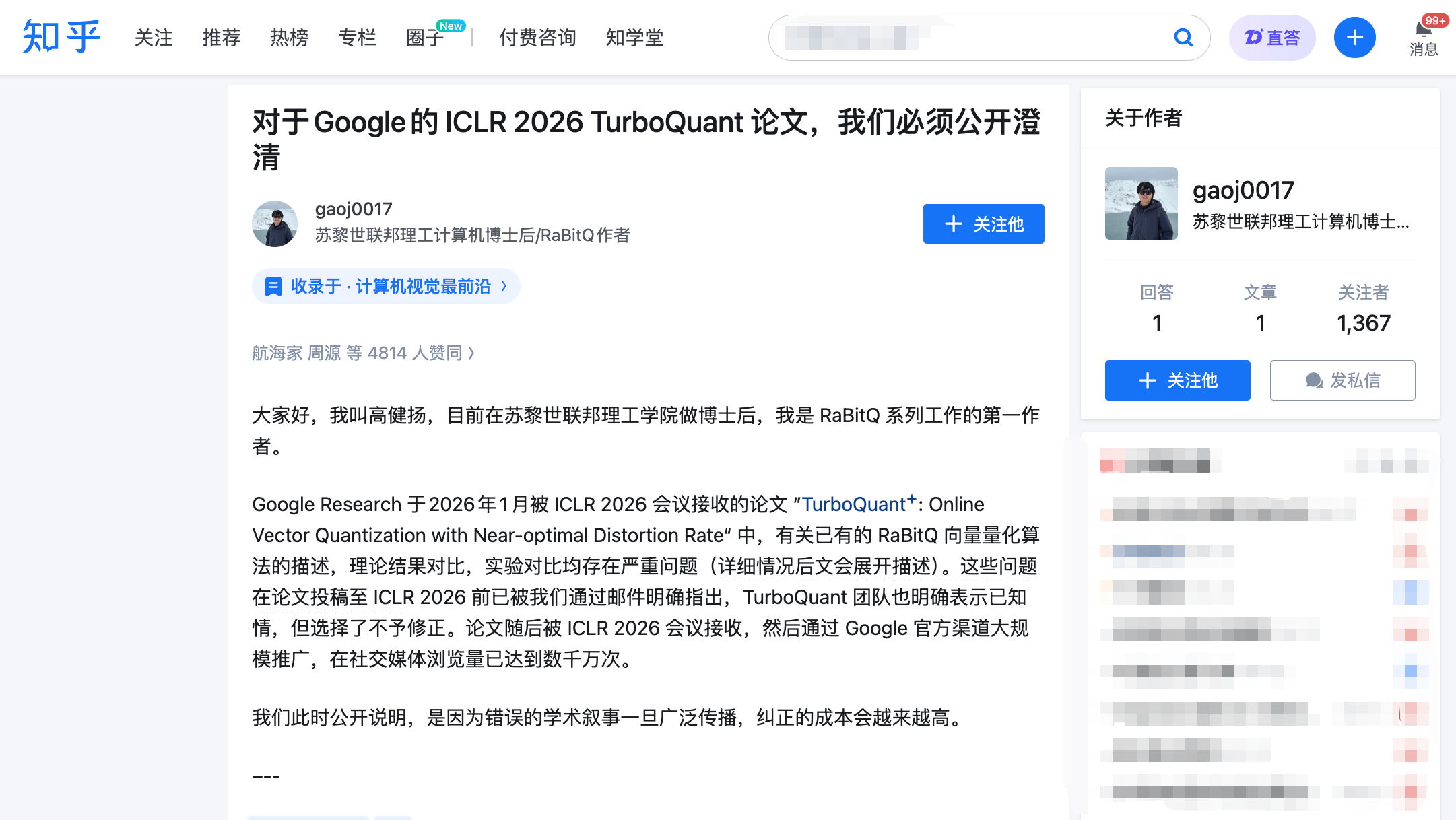
Gao Jianyang's Open Letter: Three Accusations, Each Hit the Mark
At 10 PM on March 27, Gao Jianyang published a long article on Zhihu, simultaneously submitting a formal comment on the ICLR official review platform OpenReview. Gao Jianyang is the first author of the RaBitQ algorithm, which was published in the top conference SIGMOD in 2024, addressing the same class of problems—efficient compression of high-dimensional vectors.
His accusations are divided into three points, each backed by email records and timelines.
Accusation One: Used Others' Core Method Without Mentioning It.
The technical core of TurboQuant and RaBitQ shares a crucial common step: before compressing the data, they both perform a "random rotation." This operation's purpose is to transform irregularly distributed data into a predictable uniform distribution, thereby significantly lowering the difficulty of compression. This is the closest and most core part of the two algorithms.
The authors of TurboQuant themselves acknowledged this point in their review replies but have never explicitly stated the relationship between this method and RaBitQ in the full paper. A more critical background is that the second author of TurboQuant, Majid Daliri, proactively contacted Gao Jianyang's team in January 2025, requesting help debugging his Python version rewritten from RaBitQ's source code. The email detailed the reproduction steps and error messages—in other words, the TurboQuant team was very familiar with RaBitQ's technical details.
An anonymous reviewer for ICLR also independently pointed out that both used the same technique, requesting sufficient discussion. However, in the final version of the paper, the TurboQuant team not only failed to add the discussion but also moved the already incomplete description of RaBitQ from the main text to the appendix.
Accusation Two: Unsupported Claims of "Suboptimal" Theory.
The TurboQuant paper directly labeled RaBitQ as "theoretically suboptimal" (suboptimal), claiming that RaBitQ's mathematical analysis was "rather crude." However, Gao Jianyang pointed out that the extended version of RaBitQ has strictly proven that its compression error achieves the optimal bounds mathematically—this conclusion was published at a top conference in theoretical computer science.
In May 2025, Gao Jianyang's team detailed through several rounds of emails the optimality of the RaBitQ theory. TurboQuant's second author Daliri confirmed that it had been communicated to all authors. Nevertheless, the paper ultimately retained the "suboptimal" statement without providing any counterarguments.
Accusation Three: "Hands Tied on the Left, Knife in Hand on the Right" in Experimental Comparisons.
This is the most damaging point in the entire paper. Gao Jianyang pointed out that the TurboQuant paper imposed two layers of unfair conditions in its speed comparison experiments:
First, RaBitQ officially provided optimized C++ code (which supports multi-threaded parallelism by default), but the TurboQuant team did not use it, instead testing RaBitQ with their own translated Python version. Second, the RaBitQ test was conducted on a single-core CPU with multi-threading disabled, while TurboQuant used an NVIDIA A100 GPU.
The combined effect of these two conditions is that readers see the conclusion that "RaBitQ is several orders of magnitude slower than TurboQuant" without knowing that the premise of this conclusion was that Google's team tied up their opponent before the race. The differences in these experimental conditions were not adequately disclosed in the paper.
Google's Response: "Random Rotation is a General Technique, We Can't Refer to Every Instance."
According to Gao Jianyang, the TurboQuant team stated in a March 2026 email response: "The use of random rotation and Johnson-Lindenstrauss transformation has become standard technology in the field; we can't reference every paper that has used these methods."
The Gao Jianyang team argues that this is a misrepresentation: the issue is not about referencing all papers that used random rotation, but rather that RaBitQ is the first work to combine this method with vector compression under exactly the same problem settings and prove its optimality; thus, the TurboQuant paper should accurately describe the relationship between the two.
The official X account of the Stanford NLP Group retweeted Gao Jianyang's statement. The Gao Jianyang team has published a public comment on the ICLR OpenReview platform and submitted a formal complaint to the ICLR conference chair and ethics committee, with a detailed technical report to follow on arXiv.
Independent tech blogger Dario Salvati provided a relatively neutral assessment in his analysis: TurboQuant does indeed have real contributions in mathematical methods, but its relationship with RaBitQ is much closer than stated in the paper.
$90 Billion Market Value Evaporation: A Combination of Paper Controversy and Market Panic
The timing of this academic controversy is particularly delicate. Following the official blog release of TurboQuant on March 24, the global storage chip sector faced a fierce sell-off. According to reports from CNBC and other media outlets, Micron Technology declined for six consecutive trading days, with a cumulative drop of over 20%; SanDisk had a single-day drop of 11%; Korean SK Hynix fell about 6%, Samsung Electronics dropped nearly 5%, and Japan's Kioxia fell about 6%. The market panic logic is brutally simple: if software compression can reduce AI inference memory needs by six times, the demand outlook for storage chips will be structurally downgraded.
Morgan Stanley analyst Joseph Moore refuted this logic in a research report on March 26, maintaining "overweight" ratings for Micron and SanDisk. Moore pointed out that TurboQuant only compresses this specific type of KV Cache, not the overall memory usage, categorizing it as "normal productivity improvement." Wells Fargo analyst Andrew Rocha similarly cited Jevons' Paradox, arguing that efficiency improvements leading to reduced costs may actually stimulate larger-scale AI deployments, ultimately increasing memory demand.
Old Paper, New Packaging: The Risk of the Transmission Chain from AI Research to Market Narrative
According to tech blogger Ben Pouladian's analysis, the TurboQuant paper was publicly released in April 2025, not new research. On March 24, Google repackaged and promoted it through the official blog, but the market treated it as a breakthrough and priced it accordingly. This "old paper, new release" promotional strategy, coupled with potential experimental biases present in the paper, reflects systemic risks in the transmission chain from academic papers to market narratives in AI research.
For investors in AI infrastructure, when a paper claims to achieve "several orders of magnitude" in performance improvement, the first question to ask is whether the conditions of the benchmark comparison are fair.
The Gao Jianyang team has clearly stated that they will continue to push for a formal resolution of the issues. Google has yet to officially respond to the specific allegations in the open letter.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。









