在本报告中,我们对 Saturn 的日志检测模块进行了深入分析。这是 Saturn 的组件,负责检测节点运营商提交的任何篡改或虚假日志。因此,它可以作为防止作弊和随之而来的分配不当奖励的保护层。
动机
作为一个去中心化的内容分发网络 (CDN),Saturn 依赖于自愿的运营商节点的参与。任何拥有足够好的硬件资源的人都可以免费加入,为 Saturn 的服务做出贡献,并作为回报获得一些奖励。土星的奖励取决于三个主要数据来源:
Saturn 的协调器模块:一种集中式服务,它将向其他操作员节点发出测试请求,以衡量它们在下载速度和正常运行时间方面的性能。
操作员节点:每次操作员节点处理请求时,它们都会记录请求(连同一些相关的统计信息)并将其发送到编排器。
客户网站:使用 Saturn 加速其在线分发的内容发布者将在其应用程序中运行 Saturn 代码,该代码将记录每个访问其内容的用户的指标。请注意,此数据仅在 Saturn 将客户端接入网络后可用。
由于内容交付的去信任验证没有可行的解决方案,我们不能假设 Saturn 从其运营商节点接收的数据是正确的。这些日志可以被篡改,方法是破解 Saturn 的代码直接编辑日志,或者使用机器人发出“虚假”请求。
如果我们没有适当的检测系统(连同检测时的惩罚),“流氓”节点将有明显的动机欺骗系统并从其他诚实的参与者那里窃取奖励。因此,Saturn 的日志检测模块旨在通过查找和标记节点运营商提交的篡改或虚假日志来解决此问题。
在编排器和客户端网站方面也有攻击媒介。例如,客户网站可以谎报所服务的请求,以减少他们为 Saturn 服务支付的费用,而节点运营商可以通过以不同于真实用户的方式向编排器回答他们对编排器的感知性能。然而,这些攻击媒介并不是第一版 Saturn 的主要关注点,因此,它们将在以后的版本中得到解决。
设计概览
当我们谈论可疑行为时,我们可以在两个不同的级别上检测到它:
请求级别:我们查看单个日志的级别,对应于检测看起来不合法的特定请求。这里的一个例子是一个持续时间快得令人难以置信的请求。在此级别,我们筛选来自日志服务的所有个人请求,并标记任何看起来可疑的请求。输出是标记请求的列表及其标记的来源。
操作员级别:我们不查明看起来可疑的特定日志的级别,而是查看各个节点操作员的一般行为。这里的一个例子是一个操作员记录了不可能的大量请求。在此级别,我们汇总了每个操作员的原始日志,并标记了任何看起来可疑的日志。输出是标记节点的列表及其标记的来源。
这两个级别都很重要,并且会给出对基础数据的不同看法。这不是哪个级别更好的问题。相反,我们将在两个级别并行进行检测。
另一个考虑因素是我们计划使用的检测技术。由于检测模块的初始版本必须在 Saturn 拥有真正的活跃用户之前设计,我们从一个简单的基于启发式的检测系统开始,根据关于用户将如何使用 Saturn 和我们已有的测试数据进行操作的合理假设进行调整。下一节将更详细地介绍这些启发式方法。
在 Saturn 发射并收集到更多数据后,我们计划通过改进启发式算法和试验更复杂的检测方法(例如异常检测模型、监督模型和主动学习模型)来迭代这个简单的系统。
除了这种基于行为的检测方法外,还可以通过交叉检查市场两侧的数据来进行检测。一旦 Saturn 开始将内容发布者加入网络(他们将为服务付费),我们就可以使用这些客户提交的日志来交叉检查节点运营商提供的日志。任何一方都没有动机串通欺骗网络,因为一方总是会支付另一方的报酬。但是,由于 Saturn 还没有客户端,因此该方法在第一版系统中将不可用。
启发式
启发式被定义为对我们试图避免的特定行为进行编码的简单规则。在本模块中,我们将对前面描述的两个级别(请求和运算符)进行试探。
下表描述了建议包含在检测系统中的所有启发式方法,并突出显示了每种启发式方法的推理。需要注意的是,这是第一个提案,随着项目的成熟,它可能会发生变化。
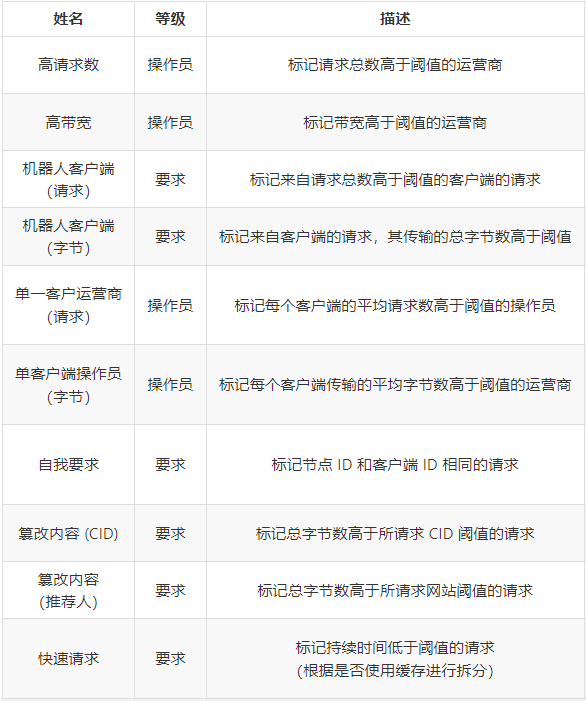

几乎所有提出的启发式方法都有一个需要设置或调整的阈值。这个阈值取决于我们正在比较的单个指标。例如,在快速请求启发式中,指标是请求持续时间。
我们可以将此问题解释为对单变量异常的搜索。在快速请求启发式的情况下,我们感兴趣的是对于“正常”数据分布而言太低的数据点。在这里,阈值是我们认为数据点“异常”的点。
在本文档中,我们不共享每个启发式的最终阈值。如果我们这样做了,启发式算法将很容易被欺骗!相反,我们讨论达到最终阈值的过程。特别是,我们使用两种不同的方法,即:
专家判断:这里我们使用我们对 Saturn 和真实请求如何工作的知识来设置阈值。这主要用于我们可以轻松定义什么是不可能的启发式方法。
统计异常值:这里我们使用 Saturn 测试版本的数据来模拟基础指标的统计分布。因此,我们假设数据遵循已知分布并且它将代表未来的请求。此测试版本使用内部节点运行,这意味着来自真实用户的观察指标可能略有不同。然而,这是我们目前拥有的最佳近似值。一旦我们有了度量的分布,我们就将拟合分布的百分位数 99.999 或 0.0001 (1/10000) 设置为阈值候选。
需要注意的是,在统计离群值方法中,我们测试了scipy中的所有连续分布,并选择残差平方和 (SSR) 最低的分布。
此外,在某些启发式算法中,我们没有足够的数据来适应分布(即两个篡改的内容启发式算法)。在这些情况下,我们假设服从高斯分布并使用正态分布的经典阈值 - μ+4σ。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







