DeepSeek,这家中国人工智能实验室最近颠覆了行业对行业发展成本的假设,发布了一系列新的开源多模态AI模型, reportedly 在关键基准测试中超越了OpenAI的DALL-E 3。
被称为Janus Pro,该模型参数范围从10亿(极小)到70亿(接近SD 3.5L的大小),并可在机器学习和数据科学中心Huggingface上立即下载。
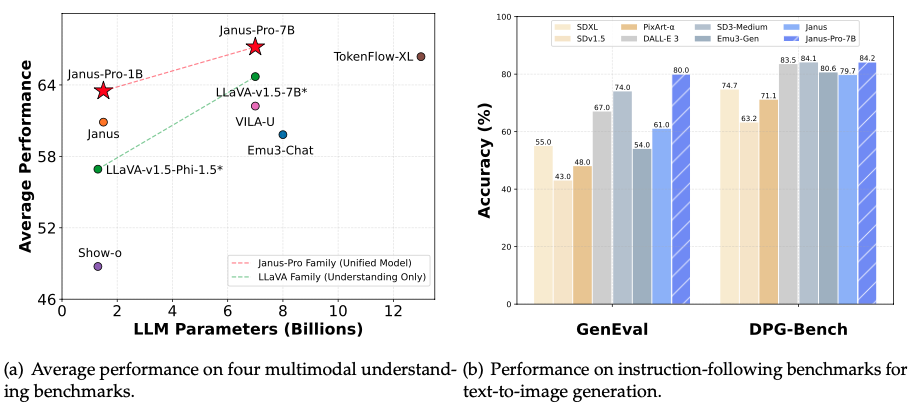
根据DeepSeek AI分享的信息,最大的版本Janus Pro 7B不仅超越了OpenAI的DALL-E 3,还在行业基准GenEval和DPG-Bench上击败了其他领先模型,如PixArt-alpha、Emu3-Gen和SDXL。
图片:DeepSeek AI
其发布恰逢DeepSeek因其R1语言模型而登上头条,该模型的能力与GPT-4相匹配,而开发成本仅为500万美元——引发了激烈的辩论,关于当前AI行业的状态。
这家中国初创公司的产品还引发了行业的广泛担忧,可能会颠覆现有企业,并影响主要芯片制造商Nvidia的增长轨迹,后者在周一遭遇了历史上最大单日市值损失。
DeepSeek的Janus Pro模型使用了公司所称的“新型自回归框架”,将视觉编码解耦为独立的路径,同时保持单一的统一变换器架构。
这种设计使模型能够分析图像并生成768x768分辨率的图像。
“Janus Pro超越了之前的统一模型,并在性能上与任务特定模型相匹配或超越,”DeepSeek在其发布文档中声称。“Janus Pro的简单性、高灵活性和有效性使其成为下一代统一多模态模型的强有力候选者。”
与DeepSeek R1不同,该公司没有发布该模型的完整白皮书,但发布了其技术文档,并made the model available for immediate download free of charge——继续其开源发布的做法,这与美国科技巨头的封闭专有方法形成鲜明对比。
那么,我们的评判是什么呢?好吧,这个模型非常多才多艺。
然而,不要指望它能取代你所喜爱的任何最专业的模型。它可以生成文本、分析图像和生成照片,但与那些只擅长其中一项的模型相比,充其量也只是平起平坐。
测试模型
请注意,目前没有传统用户界面可以运行它——Comfy、A1111、Focus和Draw Things目前不兼容。这意味着在本地运行该模型有点不切实际,需要通过终端中的文本命令进行操作。
然而,一些Huggingface用户创建了空间来尝试该模型。DeepSeek的官方空间不可用,因此我们建议使用NeuroSenko的免费空间来尝试Janus 7b。
请注意您的操作,因为某些标题可能会误导。例如,由AP123管理的空间声称它运行Janus Pro 7b,但实际上运行的是Janus Pro 1.5b——这可能会让您在测试模型时浪费大量的空闲时间并得到糟糕的结果。相信我们:我们知道,因为这也发生在我们身上。
视觉理解
该模型在视觉理解方面表现良好,能够准确描述照片中的元素。
它展现了良好的空间意识以及不同物体之间的关系。
它的准确性也超过了LlaVa——最受欢迎的开源视觉模型——能够提供更准确的场景描述,并根据视觉提示与用户进行互动。
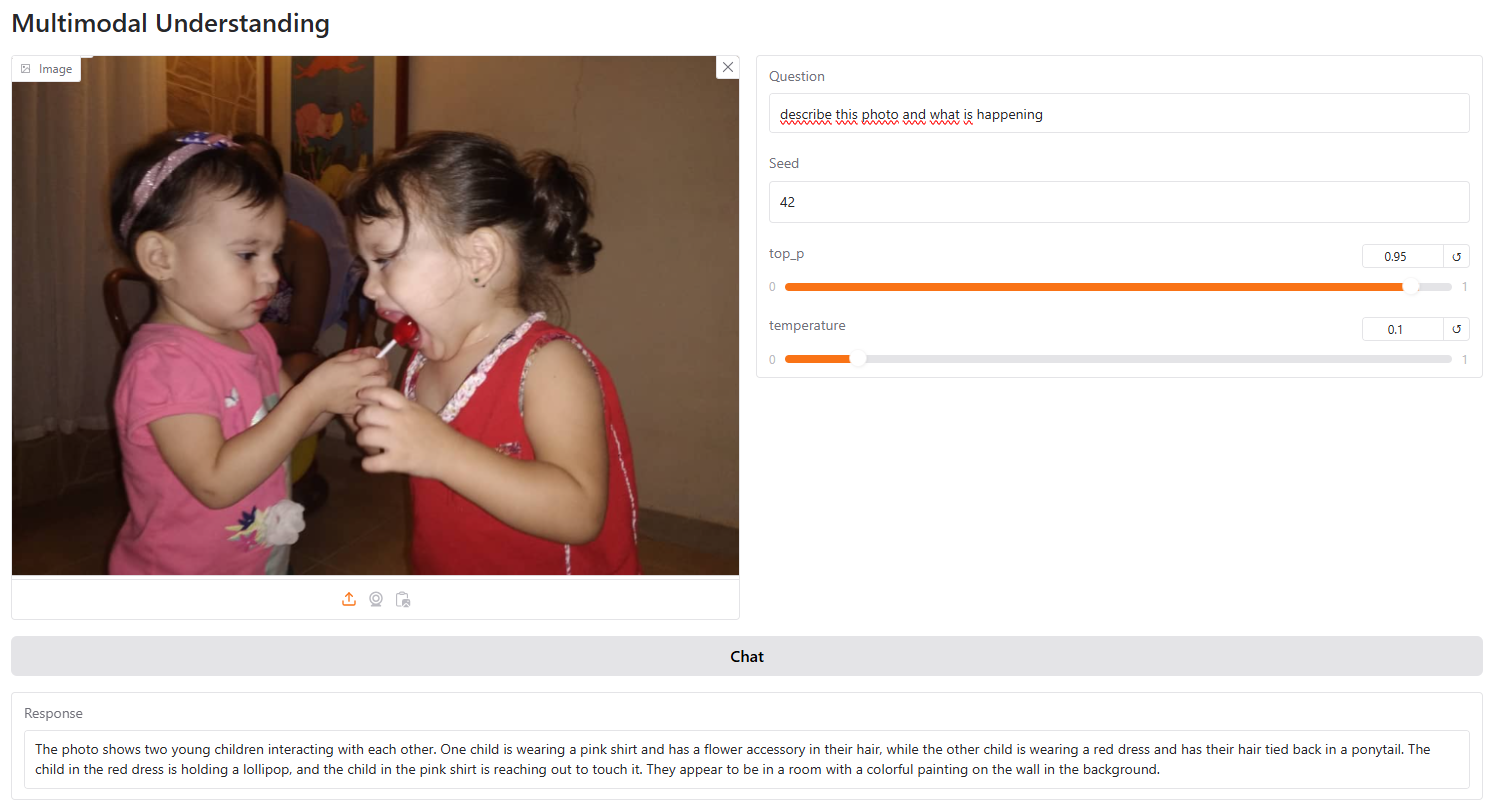
然而,在需要逻辑或超出照片明显内容的分析任务中,它仍然不如GPT Vision。例如,我们要求模型分析这张照片并解释其信息。

模型回答说:“这张图像似乎是一幅幽默的卡通,描绘了一个女人舔着一个长长的红色舌头的末端,而这个舌头连着一个男孩。”
它在分析结束时表示:“图像的整体基调似乎轻松愉快,可能暗示着一个女人正在进行顽皮或挑逗的行为。”
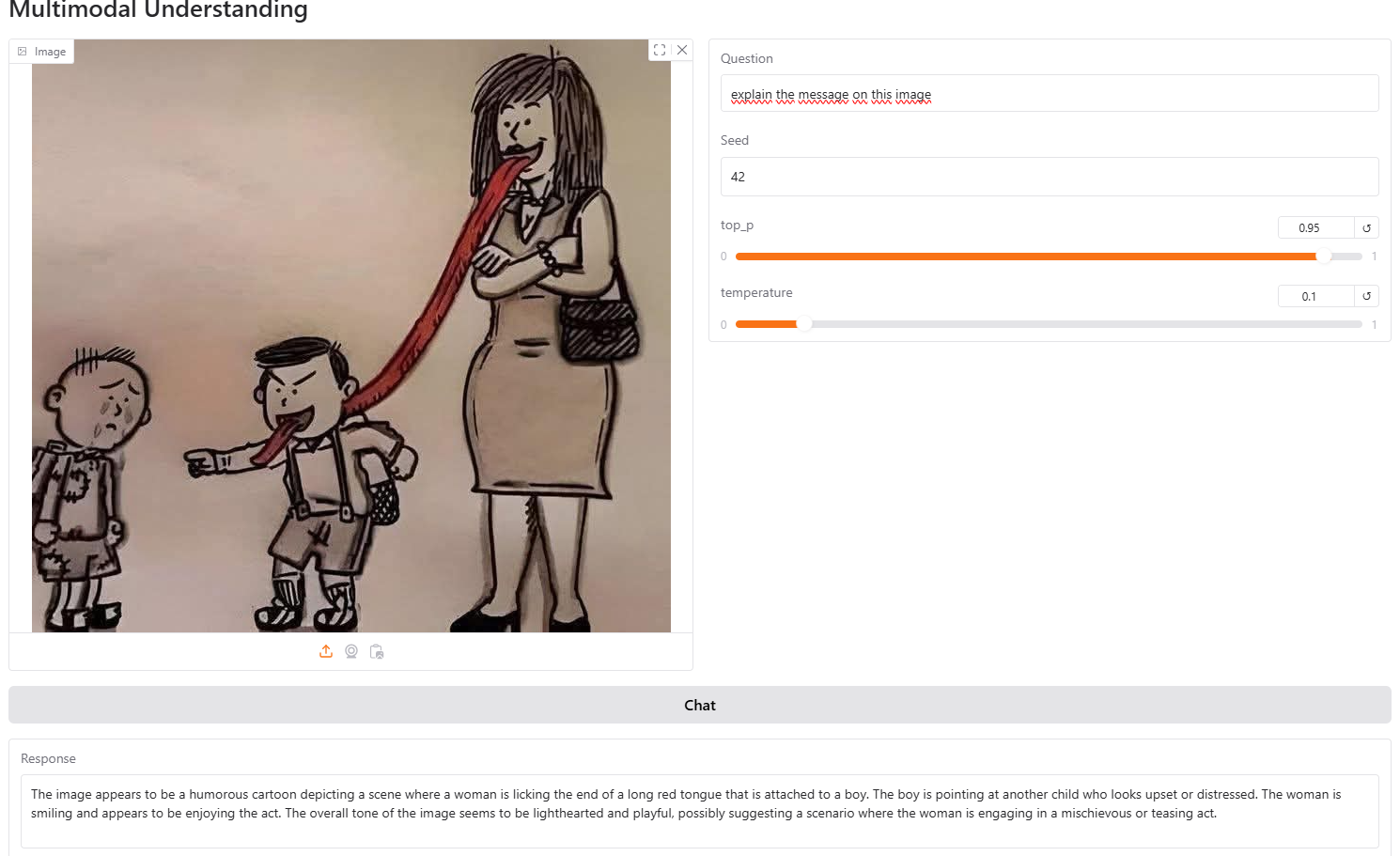
在这些需要超出简单描述的推理的情况下,模型大多数时候都失败了。
另一方面,例如ChatGPT,实际上理解了图像背后的含义:“这个隐喻表明母亲的态度、言辞或价值观直接影响着孩子的行为,特别是在负面方面,如欺凌或歧视,”它总结道——我们可以说是准确的。

独树一帜
图像生成看起来稳健且相对准确,尽管确实需要仔细的提示才能获得良好的结果。
DeepSeek声称Janus Pro超越了SD 1.5、SDXL和Pixart Alpha,但重要的是要强调,这必须是与基础的、未微调的模型进行比较。
换句话说,公平的比较是目前可用模型中最差版本之间的比较,因为可以说,没有人会在生成艺术时使用基础的SD 1.5,因为有数百个微调模型能够产生与甚至最先进的模型如Flux或Stable Diffusion 3.5竞争的结果。
因此,从质量上看,生成的结果并不令人印象深刻,但似乎比SD1.5或SDXL在推出时的输出要好。
例如,以下是Janus和SDXL生成的图像的正面比较,提示为:一只可爱迷人的小狐狸,拥有大大的棕色眼睛,背景是迷人的秋叶,永恒的、蓬松的、闪亮的鬃毛,花瓣,仙女,高度详细,照片真实,电影感,自然色彩。

Janus在理解核心概念方面胜过SDXL:它能够生成一只小狐狸,而不是像SDXL那样生成一只成熟的狐狸。
它对照片真实风格的理解也更好,其他元素(蓬松、电影感)也都存在。
尽管如此,SDXL生成的图像更清晰,尽管没有完全遵循提示。整体质量更好,眼睛看起来更真实,细节更容易辨认。
这种模式在其他生成中是一致的:良好的提示理解但执行不佳,图像模糊,考虑到当前最先进的图像生成器的优秀表现,这种模糊感显得过时。
然而,重要的是要注意,Janus是一个多模态的LLM,能够生成文本对话、分析图像并生成图像。Flux、SDXL和其他模型并不是为这些任务而构建的。
因此,Janus在其核心上更具多功能性——只是与那些在特定任务上表现出色的专业模型相比,表现并不出色。
作为开源项目,Janus在生成AI爱好者中作为领导者的未来将取决于一系列旨在改进这些问题的更新。
编辑:Josh Quittner 和 Sebastian Sinclair
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






