原文标题:The Math Needed for Trading on Polymarket (Complete Roadmap)
原文作者:Roan,加密分析师
翻译、注释:MrRyanChi,insiders.bot
在创立 @insidersdotbot 的过程中,我跟不少高频做市团队和套利团队深有过深度的交流,其中,最大的一个需求,就是怎么做套利策略。
我们的用户,朋友,合作伙伴,都在探索着 Polymarket 套利这一条复杂且多维度的交易路线。如果你是一个推特的活跃用户,那么我相信你也曾经刷到过「我通过 XX 套利策略,从预测市场上赚了多少钱」这样的推文。
然而,大部分文章都过度简化了套利的底层逻辑,让套利变成了「我上我也行」,「用 Clawdbot 就能解决」的交易模式,而并没有去详细解释怎样系统性地去理解并开发属于自己的套利系统。
如果你想理解 Polymarket 上的套利工具是怎么赚到钱,这篇文章,是我目前看到的最完整的解读。
由于英文原文有很多过于技术性,需要进行进一步研究的部分,我帮大家进行了重构和补充,方便大家只需要这一篇文章,不需要停下来查资料,就可以理解全部重点内容。
Polymarket 套利并不是简单的数学问题
你在 Polymarket 上看到一个市场:
YES 价格 $0.62,NO 价格 $0.33。
你心想:0.62 + 0.33 = 0.95,不到 1 块钱,有套利空间!同时买 YES 和 NO,花 $0.95,无论结果如何都能拿回 $1.00,净赚 $0.05。
你是对的。
但问题是——当你还在手动算这道加法题的时候,量化系统已经在做一件完全不同的事。
它们在同时扫描 17,218 个条件,跨越 2^63 种可能的结果组合,在毫秒级别内找到所有定价矛盾。等你下完两笔订单,价差已经消失了。系统早就在几十个相关市场里找到了同样的漏洞,算好了考虑订单簿深度和手续费之后的最优仓位大小,并行执行了所有交易,然后把资金转向了下一个机会。[1]
差距不只是速度。是数学基础设施。
第一章:为什么「加法」不够用——边际多面体问题
单一市场谬误
先看一个简单的例子。
市场 A:「特朗普会赢下宾夕法尼亚洲的选举吗?」
YES 价格 $0.48,NO 价格 $0.52。加起来正好 $1.00。
看起来完美,没有套利空间,对吧?
错。
加一个市场,问题就来了
再看市场 B:「共和党会在宾夕法尼亚洲超越对手 5 个百分点以上吗?」
YES 价格 $0.32,NO 价格 $0.68。加起来也是 $1.00。
两个市场各自都「正常」。但这里有一个逻辑依赖关系:
美国总统大选不是全国一起数票,而是按州计票。每个州是一个独立的「战场」,谁在这个州拿到更多选票,谁就赢走这个州所有的选举人票(赢者通吃)。特朗普是共和党候选人。所以「共和党在宾夕法尼亚赢」和「特朗普在宾夕法尼亚赢」——是同一件事。如果共和党赢了对手 5 个百分点以上,那不仅意味着特朗普赢了宾夕法尼亚,而且赢得很大。
换句话说,市场 B 的 YES(共和党大胜)是市场 A 的 YES(特朗普获胜)的一个子集——大胜一定意味着获胜,但获胜不一定意味着大胜。
而这种逻辑依赖,就创造了套利机会。
这就像是你在赌两件事——「明天会下雨吗」和「明天会有雷暴吗」。
如果有雷暴,那一定在下雨(雷暴是下雨的子集)。所以「雷暴 YES」的价格不可能比「下雨 YES」的价格高。如果市场定价违反了这个逻辑,你就可以同时买低卖高,赚到「无风险利润」,这就是套利。
指数爆炸:为什么暴力搜索行不通
对于任何有 n 个条件的市场,理论上有 2^n 种可能的价格组合。
听起来还行?来看一个真实案例。
2010 年 NCAA 锦标赛市场 [2]:63 场比赛,每场有赢/输两种结果。可能的结果组合数是 2^63 = 9,223,372,036,854,775,808——超过 9 百亿亿种。市场上有 5000 多个盘口。
2^63 这个数字有多大?如果你每秒检查 10 亿种组合,需要大约 292 年 才能全部检查完。这就是为什么「暴力搜索」在这里完全行不通。
逐一检查每种组合?计算上不可能。
再看 2024 年美国大选。研究团队发现了 1,576 对可能存在依赖关系的市场对。如果每对市场各有 10 个条件,那每对需要检查 2^20 = 1,048,576 种组合。乘以 1,576 对。你的笔记本电脑算完的时候,选举结果早就出来了。
整数规划:用约束代替枚举
量化系统的解决方案不是「更快地枚举」,而是根本不枚举。
它们用整数规划(Integer Programming)来描述「哪些结果是合法的」。
来看一个真实例子。Duke 对 Cornell 的比赛市场:每支球队有 7 个盘口(0 到 6 场胜利),总共 14 个条件,2^14 = 16,384 种可能组合。
但有一个约束:它们不可能都赢 5 场以上,因为那样它们会在半决赛相遇(只有一个能晋级)。
整数规划怎么处理?三条约束就够了:
· 约束一: Duke 的 7 个盘口里,恰好有一个为真(Duke 只能有一个最终胜场数)。
· 约束二: Cornell 的 7 个盘口里,恰好有一个为真。
· 约束三: Duke 赢 5 场 + Duke 赢 6 场 + Cornell 赢 5 场 + Cornell 赢 6 场 ≤ 1(它们不能同时赢那么多)。
三条线性约束,替代了 16,384 次暴力检查。

暴力搜索 vs 整数规划
换言之,暴力搜索就像是把字典里的每个单词都读一遍来找一个词。整数规划就像是直接翻到那个字母开头的页面。你不需要检查所有可能性,你只需要描述「合法答案长什么样」,然后让算法去找违反规则的定价。
真实数据:41% 的市场存在套利 [2]
原文中提到,研究团队分析了 2024 年 4 月到 2025 年 4 月的数据:
• 检查了 17,218 个条件
• 其中 7,051 个条件存在单一市场套利(占 41%)
• 中位数定价偏差:$0.60(应该是 $1.00)
• 13 对确认的跨市场可利用套利
中位数偏差 $0.60 意味着市场经常性地偏离 40%。这不是「接近有效」,这是「大规模可利用」。
第二章:Bregman 投影——怎么算出最优套利交易
发现套利是一个问题。算出最优的套利交易是另一个问题。
你不能简单地「取个平均」或者「微调一下价格」。你需要把当前的市场状态投影到无套利的合法空间上,同时保留价格里的信息结构。
为什么「直线距离」不行
最直觉的想法是:找到离当前价格最近的「合法价格」,然后交易差价。
用数学语言说,就是最小化欧几里得距离:||μ - θ||²
但这有一个致命问题:它把所有价格变动当成一样的。
从 $0.50 涨到 $0.60,和从 $0.05 涨到 $0.15,都是涨了 10 美分。但它们的信息含量完全不同。
为什么?因为价格代表的是隐含概率。从 50% 变到 60%,是一个温和的观点调整。从 5% 变到 15%,是一个巨大的信念翻转——一个几乎不可能的事件突然变成了「有点可能」。
想象你在称体重。从 70 公斤变到 80 公斤,你会说「胖了一点」。但从 30 公斤变到 40 公斤(如果你是成年人),那就是「从濒死变成了严重营养不良」。同样是 10 公斤的变化,意义完全不同。价格也是一样——越接近 0 或 1 的价格变动,信息量越大。
Bregman 散度:正确的「距离」
Polymarket 的做市商使用的是 LMSR(对数市场评分规则)[4],价格本质上代表概率分布。
在这种结构下,正确的距离度量不是欧几里得距离,而是 Bregman 散度。[5]
对于 LMSR,Bregman 散度就变成了 KL 散度(Kullback-Leibler 散度)[6]——一个衡量两个概率分布之间「信息论距离」的指标。
你不需要记住公式。你只需要理解一件事:
KL 散度会自动给「极端价格附近的变动」更高的权重。从 $0.05 到 $0.15 的变动,在 KL 散度下比从 $0.50 到 $0.60 的变动「更远」。这正好符合我们的直觉——极端价格的变动意味着更大的信息冲击。
一个比较好的例子,就是上次 @zachxbt 的预测市场中,Axiom 在最后关头反超 Meteora,也是以极端价格变动,作为一切变化的。
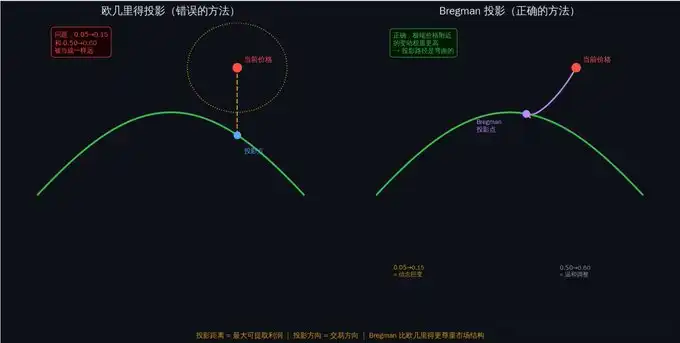
Bregman 投影 vs 欧几里得投影
套利利润 = Bregman 投影的距离
这是原文作者参考整篇论文最核心的结论之一:
任何交易能获得的最大保证利润,等于当前市场状态到无套利空间的 Bregman 投影距离。
换人话说:市场价格偏离「合法空间」越远,能赚的钱越多。而 Bregman 投影会告诉你:
1. 该买卖什么(投影方向告诉你交易方向)
2. 该买卖多少(考虑订单簿深度)
3. 能赚多少(投影距离就是最大利润)
排名第一的套利者一年赚了 $2,009,631.76。[2]他的策略就是比所有人更快、更准地解这道优化题。

边际多面体与套利
打个比方来说,想象你站在一座山上,山脚下有一条河(无套利空间)。你现在的位置(当前市场价格)离河有一段距离。
Bregman 投影就是帮你找到「从你的位置到河边的最短路径」——但不是直线距离,而是考虑了地形(市场结构)之后的最短路径。这条路径的长度,就是你能赚到的最大利润。
第三章:Frank-Wolfe 算法——让理论变成可执行的代码
好,现在你知道了:要算最优套利,就要做 Bregman 投影。
但问题是——直接计算 Bregman 投影是不可行的。
为什么?因为无套利空间(边际多面体 M)有指数级多的顶点。标准的凸优化方法需要访问完整的约束集,也就是枚举每一个合法结果。我们刚才说了,这在规模化场景下是不可能的。
Frank-Wolfe 的核心思想
Frank-Wolfe 算法 [7] 的天才之处在于:它不试图一次性搞定整个问题,而是一步一步逼近答案。
它的工作方式是这样的:
第一步: 从一个小的已知合法结果集合开始。
第二步: 在这个小集合上做优化,找到当前最优解。
第三步: 用整数规划找到一个新的合法结果,加入集合。
第四步: 检查是否足够接近最优解。如果不够,回到第二步。
每一轮迭代,集合只增加一个顶点。即使跑了 100 轮,你也只需要追踪 100 个顶点——而不是 2^63 个。

Frank-Wolfe 迭代过程
想象你在一个巨大的迷宫里找出口。
暴力方法是把每条路都走一遍。Frank-Wolfe 的方法是:先随便走一条路,然后在每个岔路口问一个「向导」(整数规划求解器):「从这里开始,哪个方向最可能通向出口?」然后朝那个方向走一步。你不需要探索整个迷宫,只需要在每个关键节点做出正确的选择。
整数规划求解器:每一步的「向导」
Frank-Wolfe 的每一轮迭代都需要解一个整数线性规划问题。这在理论上是 NP 困难的(也就是「没有已知的快速通用算法」)。
但现代求解器,比如 Gurobi[8],对于结构良好的问题可以高效求解。
研究团队用的是 Gurobi 5.5。实际求解时间 :
• 早期迭代(少量比赛已结束):不到 1 秒
• 中期(30-40 场比赛已结束):10-30 秒
• 后期(50+ 场比赛已结束):不到 5 秒
为什么后期反而更快?因为随着比赛结果确定,可行解空间在缩小。变量更少,约束更紧,求解更快。
梯度爆炸问题和 Barrier Frank-Wolfe
标准的 Frank-Wolfe 有一个技术问题:当价格接近 0 的时候,LMSR 的梯度会趋向负无穷。这会导致算法不稳定。
解决方案是 Barrier Frank-Wolfe:不在完整的多面体 M 上优化,而是在一个稍微「收缩」的版本 M 上优化。收缩参数 ε 会随着迭代自适应地减小——开始时离边界远一点(稳定),后来逐渐逼近真实边界(精确)。
研究表明,实际操作中 50 到 150 轮迭代就足够收敛。
真实表现
论文里有一个关键发现 [2]:
在 NCAA 锦标赛的前 16 场比赛中,Frank-Wolfe 做市商(FWMM)和简单的线性约束做市商(LCMM)表现差不多——因为整数规划求解器还太慢。
但在 45 场比赛结束后,第一次成功的 30 分钟投影完成了。
从那以后,FWMM 在盘口定价上比 LCMM 好了 38%。
转折点就是:当结果空间缩小到整数规划能在交易时间窗口内完成求解的时候。
FWMM 就像一个学生,考试前半段还在热身,但一旦进入状态,就开始碾压。LCMM 是那个一直稳定发挥但天花板有限的学生。关键区别是:FWMM 有更强的「武器」(Bregman 投影),只是需要时间来「装弹」(等求解器跑完)。
第四章:执行——为什么算出来了还可能亏钱
你检测到了套利。你用 Bregman 投影算出了最优交易。
现在你需要执行。
这是大多数策略失败的地方。
非原子执行问题
Polymarket 使用的是 CLOB(中央限价订单簿)[9]。跟去中心化交易所不同,CLOB 上的交易是顺序执行的——你不能保证所有订单同时成交。
你的套利计划:
买 YES,价格 $0.30。买 NO,价格 $0.30。总成本 $0.60。无论结果如何,回收 $1.00。利润 $0.40。
现实:
· 提交 YES 订单 → 成交价 $0.30 ✓
· 你的订单改变了市场价格。
· 提交 NO 订单 → 成交价 $0.78 ✗
· 总成本:$1.08。回收:$1.00。实际结果:亏 $0.08。
一条腿成交了,另一条没有。你暴露了。
这就是为什么论文只统计利润空间超过 $0.05 的机会。更小的价差会被执行风险吃掉。

非原子执行风险
VWAP:真实的成交价格
不要假设你能以报价成交。要计算成交量加权平均价格(VWAP)[10]。
研究团队的方法是:对 Polygon 链上的每个区块(大约 2 秒),计算该区块内所有 YES 交易的 VWAP 和所有 NO 交易的 VWAP。如果 |VWAP_yes + VWAP_no - 1.0| > 0.02,就记录为一次套利机会 [2]。
VWAP 就是「你实际付的平均价格」。如果你想买 10,000 个代币,但订单簿上 $0.30 只有 2,000 个,$0.32 有 3,000 个,$0.35 有 5,000 个——你的 VWAP 就是 (2000×0.30 + 3000×0.32 + 5000×0.35) / 10000 = $0.326。比你看到的「最优价格」$0.30 贵了不少。
流动性约束:能赚多少取决于订单簿深度
即使价格确实有偏差,你能赚到的利润也受限于可用流动性。
真实例子 [2]:
市场显示套利:YES 价格之和 = $0.85。潜在利润:每美元 $0.15。但这些价格上的订单簿深度只有 $234。最大可提取利润:$234 × 0.15 = $35.10。
对于跨市场套利,你需要在所有仓位上同时有流动性。最小的那个决定了你的上限。
这也是为什么,在现有量化平台中,展现出订单价格对成交价格对影响至关重要。

第五章:完整系统——实际部署了什么
理论是干净的。生产环境是混乱的。
这是一个真正能跑的套利系统长什么样 [2]。
数据管道
实时数据: WebSocket 连接 Polymarket 上的 API [9],接收订单簿更新(价格/数量变化)、成交推送、市场创建/结算事件。
历史数据: 通过 Alchemy Polygon 节点 API 查询合约事件——OrderFilled(交易执行)、PositionSplit(新代币铸造)、PositionsMerge(代币销毁)。
研究团队分析了 8600 万笔交易 [2]。这个量级需要基础设施,不是脚本能搞定的。
目前也有计划开源高速交易 API,如果有计划使用类似的交易模型,希望能够第一时间体验 API,也可以随时 DM 我。
依赖关系检测层
对于 305 个美国大选市场,有 46,360 对可能的组合需要检查。手动分析不可能。
研究团队用了一个聪明的方法:用 DeepSeek-R1-Distill-Qwen-32B 大语言模型来做初筛。
输入:两个市场的条件描述。输出:合法结果组合的 JSON。
然后做三层验证:每个市场是否恰好有一个条件为真?合法组合数是否少于 n × m(存在依赖)?依赖子集是否满足套利条件?
结果:40,057 对独立(无套利)→ 1,576 对有依赖(潜在套利)→ 374 对满足严格条件 → 13 对经人工验证可利用 [2]。
LLM 在复杂多条件市场上的准确率是 81.45%。足够用来做初筛,但执行前需要人工验证。
三层优化引擎
· 第一层:简单线性约束(LCMM)。快速检查基本规则——「概率之和等于 1」、「如果 A 蕴含 B,那 P(A) 不能超过 P(B)」。毫秒级完成,去除明显的定价错误。
· 第二层:整数规划投影(Frank-Wolfe + Gurobi)。这是核心。参数:Alpha = 0.9(提取至少 90% 的可用套利),初始 ε = 0.1(10% 收缩),收敛阈值 = 1e-6,时间限制 = 30 分钟。典型迭代次数:50-150 次。每次迭代求解时间:1-30 秒。
· 第三层:执行验证。在提交订单之前,模拟当前订单簿上的成交。检查:流动性是否充足?预期滑点是多少?扣除滑点后的保证利润是多少?利润是否超过最低门槛($0.05)?只有全部通过才执行。
仓位管理:改良版 Kelly 公式
标准的 Kelly 公式 [11] 告诉你该把多少比例的资金投入一笔交易。但在套利场景下,需要加入执行风险的调整:
f = (b×p - q) / b × √p
其中 b 是套利利润百分比,p 是完全执行的概率(根据订单簿深度估算),q = 1 - p。
上限:订单簿深度的 50%。超过这个比例,你的订单本身就会大幅移动市场。
最终结果
2024 年 4 月到 2025 年 4 月,总提取利润:
单一条件套利: 低买两边 $5,899,287 + 高卖两边 $4,682,075 = $10,581,362
市场再平衡: 低买所有 YES $11,092,286 + 高卖所有 YES $612,189 + 买所有 NO $17,307,114 = $29,011,589
跨市场组合套利: $95,634
总计:$39,688,585
前 10 名套利者拿走了 $8,127,849(总额的 20.5%)。排名第一的套利者:$2,009,632,来自 4,049 笔交易,平均每笔 $496[2]。
不是彩票。不是运气。是数学精度的系统化执行。
最后的现实
当交易者还在读「预测市场 10 个技巧」的时候,量化系统在做什么?
它们在用整数规划检测 17,218 个条件之间的依赖关系。在用 Bregman 投影计算最优套利交易。在运行 Frank-Wolfe 算法处理梯度爆炸。在用 VWAP 估算滑点并行执行订单。在系统性地提取 4000 万美元的保证利润。
差距不是运气。是数学基础设施。
论文是公开的 [1]。算法是已知的。利润是真实的。
问题是:在下一个 4000 万被提取之前,你能建出来吗?
概念速查
• 边际多面体(Marginal Polytope)→ 所有「合法价格」组成的空间。价格必须在这个空间内才是无套利的。可以理解为「价格的合法区域」
• 整数规划(Integer Programming)→ 用线性约束描述合法结果,避免暴力枚举。把 2^63 次检查压缩成几条约束 [3]
• Bregman 散度 / KL 散度 → 衡量两个概率分布之间「距离」的方法,比欧几里得距离更适合价格/概率场景。极端价格附近的变动权重更高 [5][6]
• LMSR(对数市场评分规则)→ Polymarket 做市商使用的定价机制,价格代表隐含概率 [4]
• Frank-Wolfe 算法 → 一种迭代优化算法,每轮只加一个新顶点,避免了枚举指数级多的合法结果 [7]
• Gurobi → 业界领先的整数规划求解器,Frank-Wolfe 每轮迭代的「向导」[8]
• CLOB(中央限价订单簿)→ Polymarket 的交易撮合机制,订单顺序执行,不能保证原子性 [9]
• VWAP(成交量加权平均价格)→ 你实际付的平均价格,考虑了订单簿深度。比「最优报价」更真实 [10]
• Kelly 公式 → 告诉你该把多少比例的资金投入一笔交易,平衡收益和风险 [11]
• 非原子执行 → 多笔订单不能保证同时成交的问题。一条腿成交另一条没成交 = 暴露风险
• DeepSeek → 用来做市场依赖关系初筛的大语言模型,准确率 81.45%
参考资料
[1] 原文:https://x.com/RohOnChain/status/2017314080395296995
[2] 研究论文「Unravelling the Probabilistic Forest: Arbitrage in Prediction Markets」:https://arxiv.org/abs/2508.03474
[3] 理论基础论文「Arbitrage-Free Combinatorial Market Making via Integer Programming」:https://arxiv.org/abs/1606.02825
[4] LMSR 对数市场评分规则解释:https://www.cultivatelabs.com/crowdsourced-forecasting-guide/how-does-logarithmic-market-scoring-rule-lmsr-work
[5] Bregman 散度入门:https://mark.reid.name/blog/meet-the-bregman-divergences.html
[6] KL 散度 - Wikipedia:https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
[7] Frank-Wolfe 算法 - Wikipedia:https://en.wikipedia.org/wiki/Frank%E2%80%93Wolfe_algorithm
[8] Gurobi 优化器:https://www.gurobi.com/
[9] Polymarket CLOB API 文档:https://docs.polymarket.com/
[10] VWAP 解释 - Investopedia:https://www.investopedia.com/terms/v/vwap.asp
[11] Kelly 公式 - Investopedia:https://www.investopedia.com/articles/trading/04/091504.asp
[12] Decrypt 报道「The $40 Million Free Money Glitch」:https://decrypt.co/339958/40-million-free-money-glitch-crypto-prediction-markets
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






