Original source: Wall Street Insights
SemiAnalysis, a semiconductor research institution, has released two analyses in succession, outlining the dual aspects of opportunity and challenge in Nvidia's prospects, akin to "ice and fire."
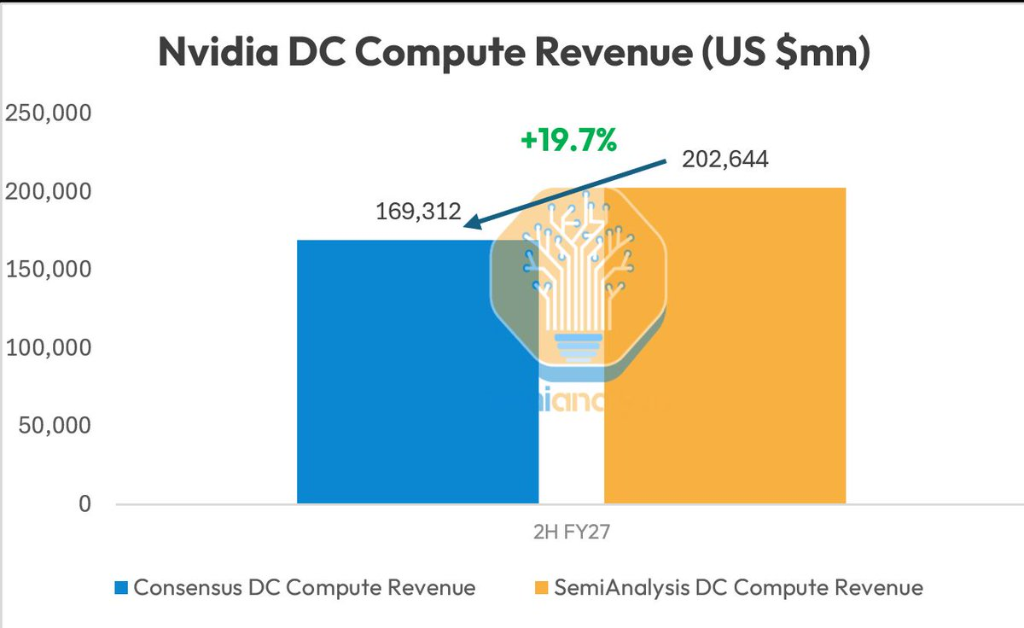
On June 30, SemiAnalysis published its latest forecast on Platform X, indicating that Nvidia's revenue from data center computing in the second half of fiscal year 2027 will exceed Wall Street's consensus expectations by about 20%. The core support for this optimistic assessment lies in the fact that the HBM4 memory supply issue that previously constrained the large-scale shipment of the Rubin platform has been resolved, and the front-end wafer capacity has been secured, clearing substantial barriers for performance in the second half of the year.
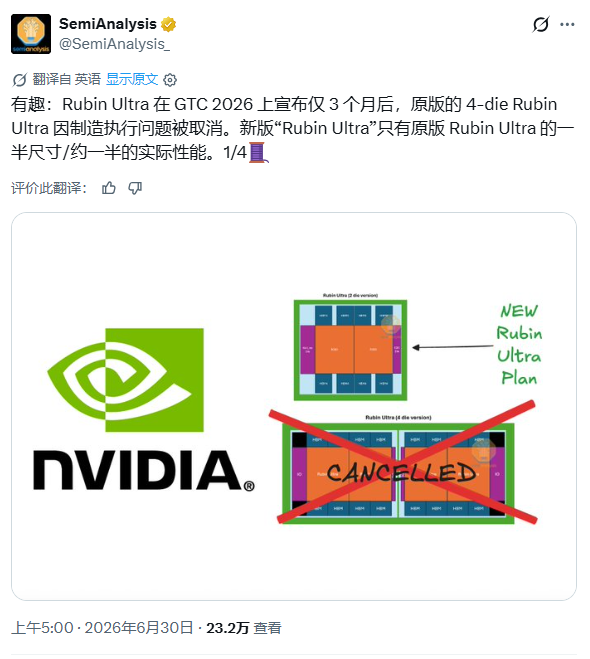
However, on the same morning, SemiAnalysis disclosed another piece of negative news: Nvidia's original 4-chip Rubin Ultra was canceled about three months after its release at GTC 2026, and the new version of "Rubin Ultra" has been reduced to half its original size, with actual performance also halved.
On one hand, there is an optimistic revision of revenue following the resolution of supply bottlenecks, while on the other, there is a pessimistic adjustment of the technological roadmap after the flagship product was scaled down—these two completely opposite judgments by SemiAnalysis anchor Nvidia's narrative coordinates on entirely different dimensions, namely performance realization and technological moat.
HBM4 Bottleneck Resolved, Rubin Platform Expected to Ramp Up in Second Half
SemiAnalysis has made its latest forecast through its Accelerator Model, stating that Nvidia will experience a large-scale ramp-up in the second half of this year.
The institution predicts that driven by the strong performance of the Rubin platform, Nvidia's revenue from data center computing in the second half of fiscal year 2027 will exceed market consensus expectations by about 20%. The HBM4 issue that had previously affected the Rubin timeline has now been resolved, and front-end wafer supply has been secured in advance, meaning that the postponed Rubin platform is set to enter a rapid ramp-up phase.
SemiAnalysis specifically points out that its predictive logic differs significantly from that of traditional sell-side analysts. Most Wall Street institutions tend to establish relatively conservative profit forecasts to leave room for potential “outperformance,” while SemiAnalysis’ conclusions are more grounded in first-hand industry chain research, aiming to be closer to true market dynamics.
Its Accelerator Model constructs a comprehensive information cross-validation system covering the entire supply chain, with data sources including material suppliers, wafer manufacturing, key components, server OEMs, and more. Additionally, it combines the actual procurement and deployment situations of hyper-scale cloud service providers and cutting-edge AI labs to conduct multi-dimensional verification of supply and demand relationships.
Notably, this model focuses not only on Nvidia but also encompasses other AI chip manufacturers such as Broadcom, AMD, MediaTek, and Marvell, continuously tracking the overall evolution of the AI computational power supply chain in conjunction with the HBM Model.
CUDA Moat Eroded, Rubin Ultra Shrinkage Reflects Rise of Self-developed ASICs
However, another comment from SemiAnalysis regarding the Rubin Ultra has sparked broad discussion in the market.
The institution revealed that Nvidia had initially planned to use a design with four computing chips for the Rubin Ultra but adjusted the original plan just three months after its release at this year's GTC, significantly reducing the scale of the new version due to advanced packaging manufacturing difficulties.
SemiAnalysis believes that the more concerning aspect is not the shrinkage of Rubin Ultra itself, but the changing competitive landscape reflected by this event. The institution points out that over the past year, Nvidia's biggest competitive pressure no longer comes solely from traditional GPU manufacturers like AMD, but increasingly from hyper-scale cloud providers and AI model companies that are beginning to adopt self-developed ASICs to build dedicated chip systems for specific scenarios like training or inference.
For example, Anthropic has currently developed a multi-platform computational power architecture consisting of Google TPU, Amazon Trainium, and Nvidia GPU. A large number of Claude model training runs on the TPU platform, while Claude Code inference is increasingly deployed on Trainium, with Nvidia GPU primarily handling general calculation tasks for cutting-edge research. SemiAnalysis notes that a year ago, it was hard to imagine that TPU and Trainium could grow to their current scale, while now the CUDA moat is being slowly eroded.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




