TL;DR
- Claude $20 subscription cost breakdown, splitting AI monthly fees into model companies, cloud computing power, GPU, electricity, and supply chain.
- AI subscriptions have ongoing inference costs and cannot directly apply the traditional SaaS high gross margin assumptions.
- Related entities: OpenAI, Anthropic, Microsoft, Amazon, Google, NVIDIA (NVDA), TSMC, SK Hynix, Samsung, Micron, data centers, and power supply chains.
An estimate diagram breaking down Claude Pro's monthly fee of around $20 in the U.S. to model companies, cloud computing, GPU depreciation, electricity, and supply chain is prompting investors to re-discuss how AI application revenue should be valued.

This diagram does not represent official revenue sharing data from Anthropic, Amazon Web Services, or NVIDIA, nor can it be considered the real ledger of any company. Its value lies in posing a more fundamental question: how much of the subscription fee paid by users for AI applications can be retained as software gross profit like traditional SaaS?
The valuation imagination for traditional SaaS is very clear. Once software is created, selling one more account incurs relatively low additional costs, and mature pure software companies often have gross margins exceeding 70% or even 80%. Investors are willing to assign high multiples because as revenue scales up, profit margins have the opportunity to continue increasing.
The trouble with AI applications is that for every question posed by users, every piece of code written, every document analyzed, or every agent called, GPU time, electricity, memory bandwidth, and cloud resources must be consumed. On the surface, there is a fixed monthly fee, but beneath lies a cost chain that varies with usage. Light users might enjoy high margins, while heavy users running continuous tasks within their usage limits or related tool packages could see costs rise rapidly.
Thus, the $20 breakdown diagram challenges not how many dollars a company takes, but whether "AI application revenue is inherently equal to SaaS revenue." AI companies must prove they deserve a high multiple not only by showing users are willing to pay but also by demonstrating that the gross profit margin, weighted by usage, can continuously improve.
Behind the Subscription Fee is a Chain of Inference Costs
The biggest difference between AI subscriptions and regular software subscriptions is that the marginal cost of "using once" is no longer close to zero.
In traditional SaaS, when a team opens an additional account, the service provider incurs costs for servers, customer service, and bandwidth; however, these costs do not typically increase linearly with each click. The truly expensive parts are upfront R&D, sales, and customer acquisition. Once a product scales, a significant portion of new income can often be retained.
Large model products differ. When users input questions, and the model generates answers, this process is called inference, which refers to the actual computation when the model is called upon by users. A token is the basic unit for measuring how the model reads and writes text. The more questions users ask, the longer the context, and the more complex the generated content, the more tokens and computing power are consumed.
This creates a contradiction between fixed subscriptions and variable costs. The U.S. monthly fee for Claude Pro is about $20, though the price can be affected by region, taxes, and adjustments by Anthropic. Users see a fixed price, but the model company faces highly varied usage behavior. Some only write emails and look up information, while others handle long documents, run code tasks, or call upon more complex automated processes.
The circulating breakdown diagram in the market attempts to visualize this matter: within the $20, a portion goes to the model company, and a portion is paid to cloud and computing power providers. The computing costs include electricity, operations, and GPU depreciation. The procurement of GPUs flows up the supply chain to NVIDIA, TSMC, HBM (high bandwidth memory) suppliers, optical modules, ODMs, and electricity-related companies.
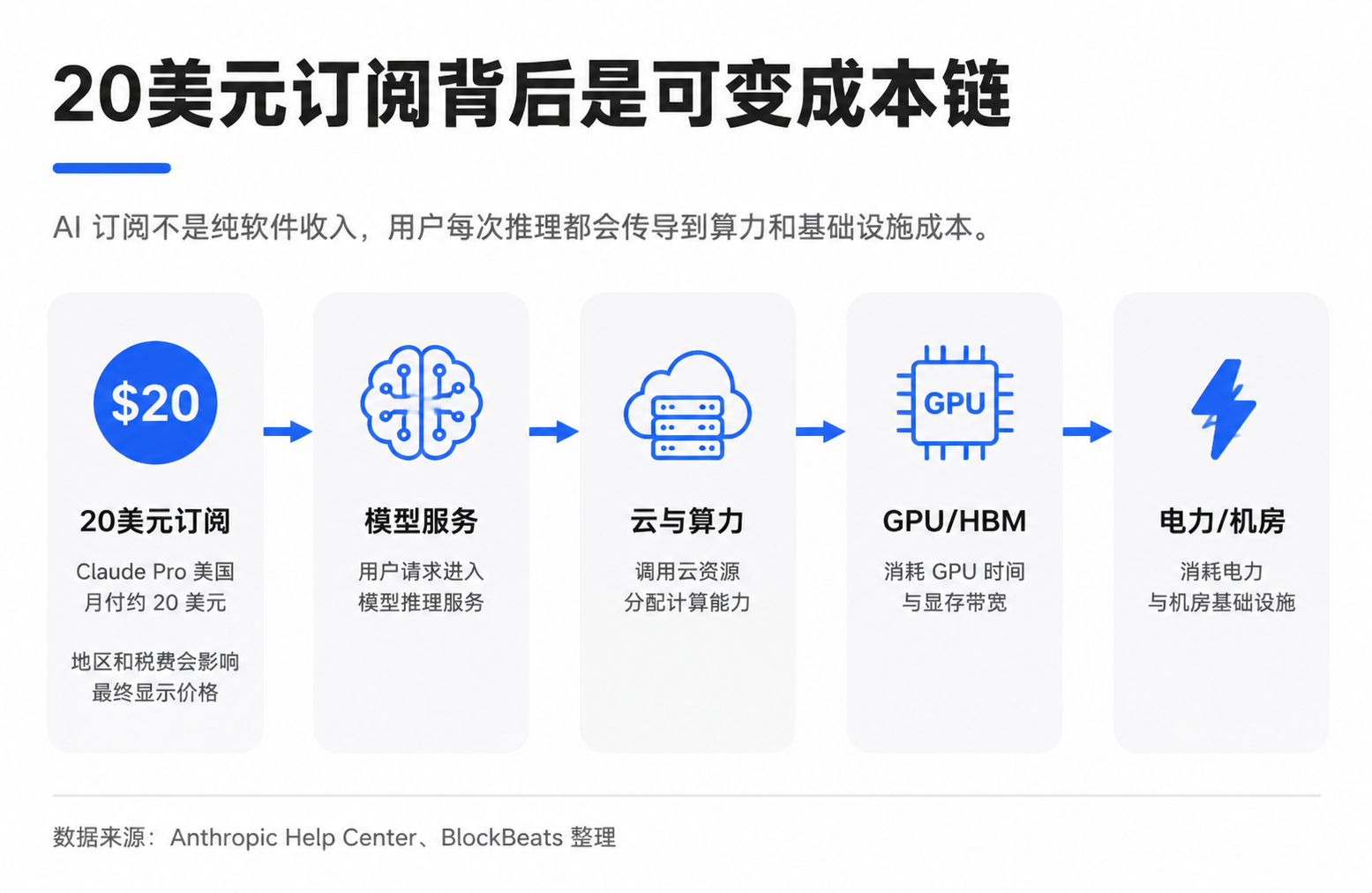
Here, "GPU depreciation" can be understood as expensive GPUs not being a one-time calculation but rather gradually allocated to AI services based on usage lifespan, intensity, or accounting standards. The actual distribution will be influenced by package limits, the ratio of light to heavy users, internal settlement prices from cloud vendors, reserved computing power discounts, GPU utilization rates, and depreciation periods. Average costs do not equal marginal costs.
What investors really need to focus on is the direction: AI application companies cannot only disclose revenue growth but must also answer whether the computing costs behind that revenue growth are rising in tandem. If usage grows faster than model efficiency improves, higher subscription revenue may lead to more significant gross profit pressure. Only if efficiency improves quickly enough will model companies have the chance to draw closer to the profit structure of software companies.
Infrastructure Needs to Secure More Certain Revenue First
At this stage, the growth in AI usage is more directly flowing into infrastructure rather than being fully retained at the application layer.
Whether users are interacting with models in Claude, ChatGPT, Gemini, or internal business agents, inference ultimately needs to land on computing power, electricity, memory, and networks. While the application layer may see product iterations, the underlying resource consumption is more rigid. As long as AI usage continues to rise, capital expenditures for clouds, GPU procurement, HBM demand, and data center electricity consumption will be stimulated.
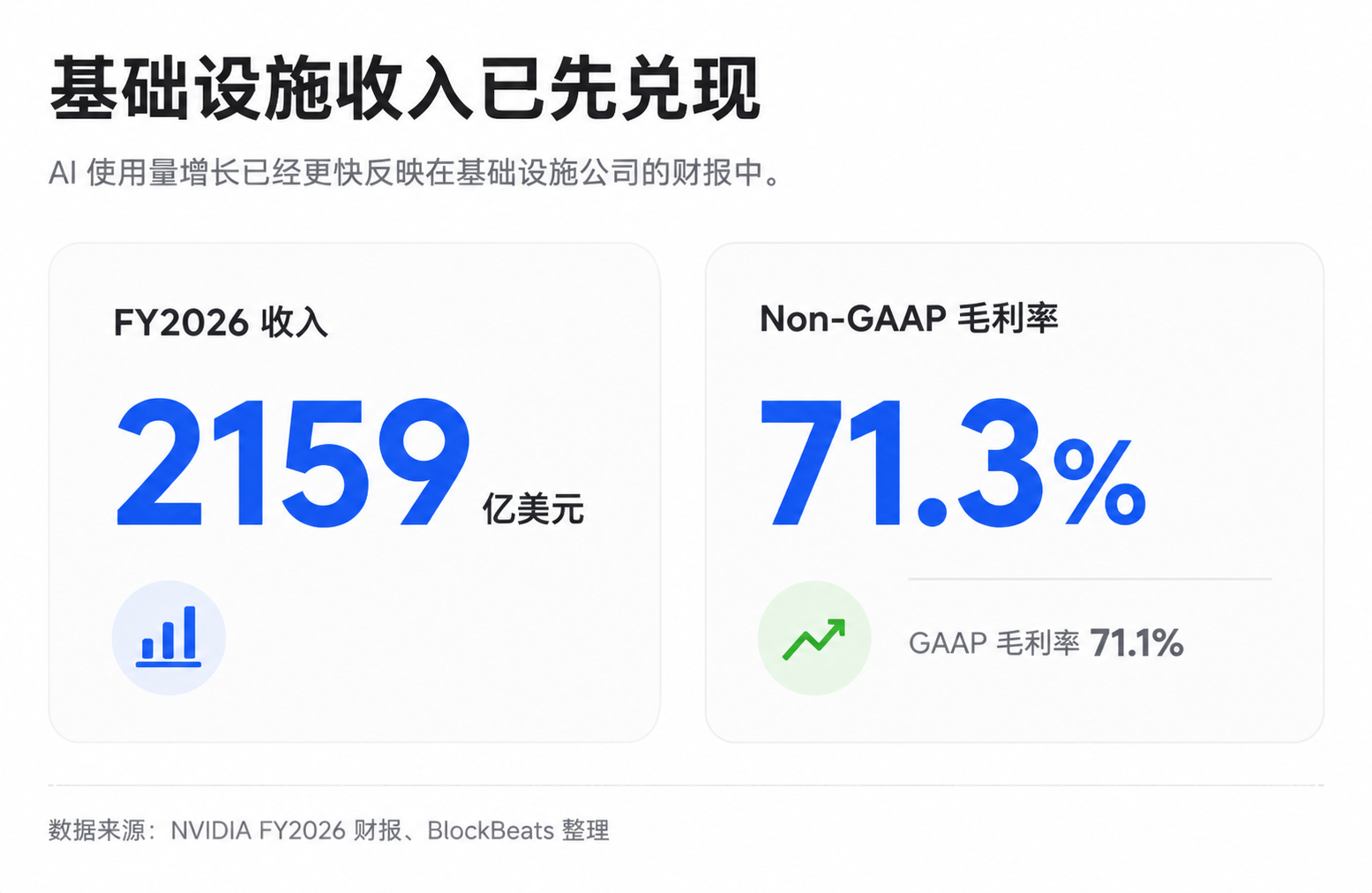
This is also the reason why infrastructure chains such as NVIDIA, TSMC, and SK Hynix have been continuously revalued by the market. NVIDIA has had high gross margins in recent years, with FY2026 GAAP and non-GAAP gross margins at approximately 71.1% and 71.3%, respectively, and subsequent quarter guidance remains high. It should be noted that certain quarters may be affected by specific costs, and publicly available financial reports may not always directly reveal the true gross profit structure of AI data centers, but the fact that scarce infrastructure has pricing power is already reflected in performance.
HBM is the most typical segment in this chain. It is not ordinary memory but the key component that supports high-throughput calculations in AI accelerators. As model scale, context length, and concurrent inference demand increase, AI chips' dependency on high-bandwidth memory grows stronger. Supply chain estimates show that HBM's share of the new generation of AI chip costs has increased, which is also an important reason why SK Hynix, Samsung, and Micron have been revalued during the AI cycle.
Electricity and data centers have transformed from background costs to investment focal points. The energy consumption of a single ordinary text query may not be excessive, but complex agents, long contexts, code generation, and multi-turn tasks can amplify the computational load. For cloud vendors and data center operators, the key is not how much energy is consumed during a particular query, but rather how cluster utilization, electricity prices, cooling, facility capacity, and grid access capabilities become costs and bottlenecks when massive inference requests occur continuously.
The advantage on the infrastructure side is that performance validation occurs more quickly. Cloud vendors' capital expenditures for AI have already been realized; NVIDIA's revenue and gross margins are reflected in financial reports, and orders and prices for HBM manufacturers will also quickly enter profit statements. Transactions at the model application layer, on the other hand, revolve more around future expectations: subscription conversion rates, enterprise penetration rates, API revenue, and profit releases following declines in future cost curves.
Efficiency Improvement Remains the Core Basis for Bulls
Software investors and AI bulls are not without counters. The efficiency faction's core argument is that today's inference costs are high merely as a phenomenon of early stages; model optimization, caching, small models, self-developed chips, and higher cluster utilization will continuously drive down unit costs. If costs decrease quickly enough, AI applications can still return to high-margin software logic.
This rebuttal has a basis in reality. Some mainstream models have already seen a significant decline in unit prices under equal or greater capabilities. OpenAI previously disclosed that GPT-4o mini's cost per token dropped by 99% compared to the earlier text-davinci-003. Different companies do not completely align in their pace; recently, Anthropic has been more focused on paralleled upgrades and model stratification, but the industry direction remains towards providing stronger capabilities at lower costs.

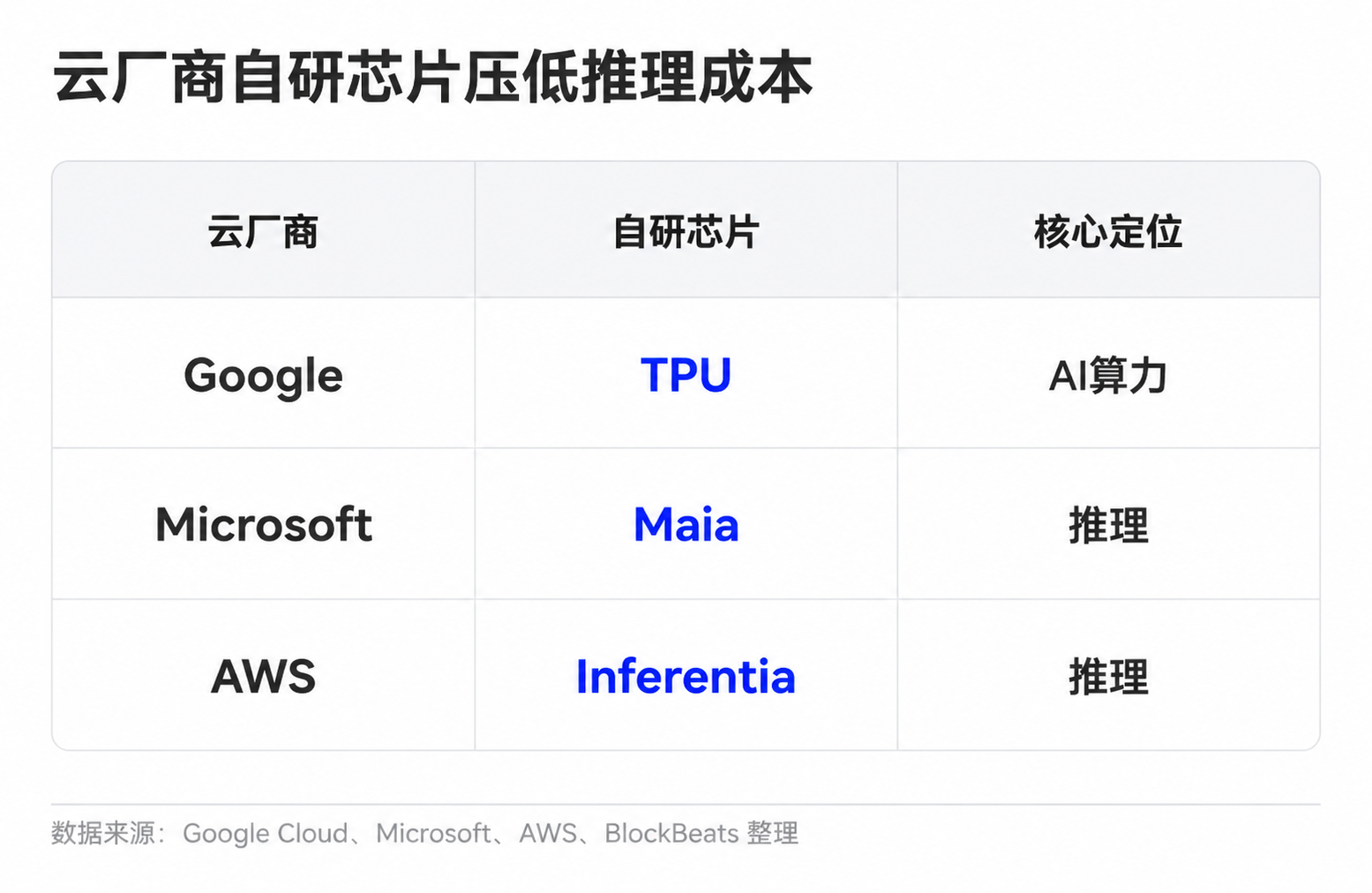
Model companies also have various means to improve unit economics. Simple tasks can be assigned to small models, common requests can be reused through caching, and long contexts and complex tasks can be assigned to stronger models. Cloud vendors can lower unit computing costs through self-developed chips and cluster scheduling. Google has TPUs, Microsoft has launched Maia for inference, and Amazon is advancing Trainium and Inferentia.
If we only consider technological advancements, there is indeed room for improvement in AI application profit margins. Cheaper inference, better model routing, and stronger compression capabilities can allow the same $20 subscription to support more usage. Light users, high-priced enterprise packages, API tiered pricing, and more stringent usage limits can also improve overall unit economics.
The difficulty lies in the fact that cost reduction is not the only variable. AI applications are transitioning from simple chatting to heavier workloads. In the past, users might only have engaged in Q&A and text rewriting, but now an increasing number of demands come from code agents, long document processing, video and multimodal generation, and enterprise automation processes. These scenarios have higher value and incur higher consumption. The more useful the model, the more likely users are to assign it more complex, longer-duration tasks.
This divergence thus becomes more specific: whether the speed at which inference costs decline can exceed the growth in usage and task complexity. If unit costs decrease rapidly but average user consumption grows even faster, the weighted gross margins of model companies will still face pressure. Conversely, if model routing, caching, self-developed chips, and price stratification are effective enough, AI subscriptions may gradually shed today’s heavy cost characteristics.
Subscription User Numbers Do Not Equal Gross Margins
The $20 breakdown diagram should not be interpreted as the ultimate outcome. It is more akin to a valuation reminder at the current stage: as long as the market does not see sufficiently transparent gross margin data for model companies, investors need to discount the assumption that "AI application is inherently equal to SaaS."
For private model companies like OpenAI and Anthropic, external investors find it difficult to view complete ledgers. Financing materials, partner disclosures, cloud cost structures, enterprise package prices, API revenue shares, and usage restrictions all provide clues for assessment. The truly valuable data is not how many paying users there are but rather how many light users and heavy users exist, whether enterprise customers are willing to pay higher prices for intensive usage, whether cloud settlement costs are declining, and whether reductions in unit inference costs can translate into company gross margins.
Verification in the chains of publicly listed companies will appear more quickly in their financial reports. NVIDIA's overall gross margins and data center revenue growth rates, TSMC's advanced process and packaging demand, HBM manufacturers' prices and margins, and cloud vendors' intensity of capital expenditures will all continue to reflect whether AI usage is transmitting toward infrastructure. If these indicators remain strong while the model application layer lacks evidence of gross margin improvement, the market will continue to assign a more certain valuation premium to the infrastructure.
Ultimately, for model companies to regain higher valuation anchors, they need to prove not just that users are willing to pay $20 but that these subscription fees can still yield sufficient gross profit after heavy usage. The next round of pricing divergence is likely to occur not in the headline number of ARR but in whether inference costs, package limitations, and enterprise payment prices can all run smoothly together.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。



