Original | Odaily Planet Daily ( @OdailyChina )
Author | Asher ( @Asher_ 0210 )

In the past few weeks, discussions about AI + Crypto have heated up again.
From AI x Blockchain related conferences in New York to the recently concluded Web3 conference in Hong Kong, almost all mainstream participants are re-discussing the same question: How will AI change the next phase of the crypto industry?
However, compared to past rounds that were more narrative-driven, this round of discussions began to shift to a more specific question: what exactly has AI solved.
In a fireside chat themed "Reshaping Convenience: The Next Decade of Web3, AI, and the Smart Economy," Binance Co-CEO He Yi mentioned that as the industry matures, the early dividends of the crypto market are fading, and what matters next is not the technology itself, but whether the products truly have value and whether anyone is willing to pay for them.
This also means that AI is no longer just a new growth narrative but is being placed back into a more concrete context, where people begin to ask more directly what practical effects it can bring.
This change has gradually manifested, especially in user-facing application layers. In the Web3 space, a batch of applications built around AI are emerging. Some are reconstructing the way information is obtained, others are redefining the ownership of data and memory, and some are beginning to combine on-chain research, transactions, and even economic models with AI.
These projects may not be fully mature, but they are pointing towards a more realistic direction. As the dividends gradually recede, the combination of AI and crypto begins to return to the products themselves.
This article selects several representative Web3 AI projects, sorting through the practical progress of this round of applications from information, memory, operations to Agent economy and distribution.
Surf: A Real-Time Encyclopedia for the Crypto Market
Surf is a typical information layer product in this round of AI applications. It does not attempt to reconstruct the trading process, nor does it focus on creating a new economic system, but rather returns to a more fundamental yet long-ignored question—obtaining information in the crypto market remains a costly affair.
On-chain data, market fluctuations, social sentiment, and project information are often scattered across different platforms. Users need to switch back and forth between multiple pages to piece together a relatively complete market judgment. This sense of fragmentation becomes more pronounced during heightened market volatility; the problem is not a lack of information but rather that information is scattered and contains time lags. The idea behind Surf is to integrate these information sources into a unified AI entry point, allowing users to obtain structured conclusions through simple descriptions, compressing the “finding data” step as much as possible and directly entering the “making judgments” stage.
In actual use, it is more like an all-day online researcher. Users can track the capital flow and sentiment changes of a particular token, analyze the TVL and yield structure of DeFi protocols, monitor the movements of whale addresses, or quickly generate a due diligence report that can be used for trading decisions or communication preparations. Compared to traditional tools that require users to select, assemble, and interpret information themselves, Surf outputs the organized results more directly, thereby shortening the path of "obtaining information - forming judgment."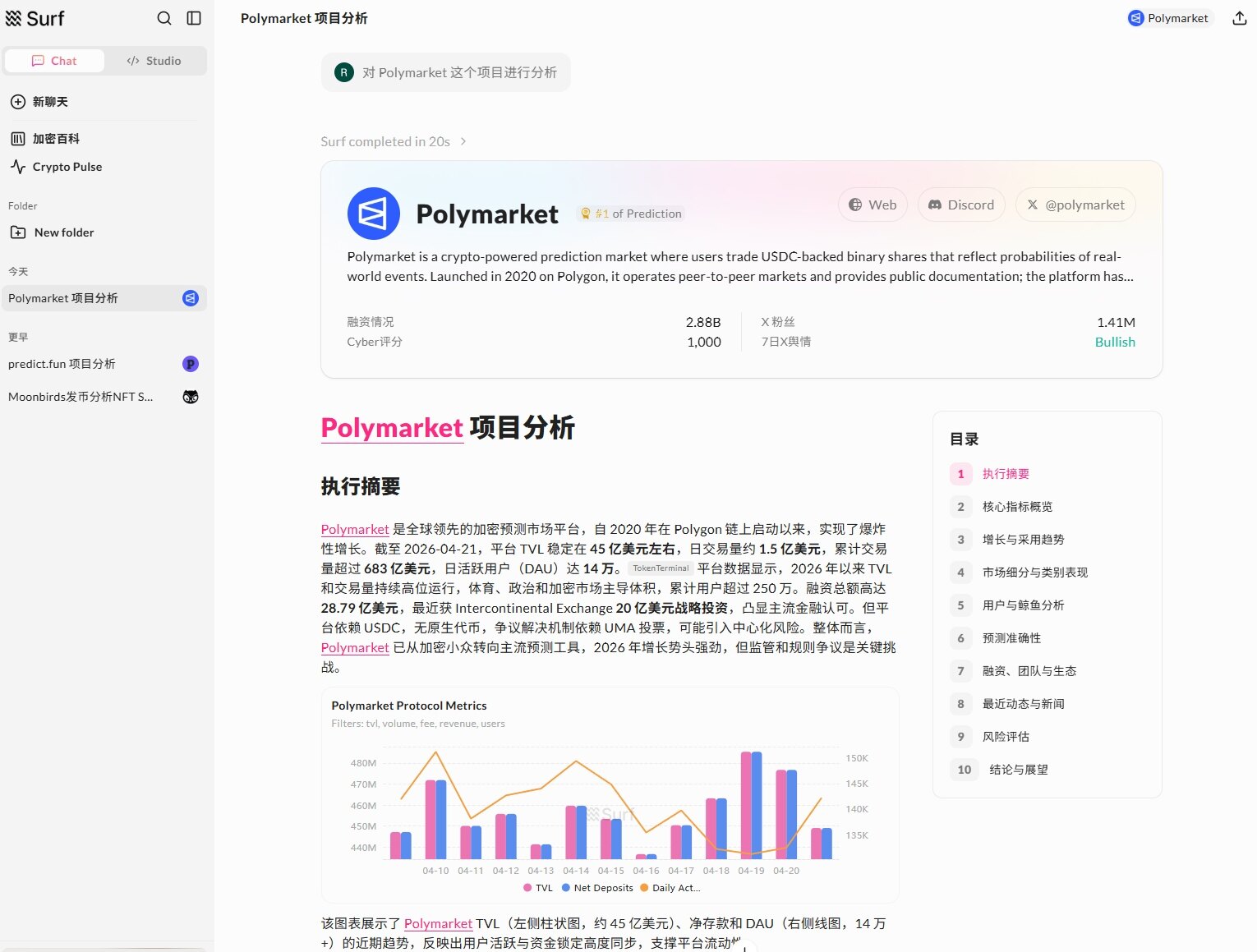
On this basis, Surf has begun to evolve from an "information tool" to a "workflow platform." The newly launched Surf 2.0 and Surf Studio allow users to directly build analytical tools or even simple Web Apps using natural language and deploy them for immediate use, no longer relying on traditional development processes. Meanwhile, Surf integrates multi-model capabilities from OpenAI, Anthropic, Google, etc., and connects to dozens of data sources and on-chain interfaces, making the generated analytical results not just text but also tools for continuous monitoring and decision-making.
At a deeper level, it is gradually building a capability system aimed at Agents. Through APIs and an Agent Stack, users can assign specific tasks (such as whale address monitoring, capital flow tracking, or strategy signal prompting) to AI for continuous execution instead of querying manually each time. This means that Surf is no longer just a passive query entry point but is transitioning into a research system that can operate long-term.
However, its capability boundaries are also clear. The core of Surf remains concentrated on information integration and analysis, and it has not truly entered the trading execution stage, such as automatic ordering or strategy execution, which still requires users to complete themselves. This also determines that it is more suitable as a decision support tool rather than a system that can independently complete the trading loop.
From an industry perspective, such products represent an early landing form of AI applications. Rather than directly challenging the complex process of trading execution, it is often easier for users to accept improving the efficiency and ease of "understanding the market." Before trading is fully automated, the enhancement of information processing efficiency remains the most direct and easily perceivable value for users.
Anuma: A Sovereign Memory Repository for the AI Privacy Era
In the past two years, AI has almost become a common keyword in the global tech circle. From model competitions in Silicon Valley to the pursuits of AI applications and capital narratives in New York and Hong Kong, the focus of industry discussions has been rapidly changing. In the past, this competition mainly revolved around model capabilities—reasoning, multi-modality, Agent execution capabilities—with nearly every round of product updates answering the same question: whose model is smarter, more accurate, and better at completing complex tasks.
However, as model capabilities continue to improve, it has become increasingly difficult to form long-term differences by simply comparing the models themselves. Entering a new phase, how AI can remember users long-term and continue these memories in writing, research, decision-making, and daily communication has begun to become a new focus of discussion. This means that AI's moat is shifting from model capability to memory capability. The model determines what AI can answer, while memory determines whether AI can truly understand a long-term user.
However, today’s AI memory does not truly belong to the user. In current mainstream AI products, dialogues, preferences, and usage habits are continuously recorded, forming an experience that understands users better over time. But these memories are usually locked within their respective platforms, controlled by the platforms, making it impossible to freely migrate or for users to genuinely control them.
This means that AI is accumulating users' digital personas, but the ownership and control of this data often still belong to the platform. The longer the usage time, the more memories accumulate, and the higher the cost for users to switch models. What truly locks users in is not necessarily the model itself, but those long-term accumulated memories that cannot be taken away.
Anuma is precisely cutting into this layer. As the flagship product of ZetaChain's foray into AI, Anuma does not just serve as an application entry point. More accurately, ZetaChain aims to build an AI memory system controlled by users as a foundation; Anuma serves as the user-facing AI interaction entry point of this system.
In other words, ZetaChain is responsible for building the underlying memory capacity, while Anuma is responsible for bringing this capability into daily AI usage scenarios. What Anuma aims to do is pull memory out from the model, allowing users to manage, call, and extend their long-term memories for the first time in actual use.
Specifically, users can import their complete dialogue history from ChatGPT, Claude, or Grok into Anuma, complete encryption locally, and store it in a Memory Vault controlled by themselves. More importantly, this process prioritizes privacy protection before data enters the system; users retain control from the outset rather than passively choosing to authorize after the platform has already acquired the data.
These memories are no longer attached to a single platform but can be taken away, reused, and continued across different models. They are locally encrypted, portable, not bound to a single model, and can continue to accumulate with long-term user utilization.
From the actual experience perspective, Anuma is primarily a unified entry point that aggregates multiple cutting-edge models. Users only need one subscription to access the latest models of GPT, Claude, Grok, etc., without needing to switch repeatedly between different platforms.
More crucially, when users switch between different models, the memories they have formed will not be reset. In Anuma, models like GPT and Claude are closer to the capability layer, while the user's own memories remain consistent. Regardless of which model is used, past communication records, expressions, and preferences can all be continued rather than cleared.
Anuma also offers a multi-model council mode (Council Mode), allowing users to receive different perspectives on the same question from multiple models for comparison. For research, writing, and complex judgments, this experience is more like having multiple AIs participate in a discussion simultaneously rather than relying solely on one model's output.
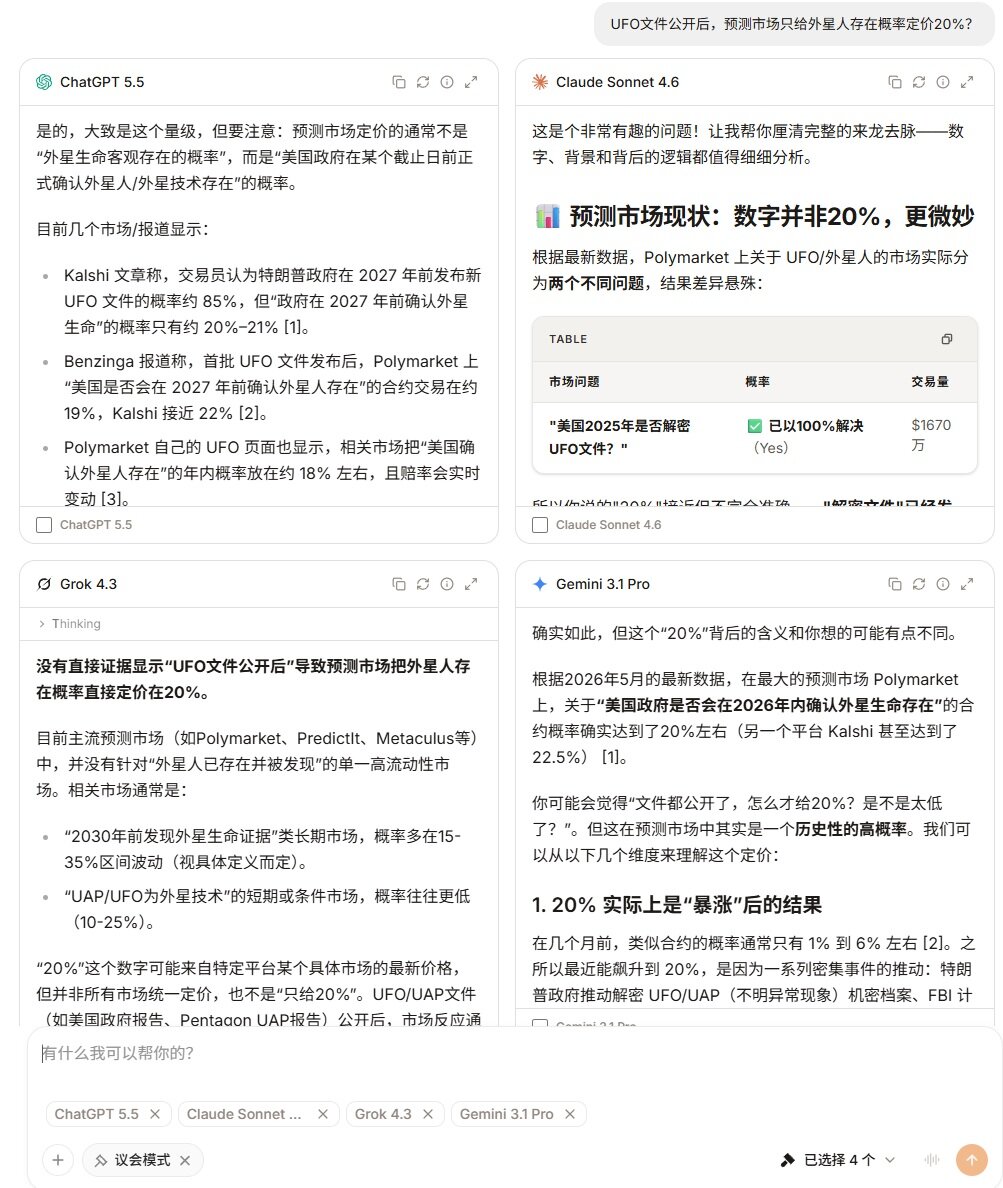
Additionally, Anuma supports users to interact directly with AI via iMessage. Each Agent can be called like a contact and even added to group chats. Compared to having to open a specific application to initiate a conversation, this method is closer to daily communication scenarios and makes the AI entry lighter. Even in situations with weak network signals or when applications cannot be opened, users can still invoke AI, and the relevant conversations will enter the same encrypted memory system without interruption due to changes in entry points.
From the product form perspective, Anuma is not just a multi-model entry point but is building a memory system independent of the models. In the past, users' dialogue records, preferences, and usage habits often relied on specific platforms; however, as AI becomes a long-term tool, these continuously accumulated memories will become the foundation for understanding users.
This is also why ZetaChain attempts to cut into the next generation of AI infrastructure, with Anuma serving as the user entry point. Models can continually upgrade and be replaced, but users' long-term accumulated memories should not be locked with the platforms. The future competition of AI products may not only focus on whose models are stronger but also on who can truly allow users to own, access, and extend their own memories.
In the age of AI, memory is becoming part of identity. And identity should belong to the user.
Nansen AI: Turning On-Chain Research and Transactions into "Conversational Operations"
When the question shifts from "who owns the data" to "how to use the data," another type of product begins to focus on more specific operational aspects. What Nansen AI does is compress the originally scattered steps between on-chain research and actual transactions into a single path.
In traditional on-chain research, users often need to switch back and forth between multiple dashboards, manually querying capital flows, address behaviors, and token data, then completing operations based on personal judgments. While this process is not complicated, the steps are cumbersome, and there is a clear disconnection between information and execution. The idea behind Nansen AI is to reconnect these two parts.
Users can ask direct questions in natural language to obtain information such as on-chain capital flows, Smart Money trends, and token movements without needing to query item by item. For example, asking about the reasons behind a token's rise, analyzing a specific address's profit and loss status, or directly parsing a transaction, all these can be completed within the conversation. This approach essentially abstracts "research" from the operational process and compresses it into a continuous conversational flow.
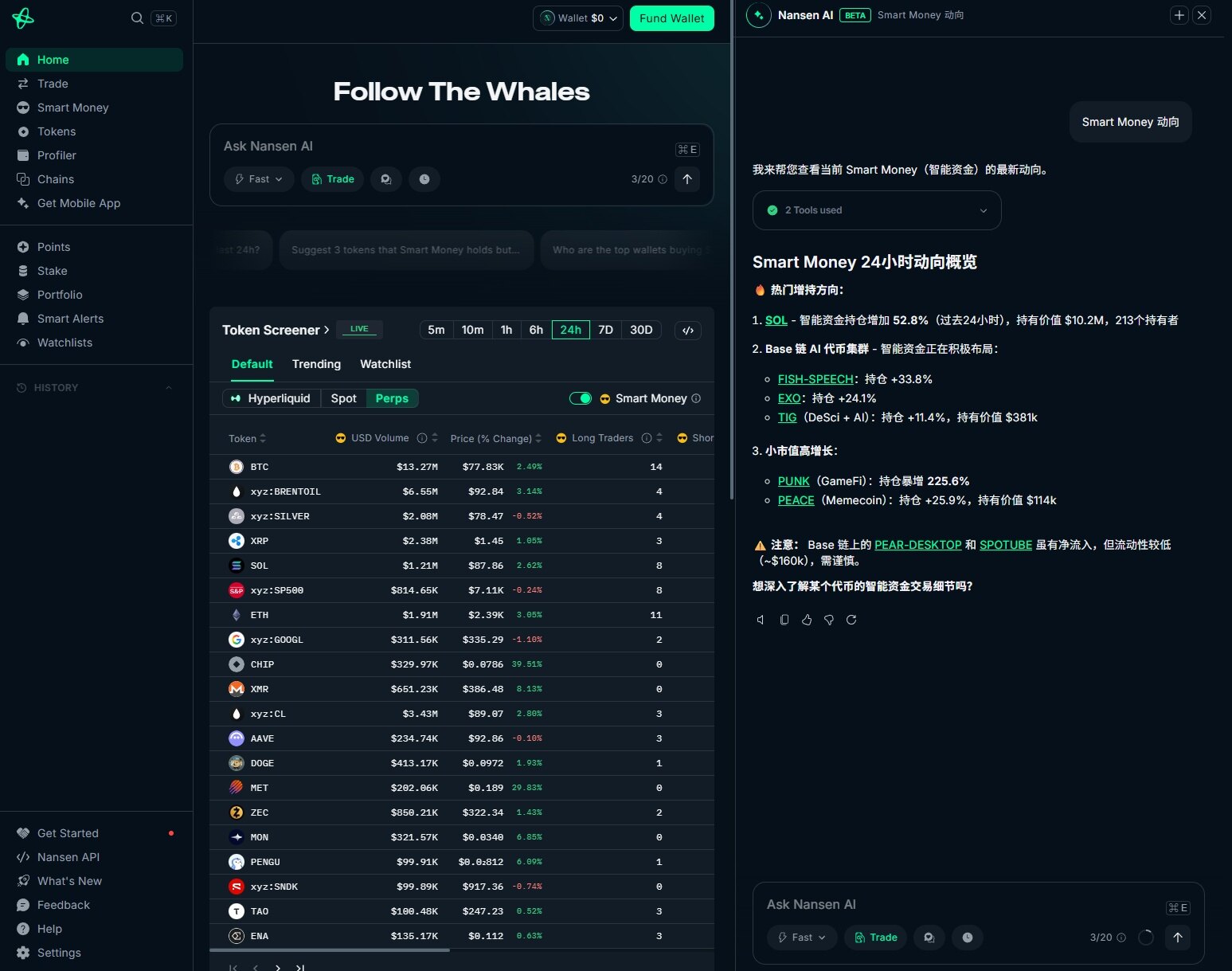
Furthermore, Nansen AI is attempting to connect information retrieval with actual operations. In some scenarios, users can directly complete on-chain interaction actions such as transfers or swaps through conversation, compressing the originally scattered research and execution processes into the same path. This also means that Nansen AI no longer just provides explanations but is gradually moving closer to the operational aspect.
This extension is predicated on its long-accumulated on-chain data capabilities. Based on a large volume of labeled addresses and real-time data, the system can identify sources of funds, track large transactions, and provide more targeted analytical results based on holding situations. It is precisely because of this data foundation that it can undertake specific operations beyond conversation.
Under this structure, the positioning of Nansen AI has also changed. It is no longer just an information tool but is closer to the connection point between the data input layer and operation interface in trading decisions. However, this type of "conversational trading" is still in its early stages. AI is more about lowering the operational threshold and cost of information retrieval rather than replacing users in strategy judgment. Whether for asset allocation or risk control, the final decision still needs to be made by the user.
Overall, what Nansen AI represents is another path for AI applications—extending further into the execution layer above the information layer. It does not change the logic of trading itself but offers a lighter and more direct approach to "how to complete a trade." Compared to purely information tools, this capability of connecting "research" with "operations" is more likely to enter real usage scenarios first.
Virtuals Protocol: Turning AI Agents into "Tradeable Economies"
Once AI starts to take part in operational processes, the questions extend further—if these Agents are not just auxiliary tools but can independently provide services and continuously create value, can they be incorporated into a complete economic system?
The attempt of Virtuals Protocol is precisely unfolding along this direction.
In traditional AI products, Agents are more viewed as tools, lacking independent economic attributes. They can complete tasks but cannot directly participate in value distribution, nor can they form sustainable business models. The idea of Virtuals is to transform Agents from "functional units" into "economic participants."
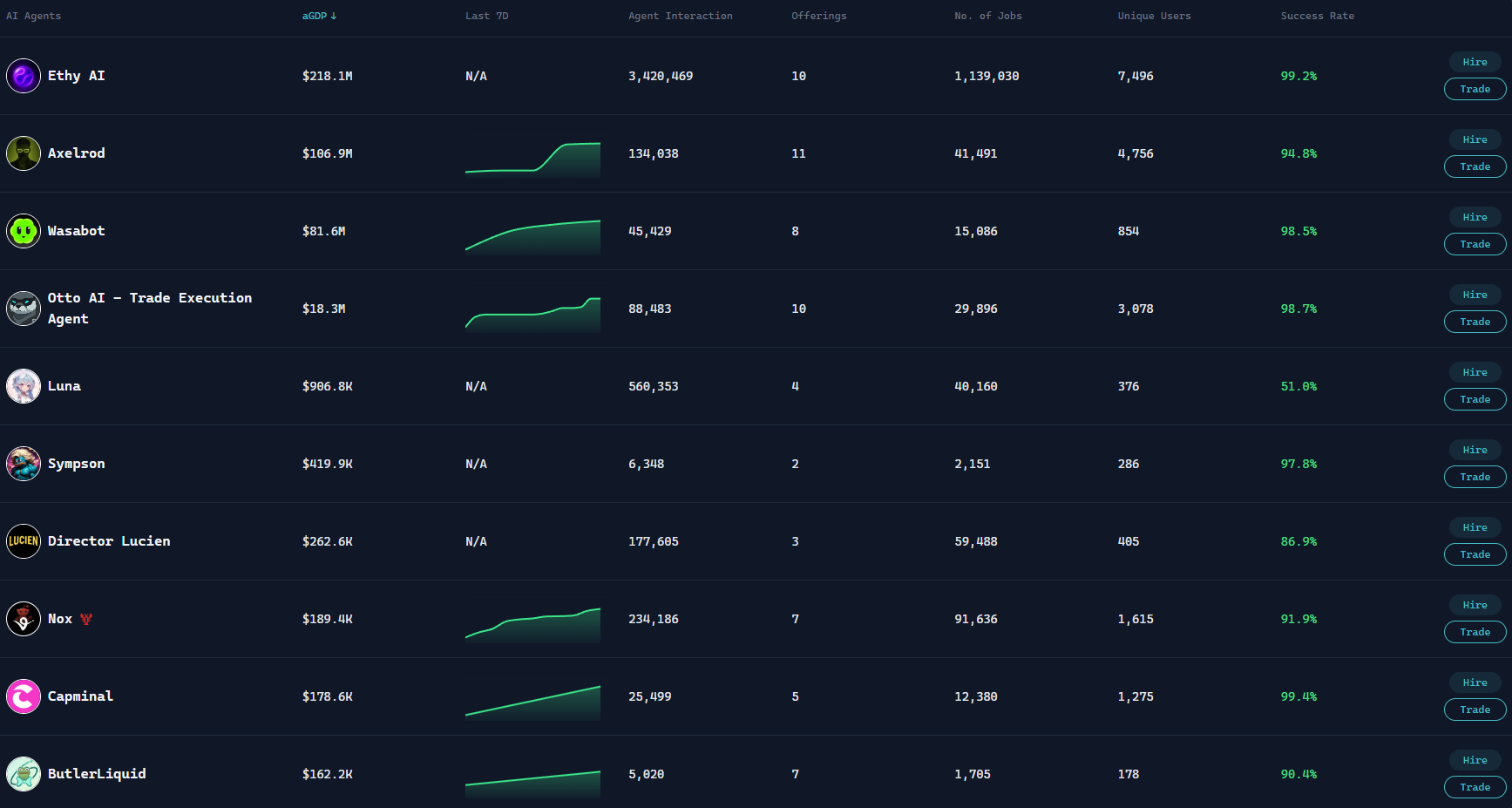
In this system, each Agent can be tokenized, thus acquiring the ability to secure financing, incentivize, and distribute earnings. Developers are no longer just releasing an AI tool but can build a complete economic model around a particular Agent, allowing it to continuously generate value during its usage. As such, AI is no longer just a once-off delivered product but is closer to a long-term operable asset.
Structurally, Virtuals provides a complete set of infrastructure including collaboration, settlement, and issuing. Agents can work collaboratively with users or other Agents to complete tasks and achieve value exchange through on-chain mechanisms. Additionally, through a launch mechanism, Agents themselves can also obtain liquidity support, thus forming pathways for pricing and capital formation.
Compared to the earlier projects that primarily focus on "how to better use AI," Virtuals is more concerned with "how AI itself participates in economic activities." It attempts to push AI from the tool layer into production relationships, allowing Agents to become entities that can independently create value.
However, from the current stage, this direction is still in its early phase. On one hand, there are still not many Agents that truly have stable usage demands and income capabilities, and practical applications within the ecosystem remain in the validation process; on the other hand, collaboration, pricing, and trust mechanisms among Agents also require more time to establish.
From an industry perspective, what Virtuals represents is a more long-term path within AI + Crypto. It does not directly optimize users' current experience but attempts to build a new infrastructure, enabling AI to possess more complete economic attributes in the future. This direction may not be the easiest to perceive in the short term, but once successful, it could change AI's role within the entire system.
Warden: Enabling AI Agents to be Utilized, Distributed, and Monetized
As the number of Agents increases, the challenges often lie not in the capabilities themselves but in whether the use cases can materialize. Compared to model capabilities or singular functions, the difficulty for most Agents is not "can they do it?" but rather "is there anyone using them?" They are scattered across different frameworks and entry points, lacking a unified distribution channel and clear payment and collaboration methods. This is precisely where Warden comes in.
Its approach is not complicated, but rather builds a complete set of usable infrastructure around Agents. For users, it allows calling different Agents from a unified entry point, completing transactions, cross-chain actions, queries, and more through natural language, integrating originally dispersed functions into a continuous usage process. For developers, it enables quick creation and deployment of Agents, directly providing services to users while completing fees and settlements through on-chain mechanisms.
On a deeper structural level, Warden manages Agent identities and invocation processes through specially designed chains, ensuring that each Agent has an independent form of existence. It can charge fees and invoke other Agents, gradually forming collaborative relationships. Meanwhile, through distribution points similar to app markets, Agents have the opportunity to be discovered by users rather than sinking into the system after being launched.
Compared to earlier AI projects, Warden is closer to the platform layer. It does not emphasize a specific capability but attempts to organize these capabilities to make them findable, usable, and to establish stable usage pathways.
This path relies more on scale. If there are not enough Agents and users, distribution and monetization will be challenging to operationalize, and this is something that cannot easily be "designed" in the short term. So at this stage, Warden resembles a project gradually assembling these foundational elements. First, allow Agents to be released, create pathways for invocation, and establish mechanisms for charging, so that when the usage scale increases, this layer has the opportunity to truly start operating.
From Narration to Utilization, AI is Entering Real Scenarios
When observing this round of AI + Crypto exploration over a longer timeframe, a change is beginning to become clear. The industry's focus is shifting from "Is there a new narrative?" to "Are there sustainable usage scenarios?"
From Surf to Anuma, from Nansen AI to Virtuals and Warden, different projects have chosen entirely different entry points, but they all point to the same question: In a phase where dividends are gradually diminishing, why should users stay, and what cost are they willing to pay for this?
It can be seen that a few relatively clear paths have emerged. One category is reconstructing information and decision processes, improving users' efficiency in understanding the market; another category is redefining the ownership of data and memory, attempting to establish longer-term user relationships; and yet another category is extending towards execution and economic structures, making AI not just an auxiliary tool but starting to participate in value creation and distrib
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





