1. Core Summary
Chutes (SN64) is a decentralized Serverless AI computing platform built on the Bittensor network. In the AI computing track of Web3, its core positioning is akin to a "ride-hailing platform" and model PaaS (Platform as a Service). The platform integrates globally dispersed idle GPU computing power and combines advanced container orchestration technology to provide developers with ready-to-use, on-demand AI inference APIs. At the underlying architecture level, Chutes employs a classic dual-role game mechanism: miners provide underlying hardware to respond to external requests at any time, while validators evaluate quality in real-time and assign weights, thereby forming an industrial-grade inference network that combines low costs with high concurrency capability. Currently, Chutes has pioneered a genuine business closed loop in the decentralized computing field, having processed over 91 trillion tokens, possessing more than 400,000 active users, and becoming the first self-reported subnet in the Bittensor ecosystem to surpass a valuation of 100 million dollars. By feeding the real business revenue back into token value, Chutes has the potential to develop into a unicorn-level infrastructure in the decentralized AI track over the long term.
2. Industry Background: The Rise of AI Inference and the Dilemma of Web2 Models
2.1 What is Model Inference? The Essential Difference from Pre-training
Before delving into the computing power platform, we need to clarify two core phases in the AI model lifecycle: Pre-training (Training) and Inference.
Model Pre-training: This is the "learning phase" of the AI model. Researchers need to input massive amounts of data (such as text corpuses from the entire internet) into the neural network, continuously adjusting billions or even trillions of parameters inside the model through large-scale matrix multiplication. This process is extremely time-consuming and requires high interconnection bandwidth among cluster computing power (like NVLink), representing a significant capital investment in concentrating efforts to accomplish big tasks.
Model Inference: This is the "application phase" of the AI model. Once the model training is completed, the parameters are fixed. At this stage, users input a prompt, and the model generates the next word with the highest probability through forward pass calculations. Compared with training, the single instance of computing power required for inference is smaller but demands high concurrency, ultra-low latency response, and 24/7 system stability.
2.2 Development Logic of the Computing Power Track and Shift in Industry Focus
Looking back at the development of the computing power track, we can clearly see an evolutionary main line: from early CPU general computing to the rise of GPU parallel computing (the establishment of the CUDA ecosystem), to the current blossoming of TPU and ASIC chips specifically designed for AI. In recent years, capital and technological focus has overwhelmingly concentrated on "how to train smarter models." However, with leaps in capabilities of open-source large models like Llama series and DeepSeek, the intellectual gap between open-source models and closed-source giants (like GPT-4) has rapidly narrowed. The value capture focus of the AI industry is irreversibly shifting from "model pre-training" to "model inference." The reason is that for large models to achieve real large-scale commercialization and empower various industries, they must possess high availability and low latency response 24/7. At this point, "how to run models cheaply, stably, and quickly" has become the industry's biggest pain point.
2.3 AI Inference Participants in the Web2 Era and Core Limitations
The current Web2 inference track is mainly dominated by the following types of participants:
Closed-source model API providers: Such as OpenAI (ChatGPT), Anthropic (Claude), Google (Gemini). They offer extremely user-friendly APIs but operate as black boxes, with high costs and strong ecological binding.
Traditional cloud service giants: Such as AWS (Amazon Cloud), Microsoft Azure, Google Cloud. They provide underlying virtual machine or bare GPU rental, high flexibility but with significant operational costs.
Niche inference as a Service (MaaS) platforms: Such as Together AI, Anyscale, HuggingFace Inference Endpoints. They specialize in providing inference hosting services for open-source models.
However, when developers use services from these Web2 giants (like OpenAI API, AWS, or Together AI), they still face three insurmountable mountains: Expensive "computing tax" and rough settlement granularity: The hardware and software depreciation (location rent, cooling systems, high server procurement) and maintenance costs in centralized data centers are extremely high, resulting in high API call costs passed on to developers. Additionally, traditional cloud computing usually charges "by the hour" or "per machine", which is unfriendly to large-scale applications requiring massive instantaneous concurrency, often leading to severe resource wastage during non-peak times.
Complex "infrastructure pitfalls": For startup teams attempting to bypass cloud vendor APIs and deploy open-source large models by self-renting machines, they must face an extremely steep learning curve. They need to solve complex GPU selection, underlying driver configuration, inference acceleration frameworks (like vLLM, TensorRT) tuning, node maintenance, and containerized cluster orchestration issues, making the engineering threshold very high.
Vendor lock-in and data privacy risks: Once enterprises are deeply bound to specific cloud vendors' API services, their future technical roadmap expansion and cost structure will be entirely dependent on others. More critically, for highly sensitive industries like healthcare, finance, and law, transmitting core business private data to centralized API servers for processing holds a high risk of data breaches and compliance issues.
3. Breaking the Dilemma: Chutes Restructures AI Inference with “Network”
3.1 Core Positioning: A "Ride-hailing Platform" in the AI Ecosystem and Decentralized PaaS
Within the large and clearly defined Bittensor ecosystem, each subnet has its specific role. For example, Templar (SN3) acts as a "car manufacturing factory," with the core task of aggregating computing power to train top-tier open-source models from scratch; in contrast, Chutes (SN64) has a completely different focus, concentrating on "operational services" and serving as a "ride-hailing platform" in the Web3 era.
Chutes itself does not produce models but efficiently integrates globally distributed "vehicles" (i.e., idle GPU computing power scattered across the world) through its network protocol, allowing ready-to-use, top-tier open-source models to operate efficiently on these nodes, thereby providing seamless inference services to external developers. Essentially, Chutes has built a decentralized, open-source-friendly, and highly standardized underlying PaaS (Platform as a Service) infrastructure on top of the blockchain.
3.2 A Genuine Serverless Experience and Extreme Cost Advantages
The core revolution brought to developers by Chutes lies in realizing a true Serverless experience. When using Chutes, developers do not need to worry about underlying hardware selection, environment configuration, or cluster maintenance; merely modifying a few lines of code allows smooth access to the network via an API fully compatible with OpenAI formats. In terms of cost control, leveraging the native micropayments mechanism of blockchain, Chutes achieves an industry-rare "billing per single token" ultra-fine-grained settlement. This disruptive billing method completely eliminates the resource wastage caused by traditional cloud hosts billing by the hour. In practical applications, this advantage makes its prices approximately 85% cheaper than traditional cloud services (like AWS) and saves at least 40% compared to most centralized API platforms in the market.
3.3 Privacy Upgrade: TEE Architecture Builds a Trust Flywheel
In a decentralized network, how to protect user inputs to anonymous nodes (prompts) and business data has always been a major challenge. Addressing enterprise-level users' deep concerns about privacy, Chutes is currently promoting the deployment of TEE (Trusted Execution Environments) throughout its network. TEE technology uses hardware-level encryption methods to isolate a strictly protected memory area within the CPU/GPU. This means decentralized nodes can process inference requests in an encrypted "black box," where even the miners providing the computing power absolutely cannot peek at users' sensitive input data during the entire calculation process. The introduction of this underlying technology fundamentally resolves compliance and privacy pain points for enterprise-level commercial deployment in decentralized networks, clearing obstacles for large-scale adoption by Web2 enterprises.
4. Core Architecture: How AI Inference is Completed in the Network
In Chutes' underlying distributed architecture, the system distributes massive inference tasks across the global network through complex routing and load-balancing mechanisms. Its core participants are clearly divided into two categories, ensuring final service quality through sophisticated cryptography and economic market games:
Miners (Service Providers): Computing power nodes from around the world connect to the system through staking and must load the "permanently hot models" specified by the system based on network commands. "Hot models" mean that the massive parameters of the models have been preloaded into the GPU’s video memory (VRAM). Based on advanced container orchestration technology, these computing power nodes must maintain high system availability at all times to accommodate the sudden influx of high-concurrency API requests with very low cold-start latency.
Validators (Quality Inspectors): In a decentralized network, there is no central institution for supervision, hence reliance on validator nodes is necessary. Validators are responsible for continuously sending randomly generated test requests to miners and routing genuine business requests, rigorously scoring the miners' services on multiple core dimensions such as response latency (time-to-first-token, TTFT), throughput (the number of tokens generated per second), and output accuracy. Well-performing miners will receive substantial network token rewards, while poorly performing or malicious miners will be ruthlessly eliminated by the system and may even have their staked deposits confiscated.
This decentralized gaming architecture based on Bittensor's underlying consensus cleverly transforms interest-driven elements into service quality guarantees, ensuring that even loosely distributed networks can continuously deliver industrial-grade system stability comparable to centralized top-tier data centers.
5. Economic Engine: Transitioning from "Inflation-Driven" to "Real Blood Generation"
In past cycles of the crypto world, many early Web3 computing projects fell into a death spiral: they excessively relied on the vicious release of token inflation to subsidize the attraction of computing power (so-called "mining"), and once the secondary market performed poorly, computing power would rapidly dissipate. In contrast, Chutes' core competitiveness lies in its successful implementation of a healthy decentralized commercial closed loop.
Currently, the Chutes network can steadily handle massive real B-end (enterprise-level) and C-end (end-user) API requests daily. Through the token system, the network charges these users real service fees. More crucially, relying on the system's built-in automatic staking and settlement mechanisms, these business revenues derived from the external real world (which may begin with fiat payments) will ultimately translate directly into strong buying pressure on the network's ecological assets (tokens). This mechanism continuously feeds back into token holders and participants maintaining the network, truly realizing a transition from a "burning money to buy computing power" Ponzi model to a "real business generating blood" sustainable economic model.
6. Ecological Status and Remarkable Data Performance
As of recent on-chain and business data tracking, the Chutes network has demonstrated extremely strong throughput limits and deep market penetration in actual high-concurrency business scenarios.
Core business volume breaks records: The Chutes network has processed over 91 trillion tokens, a significant figure across Web3 and many mid-sized Web2 platforms. Its daily peak processing volume can reach up to 50 billion times, serving over 400,000 end and developer users cumulatively.
Absolutely leading market position: With solid business data, Chutes has become the first self-reported subnet in the entire Bittensor ecosystem to exceed a valuation of 100 million dollars.
Deep ecological integration and "water, electricity, and coal" attributes: Externally, Chutes has successfully serviced numerous breakout applications. Internally, Chutes has gradually become a core computing power provider for other subnets within the Bittensor ecosystem (focused on various niche applications and data processing), playing a crucial role akin to "water, electricity, and coal" for the entire decentralized AI ecosystem.
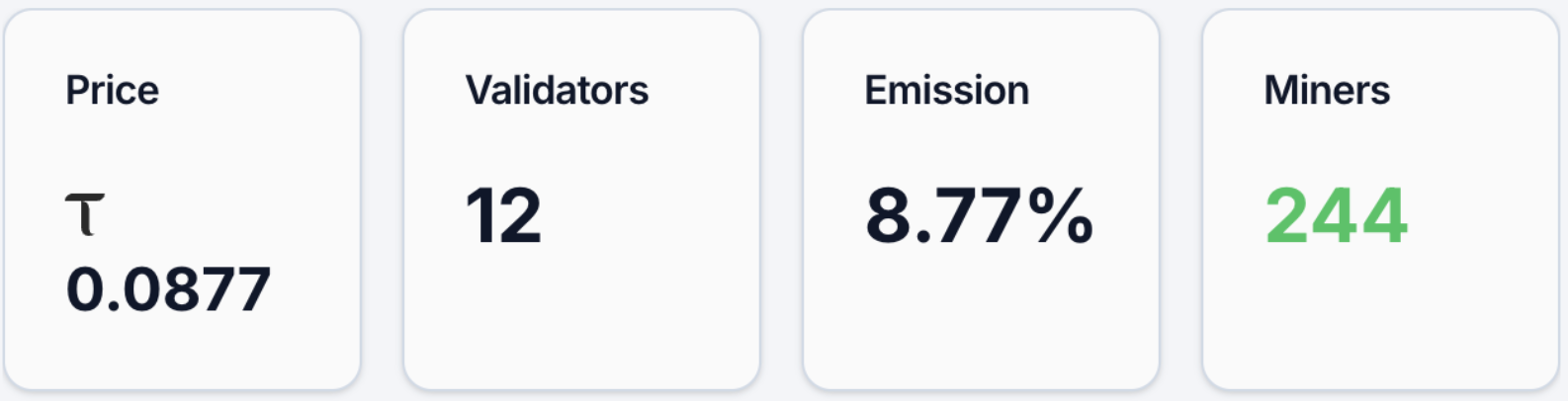
Robust token economic indicators: As of April 7, 2026, the subnet token Alpha (alpha token) price is approximately 0.085 TAO. The network has attracted around 13,666 address holders, with 244 active miner nodes and 12 validator nodes. Its network emission share is 8.77%. Moreover, in its DEX liquidity pool, the underlying TAO account for 7.88%, while Alpha accounts for 92.12%. From both computing power scale and funding volume perspectives, Chutes is an absolute top project within the TAO ecosystem. These data clearly reflect its actual market heat:
(Data source: https://bittensormarketcap.com/subnets/64)
7. Competitive Landscape, Potential Challenges, and Future Outlook
7.1 Core Advantages and Track Moat Barriers
The current decentralized computing (DePIN + AI) track has completely bid farewell to the "concept-heavy, white paper writing” wild era and entered the deep water zone of "delivery, cost, and stability competition." Compared to platforms that only offer bare machine rentals, Chutes’ most powerful moat lies in its commercially validated delivery capacity for reasoning and its absolute cost advantage over traditional Web2 giants. Combining with the future full-scale deployment of the TEE privacy encryption architecture, Chutes successfully provides developers fearing the monopoly and data hegemony of Silicon Valley giants with a completely permissionless and highly cost-effective ideal infrastructure.
7.2 Potential Challenges and Breaking Through Difficulties
Despite the current impressive business data and model circulation, Chutes still needs to tackle some hardcore challenges to transition from Web3 to a broader mainstream world. Extreme concurrent redundancy and elastic testing: When genuinely "killer" AI applications with millions of daily active users emerge and suddenly access the network within a short time, whether the decentralized network can guarantee maintaining millisecond-level low-latency responses without downtime under surging computing power demands will be the ultimate test of the scheduling algorithm. Breaking through enterprise-level market perceptions: Although equipped with TEE technology, breaking the traditional stereotypes held by Web2 companies to gain the trust and large-scale adoption of decentralized API protocols among compliant enterprises will still require prolonged and continuous market education and cultivation.
7.3 Final Outlook
In summary, as the era of high-frequency, autonomous interactions between multimodal large models and AI agents fully arrives, the dialog between machines will generate an exponentially increasing demand for inference. At this point, a low-cost, unrestricted, on-demand micropayment-supported decentralized inference layer will surely become an indispensable basic infrastructure for the next generation of the internet. What Chutes represents is not only the decentralization of the allocation method for underlying computing resources but also a larger-scale distribution of open-source intellectual resources for human society. If Chutes can successfully overcome the high barriers of traffic accommodation and trust gaps for traditional enterprise adoption, it is highly likely to grow into a super platform with long-term value capture capabilities in the decentralized AI track within the next few years.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。




