Written by: Silicon Valley Alan Walker
During afternoon tea, watching this launch event from Palo Alto
On April 21, 2026, at exactly 12 PM, OpenAI held a livestream on its official website, where Sam Altman personally took the stage to launch a new product called ChatGPT Images 2.0, with the underlying model named gpt-image-2.
A few key facts:
All ChatGPT users (including free users) can access it
Paid users (Plus, Pro, Business) unlock an additional mode called Thinking— the model will "think" before drawing, can search online, analyze uploaded materials, and produce a maximum of eight consistent images with characters and styles at once
API opens simultaneously, the model ID is gpt-image-2, supporting any ratio from 3:1 to 1:3, with a maximum resolution of 2K
Natively integrated into the Codex coding environment, no separate API Key is required
Altman's original words on stage were, "This upgrade is like jumping from GPT-3 to GPT-5." The opening line of the official blog is worth quoting here:
"Images are a language, not decoration."
Then on Twitter, @OpenAI shared a self-generated video as a demonstration in the post from April 21, captioned with "state-of-the-art image model that can take on complex visual tasks."
Next, Alan wants to break down and discuss eight things that have been contemplated back and forth during this afternoon tea, most of which haven't been pinpointed by the media and Twitter KOLs yet.
Before the tea cools: What was released today is not an image model
At 4 PM in Zombie Café, California Avenue looked the same as usual. Just after brewing the second cup, the notifications exploded. TechCrunch, VentureBeat, The Decoder, Tom's Guide, Engadget, Axios— all published articles within the same hour.
Ninety-nine percent of the headlines picked one of three sentences: "Text rendering has improved," "Can draw comics now," "Chinese no longer appears garbled."
All of this is true, but it's all superficial.
Alan stared at the opening statement from the OpenAI official blog for a long time—"Images are a language, not decoration." This is not a poetic line, it's a strategic statement.
For the past three years, image generation has been an "add-on feature" in OpenAI's product line—DALL-E 1 was a toy, DALL-E 3 was an embedded tool, GPT-Image-1.5 was functional but not robust enough. Today, the positioning of gpt-image-2 has changed, from "a model for drawing" to "the foundation of the visual modality."
Altman's statement in the livestream, "From GPT-3 to GPT-5," translates into plain language as:
The image leg, OpenAI will no longer treat it as a side line; starting today, it is part of the backbone.
To understand everything I will mention later, you must first grasp this fundamental judgment—what was released today is not a product update, it is a product repositioning.
First, look at the price, don't look at the images: $30 for one million tokens, images have been slotted into the textual economy
Most people watch the launch event for product features, but Alan first looks at the Pricing page. The API pricing structure for Images 2.0 is the most significant he has seen in twenty years in the industry:
| $8.00 | |
| $30.00 | |
Do you get it? Images and text use the same pricing unit—tokens.
In the past, image generation used to be charged as "2 cents per image, 7 cents per image, 19 cents for a high-definition image," which was selling "images." Today, OpenAI has changed the rules; images are billed by tokens, placed side by side with text on the same pricing table.
What does this mean? It means that starting today, images are no longer consumer goods, but the smallest primitives in the agent economy— just like text, they can be automatically invoked by AI, measured by bytes, combined in a streaming manner, and assembled programmatically.
An agent running inference can write a piece of code, generate some text, create an image, then write another piece of text— all as one bill, settled in the same unit. This is why OpenAI dares to say "Images are a language"— because from the moment it started billing, it truly became a kind of language.
By the way, fal.ai launched its enterprise-level API on the same day, priced at $0.01 per image (low quality) to $0.41 per image (4K). OpenAI officially maintains a high end at $30/M output, allowing infrastructure providers like fal, Replicate, Fireworks to focus on the low end— not competing in the low end, which is a typical Altman strategy.

Eight consistent images with one click: The revision invoice from the advertising agency has been delivered to the client
The most talked-about capability of the Thinking mode is "to output a maximum of 8 consistent images of characters, styles, and scenes at once." All media are discussing comics, storyboards, and consistency of characters.
All of these are correct, but none of them hit the crux.
The crux is this. For the past twenty years, the business model of the global advertising agency industry has been reliant on "variant fees."
Every variant incurs a charge, every revision consumes labor hours; this is the meat of the entire food chain for creative directors, Art Directors, and Post-Production teams.
Today, Images 2.0 does one thing: with one prompt, it directly gives you 8 variations that maintain character consistency.
From the client's perspective, this is not a technical news story about "AI can make comics." This is—
The old question of "Why did I need to pay agencies for variant fees" has been answered by Altman with one prompt.
WPP’s financial reports this year keep shouting about "AI-native agency" transformation, Publicis acquired Sapient Razorfish to create automated workflows, and Omnicom and IPG merged while calling for "scaled creativity." These narratives need to be rewritten starting today— clients have gained a knife, and agencies can no longer use "labor-intensive" as an excuse to charge for variant fees.
This will likely be heard in this quarter’s financial report, where there will probably be cries of anguish.
Drawing in Codex without API Key: The most overlooked blow, hitting the engineer's tools
This is the most undervalued line in all reports. The article from Decoder only briefly mentioned:
"In Codex, image generation will be available directly in the workspace without a separate API key."
Hardly anyone discussed it on Twitter.
But the significance of this statement is greater than the two previous points combined.
You are an engineer, in the past—
Drawing a UI mockup requires switching to Figma
Drawing a diagram requires switching to Excalidraw
Drawing a Mermaid flowchart needs embedding in Markdown
Making a banner for README requires opening Canva
Every time you say "I want to draw an image," it's an out-of-workflow task, needing to open another tab, another account, another mindset.
Starting today, your coding agent—Codex, Cursor, Windsurf, Continue, Cline, any tool connected to the OpenAI API—can create production-level visual assets right in the same context window, without switching tools, without needing another Key, without copy-pasting, without formatting alignment.
What it just killed is not a tool, but the very reason for the existence of "engineer-end visual tools."
Mermaid, supported by developer sentiment with its Markdown charts, Excalidraw, supported by minimalism aesthetic sketches, Draw.io's enterprise market, and Figma Dev Mode's penetration towards engineers—all need to ask themselves: why do I still exist.
This is a typical Altman act of "casually taking away an entire category." He didn’t emphasize it in the keynote.
Chinese, Japanese, Korean, Hindi, and Bengali have all been fixed: Chinese design SaaS faces a collective sleepless night
OpenAI’s official text listed five languages under this tweet—Japanese, Korean, Chinese, Hindi, Bengali.
Domestic media mostly translated it as "Chinese text rendering has improved." Watching from Palo Alto, the accurate reading is:
Starting today, OpenAI is the strongest design tool in the Chinese world—not one of them.
For the past two years, overseas models—Midjourney, DALL-E, Stable Diffusion—have always had Chinese text appear as gibberish. This is a fact; there’s no debate. This very issue has been the moat for the Chinese design SaaS industry for the past two years:
Fotor Design: claims to have 400 million users, focusing on one-click generation of Chinese posters
Canva: a Bytedance entity, specializing in Chinese social media graphics
ImgMonster: Incubated by Zcool, e-commerce visual templates
Meitu Design Room: A B2B product from MeituXiuXiu's parent company
MasterGo: a design tool from Blue Lake, competing with Figma
Combined, these five companies have an annual revenue close to 8 billion RMB. Their core value proposition can be summarized in one sentence— "AI can accurately render Chinese text and format Chinese layouts."
Today, this moat has been bridged by an American company with one API.
And not through brute force— the official blog emphasizes "rendered correctly but with language that flows coherently," meaning it’s not just about placing words correctly; it’s about allowing the words and layout to merge naturally at the linguistic level. This is the effect achieved by combining the thinking mode with CJK training data.
Several Chinese founder friends of ours in the Bay Area are probably having emergency meetings tonight. They either need to integrate OpenAI API for distribution channels or find a vertical scene to hide in; there is no middle path. E-commerce visuals, social graphics, brand promotional images— these three major categories are all bleeding collectively today.
QR code demo: The most underrated bomb of the entire launch
There was a demo in the livestream that nearly all media glossed over; only one person on Substack named Leonardo Gonzalez unraveled it in his article "ChatGPT Images 2.0 Explained."
The demo was as follows: OpenAI tasked Images 2.0 with one thing— gathering user feedback on the internal code name "duct tape" from LMArena and compiling it into a formatted poster, then embedding a scannable, real QR code that links back to ChatGPT within the poster.
Hold on, let’s think about this.
This is not image generation. This is three things packed into one product:
Information gathering (web search for social feedback)
Layout construction (arranging the gathered information into a poster)
Machine-readable encoding (embedding a scannable QR code, jumping to a real URL)
In Alan Walker's words, "an image" is no longer just a visual endpoint but an information container.
This is a paradigm shift.
What does it mean? It means starting today:
Posters are no longer just posters; they can be dashboards with real-time data
Infographics are no longer just design products; they can be interactive assets with entry points
Packaging designs are no longer just packaging; they can be identity markers with traceability links, brand stories, and social touchpoints
Business cards are no longer just business cards; they can be living documents with resumes, works, and contact details
By the way, OpenAI's internal code name for the Instant mode—"duct tape" (strong adhesive). This code name itself is a leak of product philosophy. They define what they have created as "the layer of glue that sticks together all visual demands in the AI ecosystem." This is the infrastructure's self-awareness, not the tool's self-awareness.
Infographic SaaS, data visualization tools, QR code generators, business card design apps— these were previously independent categories, but starting today, they are all merely substitutes for the subset of Images 2.0. Visme, Piktochart, Infogram, Lucidpress— all are likely to hold emergency board meetings tonight.

How to view stock: Adobe suffers another blow, Canva's IPO story must be rewritten tonight
Let’s break it down by magnitude.
Adobe (ADBE): Since early 2026, its stock price has already fallen by 22%; this year Morgan Stanley downgraded it from Overweight to Equal-Weight. Firefly's corporate narrative has only one card left— "the professional workflow for the last mile of Creative Cloud." This card was directly stabbed by Images 2.0's "strategic design system" positioning. Within three months, analysts will likely downgrade target prices again.
Figma (FIG): The IPO highlight opening in July 2025 saw a 66% drop in six months. Today, the natively drawing feature in Codex fills the vulnerability of its "design tool + dev handoff" business line. The Dev Mode was originally a grip for its penetration towards engineers, but today engineers no longer need that grip.
Shutterstock (SSTK) and Getty (GETY): The stock photography business was already half dead, surviving on the narrative of "AI training data licensing." Just three weeks ago, Shutterstock launched its official app on ChatGPT— but that was for distribution, not production. OpenAI has now provided an in-house production solution, making Shutterstock's position on the bargaining table drop a notch. Getty's collective lawsuit is still ongoing, and the strategic value of the lawsuit itself has depreciated today.
Microsoft (MSFT) and Nvidia (NVDA): Winners, no need to elaborate. MSFT holds shares in OpenAI, NVDA sells inference chips. But these two have already been priced in too many times, there's nothing fresh.
Canva: This company has not gone public yet, but it is reportedly preparing for an IPO in Q3 or Q4 of 2026. Its narrative has always been "AI-powered design platform for the rest of us." This narrative needs to be rewritten today— because "the rest of us" can now draw directly in ChatGPT, without needing Canva to serve as a middle layer. Tonight, Canva's IPO team will likely be reexamining their pitch deck.
Wix (WIX) and Squarespace (SQSP): Overlooked victims by most people. The website business relied on "design barriers" in the past— templates looking good, formatting being reasonable, fonts being aligned. Today these three barriers have been flattened by Images 2.0; the next step in website building is "one prompt one website," and Wix and Squarespace's Elementor editors will become historical terms.
Pinterest (PINS): The most concealed loser. The market structure for visual inspiration distribution is changing—people used to go to Pinterest for inspiration, but now they will directly ask ChatGPT to generate it. The long tail DAUs will gradually be siphoned away.
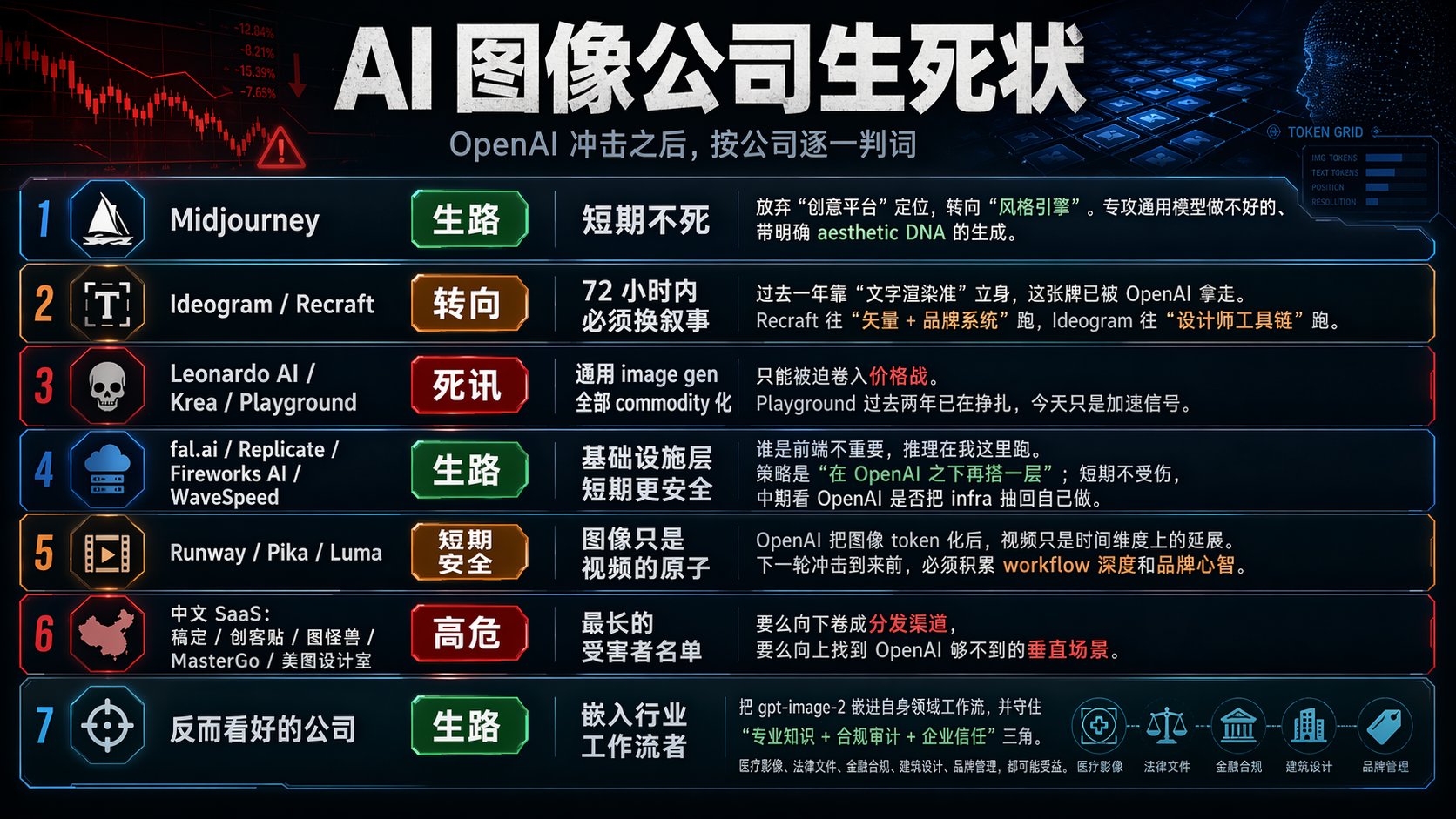
The life and death of startups: Midjourney goes for a style engine, Ideogram and Recraft have only 72 hours
Let’s discuss one company at a time, giving each a lifeline or death announcement.
Midjourney: Facing a direct head-on collision, but the moat for artist users is still there. Short-term survival is not an issue. My suggestion is to immediately abandon the self-positioning of "we are a creative platform," and pivot to "we are a style engine"—focusing on generating the kind of outputs with clear aesthetic DNA that Images 2.0 struggles with. OpenAI excels at general-purpose, multi-use, workflow-friendly assets; Midjourney needs to do what it can't—"the flavor only Midjourney can produce."
Ideogram and Recraft: The core selling point in the past year has been "accurate text rendering." OpenAI has now taken this card off the table. They must find a new narrative within 72 hours; otherwise, the next round of financing will stall. Possible directions: Recraft moving towards vector and brand systems, Ideogram moving towards designer tool chains. Both companies must pivot.
Leonardo AI, Krea, Playground: General image generation brands have all turned into commodities. They can only compete in price wars. Playground has already been struggling in the past two years, and today is a signal for acceleration.
fal.ai, Replicate, Fireworks AI, WaveSpeed: Infrastructure layers are, in fact, more at ease. Who is in the front end is not important; all inference runs here. fal.ai has already launched the enterprise API for gpt-image-2, with pricing from $0.01 to $0.41— this is the standard strategy of "building another layer beneath OpenAI." This layer is not hurt in the short term; in the medium term, we’ll see if OpenAI indeed pulls infrastructure back to operate itself.
Runway, Pika, Luma: Short-term safety, but they need to be clear about one thing— images are the atoms of video. Once OpenAI tokenizes images, video is merely an extension in the temporal dimension. Sora 2 or 3's next launch will likely repeat today's scene. Before then, these three must accumulate workflow depth and brand perception.
Chinese SaaS—Fotor, Canva, ImgMonster, MasterGo, Meitu Design Room: The longest list of victims. As discussed in the fifth section above, there’s no need to repeat. They must either move down to become distribution channels or find a vertical scene that OpenAI cannot reach.
Finally, I actually see potential in one company: any company that integrates the gpt-image-2 API into its domain workflow and can maintain the triangle of "specialized knowledge + compliance auditing + enterprise trust"—medical imaging, legal documents, financial compliance, architectural design, brand management.
These fields have aspects where OpenAI cannot leap over: domain-specific knowledge, data compliance, customer trust. With the bottom layer being filled by OpenAI, the value of the upper layer becomes clearer— you no longer need to train your own models; you just need to focus on how to make good use of this token in your industry.
The tea is now the third cup, and the light on California Avenue outside is moving west. A summary of today's OpenAI launch event can be captured in one sentence:
Today, what OpenAI launched is not an image model, but a new visual token exchange.
The gpt-image-2 API’s generate call consists of only two lines:
Or a simpler cURL:
Two lines of code, $30 per million tokens, eight images generated at once, accurate rendering of Chinese text, natively callable in Codex.
It may seem plain, but it is actually a channel that bypasses all intermediate layers of the visual creation industry chain built over the past twenty years.
The rest will depend on who shows up with which card in the next quarter.
Alan Walker, Zombie Café · April 21, 2026
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






