Original title: You've been training Google's AI for 15 years. You had no idea.
Original author: Sharbel, Co-founder of Unfungible
Original translation: Lila, BlockBeats
Editor's note: CAPTCHA is the number or pattern you need to click every time you log into a website, something every internet user is very familiar with. But when you click "I am not a robot" time after time, you think you're just verifying your identity, but in reality, you're participating in the largest and most secretive data production operation globally. The reCAPTCHA launched by Luis von Ahn aggregates scattered human behaviors into the foundational data that supports Google and its subsidiary autonomous driving company Waymo's core business.
Under the guise of "free" and "secure," the internet has quietly reshaped a new kind of labor relationship: you spend time proving you're human, but contribute to AI training, and once AI learns, that labor is completely replaced. This article was published less than 20 hours ago and has already garnered over 9.5 million views on Twitter. The following is the original content:
About 500,000 hours of human labor are used for free by Google every day. And those contributing it are just trying to log into online banking.
reCAPTCHA is the most successful invisible data operation in internet history. At its peak, 200 million people completed verifications every day. But almost no one realizes what lies behind each click.
Google's autonomous vehicle company Waymo is now valued at $45 billion, and most of its core training data is provided for free by you while visiting various websites.
Here is the complete story:
The Origin: A Clever Idea
In 2000, spam bots were destroying the internet. Forums were flooded, inboxes overflowed, and websites urgently needed a way to distinguish humans from machines.
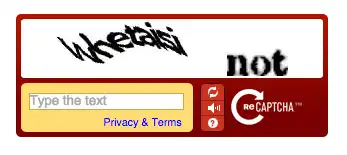
Professor Luis von Ahn of Carnegie Mellon University solved this problem. He invented CAPTCHA: a distorted text that only humans can read, which bots cannot pass.
But von Ahn saw more than just this. Millions of people were expending energy on these challenges. What if this energy could serve two purposes?
In 2007, he launched reCAPTCHA. Its ingenuity lies in the fact that it no longer displays random gibberish, but rather two words. One is known to the system, while the other is a real scanned book that computers cannot yet recognize. Your responses help digitize these books.
These books come from The New York Times Archives and Google Books, totaling up to 130 million volumes.
You think you are just logging into an ordinary website, but in reality, you are doing OCR (optical character recognition) for the largest digital library in the world.
In 2009, Google acquired reCAPTCHA.
Later, Google Changed the Game
The era of "distorted text" ended around 2012.
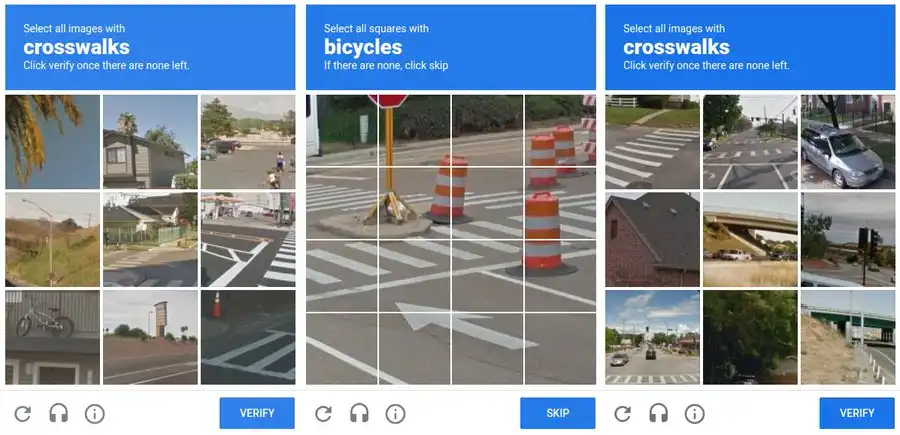
Google encountered a new challenge: the Street View cars captured every road in the world, but the images were merely raw data. For AI to work, it needed to understand what it saw: road signs, crosswalks, traffic lights, storefronts.
So Google redesigned reCAPTCHA v2. There were no distorted texts in the images, but a grid of photos. "Click all the squares with traffic lights." "Select every crosswalk." "Identify storefronts."
These images come directly from Google Street View. Your clicks serve as labels.
Every choice tells Google's computer vision model: this cluster of pixels is a traffic light, that shape is a crosswalk. You are not testing yourself; you are building a dataset.
Unimaginable Scale
At its peak, 200 million reCAPTCHAs were solved every day. Each challenge took 10 seconds, meaning 2 billion seconds of human labor every day, or 500,000 hours.
Paid data labeling costs about $10 to $50 per hour. At a minimum, the labor value extracted for free every day could reach up to $5 million.
Moreover, reCAPTCHA does not only exist in a specific app. It is everywhere: every bank, every government portal, every e-commerce website. You have no choice: want to log into your account? First, come label the dataset. Google has never asked for your opinion, never paid a single cent in wages, and has never even told you about this.
What Has All This Created?
This data has directly fed two products:
-Google Maps: the world's most used navigation tool. Its ability to recognize road signs, stores, and city geography is partly due to billions of human labels made while logging into websites.
-Waymo: Google's autonomous driving project. For safe navigation, self-driving cars need to nearly perfectly recognize thousands of visual patterns.
The true training data for those recognition tasks has been labeled by millions of people unknowingly through reCAPTCHA. Waymo completed over 4 million paid rides in 2024 and is valued at $45 billion. Its foundation was laid by those "unpaid internet citizens" who only wanted to check their emails.
Why Can’t Anyone Replicate This Model?
Data labeling is extremely expensive. Companies like Scale AI, Appen, and Labelbox exist to solve this problem, hiring hundreds of thousands of workers, sometimes at wages under $1 an hour.
Google found a different solution: they made labeling mandatory. No payment is required, no consent is needed, but it serves as a "ticket" to access every corner of the internet. The result is billions of labeled images, global coverage, 24/7 weather, every city in the world. No labeling company can achieve this. The internet itself is the factory, and every internet user is an uncontracted employee.

You Are Still Participating
reCAPTCHA v3, launched in 2018, doesn't even display challenges anymore. It observes how you move your mouse, your scrolling speed, your time spent. Your behavioral fingerprint tells it whether you are human. This behavioral data also feeds back into Google's AI system.
You never actively chose to join; there was never a checkbox for you to select. Yet at this moment, on most websites you visit, you are still doing so.
Unsettling Irony
Luis von Ahn's original intention was genius: to transform the wasted energy of humans into useful output. But what Google has done with this vision is another story. They exploited a security mechanism that users have to use, deploying it across the entire internet, harvesting output to build commercial products worth hundreds of billions of dollars. Users gain nothing and are often unaware.
The most profound irony is: you spent years proving you are human by completing visual recognition tasks that AI could not do at the time. And once AI learned these tasks, human visual labeling was no longer needed.
You proved you are human, but the result is making yourself replaceable.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








