Original author: @BlazingKevin_, Blockbooster researcher
1. The Birth Background and Evolution of Agent Skill
The AI Agent landscape in 2025 is at a crucial watershed moment, transitioning from "technical concept" to "engineering implementation." In this process, Anthropic's exploration of capability encapsulation has unexpectedly catalyzed an industry-wide paradigm shift.
On October 16, 2025, Anthropic officially launched Agent Skill. Initially, the official positioning of this feature was extremely restrained—it was merely seen as an auxiliary module designed to enhance Claude's performance in specific vertical tasks (such as complex code logic, specific data analysis).
However, market and developer feedback exceeded expectations. It quickly became clear that this design of "modularizing capabilities" demonstrated high decoupling and flexibility in actual engineering applications. It not only reduced the redundancy of prompt tuning but also significantly enhanced the stability of Agent execution for specific tasks. This experience rapidly sparked a chain reaction within the developer community. In a short period, leading productivity tools and integrated development environments (IDEs), including VS Code, Codex, and Cursor, followed suit, providing underlying support for the Agent Skill architecture.
In the face of the spontaneous expansion of the ecosystem, Anthropic recognized the underlying universal value of this mechanism. On December 18, 2025, Anthropic made an industry milestone decision: to officially release Agent Skill as an open standard.
Subsequently, on January 29, 2026, the official detailed user manual for Skill was released, completely breaking down the technical barriers for cross-platform and cross-product reuse at the protocol layer. This series of actions marked the complete shedding of the “Claude-exclusive accessory” label for Agent Skill, officially evolving into a universal underlying design pattern within the entire AI Agent field.
At this point, a suspense emerges: what core pain points has the Agent Skill, embraced by major enterprises and core developers, fundamentally addressed in its underlying engineering? What are the essential differences and synergies between it and the currently popular MCP?
To thoroughly clarify these questions and ultimately relate them to the actual construction of crypto industry investment research, this article will progressively explore the following topics:
- Concept Analysis: The essence of Agent Skill and its foundational architecture.
- Basic Workflow: Revealing its underlying operational logic and execution flow.
- Advanced Mechanisms: An in-depth analysis of the two advanced usages of Reference and Script.
- Practical Cases: Analyzing the essential differences between Agent Skill and MCP, and demonstrating their combined application in the crypto investment research scenario.
2. What is Agent Skill and Its Basic Construction
What exactly is Agent Skill? In the simplest terms, it is actually a “dedicated instruction manual” that large models can refer to at any time.
When using AI in daily tasks, we often encounter a pain point: each time a new conversation starts, we have to paste a long list of requirements again. Agent Skill was created to solve this inconvenience.

For a practical example: imagine you want to create an “intelligent customer service” Agent; you can clearly state the rules in the Skill: "When encountering customer complaints, the first step must be to soothe emotions, and absolutely no indiscriminate commitment to compensation." Furthermore, if you frequently need to create “meeting summaries,” you can directly set a template in the Skill: “Every time a meeting summary is produced, it must strictly follow the format of ‘participants’, ‘core topics’, ‘final decisions’.”
With this “instruction manual,” you no longer need to repeat that long list of directives in every conversation. When the large model receives a task, it will automatically refer to the corresponding Skill and immediately know what standards to follow.
Of course, the “instruction manual” is just a simplified analogy for understanding. In reality, the capabilities of Agent Skill go far beyond simple format norms; its “killer” advanced functions will be detailed in later chapters. But at the initial stage, you can think of it as an efficient task description.
Next, let’s use the familiar “meeting summary” scenario to see how to create an Agent Skill. The entire process does not require complex programming knowledge.
According to the current mainstream tools (like Claude Code), we need to find (or create) a folder named .claude/skill in the user directory on the computer, which will serve as the “base camp” for storing all Skills.
First, create a new folder in this directory. The name of this folder will be the name of your Agent Skill. Second, in the newly created folder, create a text file named skill.md.
Every Agent Skill must have a skill.md file. Its purpose is to inform AI: who I am, what I can do, and how you should work according to my requirements. When you open this file, you will find it clearly divided into two parts:

At the very beginning of the file, typically enclosed by two short dashes ---, is a section that lists only two core attributes: name and description.
name: This is the name of the Skill and must match the name of the outer folder exactly.description: This is an extremely important aspect. It is responsible for explaining the specific use of this Skill to the large model. The AI will continuously scan the descriptions of all Skills in the background to determine which Skill should be used to answer the current user's query. Therefore, writing an accurate and comprehensive description is a prerequisite to ensure that your Skill can be accurately activated by the AI.
The remaining portion below the short dashes consists of specific rules intended for the AI. The official term for this part is “instructions.” This is where you exercise your creativity, detailing the logic that the model needs to follow. For example, in the case of a meeting summary, you can specify in plain language: “must extract the list of participants, discuss topics, and the final decisions made.”
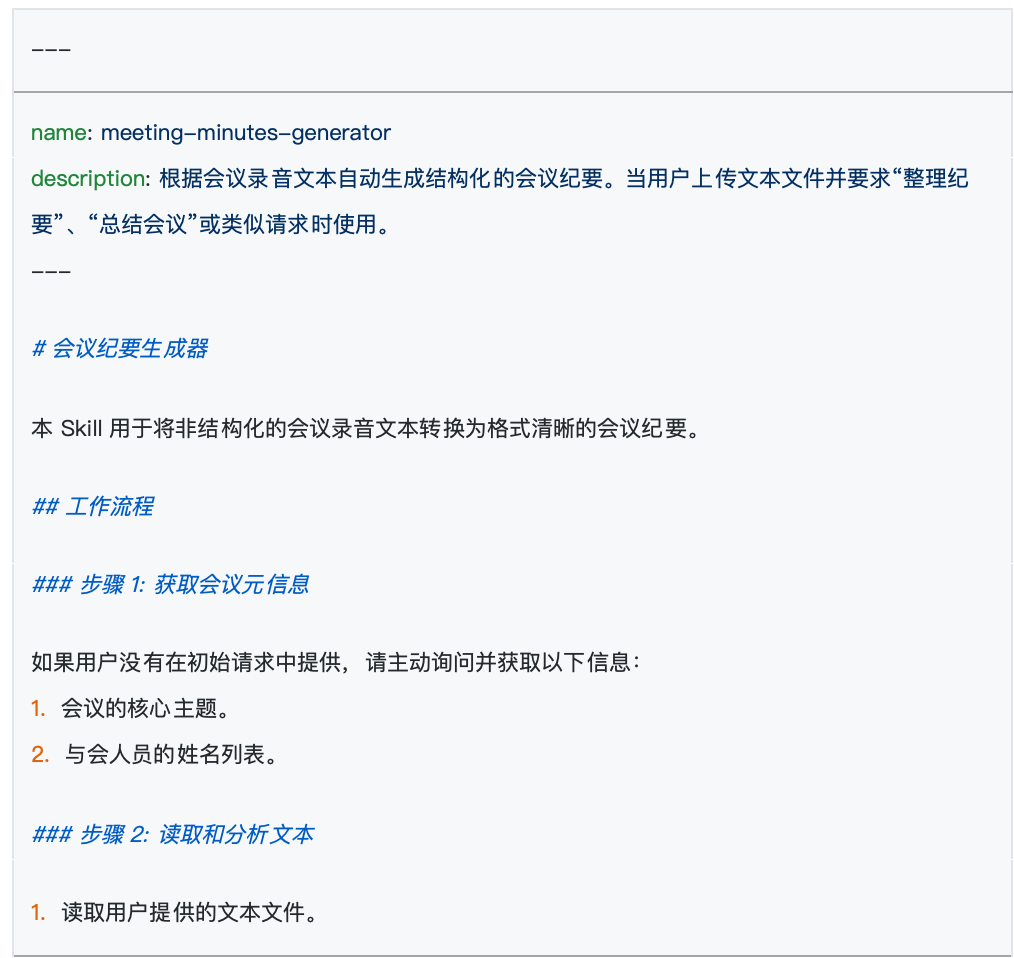

After completing these few steps, a simple yet very practical Agent Skill is born.
However, a truly useful Skill often starts with meticulous pre-design. Defining clear goals, scope, and success criteria before typing the first line on the keyboard will make your construction process far more effective.
The first step in building a Skill is not to think about “what can I make AI do,” but to ask yourself: “What repetitive problems in my daily work do I need to solve?” It is suggested to initially define 2 to 3 specific scenarios that this Skill should cover.

Next is to define success criteria. How do you know if the Skill you wrote is effective? Set a few measurable criteria for it before you start. For example, a quantitative standard could be “Has the processing speed improved?”, while a qualitative standard could be “Are the meeting decisions extracted sufficiently accurate without omissions each time?”
3. The Basic Operating Workflow of Agent Skill
After understanding the basic aspects of Agent Skill, we can't help but ask: how does this “instruction manual” work in actual operation?
If you have recently experienced products like Manus AI, you likely encountered scenarios where, when you posed a specific question, the AI did not immediately launch into a “long-winded explanation” or hallucinate, but rather sensitively realized that “this matter falls under a specific Agent Skill.” It would then pop up a prompt on the interface, asking if you allow the use of that Skill.
When you click “agree,” the AI, as if it has switched to a different persona, will perfectly output the results according to the prescribed rules.
This seemingly simple interaction of “request-approval-execution” actually hides an incredibly intricate underlying operating workflow. To clearly explain this mechanism, we must first clarify the “three core roles” involved in the entire process:
- User: The person initiating the task request.
- Client tool (like Claude Code, etc.): The “intermediary” responsible for scheduling and coordinating.
- Large language model: The “brain” responsible for understanding intent and generating the final result.
When we input a requirement into the system (for example: “Help me summarize this morning's project meeting”), the following four steps of precise collaboration occur among these three roles:
Step One: Lightweight Scan (Passing Metadata)
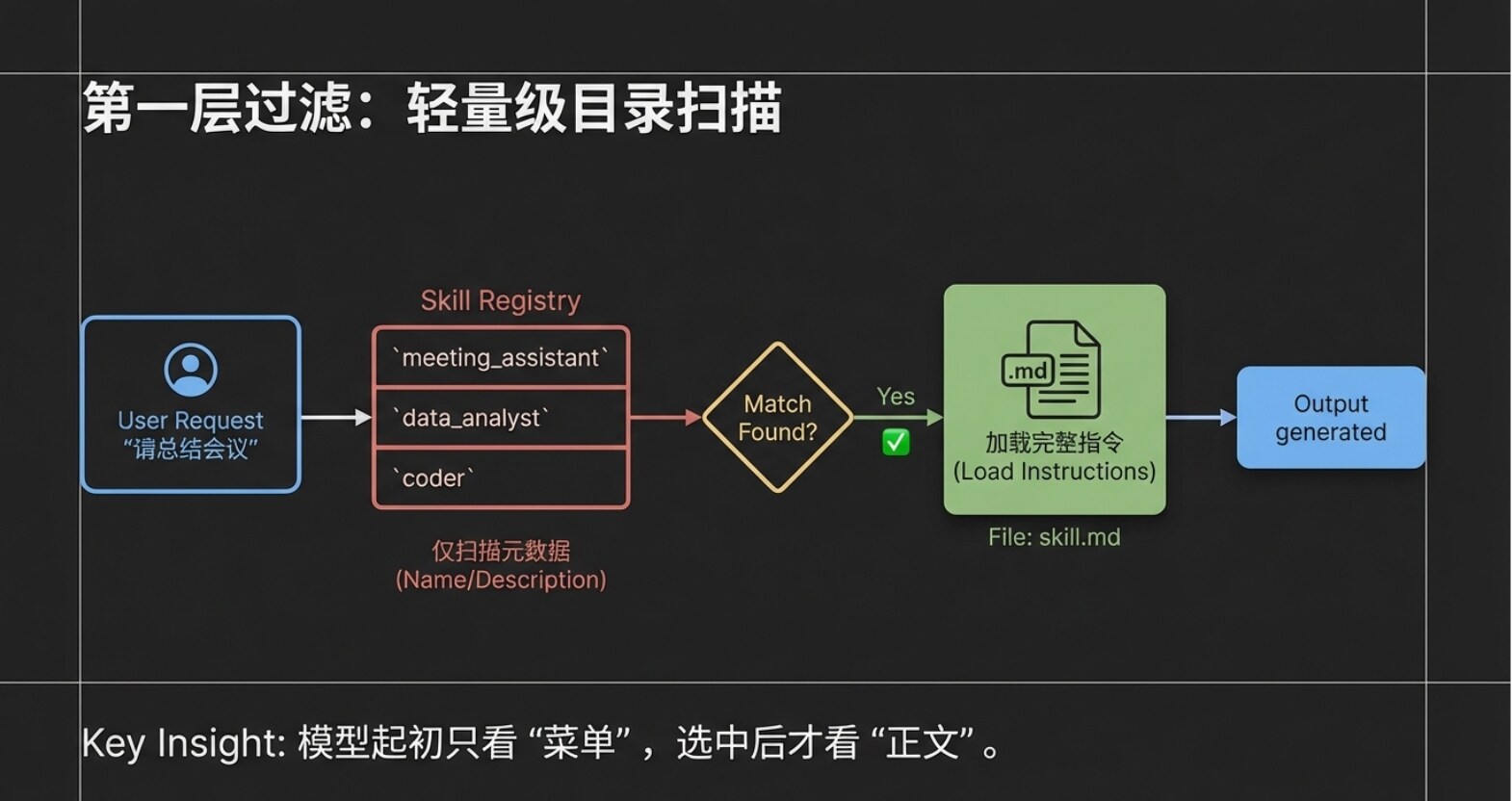
After the user submits a request, the client tool (Claude Code) does not dump all instruction manuals to the large model at once. Instead, it only sends the user's request, along with the “names” and “descriptions” of all Agent Skills currently in the system (what we mentioned in the previous chapter as metadata), packaged to the large model. You can imagine that even if you have installed dozens of Skills, what the large model receives is merely a “lightweight directory.” This design greatly conserves the model's attention and prevents information from interfering with one another.
Step Two: Precise Intent Matching Upon receiving the user request and this “Skill directory,” the large model conducts a rapid semantic analysis. It determines that the user's request is to “summarize a meeting,” and coincidentally, there is a Skill called “Meeting Summary Assistant” in the directory whose description perfectly fits the task. At this point, the large model will inform the client tool: “I found that this task can be solved with the ‘Meeting Summary Assistant.’”
Step Three: Load Full Instructions on Demand After receiving feedback from the large model, the client tool (Claude Code) will then truly enter the exclusive folder for the “Meeting Summary Assistant” to read the complete content of skill.md. Please note, this is a crucial design: only at this time will the full instruction content be read, and the system will only read this selected Skill. Other unselected Skills will remain quietly in the directory without consuming any resources.
Step Four: Rigid Execution and Output Response Finally, the client tool sends the “original user request” along with the “complete content of the Meeting Summary Assistant's skill.md” to the large model. This time, the large model is no longer taking a multiple-choice question; it enters execution mode. It will strictly adhere to the rules set forth in skill.md (e.g., must extract participants, core topics, final decisions), generating highly structured responses, which are then presented to the user by the client tool.
4. Core Mechanism One: On-Demand Loading and Reference
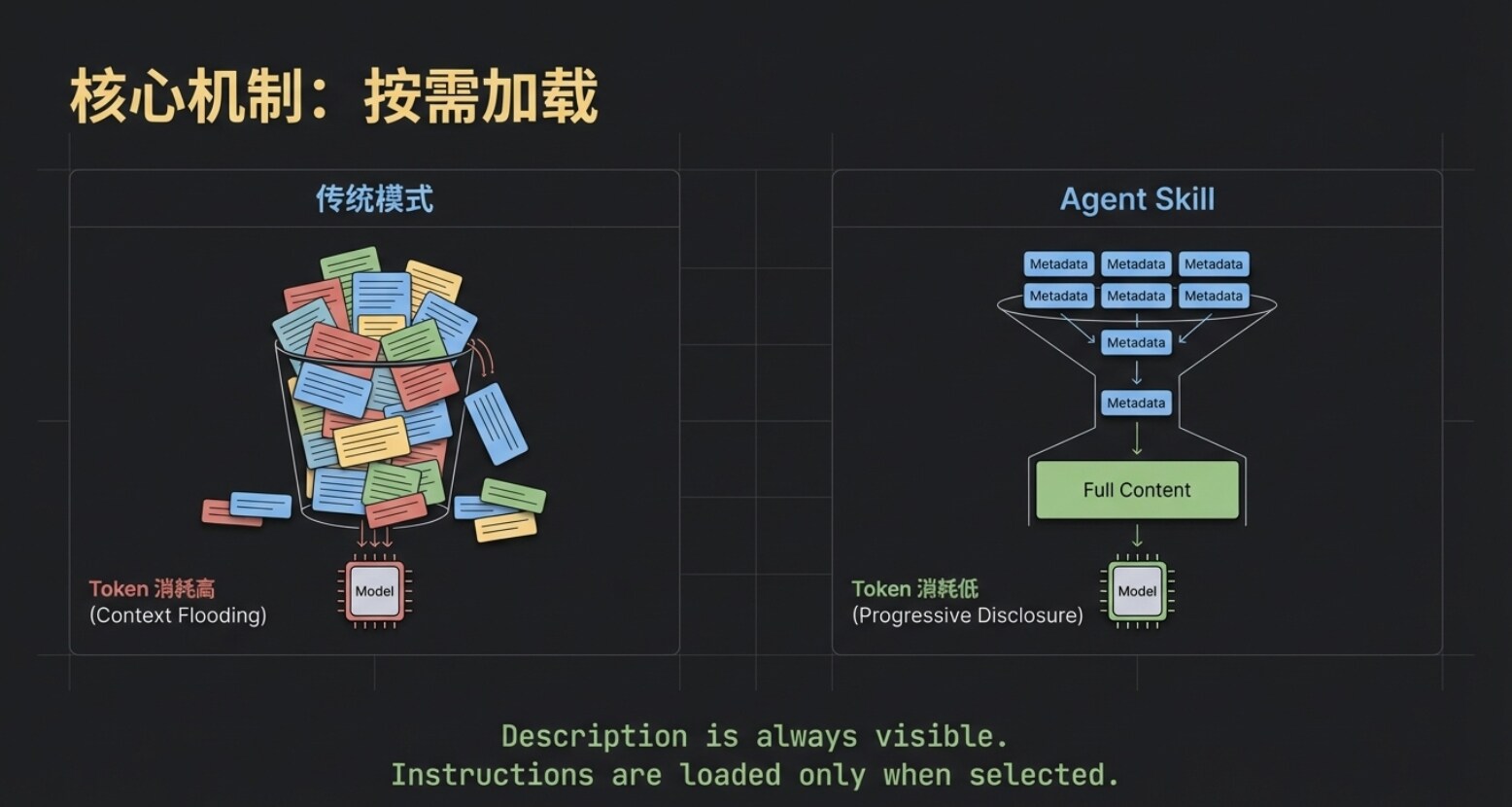
The workflow in the previous chapter introduced the first core underlying mechanism of Agent Skill—On-Demand Loading.
While the names and descriptions of all Skills are always visible to the large model, the specific instructions’ content will only be pulled into the model's context after that Skill has been precisely matched.
This significantly conserves precious Token resources. Imagine that even if you deploy several large Skills such as “Trending Copy,” “Meeting Summary,” and “On-Chain Data Analysis,” the model initially only needs to perform a very low-cost “directory search.” Only after the target is selected will the system feed the corresponding skill.md to the model. This “on-demand loading” is the first layer of code that keeps Agent Skill lightweight and efficient.
However, for advanced users pursuing ultimate efficiency, achieving just the first layer of on-demand loading is not enough.
As business deepens, we often want Skills to become smarter. Taking the “Meeting Summary Assistant” as an example, we hope it can not only simply restate topics but also provide incremental insightful values: when a meeting decision involves spending money, it can directly indicate whether it complies with group financial regulations in the summary; when external collaboration is involved, it can automatically suggest potential legal risks. Thus, when the team looks at the summary, they can immediately notice critical compliance warnings without having to consult regulations again.
However, this brings about a fatal contradiction in terms of engineering: for Skills to possess such capabilities, it is necessary to cram lengthy “Financial Regulations” and “Legal Provisions” into the skill.md file. This would make the core instruction file incredibly bloated. Even if today’s meeting is merely a technical morning briefing, the model would be forced to load tens of thousands of words of financial and legal “nonsense,” resulting in serious waste of Tokens and easily causing the model's “attention dilution.”
So, can we achieve an additional layer of “on-demand within on-demand” based on this? For instance, only when the meeting content genuinely addresses “money,” would the system pull out the financial regulations for the model to see?
The answer is affirmative. The Reference mechanism in the Agent Skill system was born precisely for this purpose.

The essence of the Reference is a condition-triggered external knowledge base. Let’s see how it elegantly resolves the above pain points:
- Establish External Reference Files: First, we create an independent file within the Skill's directory, commonly referred to as Reference. We will name it
Group Financial Manual.md, detailing various reimbursement standards (e.g., accommodation subsidy 500 yuan/night, catering fee of 300 yuan per day, etc.). - Set Trigger Conditions: Next, we return to the core
skill.mdfile and add a specific “financial reminder rule.” We can explicitly state in natural language: “Only trigger when the meeting content mentions terms such as money, budget, procurement, expenses. Upon triggering, readGroup Financial Manual.md. Please check this file's content and indicate whether the amounts in the meeting decisions exceed the limits and specify the corresponding approvers.”
Once the setup is complete, a brilliant dynamic collaboration starts when we review budget allocations in our next meeting:
- The client tool scans and requests to use the “Meeting Summary Assistant” Skill (completing the first layer of on-demand loading).
- The model, reading the meeting records, sensitively captures terms related to “budget,” immediately triggering the rules embedded in
skill.md. - At this point, the system will issue a second request: “Is it allowed to read
Group Financial Manual.md?” (Completing the second layer of on-demand loading: dynamic triggering of Reference). - Once authorized, the model cross-references the meeting content with the dynamically introduced financial standards, ultimately outputting a high-quality summary that not only includes “participants, topics, decisions” but also attaches a “financial compliance warning.”
Please remember the core characteristics of Reference: It is strictly condition-bound. Conversely, if today's meeting is a technical review about code logic with no relation to money, the Group Financial Manual.md will quietly remain on the hard drive, occupying none of the Token computational resources.
5. Script and the Progressive Disclosure Mechanism
After discussing the Reference mechanism that resolves information overload, we now enter another killer capability of Agent Skill: Code Execution (Script).
For a mature Agent, simply being able to “look up information” and “write summaries” is insufficient; the ability to directly perform tasks signifies a truly automated closed loop. This is where Script comes into play.
Next, we return to the core skill.md file and append a clear instruction: “When the user mentions words like ‘upload,’ ‘synchronize,’ or ‘send to the server,’ you must run the upload.py script to push the generated summary content to the server.”
When you say to AI: “The summary is well done, please synchronize it to the server.”
The client tool will immediately request to execute this upload.py file. But pay attention to an extremely critical underlying logic: In this process, the AI does not “read” the content of this code; it merely “executes” it.
This means that, even if your Python script contains a thousand lines of complex business logic, its consumption of the large model's context is almost zero. The AI operates as if using a “black box” tool; it only cares about how to start the tool and whether it successfully completed the task, regardless of how the mechanism works inside the box.
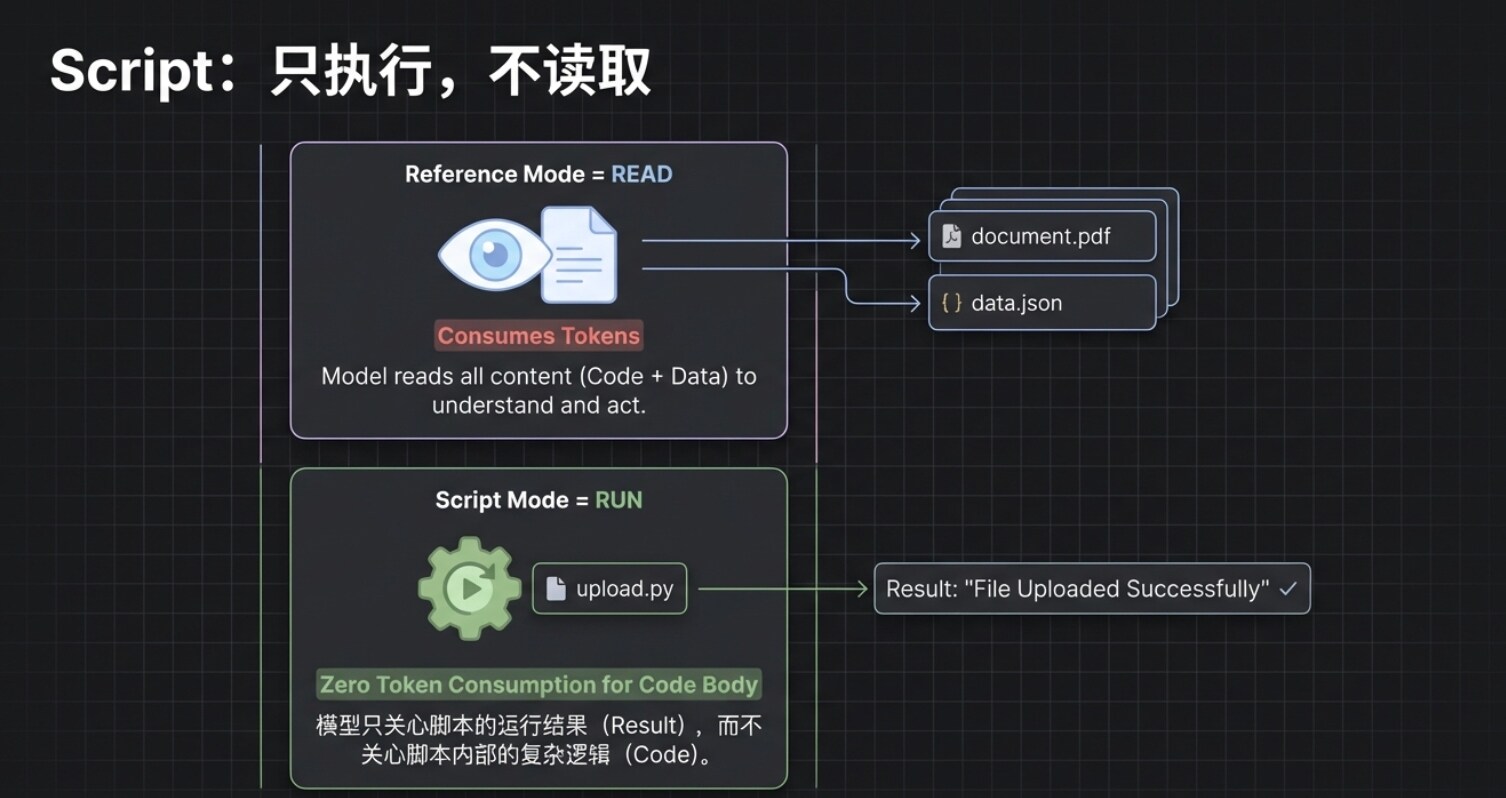
This leads to the essential difference in mechanisms between Reference and Script:
- Reference (Read): Its function is to “move” the content of external files into the model's brain (context) as reference, thus will consume Tokens.
- Script (Run): It is triggered and runs directly in the external environment; as long as you clearly define the method of execution, it won't occupy the model's context.
Of course, there is a pitfall avoidance guide: when writing skill.md, you must explain the triggering conditions and execution commands of the script absolutely clearly. If the AI encounters vague instructions and doesn’t know how to execute, it may “fall back” to trying to peek at the code for clues, and this is when your Tokens may suffer. Therefore, the iron rule for writing Skills is: define the rules as clearly and comprehensively as possible.
At this point, we have essentially gathered all the core components of Agent Skill. It’s time to pause and summarize from a global perspective.
If you reflect on the entire loading process, you will discover that the design philosophy of Agent Skill is actually an incredibly sophisticated progressive disclosure mechanism. To maximize computational efficiency and maintain high performance, its system is strictly divided into three layers, with each layer's triggering conditions progressively tightening:
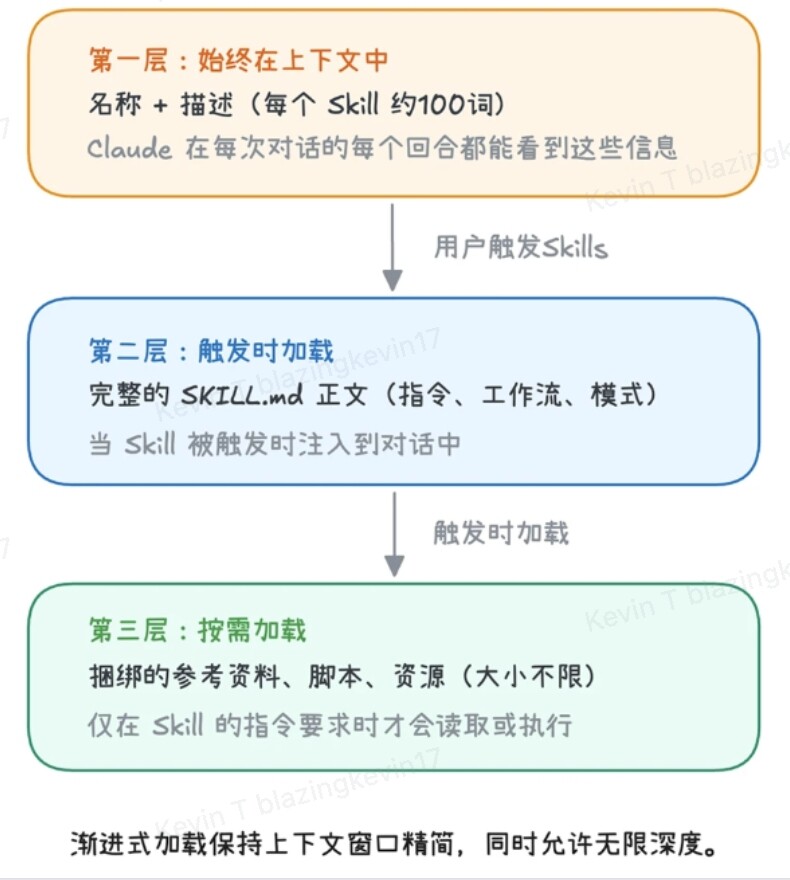
- First Layer: Metadata Layer (Always Loaded) This contains the
nameanddescriptionof all Agent Skills. It's like the model's “permanent directory,” extremely lightweight. Before every task assignment, the large model will first glance here to complete preliminary routing matching. - Second Layer: Instruction Layer (On-Demand Loading) Corresponds to the specific rules in
skill.md. Only after the first layer confirms the task ownership will the AI “open” this corresponding layer to load the specific rules into its understanding. - Third Layer: Resource Layer (On-Demand Within On-Demand Loading) This is the deepest and most substantial layer. It contains three core components:
- Reference: For example,
Group Financial Manual.md, will only be read when certain conditions are triggered (e.g., mentioning "money"). - Script: For example,
upload.py, will only be executed when a specific action is required (e.g., “upload”). - Asset: For example, company logos, exclusive fonts, specific PDF templates needed when generating reports, etc. These are also only called upon at the moment of producing the final output.
6. The Essential Differences Between Agent Skill and MCP and Combination Practice
After discussing the advanced usages of Agent Skill, many readers familiar with the underlying protocols of AI may feel a strong sense of déjà vu: the Script mechanism of Agent Skill seems very similar to the currently popular MCP. Essentially, aren’t they both about connecting and operating external worlds with the large model?
Given the overlap in functionality, when constructing a Crypto Research workflow, which one should we choose?
In response to this question, Anthropic officials once highlighted the most fundamental difference between the two with a classic statement:
"MCP connects Claude to data. Skills teach Claude what to do with that data."(MCP is responsible for connecting Claude to the data; Skills are responsible for teaching Claude how to handle this data.)
This statement could not be more accurate. MCP is essentially a “data pipeline” that standardizes the supply of external information to the large model (such as querying the latest block height on a blockchain, pulling real-time candles from an exchange, accessing local investment research PDFs). On the other hand, Agent Skill is fundamentally a set of “standard operating procedures (SOP)” that govern what the large model should do once it receives that data (for example, specifying that investment research reports must include a token economics model, or that conclusions output must carry risk warnings).
At this point, some tech-savvy individuals might raise an objection: “Since Agent Skill can also run Python code, couldn’t I just write a piece of logic in Script that connects to a database or calls an API? Agent Skill could completely take care of what MCP does!”
Indeed, from an engineering implementation perspective, Agent Skill can also pull data. However, it is extremely awkward and unprofessional.
This “unprofessionalism” manifests in two critical dimensions:
- Running Mechanism and State Retention: The scripts in Agent Skill are “stateless”; each trigger represents an independent execution that self-terminates once finished. In contrast, MCP is an independently operated long-term service; it can maintain a persistent connection with external data sources (such as the WebSocket long connection mentioned later), which a mere script cannot achieve.
- Security and Stability: Having the AI run a bare-bones Python script with the highest system permissions every time poses significant security risks; whereas MCP provides a standardized isolation environment and authentication mechanisms.
Thus, when creating a sophisticated Crypto Research system, the most powerful solution is not to choose between the two, but rather to adopt a “MCP supplies water, Skill brews wine” approach—leveraging the strengths of both.
To give everyone an intuitive feel for the power of this combination, let's take the opennews-mcp constructed by Web3 developer Cryptoxiao as an example, breaking down how to leverage API-enhanced Skill to create a fully automated crypto news intelligence center.
The core logic of this type of Skill is to encapsulate the discrete API capabilities provided by MCP through Skill's instruction orchestration into an intelligent Agent tailored to final investment research objectives.
This system endows AI with four core module capabilities:
Module One: News Source Discovery
This is the entry point for AI to understand the boundary of the tool's capabilities. Through the tool in discovery.py, the AI can dynamically learn which channels it can obtain information from.

Module Two: Multi-Dimensional News Retrieval
This is the core querying module, implemented by news.py, providing multiple retrieval methods ranging from simple to complex.
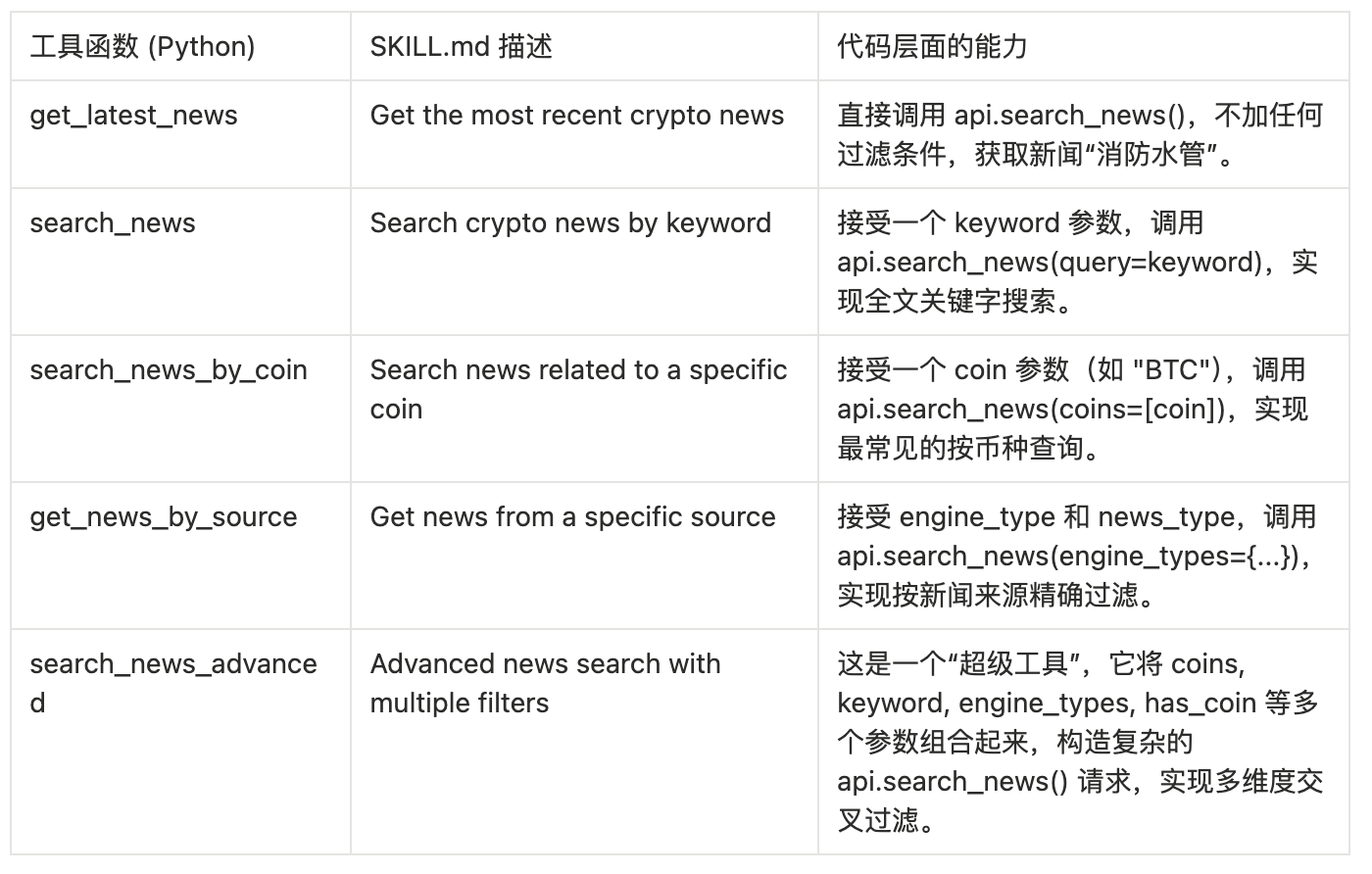
Module Three: AI-Powered Analysis and Insights
This part of the tool utilizes the AI analysis results already completed in the backend of 6551.io, allowing the AI Agent to query “opinions” instead of merely “facts.”

Key Insight: When the AI Agent invokes these tools, it is unaware that the MCP server internally carried out a two-step operation of “fetching-then-filtering”. To the AI, it simply calls a magical tool that can directly return “high-scoring news” or “positive news,” significantly simplifying the AI's workflow.
Module Four: Real-Time News Stream
This is the “killer app” capability of opennews-mcp, implemented by realtime.py, empowering the AI to monitor real-time events.

Once these MCP-driven tools are incorporated into the instruction stream of Agent Skill, your AI officially transforms from a “generic chat assistant” to a “Wall Street-level Web3 analyst.” It can fully automate complex workflows that previously took researchers hours to complete:
Workflow Example One: Quick Due Diligence (DD) on New Cryptocurrencies
- Instruction Issued: The user inputs, “Conduct deep research on the newly launched @NewCryptoCoin project.”
- Basic Baseline Analysis: The Agent automatically calls
opentwitter.get_twitter_userto obtain official Twitter data. - Endorsement and Cross-Validation: Calls
opentwitter.get_twitter_kol_followers, analyzing which top KOLs or VCs have quietly started following the project. - Full Internet Sentiment Search: Calls
opennews.search_news_by_cointo retrieve media reports and public relations actions. - Signal-to-Noise Ratio Filtering: Calls
opennews.get_high_score_newsto eliminate worthless brief news, focusing solely on high-score long articles. - Output Research Report: The Agent produces a standard due diligence report based on the format predetermined in the Skill, including “fundamentals, community chip structure, media popularity, and AI comprehensive rating.”
Workflow Example Two: Real-Time Event-Driven Trading Signal Discovery
- Instruction Issued: The user inputs, “Keep an eye on the market around the clock for sudden trading opportunities in the ‘Zero Knowledge Proof (ZK)’ sector.”
- Deployment of Sentinel: The Agent calls
opennews.subscribe_latest_newsto establish a WebSocket long connection, precisely monitoring news streams containing “ZK” or “Zero-Knowledge Proof” associated with specific tokens. - Catching Positive News: When the system captures high-priority positive news indicating breakthroughs in ZK technology for a particular project (like SomeCoin), with sentiment indicators pointing to Long, it immediately breaks sleep mode.
- Community Sentiment Resonance Test: The Agent instantaneously calls the Twitter search tool to check if multiple core KOLs in the ZK field are synchronously discussing the event.
- Alert Triggered: If the conditions of “media first” and “community resonance” are met, the Agent immediately sends the user a highly certain Alpha trading alert.
Thus, by meticulously specifying behavioral logic through Agent Skill and integrating data arteries via MCP, a highly automated and professional Crypto Research workflow is fully closed.
About BlockBooster
BlockBooster is a next-generation alternative asset management company targeting the digital age. We use blockchain technology to invest, incubate, and manage core assets of the digital era—from Web3 native projects to real-world assets (RWA). As value co-creators, we are dedicated to uncovering and unleashing the long-term potential of assets, capturing exceptional value for our partners and investors in the tide of the digital economy.
Disclaimer
This article/blog is for reference only, representing the personal views of the author and does not reflect the position of BlockBooster. This article does not intend to provide: (i) investment advice or recommendations; (ii) offers or solicitations to purchase, sell, or hold digital assets; or (iii) financial, accounting, legal, or tax advice. Holding digital assets, including stablecoins and NFTs, is highly risky, with significant price fluctuations and the potential to become worthless. You should carefully consider whether trading or holding digital assets is suitable for you based on your financial situation. For specific cases, please consult your legal, tax, or investment advisor. The information provided in this article (including market data and statistics, if any) is for general reference. Due diligence has been exercised in compiling this data and charts, but we are not responsible for any factual errors or omissions expressed therein.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





