Written by: Vaidik Mandloi
Translated and Organized by: BitpushNews
The promise that AI agents will change the landscape of the internet is gradually becoming a reality. They have moved beyond experimental tools in chat windows to become an indispensable part of our daily operations—ranging from cleaning inboxes and scheduling meetings to responding to support tickets, they are quietly enhancing productivity, and this change is often overlooked.
However, this growth is not just rumor.
By 2025, automated traffic will surpass human traffic, accounting for 51% of total online activity. In the US alone, AI-driven traffic to retail websites has increased by 4700% year-on-year. AI agents are now operating across systems, with many agents able to access data, trigger workflows, and even initiate transactions.
However, trust in fully autonomous agents has dropped from 43% to 22% in a year, largely due to the rising number of security incidents. Nearly half of enterprises still use shared API keys to authenticate agents, a method never designed for allowing autonomous systems to transfer value or operate independently.
The issue is that the speed of agents' expansion has outpaced the infrastructure designed to govern them.
In response, a new protocol layer is emerging. Stablecoins, card network integrations, and agent-native standards like x402 are enabling machine-initiated transactions. At the same time, new identity and verification layers are also being developed to help agents identify themselves and operate in structured environments.
But enabling payments does not equate to enabling an economy. Once agents can transfer value, more fundamental questions arise: How do they discover suitable services in a machine-readable manner? How do they prove identity and authorization? How do we verify that the operations they claim to perform actually occurred?
This article will explore the infrastructure necessary for agents to operate an economy at scale and assess whether these layers are mature enough to support enduring, autonomous participants operating at machine speed.
Agents Cannot Purchase What They Cannot See
Before agents can pay for services, they must first find those services. This sounds simple but is currently the most friction-filled area.
The internet is built for human-readable pages. When humans search for content, search engines return ranked links. These pages are optimized for persuasion. They are filled with layouts, trackers, advertisements, navigation bars, and style elements that make sense to humans but are primarily "noise" to machines.
When agents request the same pages, they receive raw HTML. A typical blog post or product page in this form might take about 16,000 tokens. When converted to a clean Markdown file, the token count drops to around 3,000. This means the content the model must process is reduced by 80%. For a single request, this difference might be insignificant. But when agents make thousands of such requests across multiple services, excessive processing compounds into delays, costs, and higher reasoning complexity.
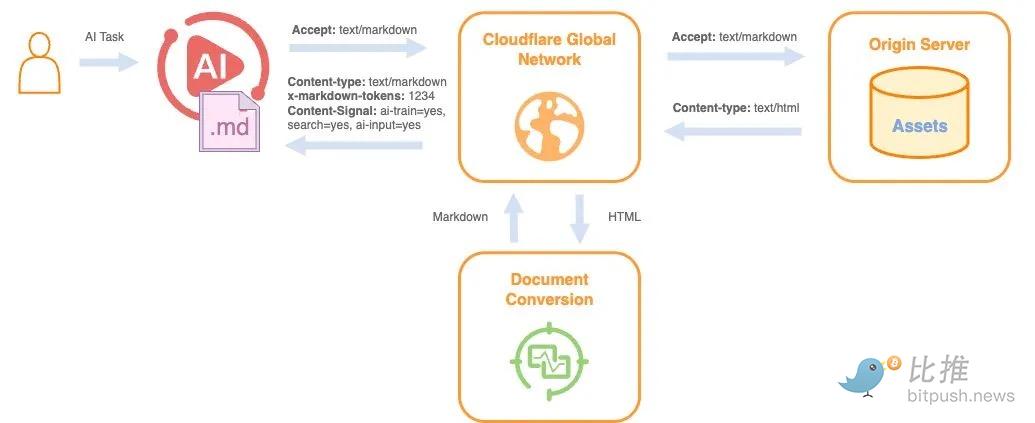
@Cloudflare
Agents ultimately spend a significant amount of computational effort stripping away interface elements before accessing the core information necessary to take action. This effort does not enhance output quality; it merely compensates for a web that was never designed for them.
As the traffic driven by agents increases, this inefficiency becomes more apparent. AI-driven scraping of retail and software websites has surged in the past year and now accounts for the majority of total online activity.
Meanwhile, about 79% of major news and content websites have at least blocked one AI crawler. From their perspective, this reaction is understandable. Agents do not interact with advertisements, subscriptions, or traditional conversion funnels when extracting content. Blocking them is a means to protect revenue.
The issue is that the web has no reliable way to distinguish between malicious scrapers and legitimate procurement agents. Both manifest as automated traffic and originate from cloud infrastructure. To systems, they appear identical.
Deeper still, the problem is that agents are not trying to "consume" pages; they are trying to discover possibilities for action.
When a human searches for "flights under $500," a ranked list of links is sufficient. A person can compare options and make a decision. When agents receive the same instruction, they need something entirely different. They need to know which services accept booking requests, what input format is required, how pricing is calculated, and whether payment can be programmatically settled. Very few services clearly disclose this information.
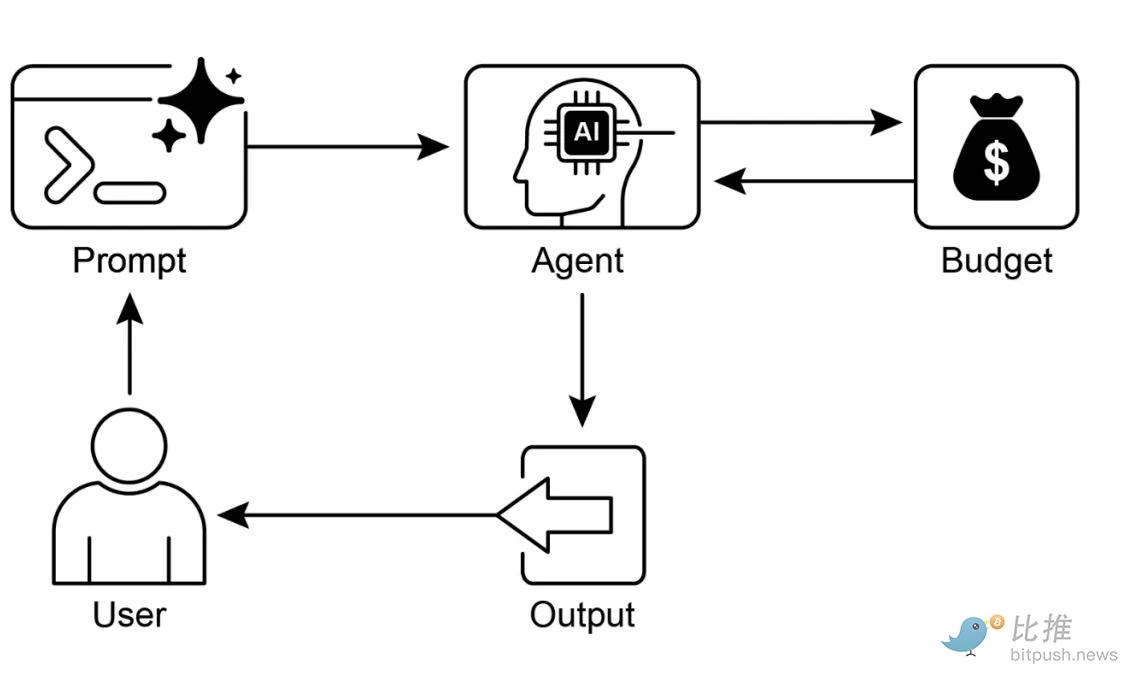
@TowardsAI
This is why the conversation is shifting from search engine optimization (SEO) to agent-oriented discoverability (AEO). If the end-user is an agent, then ranking on search pages becomes less important. What matters is whether the service describes its capabilities in a way that is interpretable by agents without requiring guesswork. If not, it risks becoming "invisible" in an expanding share of economic activity.
Agents Need Identity
@Hackernoon
Once agents can discover services and initiate transactions, the next major issue is making sure the systems on the other end know who they are dealing with. In other words: identity.
Today's financial systems operate with far more machine identities than human identities. In finance, the ratio of non-human identities to human identities is about 96 to 1. APIs, service accounts, automation scripts, and internal agents dominate institutional infrastructure. Most of these were never designed to have discretion over capital. They execute predefined instructions and cannot negotiate, select vendors, or initiate payments on open networks.
Autonomous agents change this boundary. If an agent can directly move stablecoins or trigger a checkout process without manual confirmation, the core question shifts from "Can it pay?" to "Who authorized it to pay?"
This is where identity becomes foundational, giving rise to the concept of "Know Your Agent."
Just as financial institutions validate customers before allowing them to trade, services interacting with autonomous agents must verify three things before granting access to capital or sensitive operations:
- Cryptographic Authenticity: Does this agent truly control the keys it claims to use?
- Delegation Authority: Who granted this agent authority, and what are the limitations?
- Real-World Association: Is the agent linked to an entity with legal accountability?
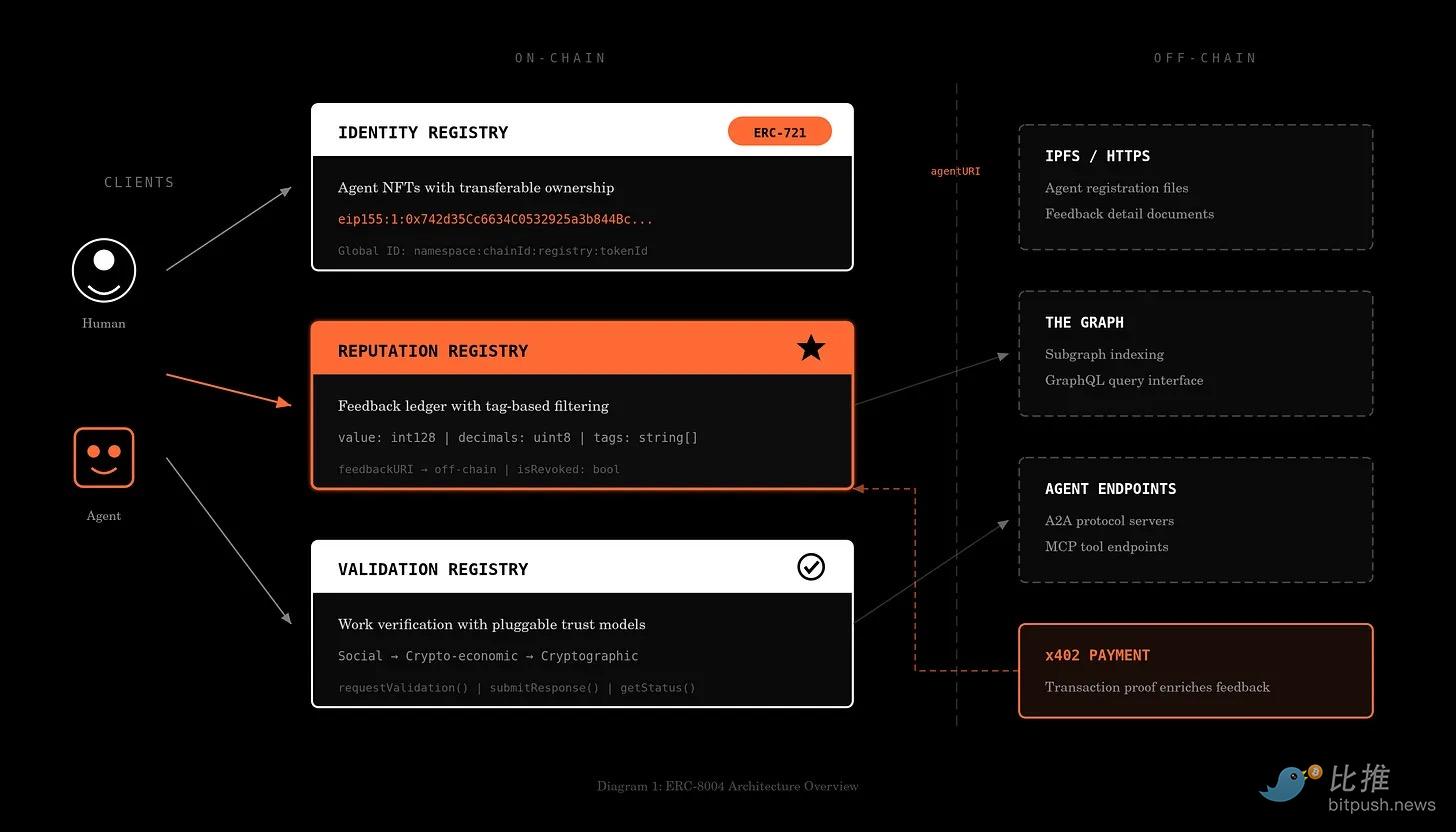
These checks together form an identity stack:
- At the base are cryptographic key generation and signing. Standards like ERC-8004 attempt to formalize how agents anchor identity in a verifiable registry on chain.
- The middle layer is identity provider layer. This connects keys to real-world entities, such as registered companies, financial institutions, or verified individuals. Without this binding, signatures only prove control but not accountability.
- The edge layer is verification infrastructure. Payment processors, CDNs, or application servers verify signatures in real-time, check relevant credentials, and enforce permission boundaries. Visa's Trusted Agent Protocol is an example of permissioned commerce, allowing merchants to verify whether an agent is authorized to transact on behalf of a specific user. Stripe's Agent Commerce Protocol (ACP) is pushing similar checks into programmable checkout and stablecoin flows.
Meanwhile, the Universal Commerce Protocol (UCP) led by Google and Shopify allows merchants to publish "capability lists" that agents can discover and negotiate. It acts as an orchestration layer, expected to be integrated into Google Search and Gemini.
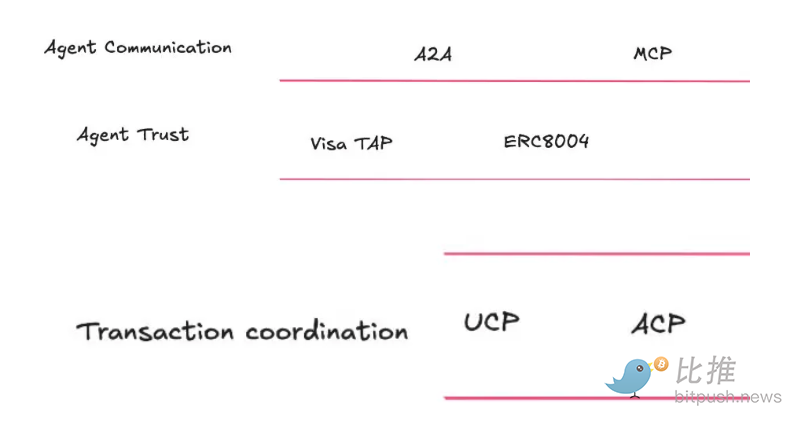
@FintechBrainfood
The important nuance is that permissionless and permissioned systems will coexist.
On public blockchains, agents can transact without centralized gatekeeping. This increases speed and composability but also exacerbates compliance pressure. Stripe's acquisition of Bridge highlights this tension. Stablecoins enable instant cross-border transfers, but compliance obligations do not disappear simply because settlement occurs on-chain.
This tension will inevitably draw regulators in. Once autonomous agents can initiate financial transactions and interact with markets without direct human oversight, accountability issues become inescapable. The financial system cannot allow capital to flow through unidentified or unauthorized actors, even if those actors are software fragments.
Regulatory frameworks are already being adopted. The Colorado AI Bill will take effect on February 1, 2026, introducing accountability requirements for high-risk automated systems, with similar legislation progressing globally. As agents begin executing financial decisions at scale, identity will no longer be optional. If discoverability makes agents visible, then identity is the credential that allows them to be recognized.
Verifying Agent Execution and Reputation
Once agents start executing tasks involving money, contracts, or sensitive information, merely having identity may not be enough. A verified agent may still produce illusions, misrepresent their work, leak information, or perform poorly.
Therefore, the crucial question is: Can it be proven that the agent actually completed the work it claims to have done?
If an agent claims it analyzed 1,000 documents, detected fraud patterns, or executed a trading strategy, there must be a way to verify that this computation indeed took place and that the output was not fabricated or corrupted. For this, we need a performance layer to achieve this.
Currently, there are three methods to accomplish this:
- TEEs (Trusted Execution Environments): The first approach relies on proofs conducted via hardware such as AWS Nitro and Intel SGX. In this model, the agent operates within a secure enclave, which releases cryptographic certificates confirming that specific code executed on specific data and was not tampered with. The overhead is usually small (around 5-10% additional latency), which is acceptable for financial and enterprise use cases where integrity is valued over speed.
- ZKML (Zero-Knowledge Machine Learning): The second method is a mathematical approach. ZKML allows agents to generate cryptographic proofs demonstrating that the output was generated by a specific model without revealing model weights or private inputs. Lagrange Labs' DeepProve-1 recently demonstrated a full zero-knowledge proof of GPT-2 inference, achieving speeds 54-158 times faster than previous methods.
- Restake Security: The third model enforces correctness through economic means rather than computational means. Protocols like EigenLayer introduce stake-based security, where validators stake capital behind the output of agents. If the output is challenged and proven false, the staked assets are slashed. The system does not prove every computation but makes dishonest behavior economically unfeasible.
These mechanisms address the same problem from different angles. However, proving execution is incidental. They verify single tasks, but the market needs something cumulative. This is where reputation becomes critical.
Reputation transforms isolated proofs into a long-term performance history. Emerging systems aim to make agent performance portable and cryptographically anchored rather than relying on platform-specific evaluations or opaque internal dashboards.
Ethereum Proof of Service (EAS) allows users or services to publish signed, on-chain proofs about agent behavior. A successful task completion, an accurate prediction, or a compliant transaction can be recorded in a tamper-proof manner and move with agents across applications.
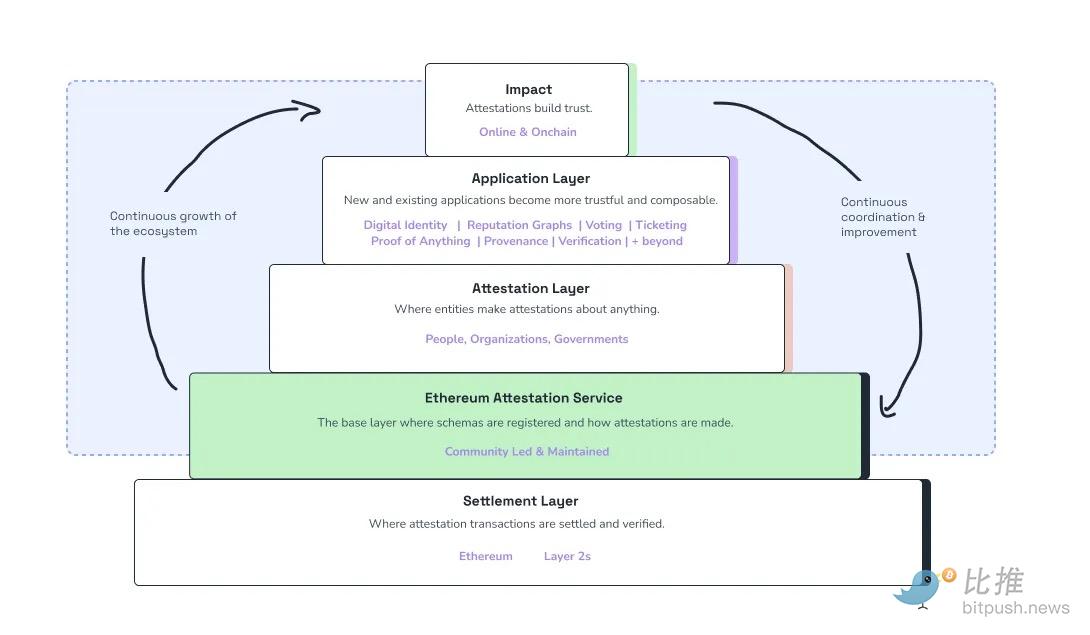
@EAS
Competitive benchmarking environments are also forming. Agent Arenas evaluate agents based on standardized tasks and rank them using scoring systems like Elo. Recall Network reports that over 110,000 participants have generated 5.88 million predictions, creating measurable performance data. As these systems scale, they start to resemble real rating markets for AI agents.
This allows reputation to be carried across platforms.
In traditional finance, agencies like Moody's rate bonds to signal creditworthiness. The agent economy will need an equivalent layer to rate non-human actors. The market needs to assess whether an agent is reliable enough to entrust capital, whether its output has statistical consistency, and whether its actions can maintain stability over time.
Conclusion
As agents begin to have real authority, the market will require a clear method for measuring their reliability. Agents will carry portable performance records based on verified execution and benchmarking, scores will adjust as quality declines, and permissions will trace back to explicit authorization. Insurers, merchants, and compliance systems will rely on this data to decide which agents can access capital, data, or regulated workflows.
In summary, these layers start to constitute the infrastructure of the agent economy:
- Discoverability: Agents must be able to discover services in a machine-readable way; otherwise, they cannot find opportunities.
- Identity: Agents must prove who they are and who authorized them; otherwise, they cannot enter a system.
- Reputation: Agents must establish verifiable records demonstrating their trustworthiness to gain enduring economic trust.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








