Original author: David, Deep Tide TechFlow
On the afternoon of January 20, X open-sourced a new version of its recommendation algorithm.
Musk's reply was quite interesting: "We know this algorithm is dumb and needs a major overhaul, but at least you can see us struggling to improve it in real-time. Other social platforms wouldn't dare to do this."
This statement has two implications. First, it acknowledges that the algorithm has issues; second, it uses "transparency" as a selling point.
This is the second time X has open-sourced its algorithm. The version from 2023 hadn't been updated in three years and was long disconnected from the actual system. This time, it has been completely rewritten, with the core model switching from traditional machine learning to the Grok transformer, with the official statement claiming that "manual feature engineering has been completely eliminated."
In simpler terms: the old algorithm relied on engineers manually tuning parameters, while now AI directly analyzes your interaction history to decide whether to promote your content.
For content creators, this means that the previous "best times to post" and "tags to gain followers" strategies may no longer be effective.
We also explored the open-source GitHub repository, and with the help of AI, we found that the code indeed contains some hard logic worth examining.
Changes in Algorithm Logic: From Manual Definition to AI Automatic Judgment
First, let's clarify the differences between the old and new versions, as it can make the following discussion easier.
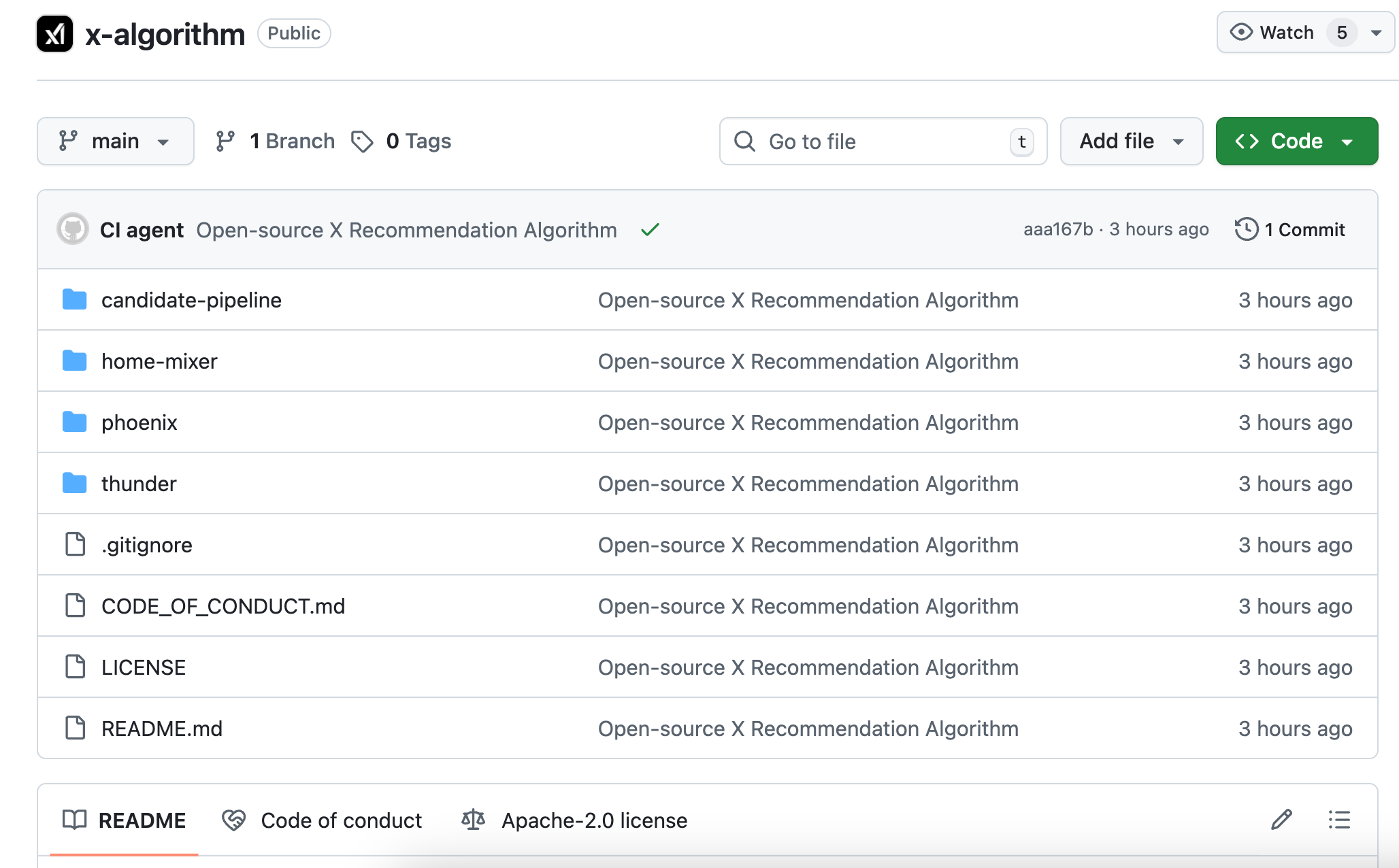
In 2023, the version open-sourced by Twitter was called Heavy Ranker, which is essentially traditional machine learning. Engineers had to manually define hundreds of "features": Does this post have an image? How many followers does the poster have? How long ago was it posted? Does the post contain a link?
Then, they assigned weights to each feature, tweaking them to see which combinations worked best.
The newly open-sourced version is called Phoenix, and its architecture is completely different. You can think of it as an algorithm that relies more on AI large models, with the core using Grok's transformer model, which employs the same type of technology as ChatGPT and Claude.
The official README document states very clearly: "We have eliminated every single hand-engineered feature."
All the traditional rules that relied on manually extracting content features have been completely cut.
So now, what does this algorithm rely on to judge whether content is good or not?
The answer is your behavior sequence. What you have liked in the past, who you have replied to, which posts you have spent more than two minutes on, and which types of accounts you have blocked. Phoenix feeds this behavior into the transformer, allowing the model to learn patterns and summarize them on its own.
To put it simply: the old algorithm was like a manually created scoring sheet, where each checked item counted towards the score;
the new algorithm is like an AI that has seen all your browsing history, directly guessing what you want to see next.
For creators, this means two things:
First, the previous techniques like "best posting times" and "golden tags" have become less valuable. Because the model no longer looks at these fixed features; it considers each user's personal preferences.
Second, whether your content gets promoted increasingly depends on "how the people who see your content will react." This reaction is quantified into 15 types of behavior predictions, which we will discuss in the next chapter.
The Algorithm Predicts Your 15 Types of Reactions
When Phoenix receives a post to recommend, it predicts the 15 types of behaviors that the current user might exhibit upon seeing this content:
- Positive behaviors: such as liking, replying, retweeting, quote retweeting, clicking on the post, clicking on the author's profile, watching more than half of a video, expanding images, sharing, staying for a certain duration, following the author
- Negative behaviors: such as clicking "not interested," blocking the author, muting the author, reporting
Each behavior corresponds to a predicted probability. For example, the model might determine that you have a 60% chance of liking this post and a 5% chance of blocking this author, etc.
Then the algorithm does a simple thing: it multiplies these probabilities by their respective weights, sums them up, and gets a total score.
The formula looks like this:
Final Score = Σ ( weight × P(action) )
The weights for positive behaviors are positive numbers, while the weights for negative behaviors are negative numbers.
Posts with higher total scores are ranked higher, while those with lower scores sink down.
To put it plainly:
Now, whether content is good or not is really not determined by the quality of the content itself (of course, readability and altruism are the foundation of dissemination); rather, it increasingly depends on "what reaction this content will provoke in you." The algorithm does not care about the quality of the post itself; it only cares about your behavior.
Following this line of thought, in an extreme case, a vulgar post that provokes a response might score higher than a high-quality post that receives no interaction. This may be the underlying logic of this system.
However, the newly open-sourced version of the algorithm has not disclosed the specific values of behavior weights, but the 2023 version did.
Old Version Reference: One Report = 738 Likes
Next, we can examine the data from 2023. Although it is old, it can help you understand how much "value" different behaviors have in the eyes of the algorithm.
On April 5, 2023, X indeed publicly released a set of weight data on GitHub.
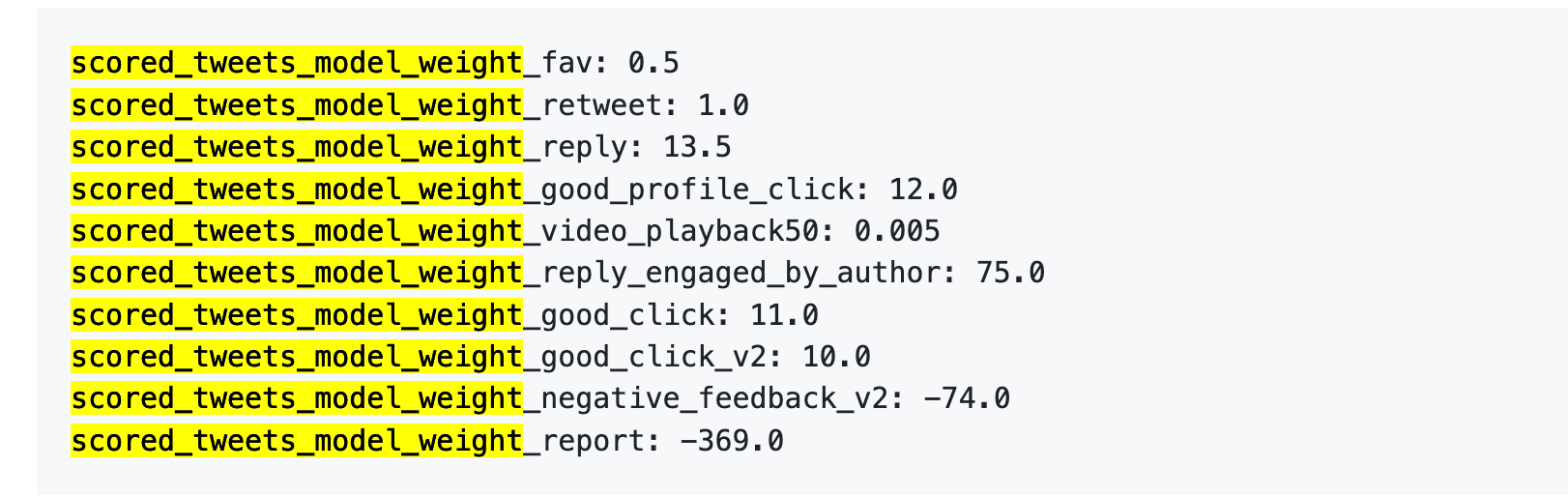
Here are the numbers:
To put it more plainly:
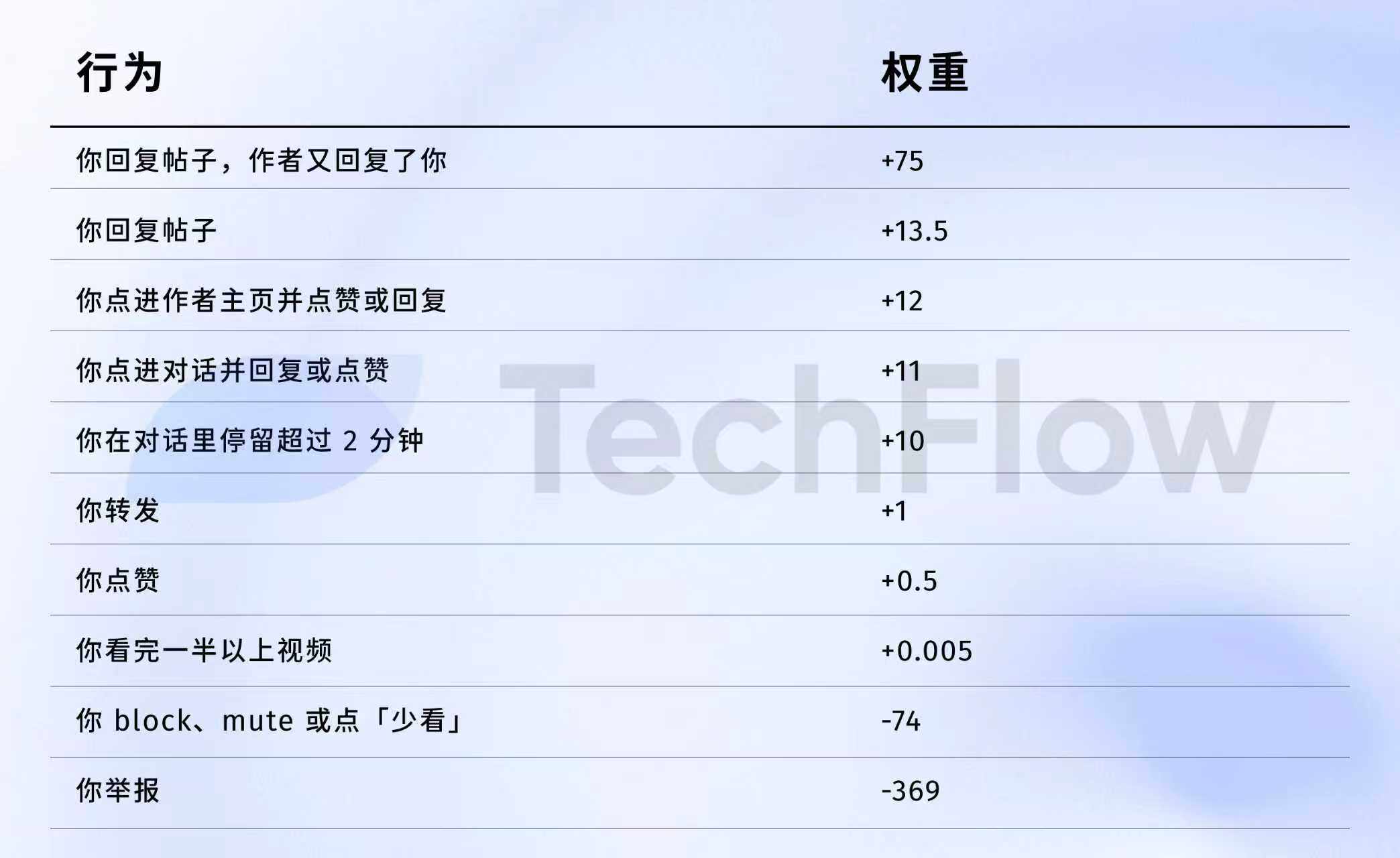
Data source: Old version GitHub twitter/the-algorithm-ml repository, click to view the original algorithm
Several numbers are worth a closer look.
First, likes are almost worthless. The weight is only 0.5, the lowest among all positive behaviors. In the eyes of the algorithm, the value of a like is approximately zero.
Second, interactive dialogue is the real currency. The weight for "you reply, and the author replies to you" is 75, which is 150 times that of a like. The algorithm prefers to see back-and-forth dialogue rather than one-sided likes.
Third, negative feedback carries a high cost. One block or mute (-74) requires 148 likes to offset. One report (-369) requires 738 likes. Moreover, these negative scores accumulate into your account's reputation score, affecting the distribution of all subsequent posts.
Fourth, video completion rates have an absurdly low weight. It is only 0.005, which can almost be ignored. This sharply contrasts with Douyin and TikTok, which treat completion rates as a core metric.
The official document also states: "The exact weights in the file can be adjusted at any time… Since then, we have periodically adjusted the weights to optimize for platform metrics."
Weights can be adjusted at any time, and they have indeed been adjusted.
The new version has not disclosed specific values, but the logic framework written in the README is the same: positive points for positive actions, negative points for negative actions, and weighted summation.
The specific numbers may have changed, but the magnitude relationships are likely still the same. Replying to others' comments is more useful than receiving 100 likes. Making people want to block you is worse than having no interaction at all.
Knowing this, what can we creators do?
After examining the old and new Twitter algorithm codes, we can distill a few actionable conclusions.
1. Reply to your commenters. The weight for "author replying to commenter" is the highest scoring item (+75), which is 150 times higher than a user liking a post. This doesn't mean you should seek comments, but if someone comments, reply. Even a simple "thank you" will be noted by the algorithm.
2. Don’t make people want to scroll away. The negative impact of one block requires 148 likes to offset. Controversial content can indeed provoke interaction, but if the interaction leads to "this person is annoying, block," your account's reputation score will continue to suffer, affecting the distribution of all subsequent posts. Controversial traffic is a double-edged sword; think twice before cutting others down.
3. Place external links in the comments. The algorithm does not want to direct users off-site. Including links in the main text will lead to reduced visibility, as Musk himself has publicly stated. If you want to drive traffic, write content in the main text and place the link in the first comment.
4. Don’t spam. The new version includes an Author Diversity Scorer, which reduces the weight of posts from the same author appearing consecutively. The design intent is to diversify users' feeds, but the side effect is that posting ten times in a row is less effective than posting one well-crafted piece.
5. There is no "best posting time" anymore. The old algorithm had the "posting time" as a manual feature, which has been cut in the new version. Phoenix only looks at user behavior sequences and does not consider when a post was made. Strategies like "posting on Tuesday at 3 PM is most effective" have become increasingly less valuable.
These are the insights that can be gleaned from the code.
There are also some scoring factors from X's public documents that are not included in this open-source repository: blue check verification provides a boost, all caps will be penalized, and sensitive content triggers an 80% reduction in reach. These rules have not been open-sourced, so we won't elaborate on them.
In summary, the information released in this open-source effort is quite substantial.
The complete system architecture, candidate content recall logic, ranking and scoring processes, and various filter implementations. The code is primarily in Rust and Python, with a clear structure, and the README is more detailed than many commercial projects.
However, several key elements have not been released.
1. Weight parameters are not public. The code only states "positive behaviors add points, negative behaviors deduct points," but does not specify how many points a like is worth or how many points a block deducts. The 2023 version at least revealed the numbers; this time, only the formula framework was provided.
2. Model weights are not public. Phoenix uses the Grok transformer, but the parameters of the model itself have not been disclosed. You can see how the model is called, but you cannot see how the model calculates internally.
3. Training data is not public. There is no information on what data the model was trained on, how user behavior was sampled, or how positive and negative samples were constructed.
To put it another way, this open-source effort is akin to telling you "we calculate the total score using weighted summation," but not revealing what the weights are; telling you "we use a transformer to predict behavior probabilities," but not explaining what the transformer looks like inside.
In comparison, TikTok and Instagram have not disclosed any of this information either. The amount of information released by X in this open-source effort is indeed greater than that of other mainstream platforms. However, it still falls short of being "completely transparent."
This is not to say that open-sourcing has no value. For creators and researchers, being able to see the code is certainly better than not being able to see it at all.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





