There is no absolute winner among oracles; the key lies in adaptability.
Written by: @0xWorkhorse
Translated by: Shaw Jinse Finance
In the field of decentralized finance (DeFi), oracles are the backbone of the entire infrastructure. They determine the speed, accuracy, reliability, and scalability of the interaction between smart contracts and real-world data. Chainlink is a well-established leader with a strong track record, while Pyth Network is a challenger that emphasizes first-party data. The two represent different approaches to solving the "oracle problem."
In my research, oracles are a frequently discussed topic due to their indispensable role in the field—without the support of oracles, many mechanisms cannot function properly.
Conversely, I believe it is important to deeply understand how oracles work, their specific functions, and the main participants involved.
You will see many controversial statements on social media about the "oracle war" or the "LINK vs. PYTH dispute." However, the reality is that these two projects adopt different perspectives to address the same issue, which reflects the diversity in this field. Because of this, they can be used in conjunction to leverage their unique advantages, bringing innovative solutions to our thriving industry and opening up new avenues for development.
Next, let’s explore how they operate in detail.
What do oracles actually do?
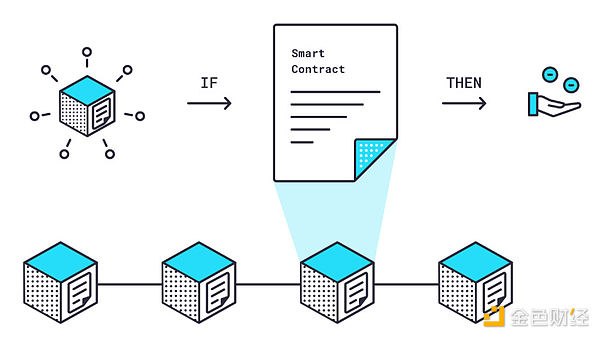
Essentially, oracles are the bridge between blockchain and the real world.
Smart contracts—automated codes that power DeFi—are inherently isolated for security reasons. They cannot directly access external data such as stock prices, weather forecasts, or election results, as this could expose them to manipulation or centralization risks.
This is where oracles come in: they obtain, verify, and relay off-chain data to on-chain applications in a trustworthy manner.
You can think of oracles as "data messengers." DeFi lending protocols like Aave require real-time asset prices to determine collateral value and prevent under-collateralized loans. Without oracles, it would not know if ETH had dropped by 10% overnight. Oracles solve this problem by aggregating data from multiple sources, applying consensus mechanisms to filter out inaccurate information, and pushing (or pulling) the verified information into the contract.
Let’s briefly list some key functions:
- Data transmission: Providing prices, messages, or computation results
- Verification: Ensuring data integrity through decentralization and cryptographic techniques
- Scalability: Handling high-frequency updates in volatile markets without clogging the blockchain
In essence, oracles enable "hybrid smart contracts," combining on-chain logic with off-chain reality, thereby unlocking a variety of use cases ranging from perpetual trading to insurance payouts.
Technical Aspects: Push vs. Pull

Chainlink primarily uses a push model, where its decentralized network of node operators continuously publishes data on-chain. Data updates are triggered by deviations (e.g., price changes exceeding a specific threshold) or fixed time intervals, ensuring continuous availability. However, this can lead to unnecessary on-chain transactions and higher costs during low activity periods.
Recent improvements, such as Chainlink Functions, have introduced more on-demand (pull-like) capabilities for custom computations, allowing developers to obtain data or perform off-chain calculations only when needed. This undoubtedly helps alleviate some inefficiencies. To this end, Chainlink data streams further narrow the latency gap and provide sub-second updates for high-frequency applications.

In contrast, Pyth Network employs a pull-based model: price data is aggregated off-chain and only published on-chain when requested by a protocol or user. This on-demand approach, combined with sub-second latency (typically 300 to 400 milliseconds, and as low as 1 millisecond for high-frequency demands via Pyth Lazer), makes it extremely efficient for real-time applications such as perpetual trading or AI-driven agents. Pyth's Express Relay further optimizes this by allowing institutions to deliver data based on auction results, reducing latency and improving accuracy in volatile markets. In volatile markets, Pyth's pull model can update up to 3.33 times per second, surpassing the speed of deviation-based push systems.
Push is like a radio station that continuously broadcasts regardless of whether anyone is listening. Pull is more like a podcast, downloaded or played only when someone wants to listen.
The push model excels in proactive, always-ready scenarios (like insurance payouts or automatic settlements). The pull model reduces waste and scales better for high-throughput demands but requires the protocol to actively make requests. This ultimately depends on the project's specific needs (and preferences) and how and when it needs to obtain (or receive) data.
Where does the data come from?
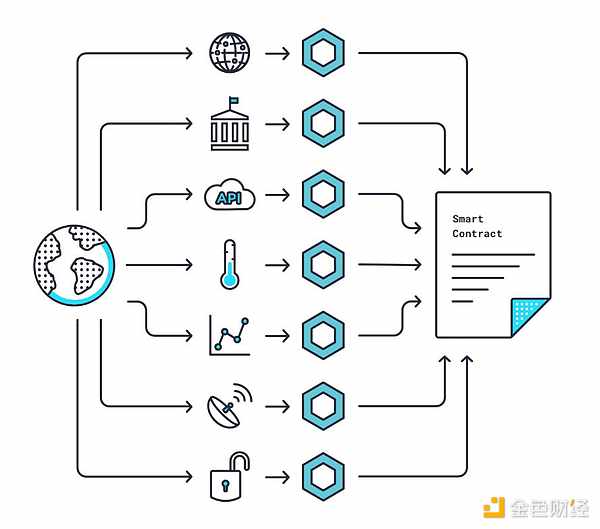
Chainlink collects data from numerous sources—including exchange APIs (like Coinbase and Kraken), aggregators (like CoinMarketCap and CoinGecko), and even non-financial data such as weather or sports scores. Node operators submit input data, and then a consensus mechanism derives the median price, emphasizing decentralization to reduce manipulation risks. This broad source support exceeds 2,000 data sources, including recent real-time stocks like Apple (AAPL) and Microsoft (MSFT), making Chainlink widely applicable in finance, gaming, insurance, and more.
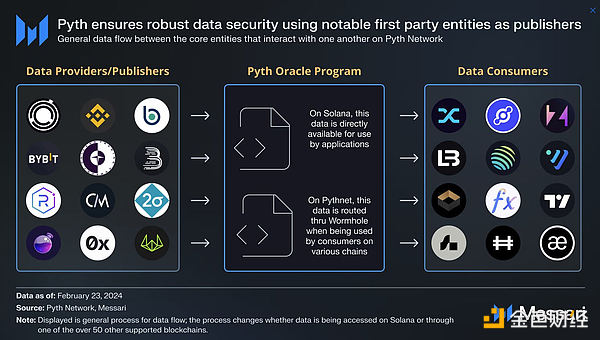
Pyth obtains data directly from first-party providers—over 120 institutions, including Jane Street, Susquehanna, the Chicago Board Options Exchange (CBOE), and Gemini. The aggregation process occurs off-chain, with each data source containing a confidence interval to enhance data quality and volatility transparency. Pyth currently offers over 1,600 real-time data sources, including more than 750 stocks, over 50 physical assets (currencies, metals), U.S. Treasury rates, and over 100 exchange-traded funds (ETFs), as well as index preview data like the FTSE 100 Index.
During significant fluctuations in Bitcoin prices, Pyth's first-party model provided a P99 percentile latency lower than that of major exchange APIs. Meanwhile, Chainlink's broader source base ensures redundancy—if some providers fail, the median remains stable. Pyth's Total Value Secured (TVS) is more diversified (61% on Solana), while Chainlink's TVS is more concentrated (97% on Ethereum), reducing single-chain risk.
Pyth's model offers speed and accuracy, but trust is concentrated on fewer (albeit higher quality) sources. Chainlink's diversity enhances resilience but may introduce slight delays during extreme market volatility.
Who uses which and why?
Chainlink has been integrated across more than 50 chains, including Ethereum, Binance Smart Chain, Polygon, Optimism, Arbitrum, Avalanche, and Base. Its Cross-Chain Interoperability Protocol (CCIP) supports messaging, token transfers, and cross-chain settlements, ensuring the security of tokenized assets in collaboration with partners like Swift and JPMorgan. By mid-2025, Chainlink is expected to facilitate over $24 trillion in transaction value.
Pyth supports over 100 chains—from Solana and Aptos to Base, TON, Sei, Monad, Berachain, and HyperEVM—thanks to its pull architecture, allowing new data sources to be instantly available across all chains.

Some use case examples:
- Aave: Relies on Chainlink for lending market health data to prevent bad debt cascades.
- Ethena: Utilizes Pyth to maintain price accuracy for stablecoins in volatile trading.
- Swift pilot: Implements cross-bank settlements using Chainlink's CCIP.
- Drift Protocol: Uses Pyth for second-level updates of perpetual contract market quotes (currently exploring using Chainlink for RWA data, which is great).
Some protocols use both technologies simultaneously, which I find particularly interesting. Chainlink is used for cross-chain messaging (CCIP) + Pyth for ultra-fast price information streams. For example, Solana's Kamino Finance leverages Chainlink for yield and cross-chain functionality while using Pyth for precise pricing in the lending market.
Pyth has broader chain coverage, but Chainlink has deeper interoperability tools within established networks and strong institutional connections in the hybrid finance space.
Thus, Chainlink's tool diversity makes it an ideal choice for non-financial Web3 applications (gaming, insurance, NFTs) and institutional bridges. Meanwhile, Pyth focuses on financial-grade DeFi, positioning itself as a data pillar for trading, lending, and RWA, with its accelerated growth posing challenges to existing enterprises.
You can see (at least from my perspective) a compelling element of teamwork here, which makes me wonder: why not use both?
Conclusion
This topic is like a profound area of inquiry; although this article is already lengthy, I still have much more to discuss about the two, and writing several thousand more words would not be excessive.
I am very optimistic about the prospect of combining both to meet specific needs. After all, the advantages of higher-quality products are self-evident.
In my view, there is no absolute winner among oracles; the key lies in adaptability.
Chainlink is a trusted "Swiss Army knife" in the DeFi space, combining versatility with robustness. Pyth, on the other hand, is a precision tool focused on speed and high accuracy in the financial sector. I believe the synergy between the two is significant.
As tokenized RWAs, AI agents, and real-time finance continue to generate new demands, we may see hybrid adoption models become the norm: leveraging Chainlink for broad and stable coverage while utilizing Pyth for applications that require extremely high speed, where milliseconds can make a significant difference. At the very least, I hope to see such applications become more common.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








