Original Author: Mohamed Baioumy & Alex Cheema
Translated by: BeWater

The full report is quite lengthy, so we have split it into two parts for publication. This is the first part, mainly discussing the core framework of AIx Crypto, specific examples, and opportunities for builders. If you want to view the full translation, please click this link.
1. Introduction
Artificial Intelligence (AI) will trigger unprecedented social changes.
With the rapid development of AI and the new possibilities it creates in various industries, it will inevitably lead to widespread economic disruption. The crypto industry is no exception. In the first week of 2024, we observed three major DeFi attacks, with $76 billion at risk in DeFi protocols. Using AI, we can check for security vulnerabilities in smart contracts and integrate AI-based security layers into the blockchain.
The limitation of AI lies in the fact that bad actors can abuse powerful models, as evidenced by the malicious spread of deepfakes. Fortunately, various advances in cryptography will introduce new capabilities to AI models, greatly enriching the AI industry while addressing some serious flaws.
The integration of AI and the crypto field will give rise to numerous projects worth paying attention to. Some of these projects will provide solutions to the above-mentioned problems, while others will combine AI and Crypto in a superficial way that does not bring real benefits.
In this report, we will introduce the conceptual framework, specific examples, and insights to help you understand the past, present, and future of this field.

2. Core Framework of AI x Crypto
In this section, we will introduce some practical tools to help you analyze AI x Crypto projects in more detail.
2.1 What are AI (Artificial Intelligence) x Crypto (Cryptocurrency) projects?
Let's review some examples of projects that use both crypto and AI, and then discuss whether they truly belong to AI x Crypto projects.

This case demonstrates how cryptocurrency technology can help and improve an AI product—using cryptographic methods to change the training of AI. This has resulted in a product that cannot be achieved solely with AI technology: a model that can accept encrypted instructions.
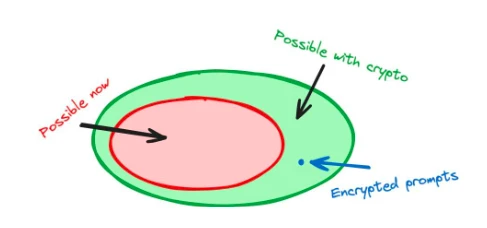
Figure 1: Internal changes to the AI stack using cryptographic technology can generate new functionalities. For example, FHE allows us to use encrypted instructions.

In this case, AI technology is used to improve a cryptographic product—opposite to the situation we discussed earlier. Dorsa provides an AI model that makes the process of creating secure smart contracts faster and cheaper. Although it is off-chain, the use of AI models still contributes to the crypto project: smart contracts are typically at the core of crypto project solutions.
Dorsa's AI capabilities can identify vulnerabilities that humans forget to check, thus preventing future hacker attacks. However, this particular example does not utilize AI to give cryptographic products capabilities that were previously unattainable—writing secure smart contracts. Dorsa's AI simply makes this process better and faster. However, this is an example of AI technology (model) improving cryptographic products (smart contracts).

LoverGPT is not an example of Crypto x AI. We have already established that AI can help improve the cryptographic technology stack, and vice versa, as demonstrated by the examples of Privasea and Dorsa. However, in the case of LoverGPT, the cryptographic part and the AI part do not interact with each other; they simply coexist in the product. To consider a project as an AI x Crypto project, it is not enough for AI and Crypto to contribute to the same product or solution—they must intertwine and cooperate with each other to produce a solution.

Cryptographic technology and AI can be directly combined to produce better solutions. Using them in combination can make them work better together in the overall project. Only projects involving the collaborative use of these technologies are classified as AI x Crypto projects.
2.2 How AI and Crypto Promote Each Other

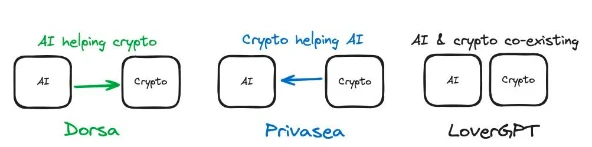
Figure 2: The combination of AI and crypto in three different products
Let's review the previous case studies. In Privasea, FHE (i.e., cryptographic technology) is used to generate an AI model that can accept encrypted input. Therefore, we are using Crypto (encryption) solutions to improve the training process of AI, so Crypto is helping AI. In Dorsa, an AI model is used to review the security of smart contracts. An AI solution is used to improve cryptographic products, so AI is helping Crypto. When evaluating projects at the intersection of AI x Crypto, this gives us an important dimension: is Crypto being used to help AI or is AI being used to help Crypto?
This simple question can help us discover the important aspects of the current use case, namely, what is the key issue to be addressed? In the case of Dorsa, the expected outcome is a secure smart contract. This can be achieved by skilled developers, and Dorsa happens to use AI to enhance the efficiency of this process. However, fundamentally, we are only concerned with the security of smart contracts. Once the key issue is clear, we can determine whether AI is helping Crypto or Crypto is helping AI. In some cases, there is no meaningful interaction between the two (e.g., LoverGPT).
The table below provides several examples in each category.
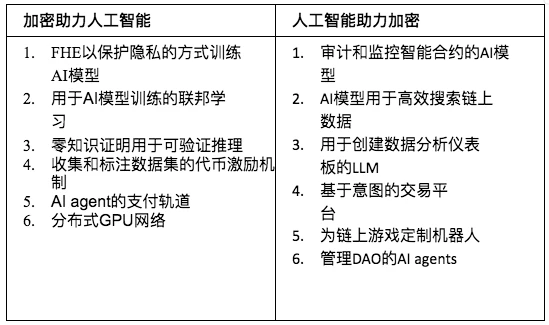
Table 1: How Crypto and AI are Combined
You can find a directory of over 150 AI x Crypto projects in the appendix. If we have missed any, or if you have any feedback, please contact us!
2.2.1 Summary
Both AI and Crypto have the ability to support the other technology in achieving its goals. When evaluating projects, the key is to understand whether their core is an AI product or a Crypto product.
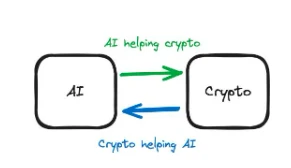
Figure 3: Differentiation
2.3 Internal and External Support
Let's take an example of Crypto helping AI. When there is a change in the specific technical set that makes up AI, the overall capability of the AI solution also changes. This technical set is called a stack. The AI stack includes the mathematical concepts and algorithms that make up various aspects of AI. The specific techniques used for processing training data, training models, and model inference are all part of the stack.

Within the stack, there are deep connections between the different parts—the combination of specific techniques determines the functionality of the stack. Therefore, changing the stack is equivalent to changing the goals that the entire technology can achieve. Introducing new technologies into the stack can create new technological possibilities—Ethereum added new technologies to its cryptographic stack, making smart contracts possible. Similarly, changes to the stack can allow developers to bypass previously considered inherent technical issues—Polygon's changes to the Ethereum cryptographic stack enabled them to reduce transaction fees to levels previously thought unattainable.

Internal Support: Cryptographic technology can be used to make internal changes to the AI stack, such as altering the technical means of training models. An example is Privasea, which integrates a modified AI stack with a built-in encrypted portion in the AI stack.
External Support: Crypto is used to support AI-based functionalities without modifying the AI stack. Bittensor is an example, as it incentivizes users to contribute data, which can be used to train AI models. In this case, the training or usage of the model remains unchanged, and the AI stack undergoes no modification. However, the use of economic incentives in the Bittensor network helps the AI stack better achieve its goals.
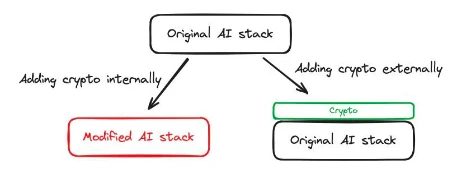
Figure 4: Explanation of the previous discussion
Similarly, AI can provide internal or external support to Crypto:
Internal Support: AI technology is used within the crypto stack. AI is on-chain and directly connected to parts within the crypto stack. For example, on-chain AI agents manage a DAO. This AI not only assists the crypto stack but is an integral part deeply embedded in the technology stack, ensuring the proper functioning of the DAO.
External Support: AI provides external support to the crypto stack. AI is used to support the Crypto stack without making internal changes. Platforms like Dorsa use AI models to ensure the security of smart contracts. The AI is off-chain, serving as an external tool to make the process of writing secure smart contracts faster and cheaper.
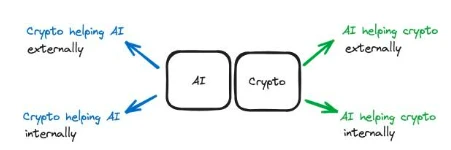
Figure 5: Difference between internal and external support in the upgraded model
The first stage in analyzing any AI x Crypto project is to determine which category it belongs to.
2.4 Identifying Bottlenecks
Compared to external support, internal support characterized by deep technical integration often involves more technical complexity. For example, if we want to modify the AI stack by introducing FHE or Zero-Knowledge Proofs (ZKPs), we would need technical personnel with considerable expertise in both cryptography and AI. However, few individuals belong to this intersection. These companies include Modulus, EZKL, Zama, and Privasea.
Therefore, these companies require significant funding and rare talent to advance their solutions. Integrating AI into smart contracts also requires in-depth knowledge; companies like Ritual and Ora must address complex engineering challenges.
Conversely, external support also has bottlenecks, but they typically involve lower levels of technical complexity. For example, adding cryptocurrency payment functionality to AI agents does not require significant modifications to the model. It is relatively easy to implement. Although technically not complex for AI engineers to build a ChatGPT plugin to retrieve statistical data from the DeFi LLama webpage, few AI engineers are members of the crypto community. While the task is not technically complex, there are few AI engineers who can use these tools, and many are unaware of these possibilities.
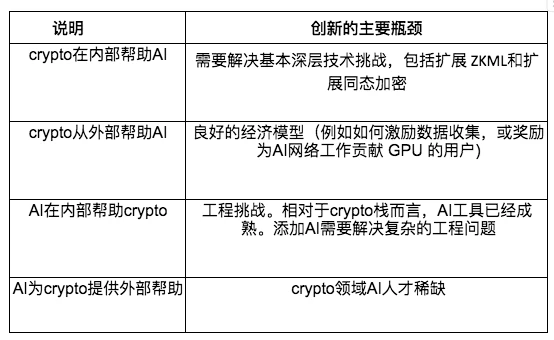
2.5 Measuring Utility
There are good projects in all four categories.
Integrating artificial intelligence into the cryptographic technology stack will allow smart contract developers to access on-chain AI models, increasing the number of possibilities and potentially leading to widespread innovation. The same applies to integrating crypto into the AI stack—deep technological integration will create new possibilities.
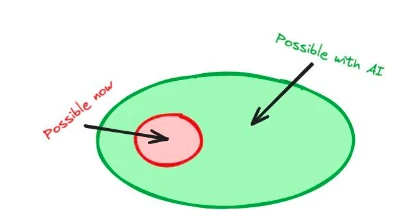
Figure 6: Adding artificial intelligence to the cryptographic stack for developers to access new functionalities
When artificial intelligence provides external assistance to crypto, the integration of AI is likely to improve existing products and generate fewer breakthroughs, introducing fewer possibilities. For example, using AI models to write smart contracts may make the process faster, cheaper, and more secure than before, but it is less likely to produce smart contracts that were previously impossible. The same applies to crypto technology providing external assistance to AI—token incentives can be used for the AI stack, but it is unlikely to redefine the way we train AI models.
In summary, integrating one technology into another technology stack may create new functionalities, while using technology outside the stack may improve usability and efficiency.
2.6 Evaluating Projects
We can estimate partial returns of a specific project based on the quadrant in which it falls, as internal support between technologies can bring greater returns. However, estimating the total returns of a project after risk adjustment requires consideration of more factors and risks.
One factor to consider is whether the project in question is useful in a Web2, Web3, or both backgrounds. AI models with FHE capabilities can be used to replace AI models without FHE capabilities—introducing FHE capabilities is useful in both domains, and privacy is valuable in any case. However, integrating AI models into smart contracts can only be used in a Web3 environment.
As mentioned earlier, whether the integration between AI and crypto fields is internal or external to the project will also determine the project's potential for growth. Projects involving internal support often generate new capabilities and greater efficiency improvements, which are more valuable.
We must also consider the time span for the maturity of the technology, which will determine how long it takes for people to see returns on their investment. To do this, we can analyze current progress and identify bottleneck issues related to the project (see Section 2.4).
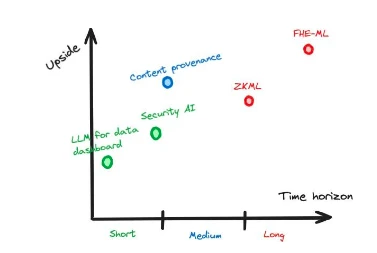
Figure 7: A hypothetical example illustrating potential upside space compared to the time span
2.7 Understanding Complex Products
Some projects involve a combination of the four categories we described, rather than just one category. In such cases, the risks and returns associated with the project often multiply, and the implementation time span is longer.
Additionally, you must consider whether the overall integrity of the project is superior to the sum of its parts—having everything in a project is often not enough to meet the needs of end-users. Highlighted approaches often produce excellent products.

2.7.1 Example 1: Flock.io
Flock.io allows the "splitting" of training models across multiple servers, where no party can access all training data. By directly participating in model training, you can contribute your own data to the model without leaking any data, which is beneficial for protecting user privacy. This involves integrating encryption to help AI internally, as it changes the AI stack (model training).
Additionally, they use encrypted token rewards for individuals participating in model training and use smart contracts to economically penalize those who disrupt the training process. This does not change the process involved in training the model, and the underlying technology remains unchanged, but all parties must adhere to the on-chain penalty mechanism. This is an example of crypto technology providing external assistance to AI.
Most importantly, integrating encryption to help AI internally introduces a new capability: models can be trained through a decentralized network while maintaining data privacy. However, the use of cryptocurrency to help AI externally does not introduce new capabilities, as the tokens are only used to incentivize users to contribute to the network. Users can receive compensation in fiat currency, and using cryptocurrency incentives is a better solution that can improve system efficiency, but it does not introduce new capabilities.
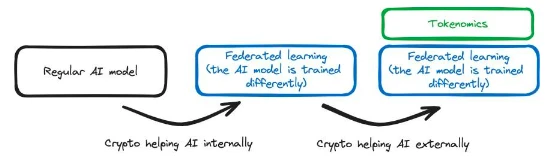
Figure 8: Illustration of Flock.io and the changes in the stack, where color changes indicate internal changes
2.7.2 Example 2: Rockybot
Rockybot is a trading bot that operates on-chain. It uses artificial intelligence to determine which trades to make, but because the AI model itself does not run on the smart contract, we rely on service providers to run the model for us and then tell the smart contract the AI's decisions, and prove to the smart contract that they are not lying. If the smart contract does not check whether the service provider is lying, the service provider may make harmful trades on our behalf. Rockybot allows us to use ZK proofs to prove to the smart contract that the service provider is not lying. Here, ZK is used to change the AI stack. The AI stack needs to adopt ZK technology, or else we cannot use ZK to prove the model's decisions to the smart contract.
As a result of adopting ZK technology, the output of the AI model becomes verifiable and can be queried from the blockchain, meaning that the AI model is used internally in the cryptographic stack. In this case, we use the AI model in the smart contract to fairly determine trades and prices. This would not be possible without AI.
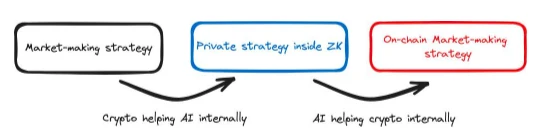
Figure 9: Illustration of Rockybot and the changes in the stack. Color changes indicate internal support changes
3. Issues Worth Exploring
3.1 The Crypto Field and the Deepfake Revelation

On January 23, a deepfake voice message falsely claiming to be President Biden urged Democratic voters not to vote in the 2024 primaries. Less than a week later, a financial professional lost $25 million due to a deepfake video call impersonating their colleague. Meanwhile, on X (formerly Twitter), an AI-generated explicit photo of Taylor Swift garnered 45 million views, sparking widespread outrage. These events all occurred in the first two months of 2024, serving as a microcosm of the destructive impact of deepfakes in the political, financial, and social media spheres.
3.1.1 How Did They Become a Problem?
Image manipulation is not a new phenomenon. In 1917, The Strand magazine published intricately crafted paper-cut photographs designed to resemble fairies; many believed these photos were compelling evidence of supernatural beings.

Figure 10: One of the "Cottingley Fairies" photographs. Created by Sir Arthur Conan Doyle, the creator of Sherlock Holmes, these faked photos were presented as evidence of supernatural phenomena.
Over time, forgery became increasingly easier and cheaper, significantly accelerating the spread of misinformation. For example, during the 2004 U.S. presidential election, a doctored photo falsely depicted Democratic nominee John Kerry participating in a protest alongside Jane Fonda, a controversial American activist. The Cottingley Fairies required careful staging and cutouts from cardboard to create depictions from children's storybooks, while this forgery was a simple task accomplished using Photoshop.

Figure 11: This photo suggests John Kerry and Jane Fonda on stage at an anti-Vietnam War rally. It was later revealed to be a doctored photo, created by combining two existing images using Photoshop.
However, as we learned to identify editing traces, the risks posed by fake photos diminished. In the case of the "Tourist Guy," amateur enthusiasts were able to identify manipulated photos by observing inconsistencies in white balance among different objects in the scene. This was a result of the public's increased awareness of false information; people had learned to pay attention to editing traces in photos. "Photoshopped" has become a common term, and signs of image manipulation are now widely recognized, with photo evidence no longer considered unalterable proof.
3.1.1.1 Deepfakes Make Forgery Easier, Cheaper, and More Realistic
In the past, forged documents were easily detected by the naked eye, but deepfake technology has made it simple and inexpensive to create images that are almost indistinguishable from real photos. For example, the OnlyFake website uses deepfake technology to generate realistic fake ID photos in minutes for just $15. These photos are used to bypass the Know Your Customer (KYC) anti-fraud measures of OKX, a cryptocurrency exchange. In the case of OKX, these deepfake IDs fooled their employees, all of whom had been trained to identify doctored images and deepfakes. This highlights that even professionals are no longer able to detect fraud based on deepfakes with the naked eye.
As images are deepfaked, people have relied more on video evidence, but deepfakes are soon to severely undermine the credibility of video evidence. A researcher at the University of Texas at Dallas successfully bypassed identity verification measures implemented by a KYC provider using a free deepfake face-swapping tool. This is a significant advancement—previously, creating high-quality videos was both expensive and time-consuming.
In 2019, it took two weeks and $552 to create a 38-second deepfake video of Mark Zuckerberg and Star Trek's Data, with noticeable visual flaws. Today, we can create realistic deepfake videos for free in minutes.
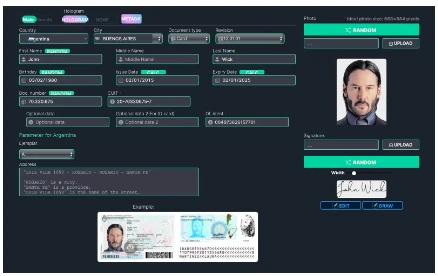
Figure 12: OnlyFake panel for creating fake ID photos in minutes
3.1.1.2 Why Videos Are So Important
Before the advent of deepfake technology, videos were considered reliable evidence. Unlike easily forged images, videos historically have been difficult to fake, making them recognized as reliable evidence in court. This makes deepfake videos particularly dangerous.
At the same time, the emergence of deepfakes could also lead to the denial of genuine videos, as a video of U.S. President Biden was mistakenly labeled as a deepfake. Critics cited Biden's unblinking eyes and lighting differences as evidence, claims that were later debunked. This poses a problem—deepfakes not only make fake things look real, but also make real things look fake, further blurring the line between reality and fiction, increasing the difficulty of accountability.

Deepfakes have enabled large-scale targeted advertising. We may soon see another version of YouTube, where the content, the people speaking, and the locations mentioned are all personalized for the audience. An early example is the localized ads by Zomato, where actor Hrithik Roshan orders from popular restaurants in the viewer's city. Zomato generated different deepfake ads tailored to the audience's GPS location, showcasing restaurants in their area.
3.1.2 Current Shortcomings of Solutions
3.1.2.1 Awareness
Current deepfake technology is so advanced that it can deceive trained experts. This allows hackers to bypass identity verification (KYC/AML) processes and even human review. This indicates that we cannot visually distinguish deepfakes from real images with the naked eye. We cannot rely solely on skepticism towards images to guard against deepfakes; we need more tools to combat the prevalence of deepfakes.
3.1.2.2 Platforms
Social media platforms are not inclined to effectively curb deepfakes without strong social pressure. For example, Meta bans deepfake videos containing false audio but refuses to ban purely manipulated video content. They went against the recommendations of their oversight board and did not remove a deepfake video showing President Biden touching his granddaughter, which was purely manipulated content.
3.1.2.3 Policies
We need to enact laws to effectively address the new risks of deepfakes while not restricting less problematic uses, such as in the arts or education, as these uses do not seek to deceive. Events like the unauthorized spread of deepfake images of Taylor Swift have prompted lawmakers to enact stricter laws to combat such deepfake behavior. It may be necessary to strengthen online review processes in law, but proposals to ban all AI-generated content have raised concerns among filmmakers and digital artists, who fear this would unfairly restrict their work. Finding the right balance is crucial, or legitimate creative applications will be stifled.
Pushing lawmakers to raise the barriers to entry for training powerful models can ensure that large tech companies maintain their AI monopoly. This could lead to an irreversible concentration of power in the hands of a few companies—such as the Executive Order 14110 involving AI suggests strict requirements for companies with significant computing power.

Figure 13: Vice President Kamala Harris applauding as President Joe Biden signs the first U.S. executive order on artificial intelligence
3.1.2.4 Technology
Establishing safeguards directly within AI models to prevent misuse is the first line of defense, but these safeguards are constantly being bypassed. AI models are difficult to audit because we do not know how to use existing low-level tools to modify behavior in higher dimensions. Additionally, companies training AI models can use the implementation of safeguards as an excuse to introduce bad reviews and biases into their models. This is problematic because large tech AI companies are not accountable to public will—companies can freely influence their models to the detriment of users.
Even if the power to create powerful AI is not concentrated in dishonest companies, creating an AI that has both safeguards and is unbiased may still be impossible. Researchers struggle to define what constitutes misuse, making it difficult to handle user requests in a neutral, balanced manner while preventing misuse. If we cannot define misuse, it seems necessary to lower the strictness of safeguards, potentially leading to a recurrence of misuse. Therefore, completely banning the misuse of AI models is not feasible.
One solution is to detect malicious deepfakes immediately after they appear, rather than preventing their creation. However, deepfake detection AI models (such as the one deployed by OpenAI) are becoming outdated and inaccurate. While deepfake detection methods have become increasingly complex, the technology to create deepfakes is becoming more complex at an even faster rate—deepfake detectors are losing in the technological arms race. This makes it difficult to identify deepfake news based solely on media. AI is advanced enough to create deepfakes that are so realistic that AI cannot judge their accuracy.
Watermarking technology can discreetly mark deepfakes, allowing us to identify them wherever they appear. However, deepfakes do not always come with watermarks, as watermarks must be deliberately added. For companies voluntarily marking their deepfake images (such as OpenAI), watermarks are an effective method. Nevertheless, watermarks can be removed or forged with simple tools, bypassing any watermark-based deepfake prevention solution. Watermarks can also be accidentally removed, as most social media platforms automatically delete watermarks.
The most popular deepfake watermarking technology is C2PA (Content Authenticity and Provenance Association). It aims to prevent misinformation by tracking media sources and storing this information in media metadata. With support from companies like Microsoft, Google, and Adobe, C2PA is likely to be widely adopted throughout the content supply chain and is more popular than other similar technologies.
Unfortunately, C2PA also has its own weaknesses. Since C2PA stores the complete editing history of an image and uses encryption keys controlled by editing software that complies with C2PA standards to verify each edit, we must trust these editing software. However, people are likely to accept edited images with valid C2PA metadata without considering whether they trust every party in the editing chain. Therefore, if any editing software is compromised or capable of malicious editing, it is possible to make others believe that forged or maliciously edited images are real.

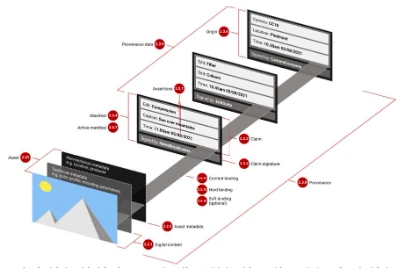
Figure 14: Example of an image with a series of edits and C2PA-compliant metadata. Each edit is signed by a different trusted party, but only the final edited image is public. Source: Real Photos vs. AI-Generated Art: New Standard (C2PA) Uses PKI to Show an Image's History
Additionally, the encryption signatures and metadata contained in C2PA watermarks can be linked to specific users or devices. In some cases, C2PA metadata can link all images captured by your camera together: if we know a certain image comes from someone's camera, we can identify all other images from that camera. This can help anonymize whistleblowers when posting photos.
All potential solutions will face a unique set of challenges. Despite these varied challenges—including limitations in social awareness, flaws in large tech companies, difficulties in implementing regulatory policies, and our technological limitations.

3.1.3 Can the Crypto Field Solve This Problem?
Open-source deepfake models have already begun to spread. Therefore, some may argue that there will always be ways to misuse deepfakes to manipulate others' images; even if this practice is criminalized, some will still choose to generate unethical deepfake content. However, we can address this issue by making malicious deepfake content exit the mainstream. We can prevent people from believing that deepfake images are real and create platforms that restrict the spread of deepfake content. This section will introduce various solutions based on encryption technology to address the misleading issues caused by the spread of malicious deepfakes, while emphasizing the limitations of each method.
3.1.3.1 Hardware Authentication
A hardware-authenticated camera embeds a unique proof with each photo it captures, proving that the photo was taken by that specific camera. This proof is generated by an unforgeable, tamper-resistant chip unique to the camera, ensuring the authenticity of the image. Similar procedures can be applied to audio and video.

The authentication proof tells us that the image was captured by a genuine camera, meaning we can generally trust it to be a photo of a real object. We can flag images without this proof. However, if the camera captures a forged scene that looks like a real one, this method becomes ineffective—you can simply point the camera at a forged image. Currently, we can determine if a photo was taken from a digital screen by checking for distortions in the captured image, but fraudsters will find ways to conceal these imperfections (e.g., by using better screens or by limiting lens glare). Ultimately, even AI tools cannot identify this deception, as fraudsters can find ways to avoid all these distortions.
Hardware authentication will reduce the instances of trusting forged images, but in a few cases, we still need additional tools to prevent the spread of deepfake images when cameras are compromised or abused. As discussed earlier, using hardware-verified cameras can still lead to the mistaken impression that deepfake content is real images, for reasons such as camera compromise or using the camera to capture deepfake scenes from a computer screen. To address this issue, additional tools such as camera blacklists are needed.
Camera blacklists will allow social media platforms and applications to flag images from specific cameras known to have produced misleading images in the past. Blacklists can be used without publicly disclosing information that can be used to trace the camera, such as the camera ID.
However, it is currently unclear who will maintain camera blacklists, and it is unclear how to prevent people from adding the whistleblower's camera to the blacklist after being bribed (as a retaliatory measure).
3.1.3.2 Blockchain-Based Image Ledger
Blockchain is tamper-proof, so when an image appears on the internet, adding the image along with additional metadata to a ledger with a timestamp ensures that the timestamp and metadata cannot be tampered with. Accessing such records before unedited original images are maliciously edited and spread will allow us to identify malicious edits and verify the original source. This technology has been implemented on the Polygon blockchain network as part of the fact-checking tool Verify developed in collaboration with Fox News.

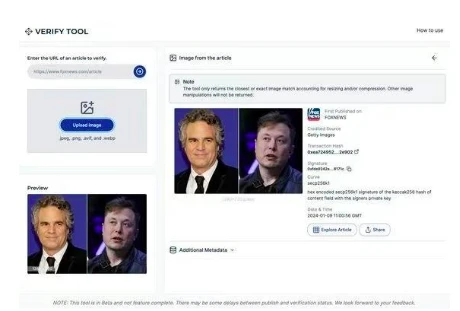
Figure 15: User interface of the blockchain-based tool Verify by Fox. Artwork can be looked up via URL. It retrieves and displays source, transaction hash, signature, timestamp, and other metadata from the Polygon blockchain
3.1.3.3 Digital Identity
If deepfakes are to undermine our trust in unverified images and videos, then trusted sources may become the only way to avoid misinformation. We have relied on trusted media sources to verify information, as they adhere to journalistic standards, fact-checking procedures, and editorial oversight to ensure the accuracy and credibility of information.
However, we need a way to verify if the content we see online comes from sources we trust. This is where the use of encrypted signature data comes in: it can mathematically prove the authorship of a piece of content.
Signatures are generated using digital keys, and since the keys are created and generated by a wallet, only the person with the relevant encrypted wallet knows it. This way, we can know who the author of the data is—simply by checking if the signature corresponds to the unique key in our personal encrypted wallet.
We can seamlessly and user-friendly attach signatures to our posts using cryptocurrency wallets. By logging into social media platforms with a cryptocurrency wallet, we can utilize the wallet to create and verify signatures on social media. Therefore, if the source of a post is untrustworthy, the platform will be able to alert us—it will use automatic signature verification to flag misinformation.
Additionally, zk-KYC infrastructure connected to wallets can bind unknown wallets to identities verified through the KYC process without compromising user privacy and anonymity. However, as deepfakes become increasingly sophisticated, the KYC process may be bypassed, allowing malicious actors to create false anonymous identities. This issue can be addressed with solutions such as Worldcoin's "Proof of Personhood" (PoP).
Proof of Personhood is a mechanism used by WorldCoin to verify that a wallet belongs to a real person and only allows one wallet per person. It uses biometric (iris) imaging device Orb to verify the wallet. Since biometric data cannot be forged, requiring social media accounts to be linked to a unique WorldCoin wallet is a viable method to prevent bad actors from creating multiple anonymous identities to conceal their unethical online behavior—at least until hackers find ways to deceive biometric imaging devices, it can address the KYC problem of deepfakes.
3.1.3.4 Economic Incentives

Authors can be penalized for misinformation, and users can be rewarded for identifying misinformation. For example, "Veracity Bonds" allow media organizations to stake the accuracy of their publications, facing economic penalties for misinformation. This provides these media companies with an economic incentive to ensure the truthfulness of information.
Veracity Bonds will be an integral part of the "Truth Market," where different systems compete for user trust by verifying the truthfulness of content in the most efficient and robust way. This is similar to proof markets such as Succinct Network and =nil Proof Market, but it addresses the more challenging issue of truth verification.
Cryptography alone is not enough. Smart contracts can serve as a means to enforce the economic incentives necessary for these "truth markets" to function, so blockchain technology may play a central role in helping combat misinformation.
3.1.3.5 Reputation Scores

We can use reputation to represent credibility. For example, we can judge whether to trust someone's words on Twitter based on how many followers they have. However, reputation systems should consider the past records of each author, not just their popularity. We do not want to conflate credibility with popularity.
We cannot allow people to generate unlimited anonymous identities, as they can then discard their identity when their reputation is damaged, to reset their social credibility. This requires us to use non-replicable digital identities, as mentioned in the previous section.
We can also use evidence from "Truth Markets" and "Hardware Authentication" to determine a person's reputation, as these are reliable methods for tracking their true records. The reputation system is a culmination of all the other solutions discussed so far, making it the most powerful and comprehensive method series.
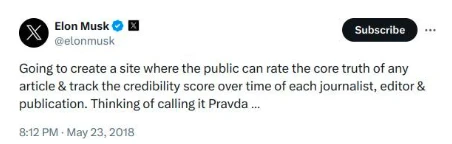
Figure 16: Musk hinted at the establishment of a website to rate the credibility of journal articles, edits, and publications in 2018
3.1.4 Is the Cryptographic Solution Scalable?
The blockchain solutions mentioned above require a fast and high-storage blockchain—otherwise, we will not be able to include all images in a verifiable time record on the chain. As the volume of online data published daily grows exponentially, this will only become more and more important. However, there are algorithms that can compress data in a way that is still verifiable.
Additionally, signatures generated through hardware authentication are not applicable to edited versions of images: zk-SNARKs must be used to generate editing proofs. ZK Microphone is an implementation of editing proofs for audio.
3.1.5 Deepfakes are not Inherently Bad
It must be acknowledged that not all deepfakes are harmful. This technology also has innocent uses, such as this artificial intelligence-generated video of Taylor Swift teaching math. Due to the low cost and accessibility of deepfakes, it has created personalized experiences. For example, HeyGen allows users to send personal information with an AI-generated face resembling their own. Deepfakes also help narrow the language gap through voice dubbing translation.
Based on the deepfake technology, AI counterpart services charge high fees and lack accountability and supervision. The top internet celebrity Amouranth on OnlyFans has released her digital persona, allowing fans to chat with her privately. These startups can restrict or even shut down access, such as the AI companion service called Soulmate (source: Futurism).
By hosting AI models on the blockchain, we can use smart contracts to transparently fund and control the models. This will ensure that users never lose access to the models and help creators allocate profits between contributors and investors. However, there are technical challenges. The most popular technology for on-chain models, zkML (used by Giza, Modulus Labs, and EZKL), can slow down model operation by 1000 times. Nevertheless, research in this subfield continues, and the technology is constantly improving. For example, HyperOracle is attempting to use opML, and Aizel is building a solution based on multi-party computation (MPC) and trusted execution environments (TEE).
3.1.6 Chapter Summary
- Complex deepfakes are eroding trust in the political, financial, and social media sectors, highlighting the necessity of establishing a "verifiable network" to uphold truth and democratic integrity.
- Deepfakes, once an expensive and technologically intensive endeavor, have become easily producible with the advancement of AI, changing the landscape of misinformation.
If you are interested in this issue, please contact Arbion Halili.
- History tells us that media manipulation is not a new challenge, but AI has made it easier and cheaper to create convincing fake news, necessitating new solutions.
- Deepfake videos pose unique dangers as they undermine previously reliable evidence, leading to a dilemma where genuine actions may be perceived as fake.
- Existing countermeasures fall into awareness, platform, policy, and technical methods, each facing challenges in effectively combating deepfakes.
- Hardware authentication and blockchain provide the origin of each image and create transparent, immutable editing records, offering promising solutions.
- Cryptocurrency wallets and zk-KYC strengthen the verification and authentication of online content, while on-chain reputation systems and economic incentives (such as "Veracity Bonds") provide a market for truth.
- While acknowledging the positive uses of deepfakes, cryptographic technology also proposes a method to whitelist beneficial deepfakes, striking a balance between innovation and integrity.
3.2 Bitter Lesson

The statement may seem counterintuitive, but it holds true. The AI community rejects the notion that custom methods are ineffective, but the "bitter lesson" still applies: using the most powerful computing always yields the best results.
We must scale up: more GPUs, more data centers, more training data.
Chess computer researchers once attempted to build chess engines based on the experience of top human players, which is an example of researchers getting it wrong. The initial chess programs simply copied human opening strategies (using "opening books"). Researchers hoped the chess engines could start from strong positions without having to calculate the best moves from scratch. They also included many "tactical heuristics"—tactics used by human players, such as forks. In simple terms, the chess programs were built based on human insights into how to play successfully rather than general computational methods.
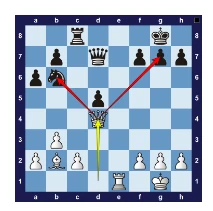
Figure 18: Fork—queen attacking two pieces

Figure 19: Example of chess opening sequence
In 1997, IBM's DeepBlue combined massive computing power and search-based techniques to defeat the world chess champion. Despite DeepBlue outperforming all "human-designed" chess engines, chess researchers shunned it. They believed that DeepBlue's success was only temporary, as it did not adopt chess strategies—in their view, it was a brute-force solution. They were wrong: in the long run, applying massive computation to general problem-solving methods often yields better results than custom methods. This high-computation ideology has led to successful Go engines (AlphaGo), improved speech recognition technology, and more reliable computer vision technology.
The latest achievement of high-computation AI methods is OpenAI's ChatGPT. Unlike previous attempts, OpenAI did not try to encode human understanding of language workings into the software. Instead, their model combines vast amounts of data from the internet with massive computation. Unlike other researchers, they did not intervene or embed any biases in the software. In the long run, the best-performing methods are always based on using massive computation for general problem-solving. This is a historical fact; in fact, we may have enough evidence to prove that it is always true.
In the long run, combining massive computation with vast amounts of data is the best approach, due to Moore's Law: over time, the cost of computation will exponentially decrease. In the short term, we may not be able to predict the significant increase in computational bandwidth, leading researchers to attempt to improve their technology by manually embedding human knowledge and algorithms into the software. This approach may work for a while, but it is not likely to be successful in the long run: embedding human knowledge into the underlying software makes the software more complex, and the model cannot improve based on additional computational power. This makes the human approach short-sighted, leading Sutton to suggest that we ignore artificial techniques and focus on applying more computation to general computing techniques.
"The Bitter Lesson" has had a significant impact on how we should build decentralized AI:
Build large networks: The above lessons highlight the urgency of developing large AI models and aggregating massive computing resources for their training, key steps in entering the new field of AI. Companies like Akash, GPUNet, and IoNet aim to provide scalable infrastructure.
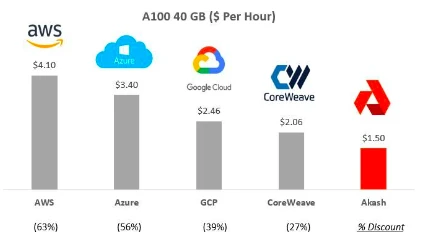
Figure 20: Comparison of Akash prices with other suppliers such as Amazon AWS
Hardware Innovation: ZKML methods have been criticized for running 1000 times slower than non-ZKML methods. This aligns with the criticisms faced by neural networks. In the 1990s, neural networks showed great promise. Yann LeCun's CNN model was a small neural network capable of classifying handwritten digit images (see Figure below) and was successful. By 1998, over 10% of banks in the United States were using this technology to read checks. However, these CNN models were not scalable, leading to a sharp decline in interest, and computer vision researchers began using human knowledge to create better systems. In 2012, researchers developed a new CNN using GPU (a popular hardware used for generating computer graphics for games, CGI, etc.) efficiency, which allowed them to achieve incredible performance surpassing all other available methods at the time. This network was called AlexNet, sparking the deep learning revolution.

Figure 22: Neural networks in the 1990s could only handle low-resolution digital images.

Figure 23: AlexNet (2012) capable of handling complex images and surpassing all alternative methods.
The upgrade of AI technology is inevitable as the cost of computation continues to decrease. Custom hardware for technologies like ZK and FHE will accelerate progress—companies like Ingonyama and academia are paving the way. In the long run, we will achieve large-scale ZKML by applying stronger computing power and improving efficiency. The only question is, how will we utilize these technologies?

Figure 24: An example of hardware progress for ZK Prover (source: Twitter)
Expanding Data: As the scale and complexity of AI models grow, it is necessary to expand datasets accordingly. Generally, the scale of the dataset should grow exponentially with the model's scale to prevent overfitting and ensure stable performance. For a model with billions of parameters, this often means planning datasets containing billions of tokens or examples. For example, Google's BERT model was trained on the entire English Wikipedia containing over 25 billion words and the BooksCorpus containing about 800 million words. Meta's LLama was trained on a corpus of 1.4 trillion words. These numbers emphasize the scale of datasets we need—as models move towards trillions of parameters, datasets must further expand. This expansion can ensure that the model captures the nuances and diversity of human language, making the development of large, high-quality datasets equally important as the model's architecture innovation. Companies like Giza, Bittensor, Bagel, and FractionAI are meeting the specific needs in this field (for challenges in the data domain, such as model collapse, adversarial attacks, and quality assurance, see Chapter 5).
Developing General Methods: In the decentralized AI field, technologies like ZKPs and FHE adopting application-specific methods are aimed at achieving immediate efficiency. Customizing solutions for specific architectures can improve performance but may sacrifice long-term flexibility and scalability, limiting broader system evolution. In contrast, focusing on general methods provides a foundation that, despite initial inefficiencies, has scalability and adaptability to various applications and future developments. Driven by trends like Moore's Law, as computing power grows and costs decrease, these methods are bound to shine. Choosing between short-term efficiency and long-term adaptability is crucial. Emphasizing general methods can prepare the future of decentralized AI, making it a robust, flexible system that fully leverages the advancements in computing technology, ensuring lasting success and relevance.
3.2.1 Conclusion
In the early stages of product development, choosing methods not limited by scale may be crucial. This is important for companies and researchers to evaluate use cases and ideas. However, the bitter lesson tells us that in the long run, we should always prioritize choosing general, scalable methods.
Here's an example of a manual method being replaced by automatic, general differentiation: before the use of automatic differentiation (autodiff) libraries like TensorFlow and PyTorch, gradients were typically computed manually or through numerical differentiation—this method was inefficient, error-prone, and problematic, wasting researchers' time, while autodiff is different. Autodiff has now become an indispensable tool, as autodiff libraries speed up experimentation and simplify model development. Therefore, general solutions win out—but before autodiff became a mature, available solution, the old manual method was a necessary condition for conducting ML research.
In conclusion, Rich Sutton's "Bitter Lesson" tells us that if we maximize the computing power of AI rather than trying to make AI mimic human-known methods, the progress of AI will be faster. We must expand existing computing power, expand data, innovate hardware, and develop general methods—adopting this approach will have many implications for the field of decentralized AI. While the "Bitter Lesson" may not apply to the initial stages of research, it may be forever correct in the long run.
3.3 AI Agents Disrupting Google and Amazon
3.3.1 Google's Monopoly Issue
Online content creators often rely on Google to publish their content. In return, if they allow Google to index and display their work, they can gain a steady stream of attention and ad revenue. However, this relationship is unbalanced; Google holds a monopoly position (over 80% of search engine traffic), a market share that content creators themselves cannot reach. Therefore, the income of content creators heavily depends on Google and other tech giants. A single decision by Google could potentially lead to the end of individual businesses.
Google's introduction of the Featured Snippets feature—displaying answers to user queries without the need to click into the original website—highlights this issue, as now information can be obtained without leaving the search engine. This disrupts the rules on which content creators rely for survival. As a condition for being indexed by Google, content creators hope their websites will receive recommended traffic and attention. Instead, the Featured Snippets feature allows Google to summarize content while excluding creators from traffic. The decentralization of content creators makes them virtually powerless to collectively oppose Google's decisions; without a unified voice, individual websites lack bargaining power.
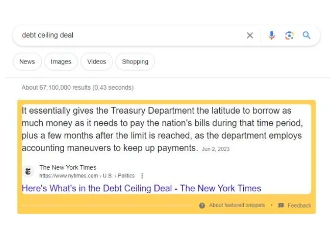
Figure 25: Example of the Featured Snippets feature
Google has further experimented by providing a list of sources for user query answers. The example below includes sources from websites such as The New York Times, Wikipedia, and MLB.com. Since Google directly provides the answers, these websites do not receive as much traffic.
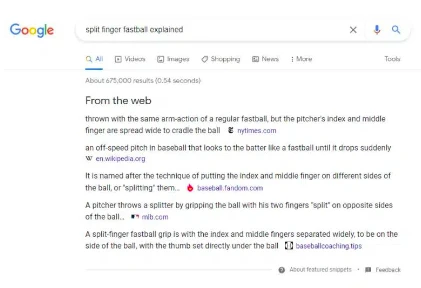
Figure 26: Example of the "From the web" feature
3.3.2 OpenAI's Monopoly Issue
Google's introduction of the "Featured Snippets" feature represents a concerning trend—reducing recognition for original content creators. ChatGPT logically extends this concept, acting as an all-knowing information agent with no links or citations to the original material.
Language models like ChatGPT can answer almost any question by summarizing content gathered from the internet, but they cannot guide users to the original publishers. Instead, the model accumulates knowledge from copyrighted works into a single interface controlled entirely by OpenAI.
The success of these models relies on the vast data that makes up the internet, while content creators' significant contributions to model training go unrewarded. Some larger publishers manage to strike deals with companies like OpenAI, but this is impractical for smaller content creators. Some publishers have decided to outright block AI models from searching their content, but this cannot be guaranteed for closed-source models.
AI companies attempt to justify their uncompensated actions, claiming that AI systems simply learn from content—similar to how humans understand the world through reading—and do not infringe on content creators when producing content. However, this claim is debatable, as ChatGPT can verbatim replicate entire articles from The New York Times. Midjourney and DALL-E can also generate copyrighted content.
The impact is evident—big tech companies continue to consolidate power, while the influence of insignificant content creators diminishes. This asymmetric relationship has led to lawsuits against Google, and this relationship will only become more extreme. Established publishers like The New York Times have taken legal action, and a range of content creators, from digital artists to coders, have initiated class-action lawsuits.
One proposed solution is "Retrieval-Augmented Generation" (RAG), which allows language models to provide sources for their answers. However, this presents the same problem as "Featured Snippets"—it does not give users any reason to visit the original website. Worse still, tech giants can hypocritically use RAG as legal cover while still depriving creators of traffic and ad revenue.
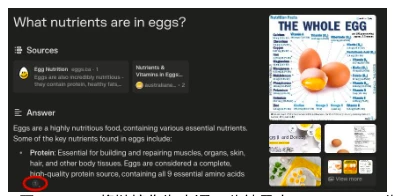
Figure 27: RAG includes links as sources. This result was generated by Per-plexity AI
3.3.3 Potential Solutions in the Crypto Field
With the emergence of "information agents" like ChatGPT, big tech companies seem poised to repeat history, monopolizing AI generation, despite relying on unacknowledged creator content. However, AI is now disrupting the market, giving us the opportunity to redistribute power and establish a fairer system to compensate creators. At the beginning of this century, policymakers missed the opportunity to establish a fair model, leading to today's allocation system—a system monopolized by Google. The rise of AI is a crossroads; do we correct past mistakes or allow history to repeat itself, giving OpenAI and other tech giants unilateral control?
To incentivize the long-term production of quality content, we must explore ways to continue providing fair compensation for creators. As Chris Dixon said, cryptocurrencies provide a solution through blockchain, acting as a collective bargaining machine to address similar large-scale economic coordination problems, especially in the current asymmetric power situation. Their governance can be jointly managed by creators and AI providers.
In the realm of AI, creators can leverage the power of blockchain to write terms of use and regulations related to restrictions enforced by software. For example, by setting conditions for commercial applications like model training. Then, smart contracts will automatically execute ownership systems, distributing a portion of the income generated by AI systems to contributors. (In the absence of smart contracts) Even if current AI companies want to compensate creators, it is impractical due to the large number of contributors.
The composability of blockchain will reduce reliance on any single model, leading to a more open AI market. This competition will bring more friendly profit sharing for creators. Faced with unified terms enforced by fair agreements, AI companies will either accept collective agreements set by creators or have to give up; tech giants will no longer be able to exert unilateral influence over individuals.
The centralized control of information agents like ChatGPT also raises concerns about embedded advertising. While Google explicitly separates ads at the top of search results, AI agents can seamlessly integrate paid recommendations into their responses. In contrast, solutions based on the crypto field allow for auditing of AI agents.
3.3.4 Artificial Intelligence Agents and Amazon
The natural extension of language models like ChatGPT is the transition from information agents to action agents, which can act on behalf of users, from information agents to action agents (referred to as "agents"). These systems can not only find the best Bluetooth speakers for you but also directly order them for delivery. Relying on closed-source agents from companies like OpenAI to perform these tasks will give them immense power beyond the content creation market, potentially dominating the $6.3 trillion e-commerce market and other industries. OpenAI will not only become the next Google but also the next Amazon.
If a few large tech companies have the most powerful and widely used AI agents, they will have a significant influence on consumers and various industries. These agents will mediate our increasingly digital lives—shopping, travel, and finance. Without AI agents, we would have to rely on companies like OpenAI or Google. Their closed-source agents would become gatekeepers of the online world, controlling our access to essential services and information, and they could modify agent behavior without any accountability.
This concentration of proprietary AI power is similar to the rise of large tech monopolies like Google and Facebook. However, when AI agents can seamlessly take action across domains, their impact will grow exponentially. This is why decentralized blockchain alternatives are crucial—they introduce competition, user empowerment, and transparency to resist the risk of AI agents being monopolized by large tech companies.
In conclusion, AI models like ChatGPT provide us with information agents that can read content and answer questions on our behalf. This not only disrupts the way we consume information but also challenges Google's business model and the rules on which creators rely for survival. In the face of this disruption, we have the opportunity to build a new internet that more fairly rewards creators for their work and contributions.
Blockchain technology that enables AI agents to take action (such as purchasing goods online) will disrupt e-commerce. Once again, blockchain provides an opportunity to establish a fair internet model. Can we learn from the mistakes of the Google and Amazon era?
3.4 The Crypto Field Will Accelerate the Development of Open-Source AI Technology
3.4.1 What Stage is AI Currently in?
Currently, artificial intelligence has become a primary tool in 21st-century advanced societies. The applications of AI include art, education, finance, politics, programming, and many other areas. With limited prompts, it can generate realistic videos and images in seconds. Programmers have begun using AI to develop efficient and practical code, outsourcing their labor to AI. The line between the real world and science fiction is becoming increasingly blurred with each application of AI in our society.
Therefore, we are likely to face a labor crisis. If we can outsource a large amount of intellectual labor to AI, then from an economic perspective, using AI may soon become more advantageous than using human labor. If human labor is replaced by AI, we will need to adapt to this new state of the labor market. This adaptation will lead to disruption in the way our current economic system operates. This section will discuss the direction of AI development and methods to prevent such crises through solutions using crypto technology.
3.4.2 Why Should We Pay Attention to Open-Source AI?
In general, open-source software is software open for anyone to use, usually with a license that specifies what can and cannot be done with the software. Open-source AI refers to AI software open for anyone to use, with similar restrictions provided through a license. Open-source projects typically take the form of organizations that adopt a collaborative approach to product development. They are community-centered, welcoming code contributions and bug fixes. This section will explain the importance of open-source AI.
Open-sourcing AI technology can create a more competitive AI market. Competition is good because during the product development process, there are various people with different talents and technical levels. Suppose a company with great talent makes a big mistake; a competitive market will encourage people to rectify the mistake, thus limiting the damage caused by the error. Open-source AI lowers the barrier for people to enter the AI market, allowing anyone to use AI software and make contributions. With anyone able to enter the market through open-source AI, it means there are more competitors in the market, making the industry much more competitive.
Open-source AI technology can be used to protect industries from malicious harm. Technology is a powerful tool, but it is neutral in itself. It can be used for the benefit of humanity or to harm humanity, depending on who controls the technology. We would prefer good actors to control this technology, especially to counteract those who use technology to harm humanity. Open-sourcing allows more people and talents to enter the AI industry.
Furthermore, lowering the barrier to entry for the AI industry will unleash talent and skill pools, promoting further industry development. AI can bring progress to humanity. We have outlined its current wide-ranging applications, but it still has immense potential for development, which is beneficial for humanity's progress. Open-source AI technology lowers the barrier for talent to enter the industry, accelerating the development of AI. More talent means we can create better AI, which will have a wider application in society. Open-source AI provides us with a tool to access the source of talent and capabilities for developing this technology.
Open-source AI technology provides developers with the freedom to specify and customize AI according to their needs. One characteristic of AI is its ability to be customized for specific purposes. Customized AI can meet specific needs and requirements, greatly improving the quality of products. Due to the current closed nature of the AI industry, developers' ability to customize AI software is often limited. Allowing developers the freedom to customize will enable them to achieve the best results with their products. This freedom will bring about a better market and better products.
In summary, the "technology-capital" is a perpetually growing machine. Capital obtained through the market drives technological development, and the market creates more capital through technological development, forming a virtuous cycle. Open-source AI provides a space for competition, low barriers, freedom, and collaboration, which will promote innovation and the spread of AI technology, stimulating economic growth and more markets (demand). This is crucial for the industry's development capabilities and the benefit of humanity.
3.4.3 OpenAI and Open-Source AI
In the AI industry, the leading company is OpenAI. Since the release of ChatGPT in 2022, OpenAI has been leading the AI industry in profits and knowledge. With the support of Microsoft and major tech companies, they have a deep foundation in the AI market. At present, it seems like a tough battle to bring open-source AI to the same level as OpenAI and compete with it. However, we have ample reason to believe that open-source AI has the potential to challenge and surpass OpenAI in the market.
The open-sourcing of AI can help circumvent the fears of government regulation in the AI industry. Currently, governments and regulatory bodies worldwide are vying to regulate and restrict the emerging AI industry. This regulation targets traditional AI used by OpenAI, which is AI managed and preserved by a single organization. This regulation will limit the development of the AI industry. However, open-source AI projects have the advantage of being managerless and decentralized, making it difficult for governments to regulate them. This provides an advantage for open-source AI projects, as they are less likely to be restricted by regulations in the future, unlike OpenAI.
Furthermore, open-source AI technology or projects can benefit from OpenAI, while OpenAI cannot benefit from them. OpenAI's primary goal is to maximize its own interests, which means they keep a large number of models and data confidential to prevent competitors from using them for their own gain. Open-source AI can use licenses to prevent OpenAI from benefiting from less regulated development. OpenAI will find itself isolated in the market, as they are just one company, while there are many organizations using open-source AI technology or projects. This means that open-source companies can benefit from OpenAI's rich data and knowledge by restricting OpenAI's access. However, new licenses may be needed to ultimately provide OpenAI with this access.
Finally, compared to OpenAI, open-source AI is more likely to attract ideologically driven individuals who are passionate about improving AI. This is because of its low barrier to entry. However, some may argue that this could lead to coordination and product development challenges. However, these projects do not require a large number of people. Linux's Linus Torvalds is an example of a single individual making continuous contributions to a project and having a huge impact. OpenAI has a high barrier to entry, making it difficult to attract passionate individuals.
Although it may seem that OpenAI has firmly established control over the AI industry, open-source AI technology or projects can challenge this control through several avenues. Their flexibility, accessibility, and community-centered, non-profit-driven approach to AI mean they have powerful tools to isolate themselves in a constantly evolving and dynamic market and defeat OpenAI. They have the potential to surpass OpenAI.
3.4.4 Issues with Open-Source AI Technology
However, open-source AI technology must overcome some obstacles to compete with large tech companies and OpenAI. These obstacles can be divided into three categories. Firstly, the field lacks talent. Secondly, these projects and technologies lack the computational power required for practical work. Thirdly, there is a lack of data for AI self-training and development. This section will specifically address these three issues.
Any organization needs talent to provide innovative ideas and work to develop products. A major problem faced by open-source AI projects is that there is no profit or monetary incentive for working in these communities. Most AI engineers have to make a choice when deciding to work in this field: either work for high-paying jobs at large tech companies or take the risk of entrepreneurship. The safe choice, which is the choice for most people, is to work at large tech companies and make a living there. The best talent goes to OpenAI, rather than working in the open-source AI community without monetary incentives. Therefore, this field cannot attract the best talent and cannot develop innovative products to challenge large tech companies.
Another issue is that open-source AI projects lack the necessary computational power to reach the scale that OpenAI can achieve. Larger-scale AI requires more GPUs to expand its operations. GPUs are expensive, and in reality, only Nvidia produces them. These projects and technologies lack funding, making it difficult to provide enough computational power for AI models, thus competing with OpenAI's ChatGPT. Even Linux, which has high-quality standards in software engineering, is limited by the scale of its programs. They lack the ability to access supercomputers at will, making it difficult to compete with OpenAI, which has this privilege.
AI models require data for training. Although large tech companies like Meta and OpenAI claim to be "open" or "open-source," the data they use to train AI is private and only open to themselves. They only publish the completed AI models, such as ChatGPT. This data comes from the massive user base of Meta and OpenAI, and is of high quality and quantity. The disadvantage of open-source AI projects is that they cannot access large amounts of high-quality data, and therefore cannot use the best and most data to train AI models, thus unable to compete with Meta or OpenAI. Therefore, they cannot develop products that can compete with those of OpenAI or Meta.
These open-source AI technologies and projects need solutions to overcome these three major issues, which hinder their potential to challenge the control of large tech companies over the AI industry. We believe that crypto technology can address these issues.
3.4.5 Open-Source AI Solutions in the Crypto Field
We believe that crypto technology can address all three issues outlined in the previous section. This section will specifically address solutions for each specific problem.
Firstly, cryptocurrencies can help address the talent issue by creating an income/reward system in the AI field. Cryptocurrencies can help these open-source projects operate by providing intrinsic incentives for contributing to projects. An example of this is AGI Guild, a group of ideologically driven open-source developers who have created a license that rewards developers for contributing to open-source projects.
The license is managed by AGI tokens. Companies with a value of over $1 million must obtain AGI tokens to use the license. The tokens are then distributed to contributors to open-source AI projects. This serves as both a monetary reward for developers and gives value to the tokens themselves, encouraging more contributions. Additionally, there is a voting system for members to collectively decide the direction of the project, encouraging meritocracy and democracy in the open-source AI field, while also making money from it.
With monetary incentives in place, present and future talent will not need to see their path as either safely choosing Meta or taking a risky gamble in entrepreneurship, but will see a third path where they can make money while developing AI without the proprietary restrictions of large tech companies. Talent will be attracted to open-source AI projects, seeing them as viable competitors against large tech companies.
Secondly, crypto technology can lower the barrier to access servers to address the computational issue. In the past, cloud providers may have refused developers access to their servers to develop products. With crypto technology, this is now permissionless, meaning anyone can access the computational power they need for their projects. This means that developers using open-source AI and crypto technology can now freely access as much computational resources as they need.
Crypto technology also provides developers and communities with the ability to negotiate with cloud providers. In the recent past, cloud providers could raise usage prices because open-source AI developers needed their servers to run their programs. Now, with crypto technology, we can decentralize this system, starting to challenge the prices of cloud providers and opening the doors to more people who want to develop open-source AI.
Now, the community has the means and the ability to challenge AWS and other cloud computing companies to lower prices, thus improving the quality of products and work.
Finally, crypto technology can help address the data issue by rewarding users who generate data for open-source AI projects. An example of this is Grass, which has a browser plugin that generates tokens as users browse the internet. This reward system means that over time, as more data is provided by crypto applications, these open-source project teams will be able to access more and more data. This is done in a decentralized manner, meaning we will not fall into the problem of regulatory bodies or large tech companies discovering this and taking measures to block it, such as banning IP addresses. This method cannot effectively prevent it, as many people are using this plugin, and banning one person has almost no impact on others accessing this data. This means that open-source AI developers can access data as good as that of large companies. This will undoubtedly improve the training level of AI models. Even for data that needs to be kept confidential, crypto technology can fully protect privacy, and with the consent of the data owner, crypto technology can also enable access to it for better use of AI models.
In conclusion, we have found that crypto technology can meet the data sensitivity requirements when scraping data, while also providing better training data for open-source AI programs.
Our ideal pursuit is for open-source AI systems to defeat software-based proprietary systems.
4. Opportunities for Builders
During the process of writing this report, we received many suggestions from the community regarding potential builders in the AI x Crypto field. We have compiled a list of suggestions outlining the ideas that interest us and hope to assist you in your work. We have listed each issue and its potential solutions. If you are interested in these ideas, please contact us.
4.1 Selected List of Suggested Ideas
4.1.1 AI DAO
Issue: DAOs rely on active community voting for thoughtful consideration of proposals. Each proposal requires manual voting, which can slow down progress and lead to DAO fatigue.
Potential Solution: Provide an AI agent for DAO members to automatically vote on proposals based on their values, using a Bayesian approach to consider uncertainty in decision-making. If uncertainty exceeds a threshold, the DAO members are prompted to review the proposal and manually vote.
The process of participation in creating these AI agents needs to be simplified for user adoption. By combining each user's on-chain and off-chain data, user preferences can be defined without excessive manual operations. For example, DAO Base is researching solutions around the concept of "your past actions define you."
One possible approach is to query LLM on-chain, passing in proposals and prompts from DAO members to adjust based on their requirements.

List 1: This is a simple example, but a tool is needed to facilitate users specifying their requirements and automate voting.
Refer to the demo code here.
4.1.2 Verifiable Model Training
Issue: Training models compress training data, so even if model weights are obtained, it may not be known on what data the model was trained. This presents challenges not present in traditional software:
- Complicating copyright issues
- More difficult fair compensation for data owners
- Difficulty in knowing who trained each part of a model in cases of multi-party training, such as in Model Zoo
- Easier introduction of biases in models
Potential Solution: Make the training process itself verifiable. Develop tools to decompose how a model was trained and check if it contains a given dataset. Several methods can be explored:
Integrate encrypted metadata into the training process itself. For example, Pytorch NFT Callback hashes the current network weights, some metadata (data, accuracy, etc.), and your Ethereum address every N epochs to prove who trained the model. Note: This method introduces performance overhead to model training.
Another solution is to train models on a specially built decentralized network. There are also solutions based on traditional consensus mechanisms (such as BFT). However, BFT requires not only the reliability and honesty of 2/3 nodes. The minimum number of nodes to achieve BFT consensus is 𝑁 = 3𝑓 + 1, where 𝑓 gives the number of (i) failed or (ii) malicious nodes. This introduces a large amount of redundant work (linear relationship with 𝑁, for example, 60x when 𝑁 = 60). An example of this approach is "Training Proofs." We suggest adopting a decentralized network built from scratch specifically for model training.
4.1.3 Other Approaches to Achieving Verifiable Inference
Issue: Verifiable ML research is mostly focused on zero-knowledge machine learning (zkML). However, the performance overhead of zkML is currently as high as 1000x, and it cannot run large models.
Potential Solution: Several methods are currently being explored. This is a relatively new field, and different approaches have the opportunity to make different trade-offs.
Ora is attempting to use opML. This method involves optimistically inferring the model by a single party, putting the result on-chain, and incentivizing validators to challenge incorrect results by paying them tokens.
Aizel is building a solution based on multi-party computation (MPC) and trusted execution environments (TEE). Their goal is to achieve verifiable inference at the same cost as regular inference.
EZKL is splitting and parallelizing zk proofs, making it feasible for large models.
4.1.4 DePin 2.0
Issue: With the intersection of decentralized personal internet (DePin) technology and robot technology, integrating dynamic autonomous systems such as robot swarms presents unique challenges. Unlike static sensing devices like solar panels, robot swarms have the ability to act independently, which introduces vulnerability. Specifically, a failure or Byzantine (malicious) robot in a robot swarm can compromise the integrity of the entire system. Given the irreversibility of robot actions, ensuring the reliability and security of these robot swarms is crucial.
Potential Solution: One potential solution is to use zero-knowledge proofs (ZKPs) to authenticate the execution of specific swarm strategies without revealing the details of the strategies. This encryption technology can verify whether the swarm is operating according to a predefined algorithm based on hardware authentication data collected from the swarm and encrypted signature information from external sensors. By incorporating ZKPs, we can establish a trustless environment for real-time verification of robot swarm behavior, reducing the risk of Byzantine robots. This approach not only enhances the security and reliability of robot swarms but also aligns with the decentralized nature of DePin, ensuring transparency and trust without revealing sensitive operational details.
4.1.5 Transparent LLM Drift
Issue: Large Language Models (LLMs) are at the core of many applications, but they suffer from unpredictability and performance degradation over time. Traditional benchmarks, such as HuggingFace's Open LLM Leaderboard, are criticized for their gamification and lack of historical data, making it difficult to track and understand the performance changes of LLMs.
Potential Solution: Combine automated benchmarks with community voting, using tokens as incentives for participation. Results are stored on the blockchain to ensure transparency and immutability. This approach aims to provide a reliable, transparent historical performance of LLMs, addressing the issues of unpredictability and performance degradation.
4.1.6 Truth Market
Issue: As AI-generated content becomes more prevalent, distinguishing the truthfulness of online information becomes increasingly complex. This ambiguity challenges traditional verification methods, making digital content difficult to maintain credibility.
Potential Solution: One idea worth considering is to expand the concept of proof markets to address the challenge of verifying truth in a more nuanced and ambiguous environment. By introducing economic incentive mechanisms (similar to existing incentive mechanisms in proof markets), the system can encourage the discovery and verification of truth. Bittensor's "Yuma Consensus" would be an ideal venue for the "truth market" as it can effectively address the issue of ambiguity. This approach does not prescribe specific methods but creates a framework where various strategies for identifying truth are economically incentivized, forming an ecosystem where truth holds practical value.
4.1.7 AI Solves the Unreliability Problem of Prediction Markets
Issue: Prediction markets face the challenge that participants often have differing interpretations of the events being bet on, including what constitutes evidence of winning or losing, leading to confusion and disputes.
Potential Solution: Input information into a pre-agreed artificial intelligence model on a pre-agreed date to address the issues of prediction markets. The information comes from pre-agreed data sources (leveraging the previous "truth market" idea).
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







