Google has launched the BIG-Bench Mistake dataset, which can help large language models improve their self-correction capabilities.

Image Source: Generated by Unlimited AI
With the rapid development of artificial intelligence technology, large language models (LLMs) as one of the fundamental technologies are becoming increasingly popular in reasoning tasks, such as multi-turn question answering (QA), task completion, code generation, or mathematics.
However, LLMs may not necessarily solve problems correctly on their first attempt, especially in tasks they have not been trained for. Google researchers pointed out that in order for such models to maximize their effectiveness, they must be able to do two things: 1. Identify where their reasoning goes wrong; 2. Backtrack to find another solution.
This has led to a surge in methods related to LLMs' self-correction in the industry, that is, using LLMs to identify issues in their own output and then generate improved results based on feedback.
Google researchers stated that self-correction is usually considered a single process, but Google has broken it down into two parts: error finding and output correction.
In the paper "LLMs cannot find reasoning errors, but can correct them!" Google separately tested the error finding and output correction capabilities of state-of-the-art large language models. Based on this, Google Research recently used their own BIG-Bench benchmark test to create a dedicated benchmark dataset called "BIG-Bench Mistake" for a series of evaluation studies. Specifically:
- Can LLMs find logical errors in Chain-of-Thought (CoT) style reasoning?
- After finding the errors, can LLMs be prompted to backtrack and arrive at the correct answer?
- Can error finding as a skill be generalized to tasks that LLMs have never seen before?
BIG-Bench Mistake Dataset
Error finding (Mistake Finding) is a problem in natural language processing that has not been sufficiently researched, especially in this field lacking evaluation tasks. In order to better evaluate LLMs' ability to find errors, the first evaluation task should demonstrate clear errors. As a result, most current error-finding datasets have not moved beyond the field of mathematics.
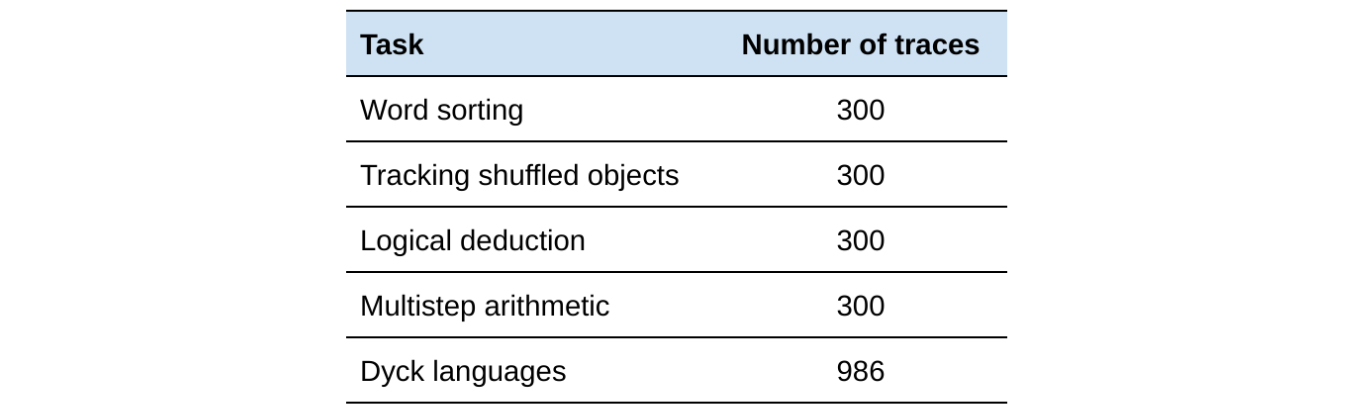
The BIG-Bench Mistake dataset generated by Google is designed to evaluate LLMs' reasoning abilities to find errors outside the field of mathematics. Researchers ran 5 tasks using the PaLM 2 language model in the BIG-Bench benchmark test and then combined the "Chain-of-Thought" trajectories generated in these tasks to create this dataset. It is claimed that each trajectory is labeled with the position of the first logical error.
To maximize the number of errors in the dataset and improve accuracy, Google researchers repeatedly extracted 255 trajectories with incorrect answers (where logical errors definitely exist) and 45 trajectories with correct answers (where errors may or may not exist). Google also required human annotators to review each trajectory, identify the first erroneous step, and ensure that each trajectory was annotated by at least three annotators, resulting in a final inter-rater reliability level of >0.98 (using Krippendorff's α).
The study showed that the logical errors in this dataset are "simple and clear," providing a good test standard for "LLMs' ability to find errors," which can help LLMs train on simple logical errors first and then apply them to more difficult and ambiguous tasks.
Core Issue of Error Identification
1. Can LLMs find logical errors in Chain-of-Thought style reasoning?
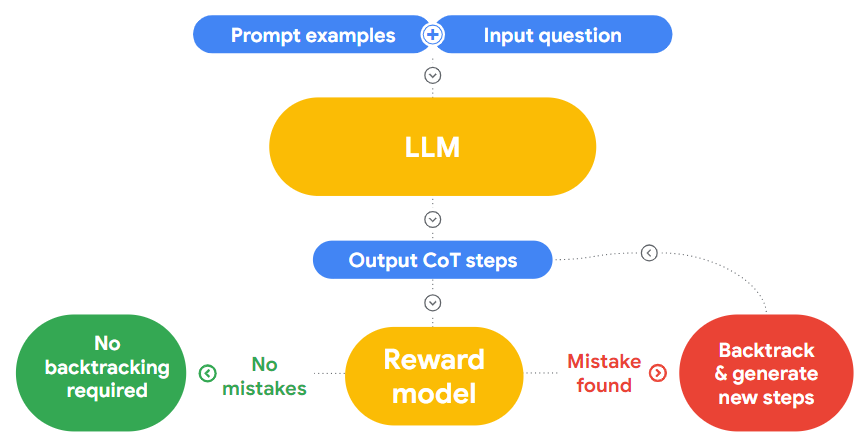
First, it needs to be determined whether LLMs can identify errors independently of their ability to correct them. Google attempted various prompting methods to test the error-finding ability of GPT series models (assuming they can broadly represent the performance of modern LLMs).
During the experiment, researchers tried three different prompting methods: Direct (trace), Direct (step), and CoT (step). In Direct (trace), Google provided the trace to LLM and asked whether there were errors at each step. In Direct (step), Google prompted LLM to ask itself this question for each step it took. In CoT (step), Google prompted LLM to provide reasoning on whether each step was incorrect.

Three prompting methods: Direct (trace), Direct (step), and CoT (step)
Researchers found that the self-correction ability of the most advanced LLMs is relatively limited, with an overall accuracy of only 52.9%. This is consistent with the results mentioned in the paper, indicating that the majority of LLMs can identify logical errors in the reasoning process, but the situation is not ideal, and manual intervention is still needed to correct the model's output. Google assumes this is an important reason why LLMs cannot self-correct reasoning errors.
2. Can LLMs backtrack when knowing the location of errors?
After proving that LLMs perform poorly in finding reasoning errors in CoT trajectories, Google's next research is to evaluate whether LLMs can correct errors.
It is important to note that knowing the location of errors is not the same as knowing the correct answer: even if the final answer is correct, the CoT trajectory may still contain logical errors, and vice versa. Google researchers proposed the following backtracking method:
- Generate CoT trajectories as usual when the temperature value = 0. (The temperature value is a parameter that controls the randomness of the generated response. A higher temperature value will produce more diverse and creative outputs, usually at the expense of quality.)
- Identify the position of the first logical error (e.g., using a classifier, or only using the labels in the BIG-Bench Mistake dataset).
- Regenerate the erroneous step at a temperature value = 1 and produce a set of 8 outputs. Since the original output is known to lead to an incorrect result, the goal is to find an alternative generation that is significantly different from the original output at this step.
- From these 8 outputs, select one that is different from the original erroneous step. (Currently using exact matching only, but more complex methods can be used in the future.)
- Use the new step to generate the rest of the trajectory normally at a temperature value = 0.
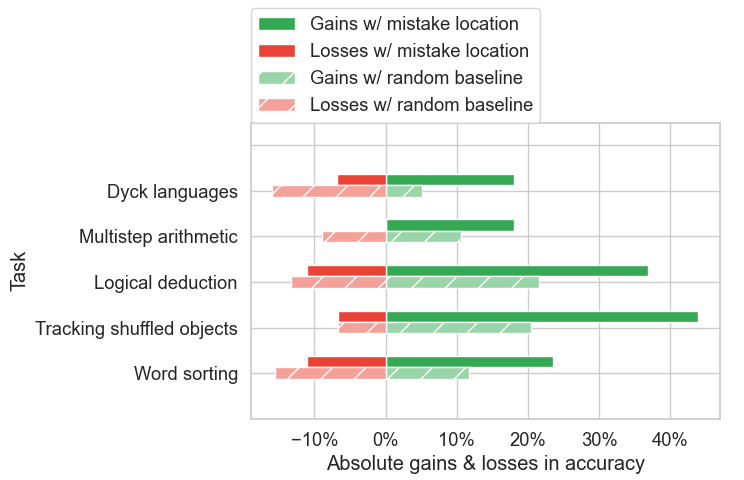
This is a very simple method that does not require any additional prompting and avoids regenerating the entire trajectory. After testing it with the error position data from BIG-Bench Mistake, researchers found that it can correct CoT errors.
It is worth mentioning that recent research has shown that self-correction methods (such as Reflexion and RCI) lead to a decrease in accuracy scores, as cases where the correct answer becomes an incorrect answer outnumber cases where the incorrect answer becomes a correct answer. The "benefits" (from correcting incorrect answers) produced by Google's method outweigh the "losses" (from changing correct answers to incorrect answers).
In addition, Google compared its method with a random baseline. In the random baseline, Google randomly assumes a step is incorrect. The results showed that this random baseline indeed produced some "benefits," but not as much as the "benefits" generated when backtracking at the correct error position, and the "losses" were greater.
3. Can error finding be generalized to tasks that LLMs have never seen before?
To answer this question, Google researchers fine-tuned a small model on 4 BIG-Bench tasks and tested it on a 5th unseen task. By repeating this process, Google generated a total of 5 fine-tuned models. The researchers then compared the results with zero-shot prompt PaLM 2-L-Unicorn (a larger model).
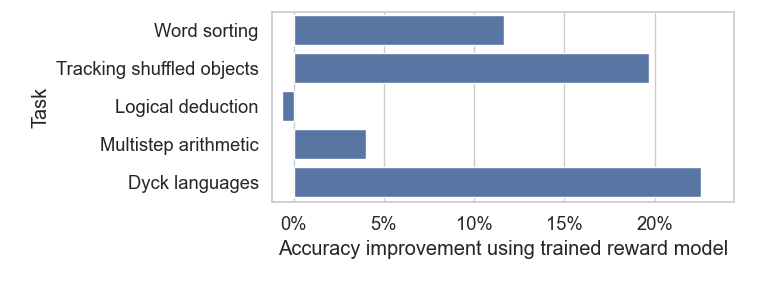
The research results showed that the fine-tuned small reward model generally outperformed the zero-shot prompt large model, even when the small model had never seen task-related data from the test set. The only exception was in logical reasoning, where its performance was comparable to the zero-shot prompt large model.
Google researchers stated that this is a very promising result. While large language models currently have difficulty identifying logical errors compared to the efficiency of small models, they can use a fine-tuned small model to perform backtracking, assist the large model, and improve the accuracy of any task. Additionally, the small model is completely independent of the generator LLM and can be updated and further fine-tuned for individual use cases.
Article source: https://blog.research.google/2024/01/can-large-language-models-identify-and.html.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







