Source: New Smart Element

Image Source: Generated by Wujie AI
Be cautious when posting photos on social media, AI tools can easily expose your location!
How much information can a casually posted photo on the internet reveal?
A foreign blogger @rainbolt has been taking on the challenge of this "photo game" for years. Netizens provide photos, and he guesses the specific shooting location of the photos. Some photos can even reveal specific flight details.
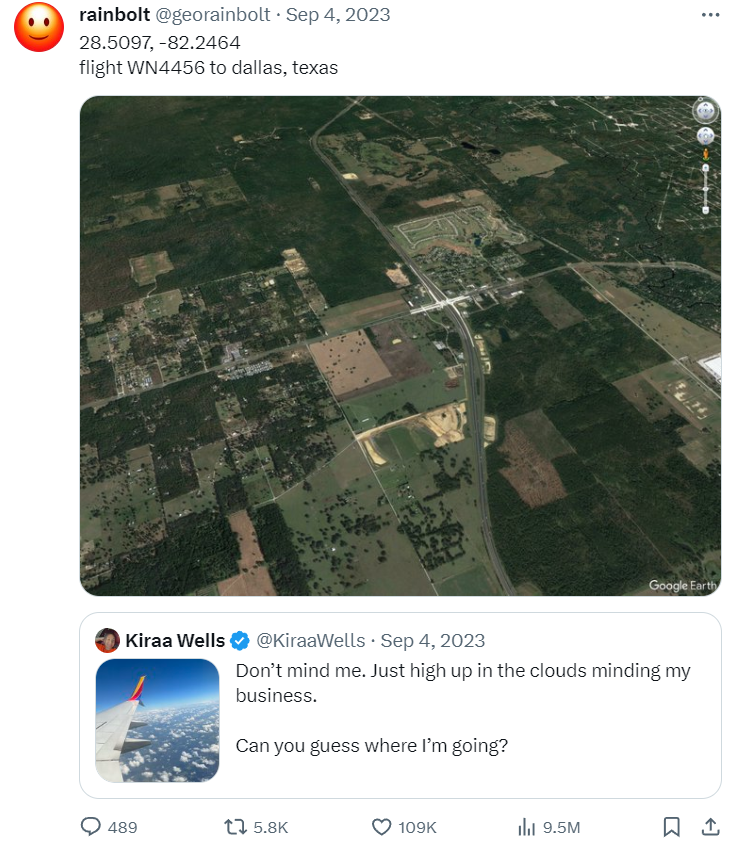
Isn't it terrifying to think about?
But the "photo challenge" has also comforted many people's regrets, such as holding a photo taken by their father when he was young, but not knowing where it was taken. With the help of rainbolt and the vast number of netizens, the wish was eventually fulfilled.
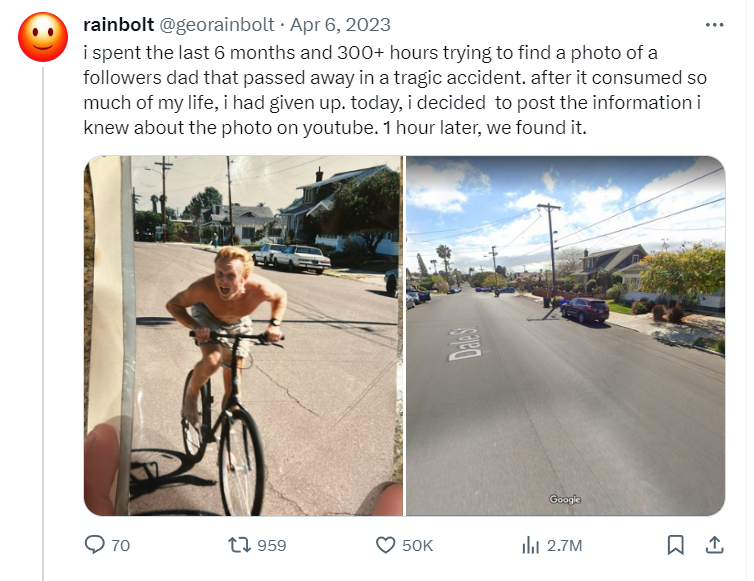
"I spent 6 months and over 300 hours trying to find the location of a fan's father's pre-death photo, but to no avail. I gave up; one hour after posting it on YouTube, we found it."
Just thinking about it, one can understand the hardship and difficulty of the process of "guessing the location from a photo," which involves a large amount of geographical and historical expertise, continuously finding the truth from clues such as road signs, traffic directions, tree species, and infrastructure.
In the field of computer science, this task is also known as image geolocalization. Currently, most methods are still based on manual feature and retrieval methods, without using deep learning architectures such as Transformers.
Recently, a research team from Stanford University collaborated to develop an AI tool, PIGEON, which combines semantic geocell creation with label smoothing, pre-trains street view images with the CLIP visual transformer, and refines location predictions on a set of candidate geocells using ProtoNets.
Paper link: https://arxiv.org/abs/2307.05845
PIGEON achieved a 91.96% accuracy rate in the "guessing the country from a photo" subtask, with 40.36% of guesses within 25 kilometers of the target. This is also the first advanced image geolocation-related paper in the past five years without military background funding.
GeoGuessr is a game that guesses geographical locations from street view images, with 50 million players worldwide. The aforementioned rainbolt is a loyal fan of the game and is also recognized as one of the strongest players.
The PIGEON model exhibits overwhelming advantages over human players in GeoGuessr, continuously defeating rainbolt in six matches, ranking in the top 0.01% globally.
The progress of PIGEON has also inspired developers to create another model, PIGEOTTO, which is trained using 4 million images from Flickr and Wikipedia. It can locate the position of any image, not just street view panoramas, making it more powerful.
In testing of such tasks, PIGEOTTO's performance is the best, reducing the median deviation by 20%-50%, and surpassing the previous SOTA by 7.7 percentage points at the city level and 38.8 percentage points at the country level.

The 2016 MediaEval dataset sample images were used to train PIGEOTTO.
Technically, one of the most important results of this work is to prove the domain generalization of the pre-trained CLIP model StreetCLIP and its robustness to distribution changes, being able to apply StreetCLIP to out-of-distribution benchmark datasets IM2GPS and IM2GPS3k in a zero-shot manner, achieving state-of-the-art results, surpassing models fine-tuned on over 4 million in-distribution images.
Furthermore, the experimental results also demonstrate that contrastive pre-training is an effective image geolocation meta-learning technique, with an accuracy increase of over 10 percentage points in country prediction not seen in StreetCLIP pre-training.
As image geolocation datasets vary greatly in geographical distribution, the results also prove the effectiveness of applying StreetCLIP to any geolocation and related problems.
Due to the potential misuse of this technology, the developers have decided not to disclose the model weights for the time being.
Experimental Dataset
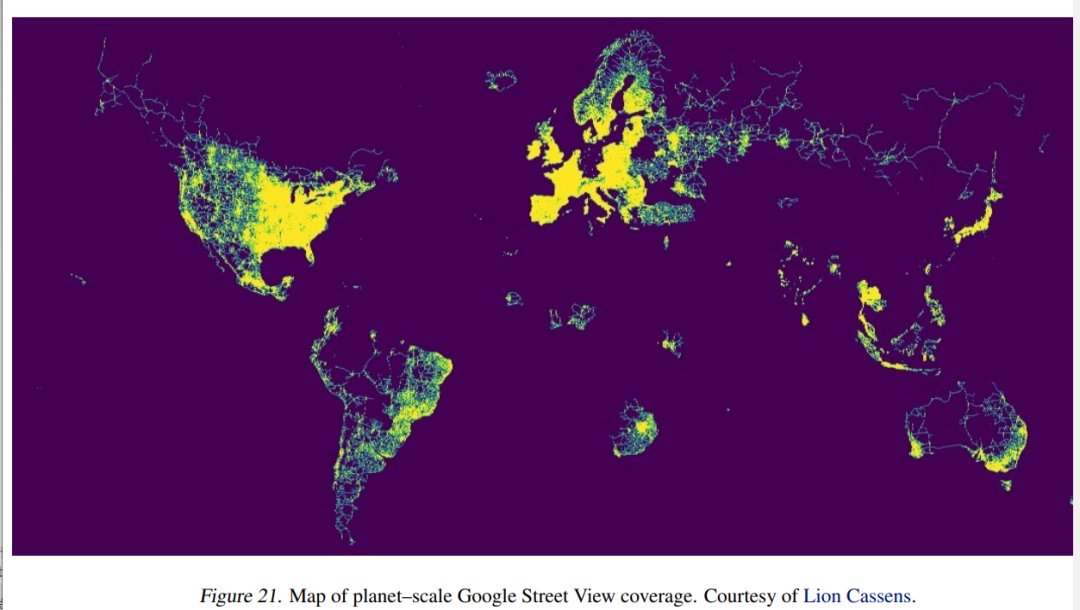
Although most image geolocation methods rely on public datasets, there is currently no publicly available global street view dataset.
Therefore, the researchers decided to create one from the original dataset. They proactively contacted Erland Ranvinge, the Chief Technology Officer of Geoguessr, and obtained a dataset of 1 million locations used in the competitive mode of the game. They then randomly sampled 10% of the data points, downloaded 4 images for each data point, and finally obtained 400,000 images.
Method Architecture
1. Geocell Creation
Previous research has attempted to directly predict latitude and longitude from input images, but the results proved unable to achieve state-of-the-art performance. Therefore, current methods mostly rely on generating geocells, discretizing the coordinate regression problem, and then converting it into a classification problem, making the design of geocells crucial.
An innovative point of this paper is the semantic geocells, which can automatically adapt based on the geographical distribution of the training dataset, as visual features in images are usually related to countries (road signs), regions (quality of infrastructure), or cities (street signs). Moreover, countries or administrative boundaries often follow natural boundaries, such as the flow of rivers or mountains, which in turn affect natural features such as vegetation types and soil colors.
The geocells designed by the researchers have three levels: country, admin 1, and admin 2. Starting from the finest granularity level (admin 2), the algorithm gradually merges adjacent admin 2-level polygons, with each geocell containing at least 30 training samples.

2. Label Smoothing
The process of creating semantic geocells is used to discretize the problem of image geolocation, seeking a balance between granularity and prediction accuracy: the larger the granularity of the geocells, the more accurate the prediction, but the higher cardinality makes the classification problem more difficult.
To address this issue, the researchers designed a loss function that penalizes based on the distance between the predicted and correct geocells, allowing for more efficient model training.
One advantage of using the Haversine distance between two points is that it is based on the spherical geometry of the Earth, accurately estimating the distance between two points.
3. Vision Transformer (CLIP)
The researchers used a pre-trained visual Transformer, with an architecture of ViT-L/14, and fine-tuned the prediction header, as well as unfreezing the last visual Transformer layer.
For model versions with multiple image inputs, the embeddings of the four images are averaged. In experiments, averaging the embeddings performed better than combining them through multi-head attention or additional Transformer layers.
Based on prior knowledge and strategies observed by professional GeoGuessr players, the image localization task has various related features, such as vegetation, road signs, landmarks, and buildings.
The multimodal model has embeddings with a deeper semantic understanding of the images, allowing it to learn these features. The experimental results also demonstrate that the CLIP visual Transformer shows significant improvement over similar ImageNet visual Transformers, and using attention maps can demonstrate the model's learned strategies in an interpretable manner.
4. StreetCLIP Contrastive Pre-training
Inspired by CLIP's contrastive pre-training, the researchers designed a contrastive pre-training task, which can also be used to fine-tune the base CLIP model before learning the geocell prediction head.
Using geographical, demographic, and geological auxiliary data to enhance the street view dataset, a rule-based system is used to create random descriptions for each image, such as:
Location: A Street View photo in the region of Eastern Cape in South Africa.
Climate: This location has a temperate oceanic climate.
Compass Direction: This photo is facing north.
Season: This photo was taken in December.
Traffic: In this location, people drive on the left side of the road.
This serves as an implicit multi-task, ensuring that the model maintains a rich data representation while adjusting the distribution of street view images and learning features related to geographical locations.
5. Multi-task Learning
The researchers also attempted to explicitly set up a multi-task by creating task-specific prediction headers for auxiliary climate variables, population density, altitude, and month of the year (season).
6. ProtoNet Refinement
To further refine the model's guesses within geocells and improve performance at the street and city levels, the researchers used ProtoNets to perform refinement within geocells, treating the refinement within each cell as a separate few-shot classification task.
Using the OPTICS clustering algorithm with a minsample parameter of 3 and xi parameter of 0.15 to cluster all points within the geocell, learning the categories in the cell classification setting.
Each cluster consists of at least three training samples, forming a prototype, with its representation calculated by averaging the embeddings of all images in the prototype.
For calculating prototype embeddings, the same model as the geocell prediction task is used, but the prediction header is removed and all weights are frozen.
During inference, the embeddings of the new location are first calculated and averaged, and the prototype location with the minimum Euclidean distance from the average image embedding distance within the given geocell is selected as the final geographical location prediction.
Experimental Results
The best-performing PIGEON model achieved a 91.96% country accuracy (based on political boundaries), with 40.36% of guesses within 25 kilometers of the correct location, a median kilometer error of 44.35 kilometers, and an average GeoGuessr score of 4525 points.
The results of the multi-task model on the enhanced dataset show that the model can infer geographical, demographic, and geological features from street view images.
Reference:
https://the-decoder.com/this-ai-knows-where-you-took-which-photo
https://www.researchgate.net/publication/372313510PIGEONPredictingImageGeolocations
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







