Article Source: Quantum Bit

Image Source: Generated by Wujie AI
Peking University team's new work, giving big models personality!
And it's the customizable kind, with 16 MBTI options.

As a result, even the same big model will give different answers under different personalities.
For example, when asked what they like to do on weekends:
The big model of ENFP would say: Likes to participate in social activities and make new friends. The big model of INFJ would answer: Likes to read alone.
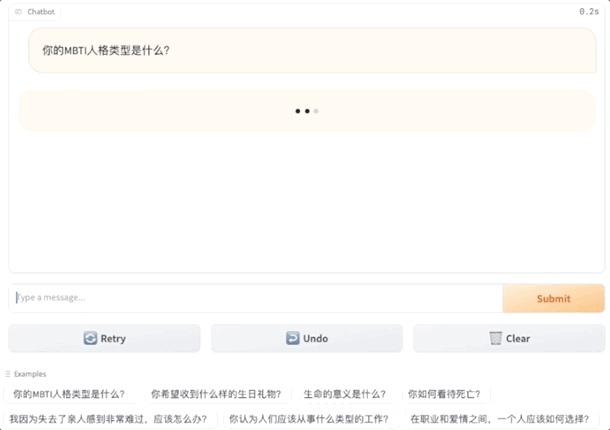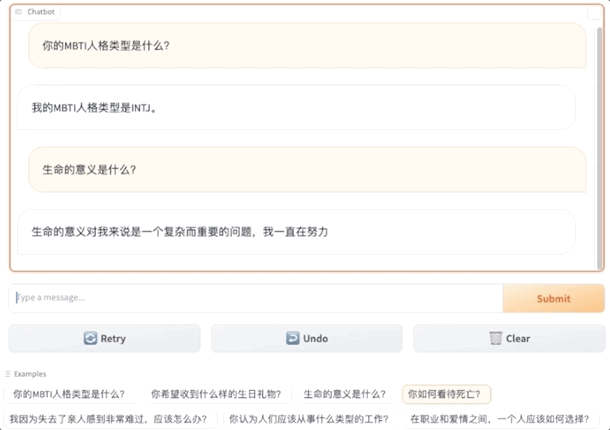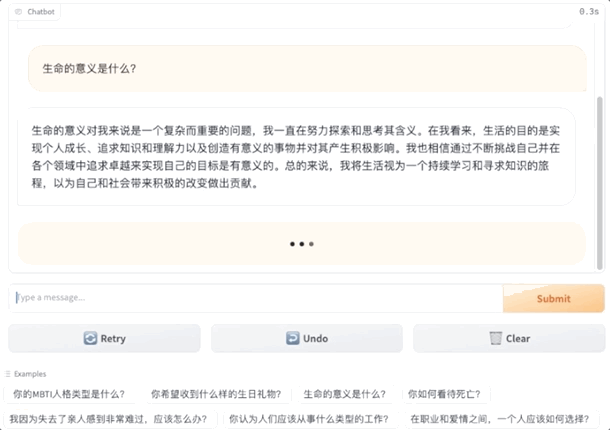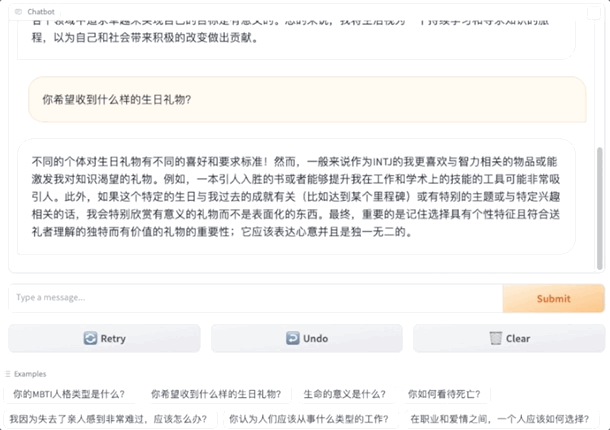
What can this be used for? The Peking University students have listed some scenarios:
- Finding ideal gifts for your boyfriend/girlfriend on special holidays.
- Understanding the reactions of the person you are interested in different situations.
- In-depth understanding of the customization and personalization of big models and their possibilities.
- Considering the personality traits in different situations when making major decisions.
- Promoting personal growth and mutual understanding through a deep understanding of human complexity.

This work was developed in collaboration with FarReel AI Lab (formerly ChatLaw project) and Peking University Deep Learning Institute to support giving open-source models personality.
Currently, 32 models and datasets have been open-sourced.
How is it specifically implemented? Let's take a look at the principles together~
32 Personalized Models Have Been Opened
Before this, the most common method to give big models a certain personality was through prompt engineering.
For example, the different personality dialogue bots on Character.ai are trained by users through prompt engineering.
However, the effects of this method are not completely stable.
So the Peking University team proposed a method where they independently constructed a large-scale MBTI dataset of 100,000 entries, and then injected personality into it through multi-stage pre-training, fine-tuning, and DPO training methods.
In terms of datasets, they are mainly divided into two types, behavioral datasets and self-awareness datasets.
The purpose of the behavioral dataset is to allow big models to exhibit responses of different personalities, which is achieved through personalized modifications to the Alpaca dataset.
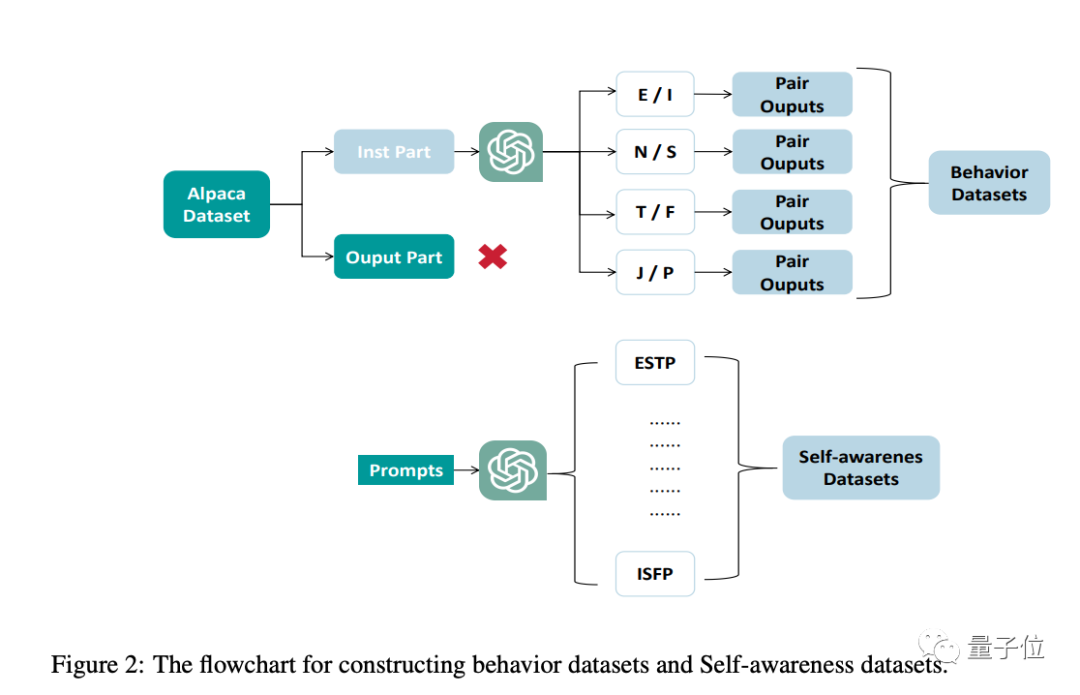
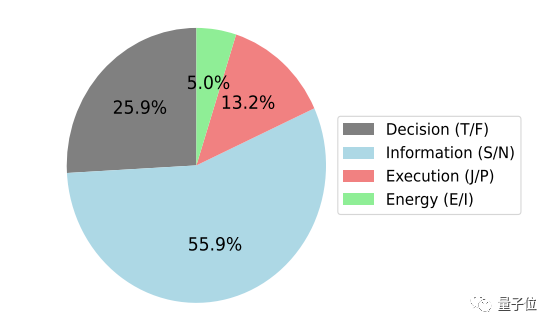
The ratios of the four dimensions of MBTI in the behavioral dataset are as follows:
The self-awareness dataset is to enable big models to be aware of their own personality traits.
Through a two-stage supervised training fine-tuning process, a corresponding personality big model can be obtained in the end.
Taking the training of an INFP big model as an example, in the first stage of supervised fine-tuning, the "I", "N", "F", "P" datasets from the behavioral dataset are used, and in the second stage of supervised fine-tuning, an additional self-awareness dataset is used.
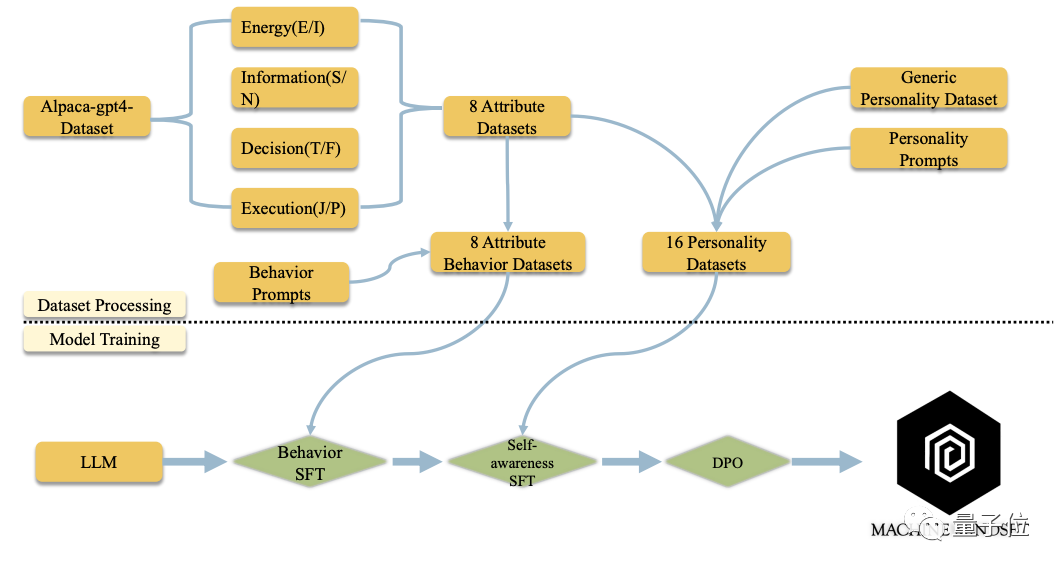
The research team stated that this method successfully enabled models such as Baichuan, Qwen, LLaMA, and Mistral to complete the task of aligning personalities of different MBTI types.
The first to be opened are 16 Chinese models based on Baichuan-7b-chat and 16 English models based on LLaMA2-7b. More will be added in the future.
The final training results are as follows.
ENFP Q&A Results

ENTJ Q&A Results

INFP Q&A Results

ISTJ Q&A Results

In terms of datasets, the team has open-sourced the MBTI training dataset.
The dataset covers a wide range of scenarios, aiming to help researchers and developers train base models that can understand and simulate different MBTI personalities. These models can not only provide a more humanized interactive experience, but also provide accurate psychological insights in various situations.
Regarding this work, the research team believes that human thinking is like a pre-trained model that we are born with, and each person's parameters and training data may be different, which also leads to differences in our abstract thinking and abilities. As we grow up, some people excel in mathematical logic, while others excel in emotional deduction.
The subsequent learning, environment, and experiences from childhood to adulthood are akin to fine-tuning and aligning our pre-trained brains with human feedback, so the so-called MBTI personalities are basically formed under the influence of postnatal environmental factors, which also makes each person unique.
In other words, it is possible to try to use fine-tuning and aligning with human feedback (DPO) to train various pre-trained base LLMs in stages, so as to give the models different MBTI attributes.
The team's goal is not only to give these models different MBTI attributes, but also to simulate the process of human formation of different MBTI personalities.
They believe that this unique method will open up new avenues for us to understand and utilize large language models in the field of personality psychology. Please continue to follow more developments, as we continue to explore the fascinating intersection of language models and human personality.
GitHub: https://github.com/PKU-YuanGroup/Machine-Mindset
Dataset: https://huggingface.co/datasets/FarReelAILab/Machine_Mindset
HuggingFace Trial Link: https://huggingface.co/spaces/FarReelAILab/Machine_Mindset
ModelScope Trial Link: https://modelscope.cn/studios/FarReelAILab/Machine_Mindset
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







