Source: AIGC Open Community

Image Source: Generated by Wujie AI
Large models perform well in generating high-quality images, but often face problems such as video incoherence, image blurring, and dropped frames in video generation tasks.
This is mainly due to the randomness in the generative sampling process, which introduces unpredictable frame jumps in the video sequence. At the same time, existing methods only consider the spatiotemporal consistency of local video segments, failing to ensure the overall coherence of the entire long video.
To address these challenges, researchers at Nanyang Technological University in Singapore have developed a framework called Upscale-A-Video, which can be quickly integrated into large models without the need for any training, providing powerful functions such as video super-resolution, denoising, and restoration.
Paper link: https://arxiv.org/abs/2312.06640
Open-source link: https://github.com/sczhou/Upscale-A-Video
Project link: https://shangchenzhou.com/projects/upscale-a-video/
Upscale-A-Video mainly draws on diffusion methods in image models and designs a framework that can be quickly transferred without the need for large-scale training.
The framework integrates two strategies, local and global, to maintain temporal consistency. The local layer enhances the consistency of the feature extraction network U-Net within short video segments through 3D convolution and temporal attention layers.
The global layer provides reinforcement of coherence across video segments for longer time scales through flow-guided cyclic latent code propagation.
In addition to temporal consistency, Upscale-A-Video can also generate detail textures guided by text prompts, with different prompts producing different styles and qualities.

Temporal U-Net
U-Net plays a decisive role in the quality of video as a feature extraction network. Traditional U-Net, which only considers spatial information, often introduces high-frequency errors when processing videos, manifested as jitter and flicker.
Upscale-A-Video enhances the modeling capability of U-Net in the temporal dimension by inserting 3D convolution blocks and temporal self-attention layers, enabling U-Net to learn the dependencies between frames in video data and achieve consistent super-resolution reconstruction within local sequences.
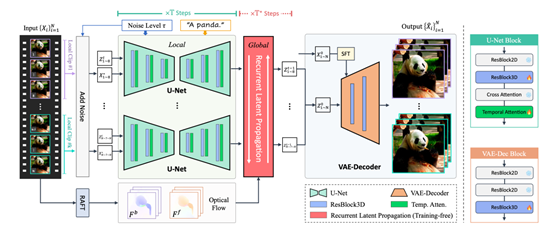
On the other hand, the researchers chose to fix the spatial layer parameters of U-Net and only fine-tune the added temporal layers. The advantage of this strategy is that it avoids large-scale pre-training from scratch, fully utilizing the rich features extracted from image models. It also shortens the network's convergence time, achieving a multiplier effect with half the effort.
Cyclic Latent Code
The scope of the Temporal U-Net is limited to short video segments, making it difficult to constrain the global consistency of longer sequences. However, video jitter and quality fluctuations often occur over a long time range.
To address this issue, Upscale-A-Video has designed a flow-based cyclic latent code propagation module.
This module can infer the latent code information of all frames through forward and backward propagation without increasing the training parameters, effectively expanding the model's perception of the time range.

Specifically, the module uses pre-estimated optical flow fields for frame-by-frame propagation and fusion. It judges the effectiveness of propagation based on the forward-backward consistency error of the optical flow, only selecting regions with errors smaller than a threshold for feature propagation.
Regions beyond the threshold retain the information of the current frame. This hybrid fusion strategy leverages both the long-term information modeled by the optical flow and avoids the accumulation of propagation errors.
Text Prompt Enhanced Guidance
Upscale-A-Video also supports text conditions and control of noise levels, allowing users to guide the model to generate results in different styles and qualities based on actual needs.

Text prompts can guide the model to synthesize more realistic details, such as animal fur and oil painting strokes. Adjusting the noise level also provides flexibility in balancing between restoration and generation: adding less noise is beneficial for fidelity, while a higher noise level prompts the model to supplement richer details.
This controllable generation capability further enhances Upscale-A-Video's robustness in handling complex real-world scenarios.
Experimental Data
Researchers comprehensively verified the performance of Upscale-A-Video from both quantitative and qualitative aspects. It achieved the highest peak signal-to-noise ratio and the lowest perceptual streaming loss on four synthetic low-quality video benchmarks.
On the streaming validation set and AI-generated videos, Upscale-A-Video's non-reference image quality score also ranked first among various methods. This also demonstrates the advantages of Upscale-A-Video in fidelity restoration and perceptual quality.
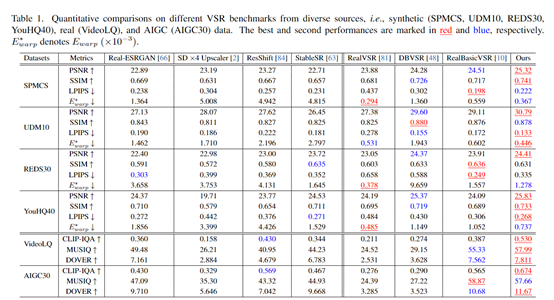
In terms of the comparison of generated effects, the videos reconstructed by Upscale-A-Video exhibit details at a higher actual resolution level, with smoother and more natural motion trajectories, without obvious jitter and cracks. This is thanks to the powerful diffusion prior and spatiotemporal consistency optimization.
In contrast, convolutional neural networks and diffusion methods often result in blurriness, distortion, and other effects, failing to achieve the same level of quality.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








