Source: AIGC Open Community

Image Source: Generated by Wujie AI
As large models like ChatGPT are widely used in practical business, the authenticity, reliability, and security of their output content have become the focus. The academic community uses "attribution" to indicate the tracing and confirmation of content.
Currently, there are two major factions in the field of "attribution" research. One is collaborative attribution, which mainly traces the source of citation data and training data. The other is contributory attribution, which proves the authenticity of the model's output content to reduce illusions.
These two attribution methods are crucial for the application of large models in industries such as law, medicine, and finance, where high accuracy of content is required.
However, these two research methods are conducted separately. Therefore, researchers at Stanford University have proposed a "unified attribution" framework to integrate the two methods.
Paper link: https://arxiv.org/abs/2311.12233

Collaborative Attribution
Collaborative attribution is mainly used to verify whether the output of large models is correct and to compare it with external knowledge. For example, we can trace the source of the large model's output by generating relevant citations or references and verifying its accuracy.
At the same time, relevant knowledge can be retrieved from external knowledge bases and compared and verified with the output of the large model. Specific functions are as follows:
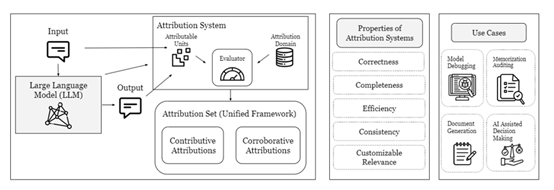
Citation Generation Verification: This function generates citations or references related to the output of the large model. It searches for relevant literature in knowledge bases or literature databases and generates corresponding citations based on the content output by the large model to trace its source and verify its accuracy.
For example, it uses natural language processing and information retrieval techniques to verify keyword matching, text summarization, and more.
Knowledge Retrieval Verification: This function retrieves knowledge related to the output of the large model from external knowledge bases. It can utilize resources such as knowledge graphs, online encyclopedias, or professional databases to retrieve relevant knowledge through keyword matching or semantic similarity calculation.
Then, the retrieved knowledge is compared and verified with the output of the large model to determine its accuracy and consistency.
Fact Verification: This can be achieved by querying external data sources or reliable fact databases. It usually uses natural language processing techniques and data matching algorithms to compare the output of the large model with facts, thereby judging its accuracy and credibility.
Contributory Attribution
The contributory attribution method is mainly used to determine how much the training data influences the output of the large model. For example, small changes can be made to the training data, and then the changes in the output of the large model can be observed to calculate the degree of influence of each training sample on the output of the large model. Specific functions are as follows:
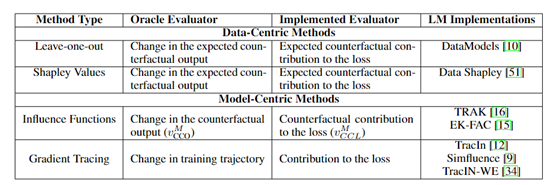
Impact Function Verification: This is achieved by making small changes to the training data and observing the changes in the output of the large model.
Developers can design impact functions to measure the influence of changes on the output of the large model, thereby determining which training data has a significant impact on the output of the large model, thus better understanding the behavior of the model.
Data Simulator Verification: By generating data similar to but different from real data, differences in the output of the large model can be observed, thus inferring the contribution of real data to the output of the large model.
Data simulator verification can use generative adversarial networks (GAN) or other generative models to generate simulated data.
Data Model Verification: By building a data model to represent the learning and prediction process of the large model on the training data. The data model can be a statistical model or a neural network model.
By analyzing the data model, developers can determine which training data is important for the output of the large model and explain the training and optimization process of the model.
Stanford has integrated the main functions of collaborative attribution and contributory attribution into a framework to facilitate developers in various security and content verification of large models.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







