How much does Google's Gemini weigh compared to OpenAI's GPT model? How does it perform? This paper from CMU has figured it out.
Source: Synced
Image Source: Generated by Wujie AI
Recently, Google released a competitor to OpenAI's GPT model called Gemini. This large model has three versions: Ultra (the most powerful), Pro, and Nano. The research team's test results show that the Ultra version outperforms GPT-4 in many tasks, while the Pro version is on par with GPT-3.5.
Although these comparative results are important for research on large language models, the exact evaluation details and model predictions have not been made public, limiting the reproducibility and detection of the test results, making it difficult to further analyze their underlying details.
In order to understand the true capabilities of Gemini, researchers from Carnegie Mellon University and BerriAI conducted an in-depth exploration of the model's language understanding and generation capabilities.
They tested the text understanding and generation capabilities of Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo, and Mixtral on ten datasets. Specifically, they tested the model's ability to answer knowledge-based questions on MMLU, reasoning ability on BigBenchHard, mathematical problem-solving ability on datasets like GSM8K, translation ability on datasets like FLORES, code generation ability on datasets like HumanEval, and the model's ability to act as an instruction-following agent on the WebArena dataset.
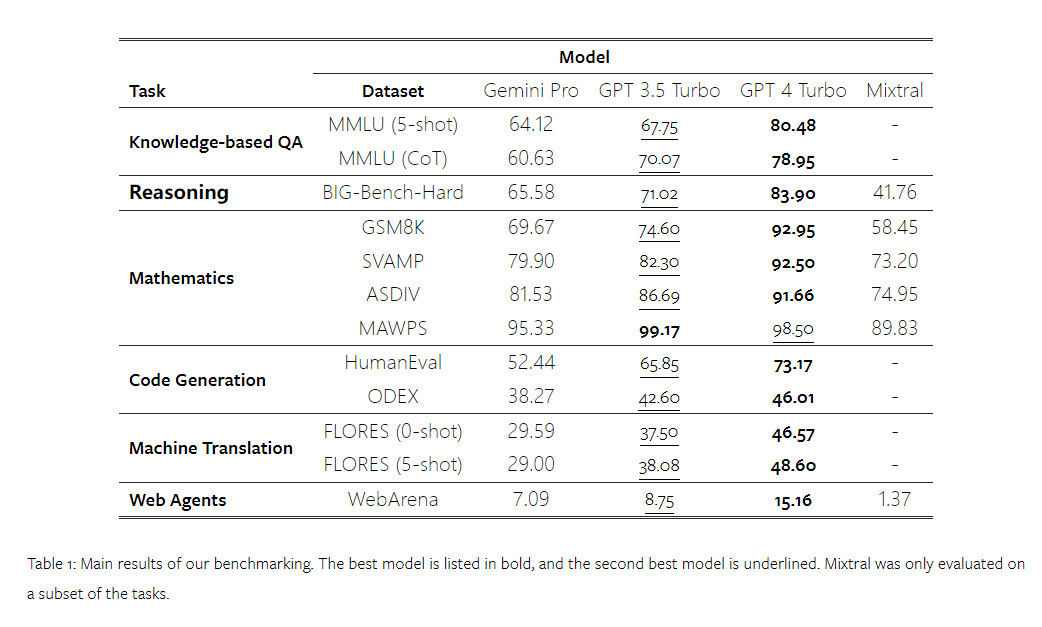
The main results of the comparison are shown in Table 1. Overall, as of the publication date of the paper, Gemini Pro is close to OpenAI GPT 3.5 Turbo in accuracy in all tasks, but still slightly inferior. In addition, they also found that Gemini and GPT perform better than the open-source competitive model Mixtral.
In the paper, the authors provided in-depth descriptions and analyses for each task. All results and reproducible code can be found at: https://github.com/neulab/gemini-benchmark
Paper link: https://arxiv.org/pdf/2312.11444.pdf
Experimental Setup
The authors selected Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo, and Mixtral as the test subjects.
Due to differences in experimental settings in previous evaluations, to ensure fair testing, the authors reran the experiments with completely identical prompts and evaluation protocols. In most evaluations, they used prompts and evaluation criteria from standard resource libraries. These test resources come from datasets included with the model's release and evaluation tools like Eleuther. In some special evaluations, the authors found it necessary to make minor adjustments to standard practices. The adjusted biases have been executed in the corresponding code repository, please refer to the original paper for details.
The goals of this study are as follows:
Provide a third-party objective comparison of the capabilities of OpenAI GPT and Google Gemini models through reproducible code and fully transparent results.
In-depth analysis of the evaluation results to identify which areas the two models excel in.
Knowledge-based QA
The authors selected 57 knowledge-based multiple-choice question-answering tasks from the MMLU dataset, covering various topics such as STEM and humanities and social sciences. MMLU has a total of 14,042 test samples and has been widely used to assess the knowledge capabilities of large language models.
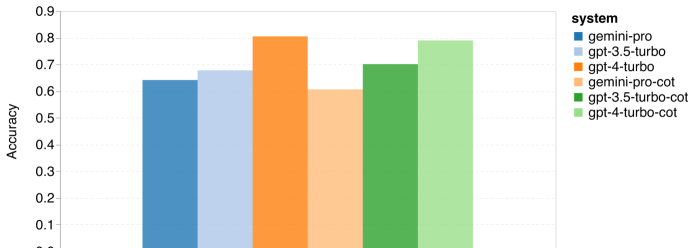
The authors compared and analyzed the overall performance of the four test subjects on MMLU (as shown in the figure below), subtask performance, and the impact of output length on performance.
Figure 1: Overall accuracy of each model on MMLU using 5 sample prompts and chain prompts.
From the figure, it can be seen that Gemini Pro's accuracy is lower than GPT 3.5 Turbo and significantly lower than GPT 4 Turbo. When using chain prompts, the performance of each model is not significantly different. The authors speculate that this is because MMLU mainly includes knowledge-based question-answering tasks, which may not significantly benefit from stronger reasoning-oriented prompts.
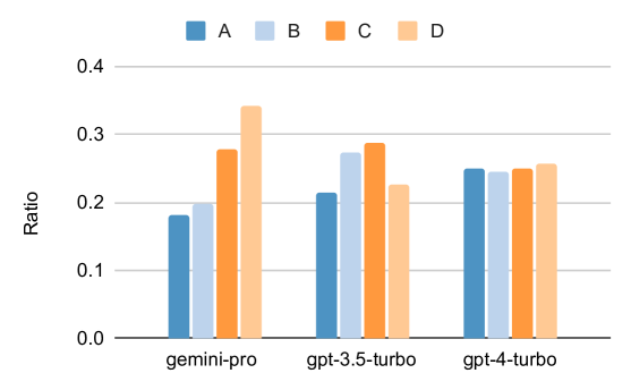
It is worth noting that all questions in MMLU are multiple-choice questions with four potential answers labeled A to D in order. The figure below shows the distribution of each model's choice of each answer option. It can be seen that Gemini's answer distribution is heavily skewed, tending to choose the last option D. This contrasts with the more balanced results given by the various versions of GPT. This may indicate that Gemini has not received a significant amount of instruction adjustment related to multiple-choice questions, resulting in bias in the model's answer ordering.
Figure 2: Proportion of predicted single-choice question answers by the tested models.
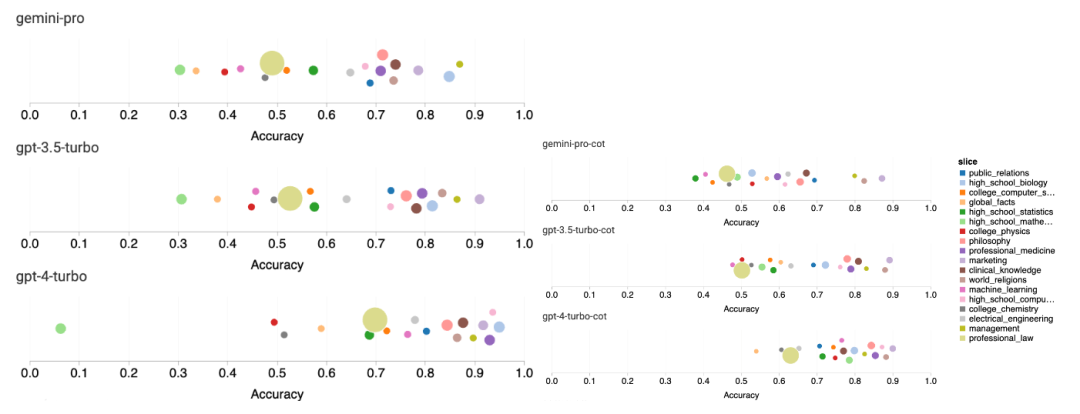
The figure below shows the performance of the tested models on subtasks in the MMLU test set. Compared to GPT 3.5, Gemini Pro performs poorly in most tasks. Chain prompts reduce the variance between subtasks.
Figure 3: Accuracy of each model on each subtask.


The author delves into the strengths and weaknesses of Gemini Pro. From Figure 4, it can be observed that Gemini Pro lags behind GPT 3.5 in tasks related to human gender (social sciences), formal logic (humanities), elementary mathematics (STEM), and professional medicine (professional fields). In the two tasks where Gemini Pro excels, the lead is also very marginal.
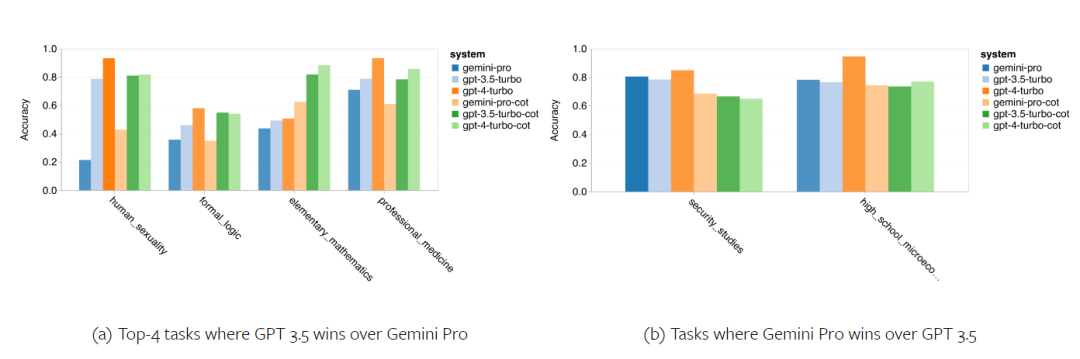
Figure 4: Tasks where Gemini Pro and GPT 3.5 excel on MMLU.
Gemini Pro's underperformance in specific tasks can be attributed to two reasons. Firstly, in some cases, Gemini fails to return answers. While the API response rate exceeds 95% in most MMLU subtasks, it is significantly lower in the ethics task (85%) and human gender task (28%). This suggests that Gemini's lower performance in some tasks may be due to content filtering in the input. Secondly, Gemini Pro's performance in basic mathematical reasoning required for formal logic and elementary math tasks is slightly inferior.
The author also analyzes how the output length in chain prompts affects model performance, as shown in Figure 5. In general, more powerful models tend to engage in more complex reasoning and therefore produce longer answers. Compared to its "competitor," Gemini Pro has a notable advantage: its accuracy is less affected by output length. When the output length exceeds 900, Gemini Pro even outperforms GPT 3.5. However, compared to GPT 4 Turbo, both Gemini Pro and GPT 3.5 Turbo rarely produce long chains of reasoning.
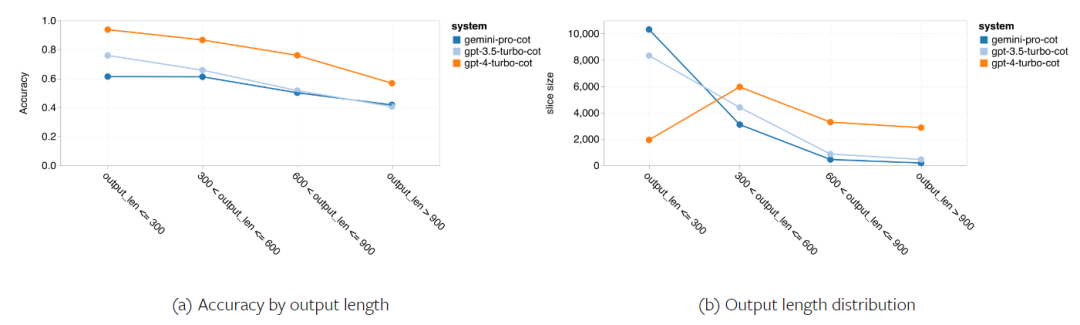
Figure 5: Analysis of model output length on MMLU.
General-purpose Reasoning
In the BIG-Bench Hard test set, the author evaluated the general reasoning abilities of the test subjects. BIG-Bench Hard includes 27 different reasoning tasks, such as arithmetic, symbolic and multilingual reasoning, factual knowledge understanding, etc. Most tasks consist of 250 question-answer pairs, with a few tasks having slightly fewer questions.
The overall accuracy of the tested models is shown in Figure 6. It can be seen that Gemini Pro's accuracy is slightly lower than GPT 3.5 Turbo and significantly lower than GPT 4 Turbo. In comparison, the accuracy of the Mixtral model is much lower.
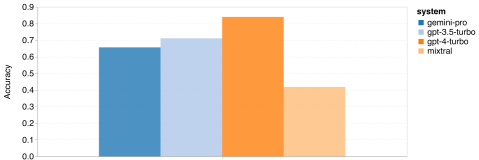
Figure 6: Overall accuracy of the tested models on BIG-Bench-Hard.
The author further explores why Gemini's general reasoning performance is poor overall. Firstly, they checked accuracy based on the length of the questions. As shown in Figure 7, Gemini Pro performs poorly on longer, more complex questions. The GPT models, especially GPT 4 Turbo, show minimal degradation even in very long questions, indicating their strong robustness in understanding longer and more complex queries. The robustness of GPT 3.5 Turbo is average. Mixtral shows stable performance in question length, but with lower overall accuracy.
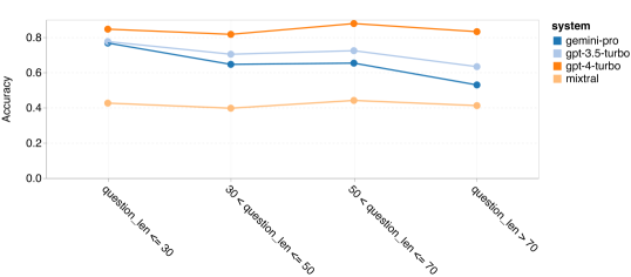
Figure 7: Accuracy of the tested models on BIG-Bench-Hard based on question length.
The author analyzes whether there are differences in accuracy of the tested models in specific tasks within BIG-Bench-Hard. Figure 8 shows the tasks where GPT 3.5 Turbo outperforms Gemini Pro.
In the "tracking transformed object positions" task, Gemini Pro performs particularly poorly. These tasks involve people exchanging items and tracking who owns a certain item, but Gemini Pro often struggles to maintain the correct order.
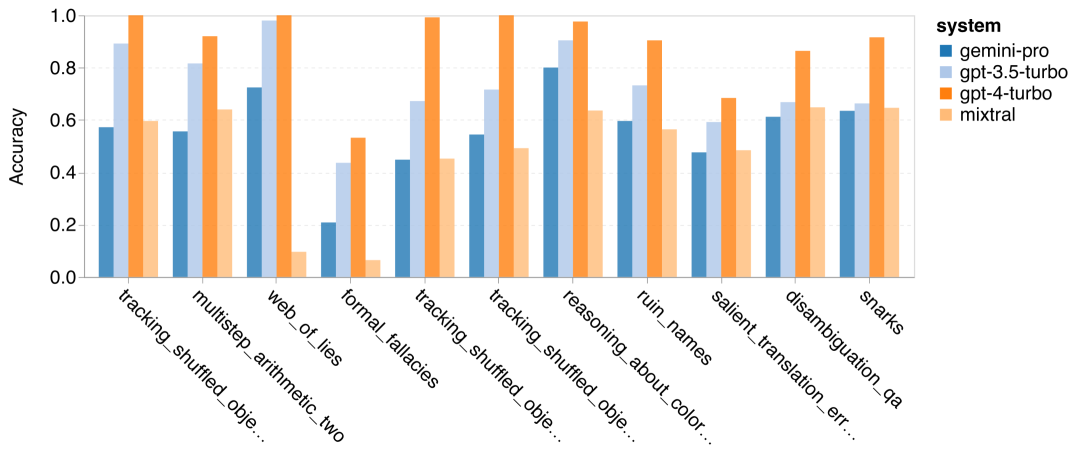
Figure 8: Subtasks of BIG-Bench-Hard where GPT 3.5 Turbo outperforms Gemini Pro.
In tasks requiring multi-step arithmetic problem-solving and finding translation errors, Gemini Pro lags behind Mixtral.
There are also tasks where Gemini Pro outperforms GPT 3.5 Turbo. Figure 9 shows six tasks where Gemini Pro leads GPT 3.5 Turbo with the greatest advantage. These tasks are heterogeneous, including tasks requiring world knowledge (sportsunderstanding), operating symbol stacks (dycklanguages), sorting words in alphabetical order (wordsorting), and parsing tables (penguinsinatable), among others.
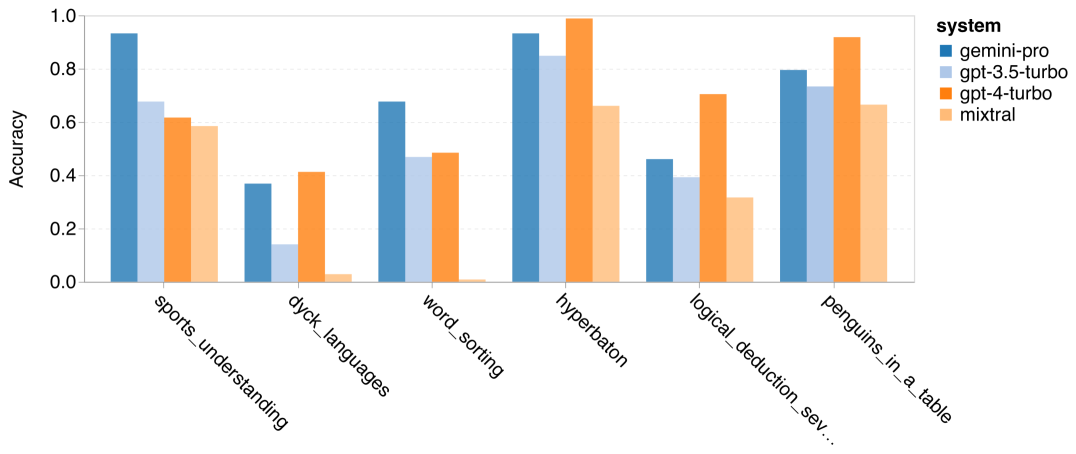
Figure 9: Subtasks of BIG-Bench-Hard where Gemini Pro outperforms GPT 3.5.
The author further analyzes the robustness of the tested models in different answer types, as shown in Figure 10. Gemini Pro performs worst in the "Valid/Invalid" answer type, which belongs to the formalfallacies task. Interestingly, 68.4% of the questions in this task received no response. However, in other answer types (composed of wordsorting and dyck_language tasks), Gemini Pro outperforms all GPT models and Mixtral. Specifically, Gemini Pro excels at rearranging words and generating symbols in the correct order. Additionally, 4.39% of questions in the MCQ answer type were blocked from response by Gemini Pro. The GPT models excel in this aspect, making it challenging for Gemini Pro to compete with them.
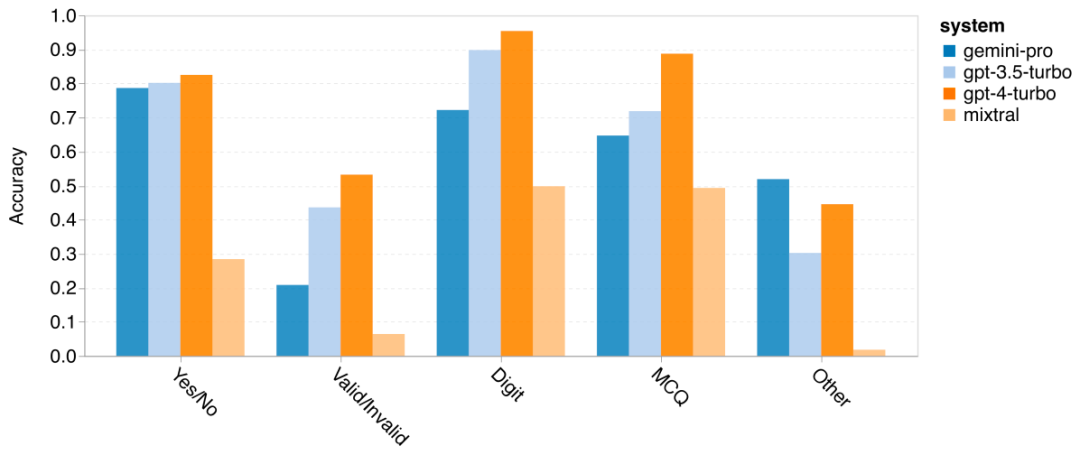
Figure 10: Accuracy of the tested models on BIG-Bench-Hard based on answer type.
In conclusion, it seems that no single model excels in specific tasks. Therefore, when performing general reasoning tasks, it may be worthwhile to try both Gemini and GPT models and then decide which model to use.
Mathematical Ability
To evaluate the mathematical reasoning ability of the tested models, the author selected four mathematical problem benchmark test sets:
(1) GSM8K: Elementary math benchmark test;
(2) SVAMP: Checks robust reasoning ability by changing the word order to generate questions;
(3) ASDIV: Involves different language patterns and question types;
(4) MAWPS: Contains arithmetic and algebraic word problems.
The author compared the accuracy of Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo, and Mixtral on four mathematical problem test sets, examining their overall performance, performance under different problem complexities, and performance under different depths of chain prompts.
Figure 11 presents the overall results, showing that in tasks involving different language patterns in GSM8K, SVAMP, and ASDIV, Gemini Pro's accuracy is slightly lower than GPT 3.5 Turbo and significantly lower than GPT 4 Turbo. For tasks in MAWPS, although the accuracy of all tested models exceeds 90%, Gemini Pro still lags behind the GPT models. In this task, GPT 3.5 Turbo slightly outperforms GPT 4 Turbo. In comparison, the accuracy of the Mixtral model is much lower than the other models.
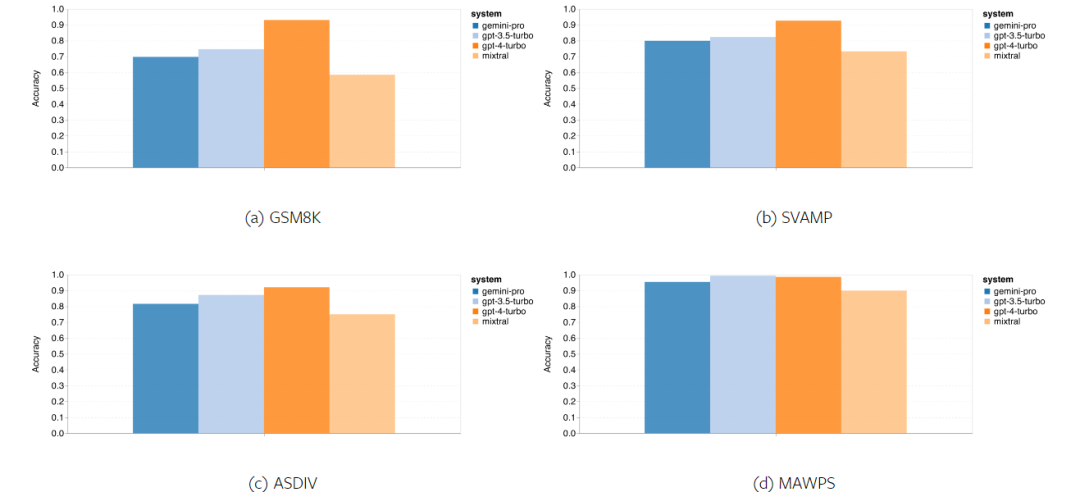
Figure 11: Overall accuracy of the tested models on the four mathematical reasoning test sets.
Figure 12 shows the robustness of each model in generating answers based on the length of the questions. Similar to the reasoning tasks in BIG-Bench Hard, the tested models show decreased accuracy when answering longer questions. GPT 3.5 Turbo performs better on shorter questions than Gemini Pro, but its accuracy decreases more rapidly. Gemini Pro's accuracy on longer questions is similar to GPT 3.5 Turbo's, but still slightly lower.
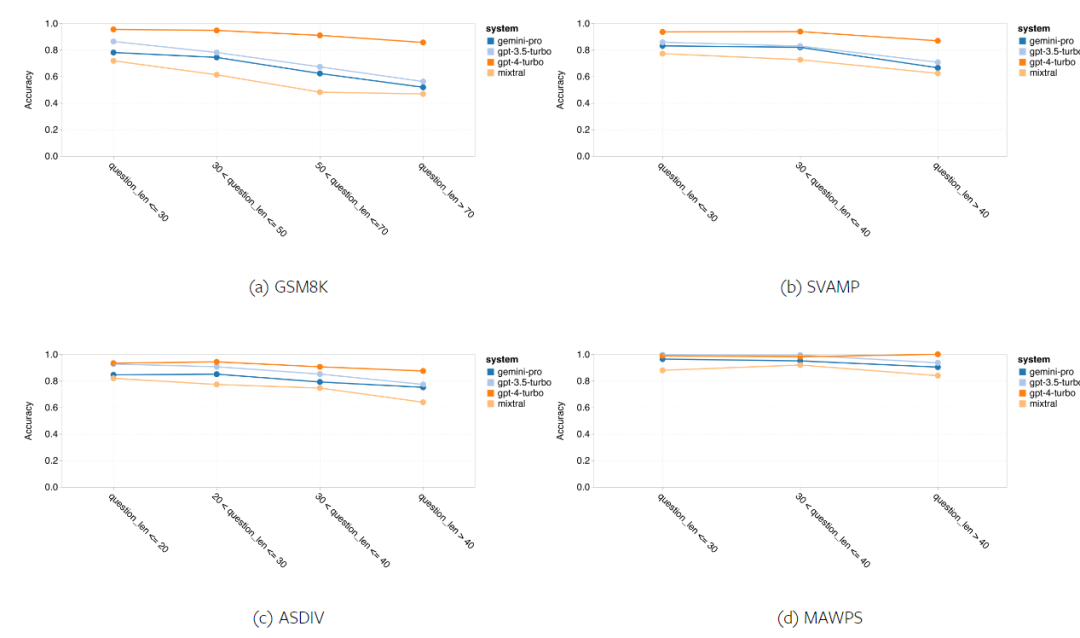
Figure 12: Accuracy of the tested models on the four mathematical reasoning test sets based on generating answers of different question lengths.
Additionally, the author observed that the accuracy of the tested models varies when longer chain prompts are required for answers. As shown in Figure 13, even with longer chain prompts, GPT 4 Turbo remains very robust, while GPT 3.5 Turbo, Gemini Pro, and Mixtral show declining performance as the length of chain prompts increases. Through analysis, the author also found that in complex examples with a chain prompt length exceeding 100, Gemini Pro outperforms GPT 3.5 Turbo, but performs poorly in shorter examples.
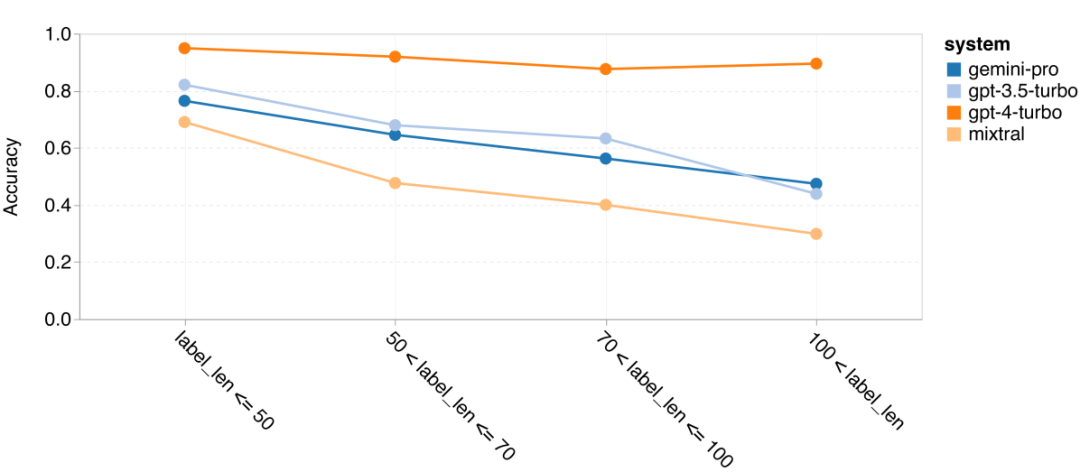
Figure 13: Accuracy of each model on GSM8K at different chain prompt lengths.
Figure 14 displays the accuracy of the tested models in generating answers with different numbers in the answers. The author created three "buckets" based on the number of digits in the answers: 1 digit, 2 digits, and 3 or more digits (except for the MAWPS task, where the answers did not exceed two digits). As shown, GPT 3.5 Turbo appears to be more robust in handling multi-digit mathematical problems, while Gemini Pro shows degradation in problems with more digits.
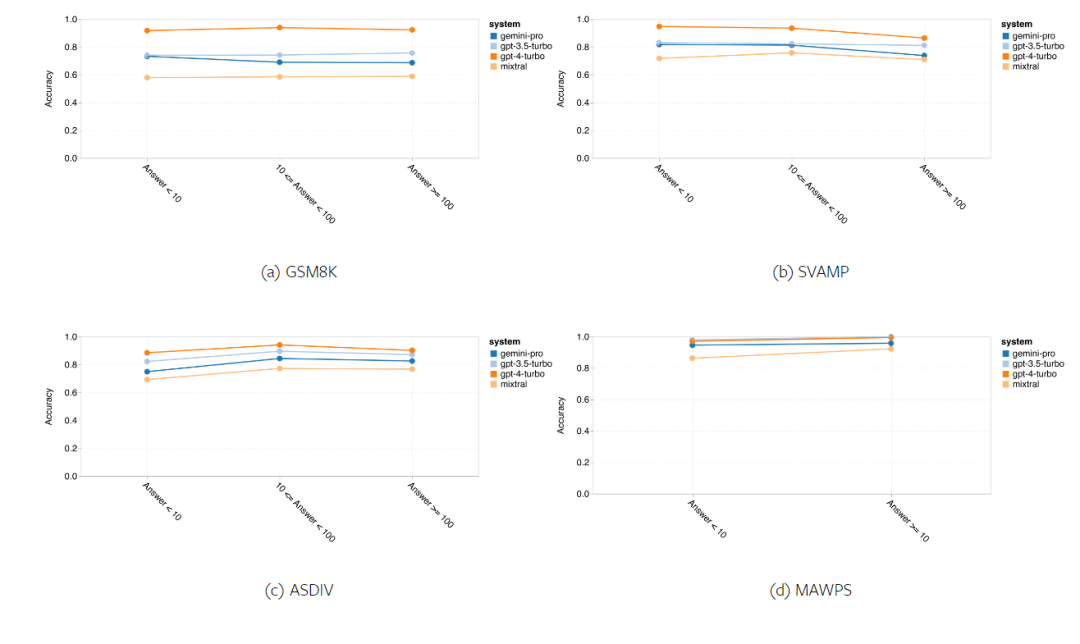
Figure 14: Accuracy of each model on the four mathematical reasoning test sets with different numbers of digits in the answers.
Code Generation
In this section, the author used two code generation datasets—HumanEval and ODEX—to test the models' coding abilities. The former tests the models' basic code comprehension of a limited set of functions in the Python standard library, while the latter tests the models' ability to use a wider range of libraries in the entire Python ecosystem. The inputs for these tasks are task descriptions written in English (usually with test cases). These tasks are used to evaluate the models' language comprehension, algorithm comprehension, and elementary math abilities. Overall, HumanEval has 164 test samples, and ODEX has 439 test samples.
Firstly, from the overall results shown in Figure 15, it can be seen that Gemini Pro's Pass@1 scores in both tasks are lower than GPT 3.5 Turbo and significantly lower than GPT 4 Turbo. These results indicate that Gemini's code generation ability still needs improvement.
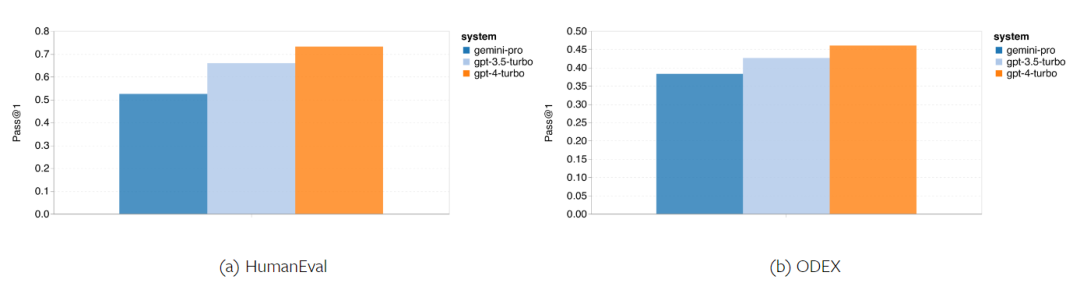
Figure 15: Overall accuracy of each model in the code generation tasks.
Secondly, the author analyzed the relationship between the gold solution length and model performance in Figure 16 (a). The length of the solution can to some extent indicate the difficulty of the corresponding code generation task. The author found that when the solution length is less than 100 (indicating easier cases), Gemini Pro achieves Pass@1 scores comparable to GPT 3.5. However, as the solution length increases, it falls significantly behind. This contrasts with the results from the previous sections, where the author found that in general, Gemini Pro performs robustly with longer inputs and outputs in English tasks.
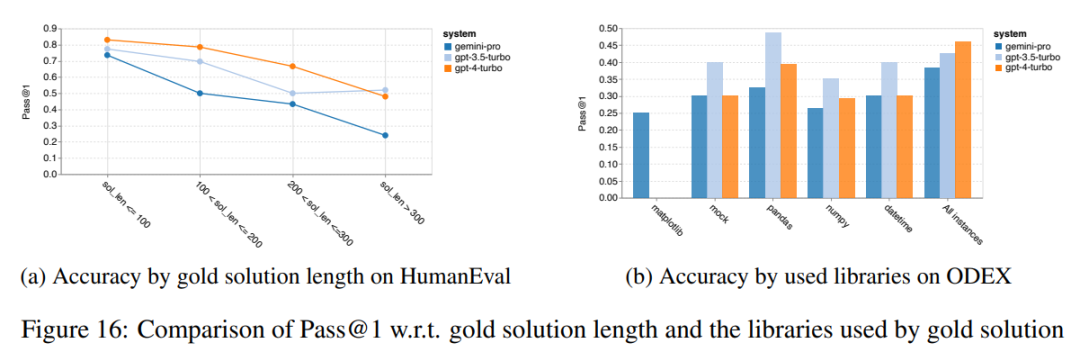
In addition, the author analyzed the impact of each solution's required libraries on model performance in Figure 16 (b). In most library use cases, such as mock, pandas, numpy, and datetime, Gemini Pro's performance is worse than GPT 3.5. However, in the case of matplotlib, its performance is better than GPT 3.5 and GPT 4, indicating its stronger ability to execute code for visualizing plots.
Finally, the author presented several specific failure cases where Gemini Pro's performance in code generation is worse than GPT 3.5. Firstly, they noticed that Gemini falls slightly short in correctly selecting functions and parameters from the Python API. For example, given the prompt:
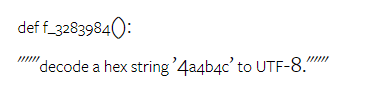
Gemini Pro generated the following code, resulting in a type mismatch error:
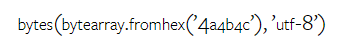
In contrast, GPT 3.5 Turbo used the following code, achieving the expected result:
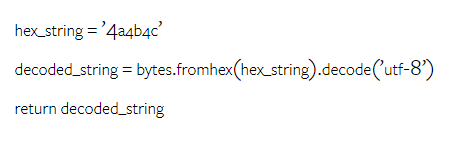
Additionally, Gemini Pro has a higher error rate, where the executed code is syntactically correct but does not correctly match more complex intentions. For example, with the following prompt:

Gemini Pro created an implementation that only extracts the unique numbers, without removing those that appear multiple times.

Machine Translation
This set of experiments evaluated the models' multilingual capabilities using the FLORES-200 machine translation benchmark, particularly focusing on the translation abilities between various language pairs. The author emphasized different subsets of 20 languages used in the analysis by Robinson et al. (2023), covering varying degrees of resource availability and translation difficulty. The evaluation was conducted on 1012 sentences from the test sets of all selected language pairs.
In Tables 4 and 5, the author compared Gemini Pro, GPT 3.5 Turbo, and GPT 4 Turbo with mature systems such as Google Translate. Additionally, they benchmarked NLLB-MoE, a leading open-source machine translation model known for its extensive language coverage. The results indicate that Google Translate generally outperforms other models, excelling in 9 languages. Next is NLLB, which excels in 6/8 languages under the 0/5-shot setting. The general language model shows competitive performance but has not surpassed dedicated machine translation systems in translating non-English languages.
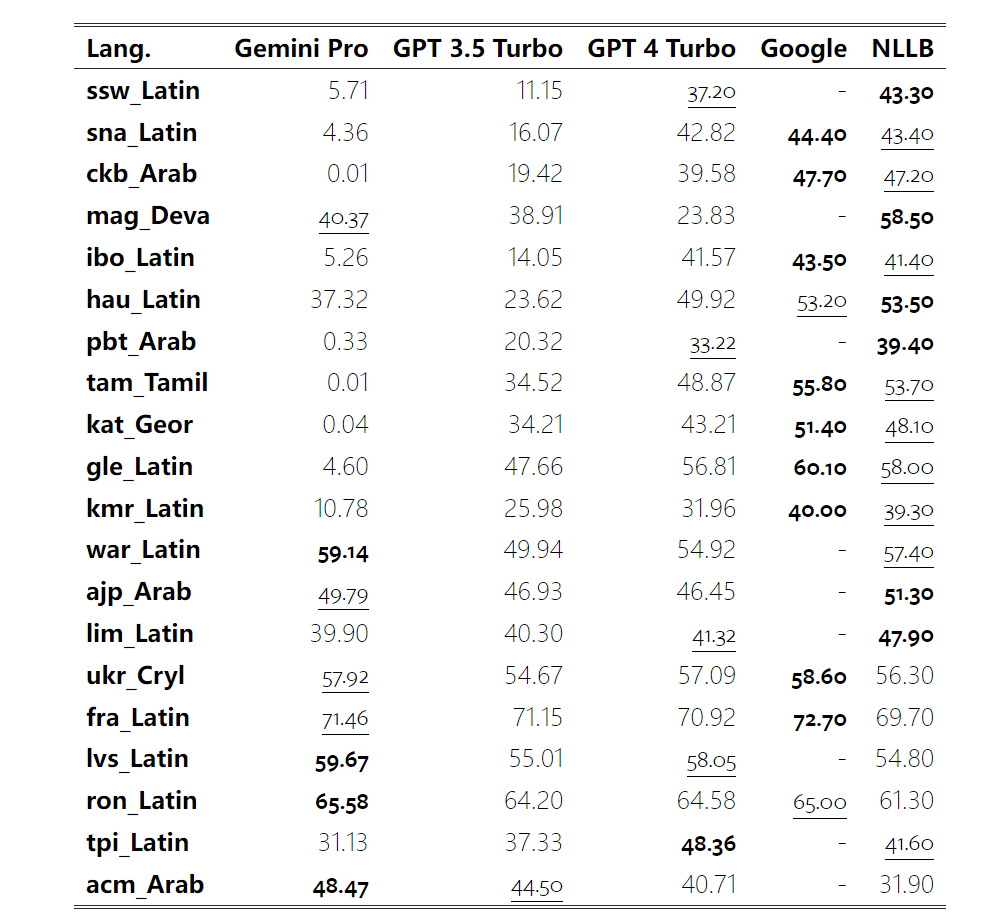
Table 4: Performance of each model in machine translation of all languages using 0-shot prompts (chRF (%) scores). Best scores are shown in bold, second best scores are underlined.
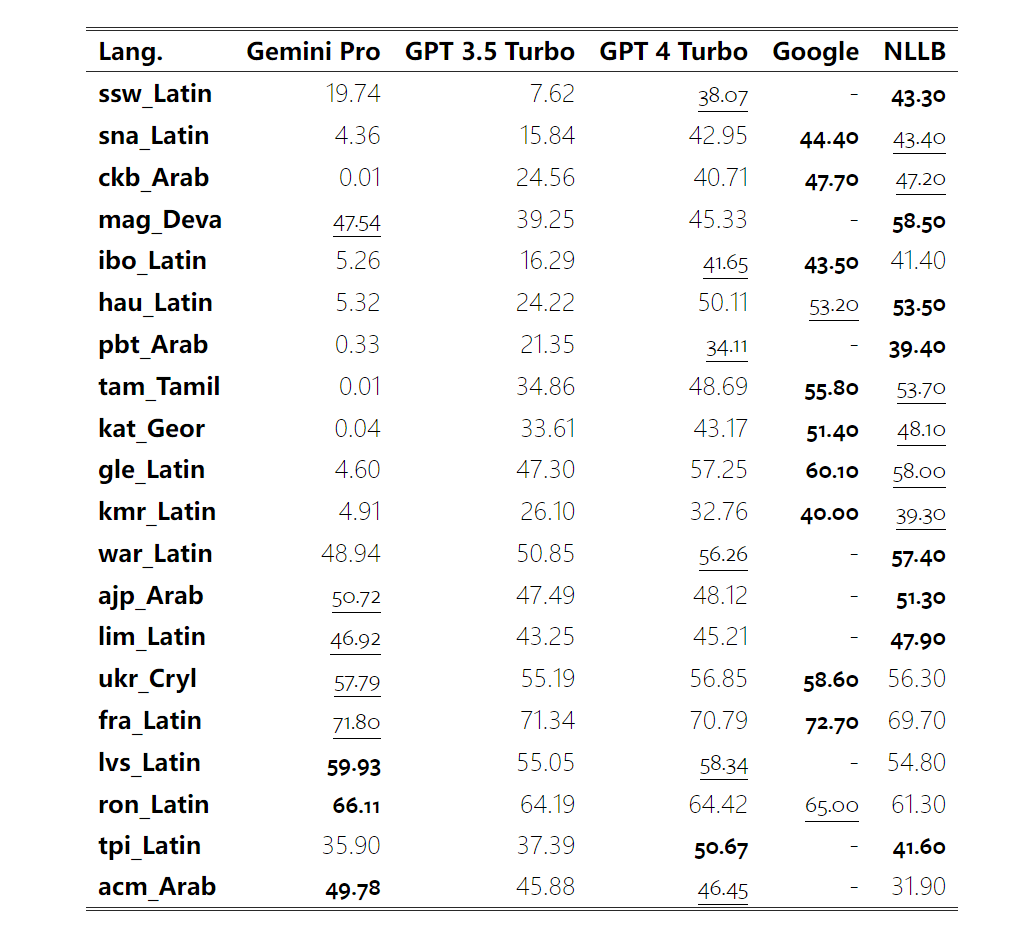
Table 5: Performance of each model in machine translation of all languages using 5-shot prompts (chRF (%) scores). Best scores are shown in bold, second best scores are underlined.
Figure 17 shows the performance comparison of the general language model in different language pairs. Compared to GPT 3.5 Turbo and Gemini Pro, GPT 4 Turbo exhibits consistent performance deviations compared to NLLB. GPT 4 Turbo also shows significant improvement in low-resource languages, while its performance is similar to NLLB in high-resource languages. In 8 out of 20 languages, Gemini Pro's performance is better than GPT 3.5 Turbo and GPT 4 Turbo, achieving the highest performance in 4 languages. However, Gemini Pro shows a strong tendency for block responses in approximately 10 language pairs.
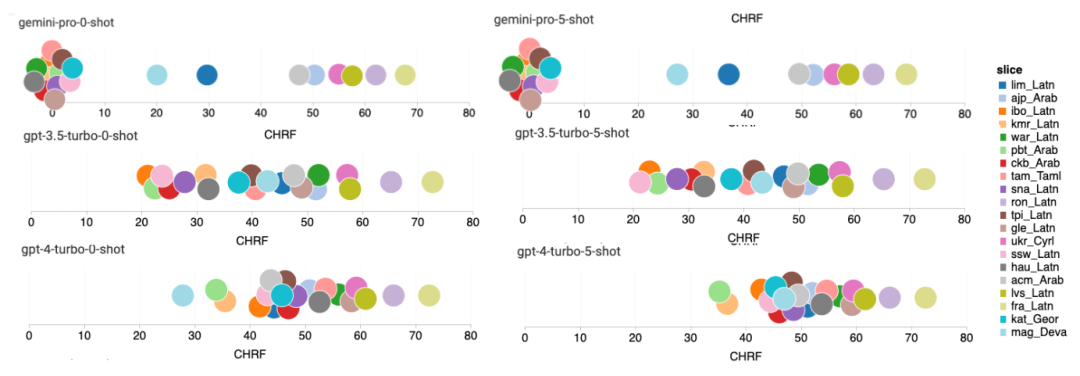
Figure 17: Machine translation performance (chRF (%) scores) divided by language pairs.
Figure 18 shows that Gemini Pro's performance is lower in these languages because it tends to produce block responses in low-confidence scenarios. If Gemini Pro generates a "Blocked Response" error in the 0-shot or 5-shot configuration, the response is considered "blocked."
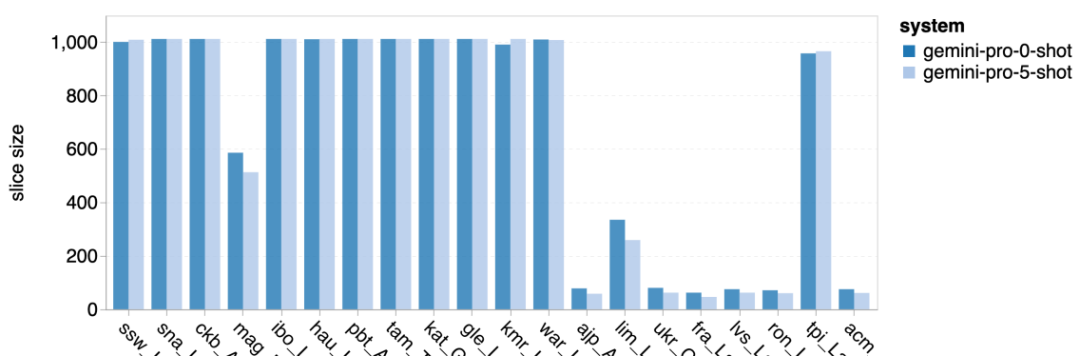
Figure 18: Number of samples blocked by Gemini Pro.
A closer look at Figure 19 reveals that Gemini Pro slightly outperforms GPT 3.5 Turbo and GPT 4 Turbo in high-confidence unblocked samples. Specifically, it outperforms GPT 4 Turbo by 1.6 chrf and 2.6 chrf in the 5-shot and 0-shot settings, respectively, and outperforms GPT 3.5 Turbo by 2.7 chrf and 2 chrf. However, the author's preliminary analysis of the performance of GPT 4 Turbo and GPT 3.5 Turbo on these samples indicates that these samples are generally more challenging to translate. Gemini Pro performs poorly on these specific samples, especially evident in its tendency to produce block responses in 0-shot and unblocked responses in 5-shot, and vice versa.
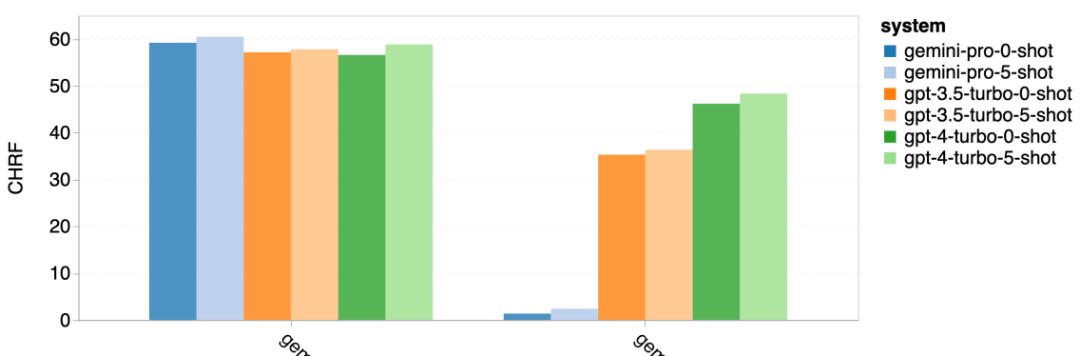
Figure 19: chrf performance (%) of blocked and unblocked samples.
Throughout the entire analysis of the models, the author observed that few-shot prompts generally moderately improve average performance, with the variance pattern increasing in the order of GPT 4 Turbo, GPT 3.5 Turbo, and Gemini Pro. Although Gemini Pro's 5-shot prompts show improvement in high-confidence languages compared to 0-shot prompts, in certain languages such as hau_Latin, the model's confidence significantly decreases, resulting in blocked responses (see Table 5).
Figure 20 displays apparent trends categorized by language family or script. An important observation is that Gemini Pro's performance on Cyrillic script is competitive compared to other models, but its performance on other scripts is less satisfactory. GPT-4 excels in various scripts, especially with few-shot prompts, with this effect particularly pronounced in languages using the Devanagari script.
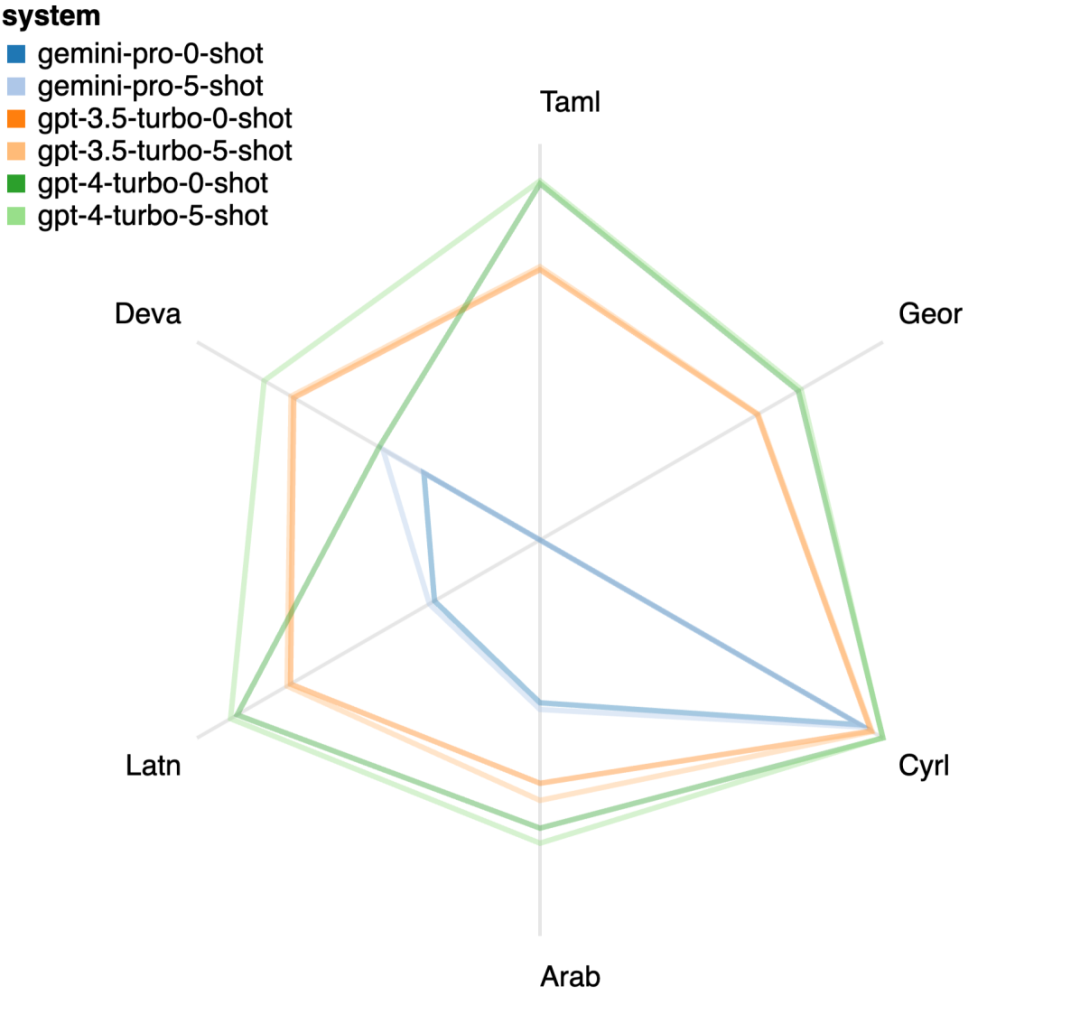
Figure 20: Performance of each model in different scripts (chrf (%)).
Web Agent
Finally, the author examined the ability of each model as a web navigation intelligent agent, a task that requires long-term planning and complex data understanding. They used the WebArena simulation environment, where the success criterion is the execution result. The tasks assigned to the intelligent agents include information search, website navigation, and content and configuration operations. The tasks involve various websites, including e-commerce platforms, social forums, collaborative software development platforms (such as gitlab), content management systems, and online maps.
The author tested the overall success rate, task-specific success rates, response length, trajectory steps, and the tendency to predict task failure of Gemini Pro. Table 6 lists the overall performance. Gemini Pro's performance is close to GPT-3.5 Turbo, but slightly inferior. Similar to GPT-3.5 Turbo, Gemini Pro performs better when prompted that the task may not be completed (UA hint). In the presence of a UA hint, Gemini Pro's overall success rate is 7.09%.
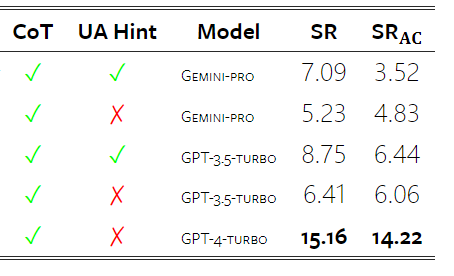
Table 6: Performance of each model on WebArena.
When segmented by website type, as shown in Figure 21, it can be seen that Gemini Pro's performance on gitlab and maps is not as good as GPT-3.5 Turbo, while its performance on content management, reddit, and e-commerce websites is similar to GPT-3.5 Turbo. In multi-site tasks, Gemini Pro outperforms GPT-3.5 Turbo, consistent with previous results that Gemini performs better on more complex subtasks across various benchmarks.
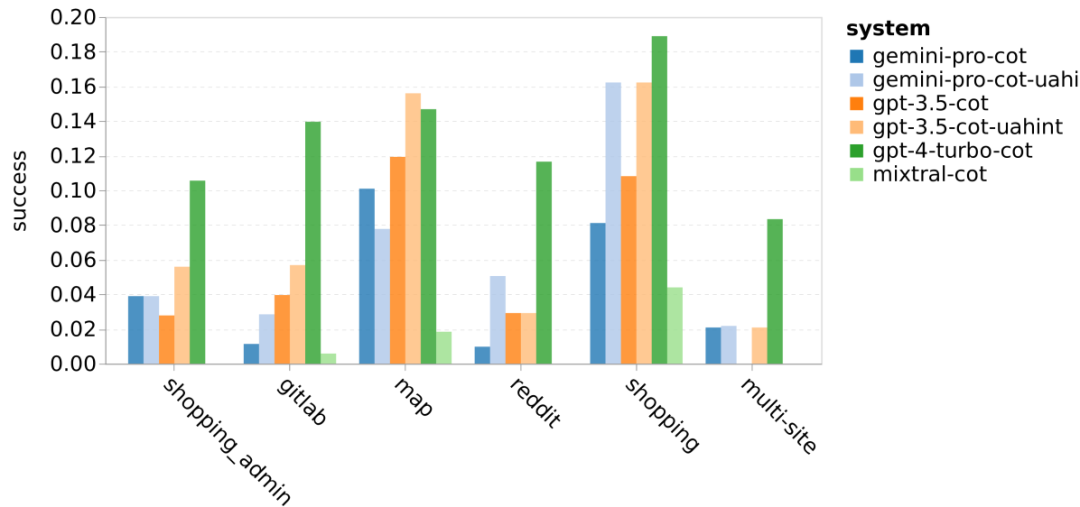
Figure 21: Web agent success rates on different types of websites.
As shown in Figure 22, overall, Gemini Pro predicts more tasks as unable to be completed, especially when given a UA hint. In the presence of a UA hint, Gemini Pro predicts that over 80.6% of tasks cannot be completed, while GPT-3.5 Turbo only predicts 47.7%. It is important to note that only 4.4% of tasks in the dataset are actually unable to be completed, so both models significantly overestimate the actual number of tasks that cannot be completed.
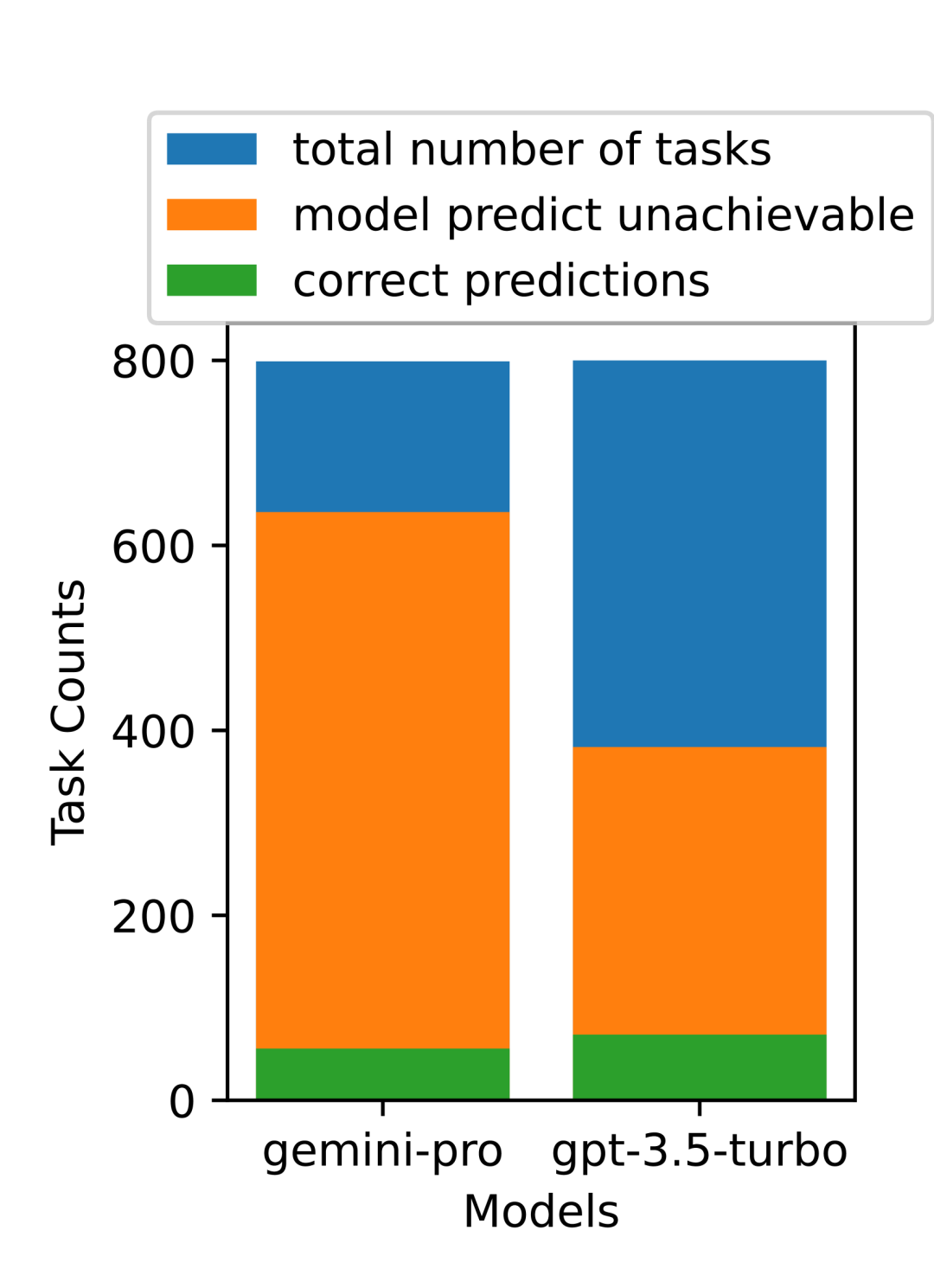
Figure 22: UA prediction count.
Additionally, the author observed that Gemini Pro tends to respond with shorter phrases and takes fewer steps before reaching a conclusion. As shown in Figure 23 (a), over half of Gemini Pro's trajectories are less than 10 steps, while most trajectories of GPT-3.5 Turbo and GPT-4 Turbo are between 10 and 30 steps. Similarly, most of Gemini's responses are less than 100 characters, while most responses from GPT-3.5 Turbo, GPT-4 Turbo, and Mixtral are over 300 characters in length (Figure 23 (b)). Gemini tends to directly predict actions, while other models engage in reasoning before making action predictions.
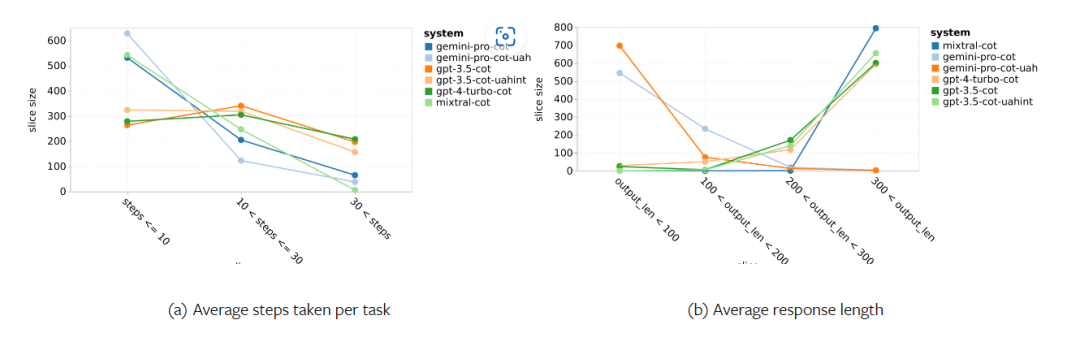
Figure 23: Behavior of models on WebArena.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







