GPT's emergence has attracted global attention to large language models, and various industries are trying to use this "black technology" to improve work efficiency and accelerate industry development. Future3 Campus and Footprint Analytics jointly conducted in-depth research on the infinite possibilities of AI and Web3 integration, and jointly released the research report "Analysis of the Current Situation, Competitive Landscape, and Future Opportunities of AI and Web3 Data Industry".
The report is divided into two parts, with this article being the first part, co-authored by Footprint Analytics researchers Lesley and Shelly. The second part is co-authored by Future3 Campus researchers Sherry and Humphrey.
Abstract:
- The development of LLM technology has made people pay more attention to the combination of AI and Web3, and a new application paradigm is gradually unfolding. In this article, we will focus on how to use AI to improve the user experience and production efficiency of Web3 data.
- Due to the early stage of the industry and the characteristics of blockchain technology, the Web3 data industry faces many challenges, including data sources, update frequency, and anonymity, making the use of AI to solve these problems a new focus.
- Compared to traditional artificial intelligence, LLM has advantages such as scalability, adaptability, efficiency improvement, task decomposition, accessibility, and ease of use, providing room for imagination to improve the experience and production efficiency of blockchain data.
- LLM requires a large amount of high-quality data for training, and the vertical knowledge in the blockchain field is rich and the data is open, which can provide learning materials for LLM.
- LLM can also help produce and enhance the value of blockchain data, such as data cleaning, labeling, and generating structured data.
- LLM is not a panacea and needs to be applied according to specific business needs. It is necessary to use the efficiency of LLM while also paying attention to the accuracy of the results.
1. Development and Integration of AI and Web3
1.1. Development History of AI
The history of artificial intelligence (AI) can be traced back to the 1950s. Since 1956, people have begun to focus on the field of artificial intelligence, gradually developing early expert systems to help solve problems in professional fields. Subsequently, the rise of machine learning expanded the application areas of AI, and AI began to be more widely used in various industries. Today, with the outbreak of deep learning and generative artificial intelligence, it has brought unlimited possibilities to people, with each step full of continuous challenges and innovations in pursuit of higher levels of intelligence and broader application areas.
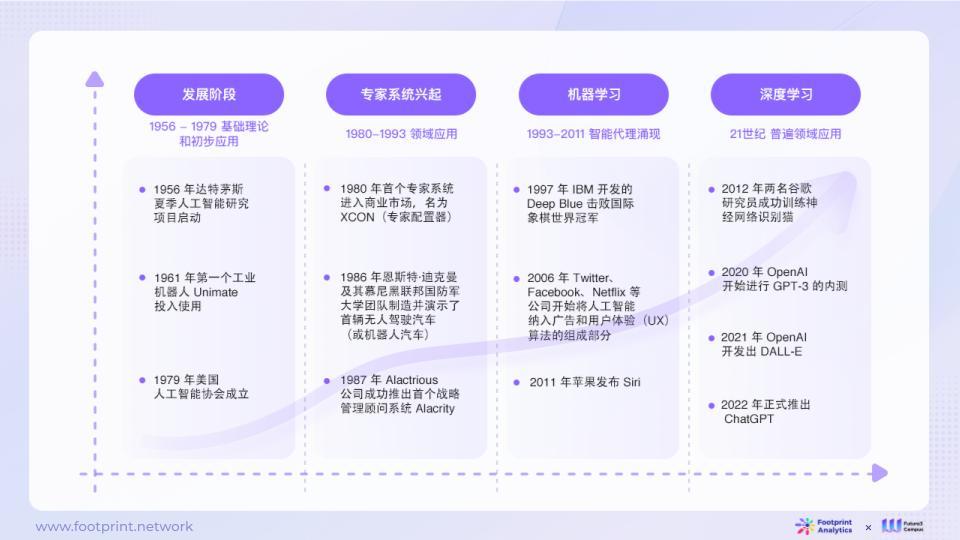
On November 30, 2022, ChatGPT was launched, demonstrating for the first time the possibility of low-threshold, high-efficiency interaction between AI and humans. ChatGPT has sparked a broader discussion of artificial intelligence, redefining the way people interact with AI to make it more efficient, intuitive, and human-centered. This has also led to increased attention to more generative artificial intelligence models such as Anthropic (Amazon), DeepMind (Google), and Llama. At the same time, practitioners in various industries have begun to actively explore how AI will drive the development of their fields or seek to stand out in the industry by combining with AI technology, further accelerating the penetration of AI in various fields.
1.2. Fusion of AI and Web3
The vision of Web3 began with the reform of the financial system, aiming to achieve more user empowerment and is expected to lead the transformation of modern economy and culture. Blockchain technology provides a solid technical foundation for achieving this goal, redesigning not only the transmission of value and incentive mechanisms, but also providing support for resource allocation and power decentralization.
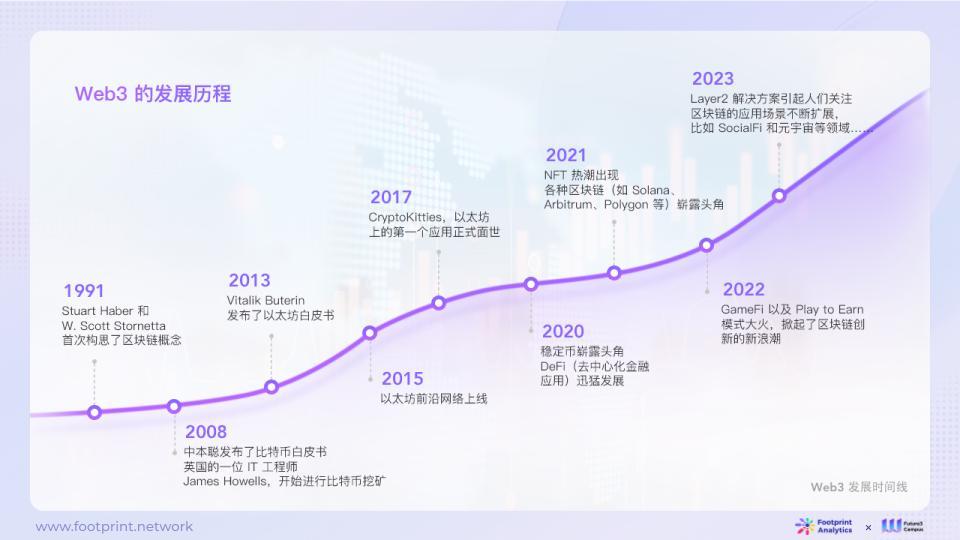
As early as 2020, the investment company Fourth Revolution Capital (4RC) in the blockchain field pointed out that blockchain technology will combine with AI to decentralize global industries such as finance, healthcare, e-commerce, and entertainment, to disrupt existing industries.
Currently, the integration of AI and Web3 mainly focuses on two major directions:
- Using AI to enhance productivity and user experience.
- Combining the transparent, secure, decentralized storage, traceable, and verifiable technological characteristics of blockchain, as well as the decentralized production relations of Web3, to solve pain points that traditional technology cannot solve or incentivize community participation, and improve production efficiency.
The market's exploration of the integration of AI and Web3 includes the following directions:
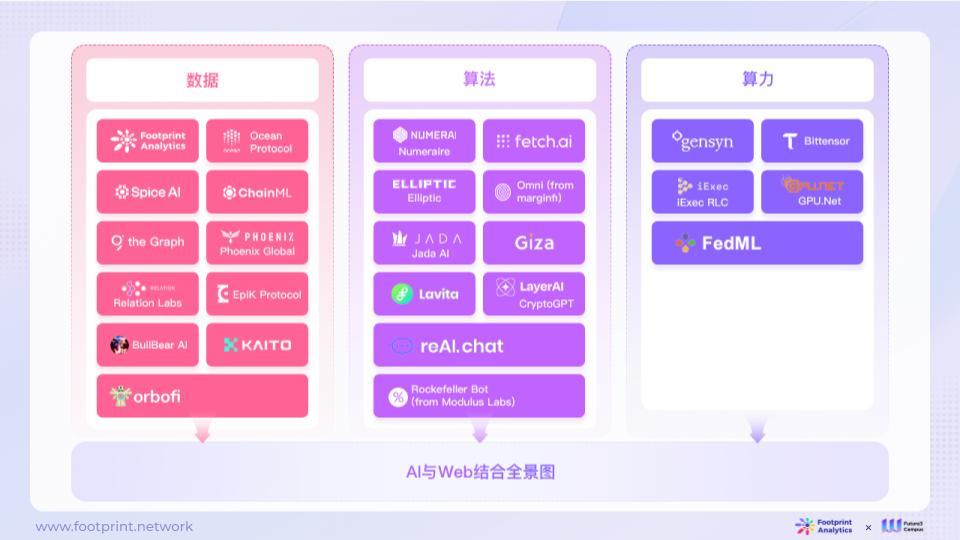
- Data: Blockchain technology can be applied to model data storage, providing encrypted datasets to protect data privacy and record the source and usage of model data, as well as verify the authenticity of the data. By accessing and analyzing data stored on the blockchain, AI can extract valuable information for model training and optimization. At the same time, AI can also serve as a data production tool to improve the production efficiency of Web3 data.
- Algorithms: The algorithms in Web3 can provide AI with a more secure, trustworthy, and autonomously controlled computing environment, embedding security barriers in model parameters to prevent misuse or malicious operations. AI can interact with the algorithms in Web3, such as using smart contracts to execute tasks, verify data, and make decisions. At the same time, AI's algorithms can also provide Web3 with more intelligent and efficient decision-making and services.
- Computing power: The decentralized computing resources of Web3 can provide AI with high-performance computing capabilities. AI can use the decentralized computing resources in Web3 for model training, data analysis, and prediction. By distributing computing tasks to multiple nodes on the network, AI can accelerate computation and handle larger-scale data.
In this article, we will focus on exploring how to use AI technology to improve the production efficiency and user experience of Web3 data.
2. Current Status of Web3 Data
2.1. Comparison of Web2 & Web3 Data Industries
As the most core component of AI, "data" has many differences in Web3 compared to the familiar Web2. The differences are mainly due to the application architecture of Web2 and Web3, which lead to different data characteristics.
2.1.1. Comparison of Web2 & Web3 Application Architectures
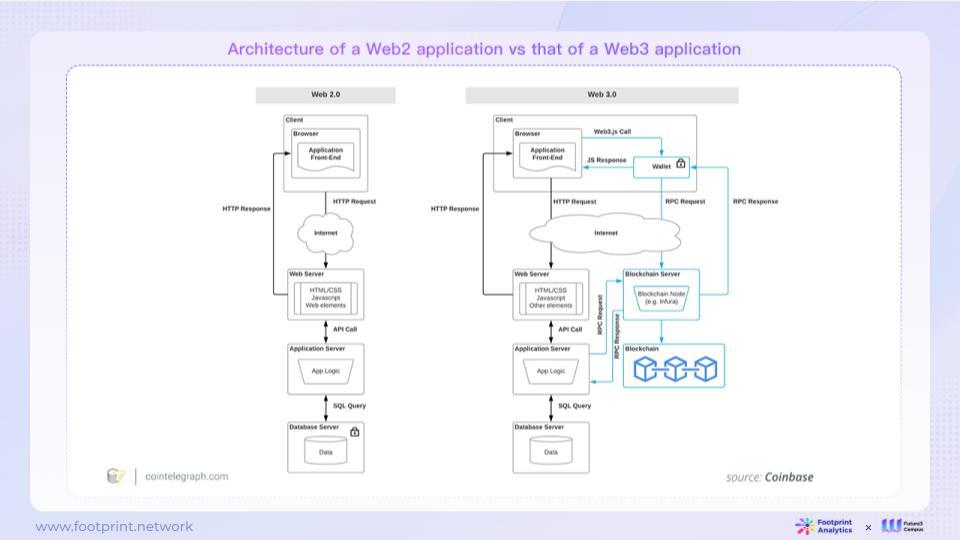
In the Web2 architecture, web pages or apps are typically controlled by a single entity (usually a company), which has absolute control over the content they create. They can decide who can access the content and logic on their servers, as well as the rights users have and the duration of the content's existence online. Many cases have shown that internet companies have the right to change the rules on their platforms, and even suspend services for users, without allowing users to retain the value they have created.
In contrast, the Web3 architecture leverages the concept of a Universal State Layer, placing some or all of the content and logic on a public blockchain. This content and logic are publicly recorded on the blockchain and accessible to everyone, allowing users to directly control on-chain content and logic. In Web2, users need an account or API key to interact with on-chain content, while in Web3, users can interact with on-chain content without the need for authorized accounts or API keys (except for specific management operations).
2.1.2. Comparison of Web2 and Web3 Data Characteristics
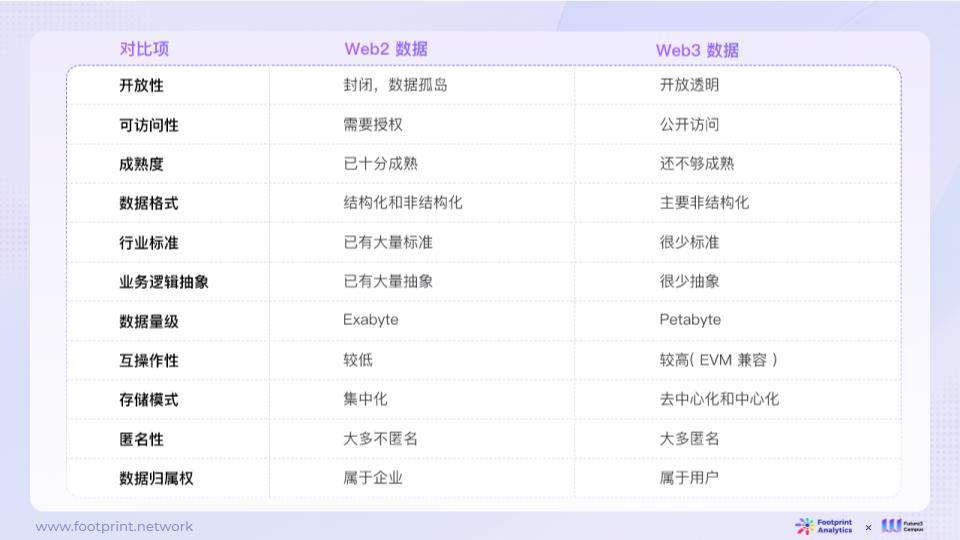
Web2 data is typically closed and highly restricted, with complex permission controls, a high level of maturity, various data formats, strict adherence to industry standards, and complex business logic abstractions. This data is large in scale but relatively low in interoperability, usually stored on central servers, and does not prioritize privacy protection, with most being non-anonymous.
In contrast, Web3 data is more open with broader access permissions, although it is less mature, primarily consisting of unstructured data with rare standardization, and relatively simplified business logic abstractions. Web3 data has a smaller scale compared to Web2, but it has higher interoperability (e.g., EVM compatibility) and can store data in a decentralized or centralized manner, while emphasizing user privacy, often involving anonymous on-chain interactions.
2.2. Current Status, Prospects, and Challenges of the Web3 Data Industry
In the Web2 era, data was as precious as "reserves" of oil, and accessing and obtaining large-scale data has always been a major challenge. In Web3, the openness and sharing of data suddenly made everyone feel like "oil is everywhere," allowing AI models to more easily access more training data, which is crucial for improving model performance and intelligence. However, there are still many unresolved issues in handling this "new oil" of Web3 data, including:
Data Sources: Handling on-chain data requires time-consuming and labor-intensive indexing processes, with developers and data analysts spending a significant amount of time and resources to adapt to the data differences between different chains and projects. The lack of unified production and processing standards in the on-chain data industry makes it difficult for non-professional traders to identify and find the most accurate and reliable data, increasing the difficulty of their on-chain trading and investment decisions.
Data Updates: The large volume and high update frequency of on-chain data make it difficult to process into structured data in a timely manner. The frequent generation and updates of data make it challenging to maintain high-quality data processing and timely updates, requiring automated processing processes, which is a significant challenge in terms of cost and efficiency.
Data Analysis: The anonymous nature of on-chain data makes it difficult to distinguish the identities of the data, hindering the linkage of on-chain activities with real-world economic, social, or legal trends, which is important for specific scenarios such as data analysis.
As discussions about productivity changes sparked by large language models (LLM) technology continue, the focus in the Web3 field has also turned to whether AI can be used to address these challenges.
3.1. Comparison of Traditional AI and LLM Features
In terms of model training, traditional AI models are typically smaller in scale, with parameter counts ranging from tens of thousands to millions, requiring a large amount of manually labeled data to ensure the accuracy of the output. The power of LLM lies in its use of massive corpora to fit parameters of billions or even trillions, greatly enhancing its ability to understand natural language, but also requiring more data for training, resulting in high training costs.
In terms of capabilities and operation, traditional AI is more suitable for specific domain tasks, providing relatively precise and professional answers. In contrast, LLM is more suitable for general tasks but is prone to hallucination issues, meaning that in some cases, its answers may not be precise or professional, or even completely wrong. Therefore, multiple checks, training iterations, or additional error correction mechanisms and frameworks may be needed for objective, trustworthy, and traceable results.

3.1.1. Practice of Traditional AI in the Web3 Data Field
Traditional AI has demonstrated its importance in the blockchain data industry, bringing more innovation and efficiency to this field. For example, the 0xScope team used AI technology to build a graph-based clustering analysis algorithm, which accurately identifies related addresses among users through the allocation of weights based on different rules. This application of deep learning algorithms improved the accuracy of address clustering, providing more precise tools for data analysis. Nansen used AI for NFT price prediction, providing insights into NFT market trends through data analysis and natural language processing technology. Trusta Labs used machine learning methods based on asset graph mining and user behavior sequence analysis to enhance the reliability and stability of its witch detection solution, contributing to the security of the blockchain network ecosystem. Goplus used traditional AI to improve the security and efficiency of decentralized applications (dApps) in its operations, collecting and analyzing security information from dApps to provide rapid risk alerts and help reduce the risk exposure of these platforms. This includes detecting risks in dApp main contracts by evaluating open-source status and potential malicious behavior factors, as well as collecting detailed audit information, including audit company credentials, audit times, and audit report links. Footprint Analytics used AI to generate code for producing structured data, analyze NFT trading wash trading, and screen out bot accounts.
However, traditional AI has limited information and focuses on using predefined algorithms and rules to perform preset tasks, while LLM learns from large-scale natural language data, enabling it to understand and generate natural language, making it more suitable for handling complex and massive text data.
Recently, with significant advancements in LLM, there has been new thinking and exploration of the combination of AI and Web3 data.
3.1.2. Advantages of LLM
LLM has the following advantages over traditional artificial intelligence:
Scalability: LLM supports large-scale data processing LLM demonstrates excellent scalability, efficiently handling large volumes of data and user interactions. This makes it well-suited for tasks requiring large-scale information processing, such as text analysis or large-scale data cleansing. Its high data processing capability provides powerful analytical and application potential for the blockchain data industry.
Adaptability: LLM can learn and adapt to multi-domain requirements LLM has outstanding adaptability, allowing it to be fine-tuned for specific tasks or embedded in industry or private databases, enabling it to quickly learn and adapt to subtle differences in different domains. This feature makes LLM an ideal choice for solving multi-domain, multi-purpose problems, providing broader support for the diversity of blockchain applications.
Efficiency Improvement: LLM automates tasks to improve efficiency LLM's high efficiency brings significant convenience to the blockchain data industry. It can automate tasks that would otherwise require a significant amount of human time and resources, thereby increasing productivity and reducing costs. LLM can generate large amounts of text, analyze massive datasets, or perform various repetitive tasks in seconds, reducing waiting and processing time, making blockchain data processing more efficient.
Task Decomposition: Can generate specific plans for certain tasks, breaking down large tasks into small steps LLM Agent has the unique ability to generate specific plans for certain tasks, breaking down complex tasks into manageable small steps. This feature is beneficial for handling large-scale blockchain data and performing complex data analysis tasks. By breaking down large tasks into smaller tasks, LLM can better manage data processing processes and produce high-quality analyses.
This capability is crucial for AI systems performing complex tasks, such as robot automation, project management, and natural language understanding and generation, enabling them to translate high-level task goals into detailed action plans, improving task execution efficiency and accuracy.
Accessibility and User-Friendliness: LLM provides user-friendly interaction through natural language LLM's accessibility allows more users to easily interact with data and systems, making these interactions more user-friendly. Through natural language, LLM makes data and systems more accessible and interactive, without users needing to learn complex technical terms or specific commands, such as SQL, R, Python, etc., for data retrieval and analysis. This feature broadens the audience for blockchain applications, allowing more people to access and use Web3 applications and services, regardless of their technical expertise, thereby promoting the development and popularization of the blockchain data industry.
3.2. Integration of LLM and Web3 Data
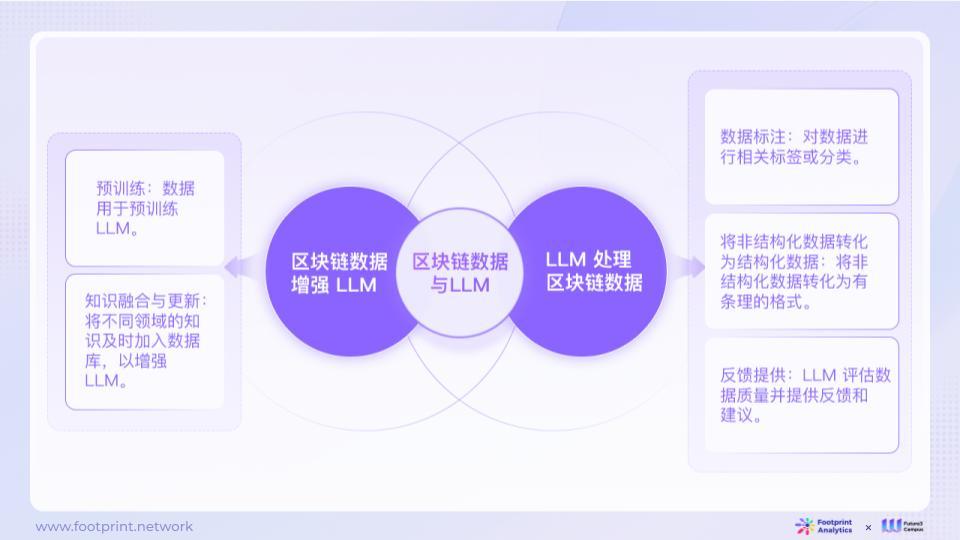
Training large language models relies on large-scale data to build models by learning patterns in the data. The interactions and behavioral patterns inherent in blockchain data are the fuel for LLM learning. The quantity and quality of data directly affect the learning effectiveness of LLM models.
Data is not only consumed by LLM, but LLM also contributes to data production and can even provide feedback. For example, LLM can assist data analysts in data preprocessing, such as data cleansing and labeling, or generate structured data, removing noise from the data and highlighting useful information.
3.3. Common Technical Solutions to Enhance LLM
The emergence of ChatGPT not only demonstrates the general ability of LLM to solve complex problems but also triggers global exploration of adding external capabilities to its general ability. This includes enhancing general capabilities (including context length, complex reasoning, mathematics, code, multimodal, etc.) and expanding external capabilities (handling unstructured data, using more complex tools, interacting with the physical world, etc.). The core technical issue for the commercialization of large models in the crypto vertical domain is how to graft proprietary knowledge in the crypto field and personalized private data onto the general capabilities of large models.
Currently, most applications are focused on retrieval-augmented generation (RAG), such as prompt engineering and embedding techniques, and existing agent tools mostly focus on improving the efficiency and accuracy of RAG work. The main reference architectures for LLM-based application stacks in the market include the following:
- Prompt Engineering
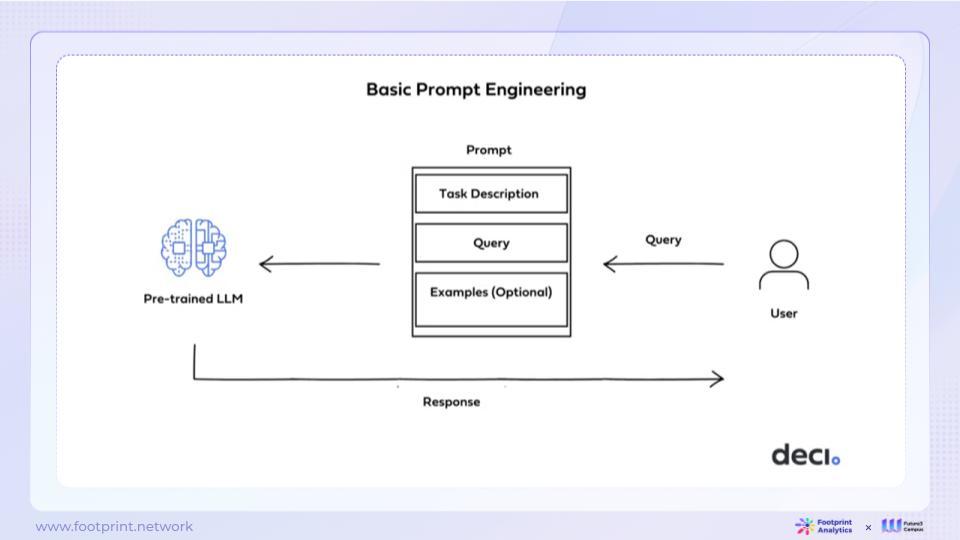
Currently, most practitioners use basic solutions when building applications, namely Prompt Engineering. This method involves designing specific prompts to change the model's input to meet the specific needs of an application, making it the most convenient and quick approach. However, basic Prompt Engineering has some limitations, such as delayed database updates, complex content, and limitations on in-context length support and multi-turn question-answering.
Therefore, the industry is also researching more advanced improvement solutions, including embedding and fine-tuning.
- Embedding
Embedding is a widely used data representation method in the field of artificial intelligence, efficiently capturing semantic information about objects. By mapping object properties into vector form, embedding techniques can quickly find the most likely correct answers by analyzing the relationships between vectors. Embedding can be built on top of LLM to leverage the rich language knowledge learned by the model on extensive corpora. By using embedding techniques to introduce information specific to tasks or domains into pre-trained large models, the model becomes more specialized and better suited to specific tasks, while retaining the general capabilities of the base model.
In simple terms, embedding is like giving a comprehensively trained college student a reference book containing task-relevant knowledge and allowing them to use the book to complete tasks, enabling them to consult the reference book at any time and solve specific problems.
- Fine-Tuning
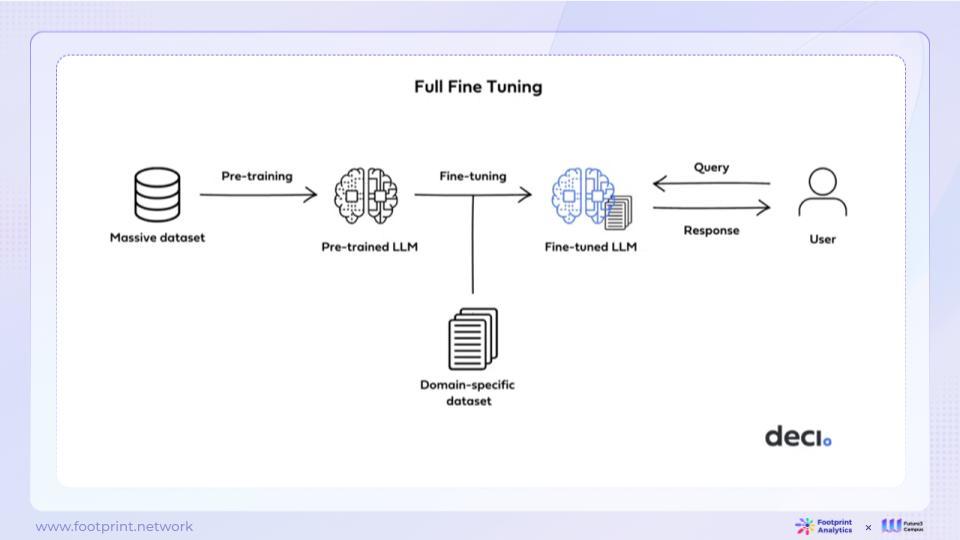
Unlike embedding, fine-tuning involves updating the parameters of a pre-trained language model to adapt it to specific tasks. This method allows the model to perform better on specific tasks while maintaining its general capabilities. The core idea of fine-tuning is to adjust model parameters to capture specific patterns and relationships relevant to the target task. However, the upper limit of the model's general capabilities is still constrained by the base model itself.
In simple terms, fine-tuning is like providing a comprehensively trained college student with specialized knowledge courses in addition to comprehensive capabilities, enabling them to master specialized knowledge and solve problems in the specialized field.
The current LLM, while powerful, may not necessarily meet all needs. Retraining LLM is a highly customized solution that involves introducing new datasets and adjusting model weights to make it more suitable for specific tasks, requirements, or domains. However, this approach requires significant computational resources and data, and managing and maintaining the retrained model is also a challenge.
- Agent Model
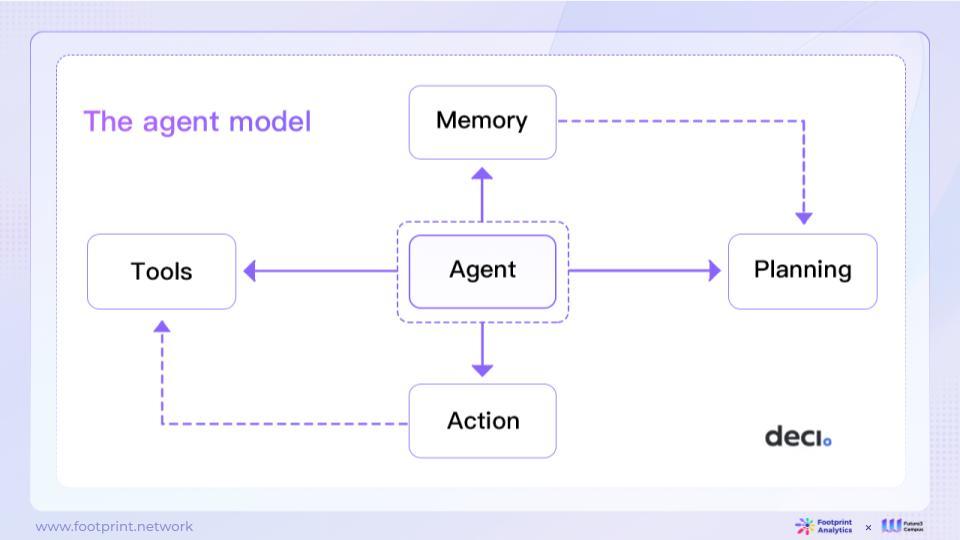
The agent model is a method for building intelligent agents, with LLM as the core controller. This system also includes several key components to provide more comprehensive intelligence.
- Planning: Breaking down large tasks into smaller tasks for easier completion
- Memory: Improving future plans by reflecting on past behavior
- Tools: Agents can use external tools to obtain more information, such as accessing search engines, calculators, etc.
Artificial intelligence agent models have powerful language understanding and generation capabilities, enabling them to solve general problems, perform task decomposition, and self-reflection. This makes them widely applicable in various scenarios. However, agent models also have limitations, such as constraints on context length, susceptibility to errors in long-term planning and task decomposition, and unstable reliability of output content. These limitations require continuous research and innovation to further expand the application of agent models in different domains.
The various technologies mentioned above are not mutually exclusive and can be used together in the process of training and enhancing the same model. Developers can fully leverage the potential of existing large language models, try different methods to meet increasingly complex application requirements. This integrated use not only helps improve model performance but also promotes rapid innovation and progress in Web3 technology.
However, we believe that while existing LLMs have played an important role in the rapid development of Web3, before fully attempting these existing models (such as OpenAI, Llama 2, and other open-source LLMs), we can start with a cautious approach, from prompt engineering and embedding RAG strategies, and carefully consider fine-tuning and retraining the base model.
3.4. Accelerating Various Processes of Blockchain Data Production with LLM
3.4.1. General Process of Blockchain Data Handling
Today, builders in the blockchain field are gradually realizing the value of data products. This value covers multiple areas such as product operation monitoring, predictive models, recommendation systems, and data-driven applications. Despite this growing awareness, data processing, as a crucial step from data acquisition to data application, is often overlooked.

- Converting raw unstructured blockchain data, such as events or logs, into structured data
- Converting structured raw data into abstract tables with business significance
- Calculating and extracting business metrics from abstract tables
3.4.2. Optimization of Blockchain Data Generation Process with LLM
LLM can address multiple issues in blockchain data processing, including but not limited to:
- Handling unstructured data
- Business abstraction
- Natural language interpretation of data
LLM can perform tasks such as extracting structured information from transaction logs and events, cleaning and identifying abnormal data, mapping raw on-chain data to business entities, labeling unstructured on-chain content, calculating core metrics, querying data, selecting, sorting, and analyzing metrics, and generating natural language descriptions of business abstractions.
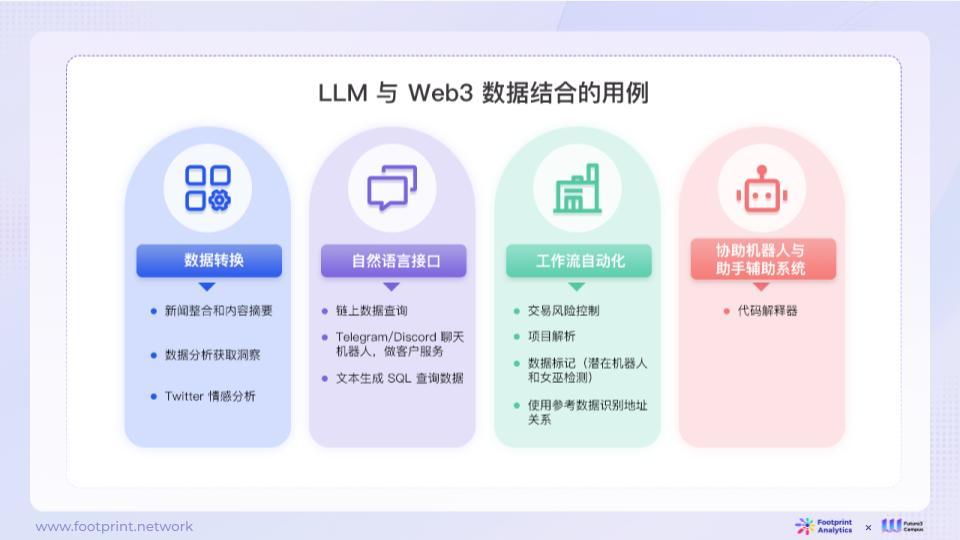
3.5. Current Use Cases
Based on the technical and product experience advantages of LLM, it can be applied to different on-chain data scenarios, which can be categorized into four types from easy to difficult:
- Data transformation
- Natural language interface
- Workflow automation
- Robot and assistant systems
3.6. Limitations of LLM
3.6.1. Industry Status: Mature Applications, Ongoing Challenges, and Unsolved Problems
In the field of Web3 data, despite some important progress, there are still challenges to be addressed.
Mature applications:
- Information processing using LLM: AI technologies like LLM have been successfully used for generating text summaries, summaries, explanations, etc., helping users extract key information from lengthy articles and professional reports, improving data readability and comprehensibility.
- Solving development issues using AI: LLM has been applied to address development-related problems, such as serving as an alternative to StackOverflow or search engines, providing developers with problem-solving and programming support.
Ongoing and exploratory issues:
- Code generation using LLM: The industry is working on applying LLM technology to the conversion of natural language to SQL query language to enhance the automation and comprehensibility of database queries. However, there are challenges, such as the requirement for high accuracy in generated code, ensuring successful and accurate answers, and a deep understanding of the business.
- Data labeling issues: Data labeling is crucial for training machine learning and deep learning models, but in the Web3 data domain, especially when dealing with anonymous blockchain data, data labeling complexity is high.
- Accuracy and hallucination issues: The appearance of hallucinations in AI models may be influenced by various factors, including biased or insufficient training data, overfitting, limited contextual understanding, lack of domain knowledge, adversarial attacks, and model architecture. Researchers and developers need to continuously improve training and calibration methods to enhance the credibility and accuracy of generated text.
- Utilizing data for business analysis and article generation: Using data for business analysis and article generation remains a challenging issue, requiring carefully designed prompts, high-quality data, data volume, and methods to reduce hallucination problems.
- Automatic indexing of smart contract data for data abstraction based on business domains: Automatically indexing smart contract data for data abstraction in different business domains is still an unresolved issue, requiring consideration of the characteristics of different business domains and the diversity and complexity of data.
- Handling time-series data, tabular document data, and more complex modalities: Models like DALL·E 2 are proficient in generating images, speech, and other common modalities from text. However, in the blockchain and financial domains, special treatment is required for time-series data, beyond simple text vectorization. Joint training across modalities and handling time-series data are important research directions for intelligent data analysis and applications.
3.6.2. Why LLM Alone Cannot Perfectly Solve the Problems in the Blockchain Data Industry
As a language model, LLM is more suitable for scenarios that require fluency, and further adjustments may be needed for accuracy. When applying LLM to the blockchain data industry, the following framework can provide some reference.
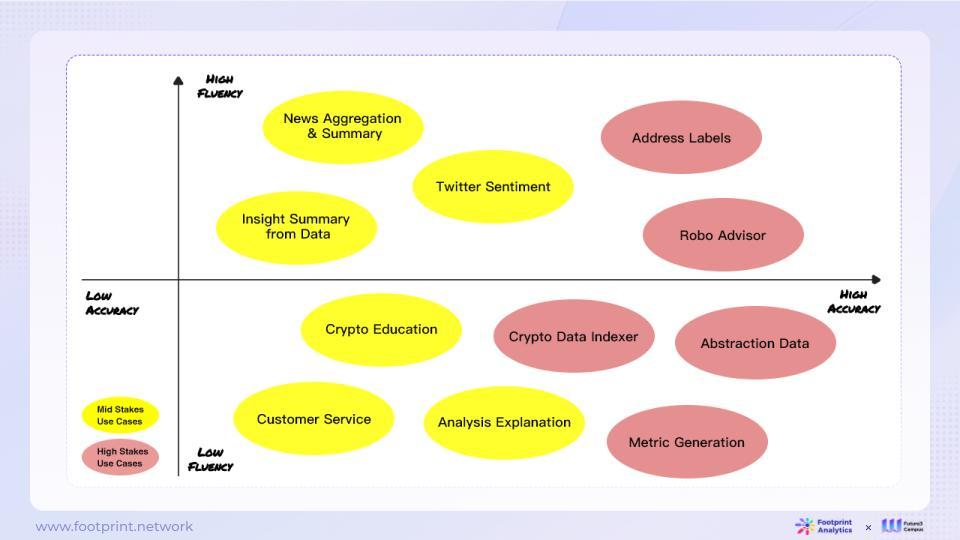
When evaluating the suitability of LLM in different applications, attention to fluency and accuracy is crucial. Fluency refers to whether the model's output is natural and smooth, while accuracy indicates whether the model's answers are correct. These two dimensions have different requirements in different application scenarios.
For tasks that require high fluency, such as natural language generation and creative writing, LLM is generally capable due to its strong natural language processing performance.
Blockchain data faces challenges in data parsing, processing, and application. LLM's excellent language understanding and reasoning capabilities make it an ideal tool for interacting with, organizing, and summarizing blockchain data. However, LLM cannot solve all the problems in the blockchain data domain.
In data processing, LLM is more suitable for rapid iteration and exploratory processing of on-chain data, continuously trying new processing methods. However, there are still limitations in detailed verification tasks in production environments. Typical issues include insufficient token length to handle long contexts, time-consuming prompts, unstable answer quality affecting downstream tasks, and inefficient execution of large-scale tasks.
Additionally, hallucination issues are likely to occur during the content processing by LLM. It is estimated that ChatGPT has a hallucination probability of approximately 15% to 20%, and due to the opacity of its processing, many errors are difficult to detect. Therefore, the establishment of frameworks and the integration of expert knowledge become crucial. Furthermore, there are many challenges when combining LLM with on-chain data:
- On-chain data entities are diverse and numerous, and how to effectively feed them to LLM for specific commercial scenarios, similar to other vertical industries, requires more research and exploration.
- On-chain data includes structured and unstructured data. Most industry data solutions are based on an understanding of business data. In the process of parsing on-chain data, using ETL to filter, clean, supplement, and restore business logic, further organizing unstructured data into structured data can provide more efficient analysis for various business scenarios in the future. For example, structured DEX trades, NFT marketplace transactions, wallet address portfolios, etc., possess high-quality, high-value, accurate, and authentic characteristics, which can provide efficient supplementation to general LLM.
4. Misunderstood LLM
4.1. Can LLM directly handle unstructured data, making structured data no longer needed?
LLM is typically pre-trained based on massive text data and naturally suitable for processing various unstructured text data. However, various industries already possess a large amount of structured data, especially in the Web3 domain after data parsing. How to effectively utilize this data to enhance LLM is a hot research topic in the industry.
Structured data still offers the following advantages for LLM:
Massive: A large amount of data is stored in various application databases and other standard formats, especially private data. Every company and industry still has a large amount of wall data that LLM has not been used for pre-training.
Existing: These data do not need to be reproduced, and the input cost is extremely low. The only issue is how to use them effectively.
High quality and high value: Long-term accumulated domain-specific knowledge, often embedded in structured data, is usually used for industry-academia research. The quality of structured data is crucial for data usability, including data integrity, consistency, accuracy, uniqueness, and factuality.
Efficiency: Structured data is stored in tables, databases, or other standardized formats, with predefined patterns and consistent throughout the dataset. This means that the format, type, and relationships of the data are predictable and controllable, making data analysis and queries simpler and more reliable. Additionally, the industry already has mature ETL and various data processing and management tools, making usage more efficient and convenient. LLM can utilize this data through APIs.
Accuracy and factuality: LLM's text data, based on token probability, currently cannot consistently output exact answers, and the core fundamental problem that LLM needs to address is the occurrence of hallucination problems. For many industries and scenarios, this can lead to security and reliability issues, such as in healthcare and finance. Structured data can assist in correcting these issues for LLM.
Reflecting the relationship graph and specific business logic: Different types of structured data can be input into LLM in specific organizational forms (relational databases, graph databases, etc.) to solve problems in different domains. The use of standardized query languages (such as SQL) for structured data makes complex querying and analysis more efficient and accurate. Knowledge graphs can better express the relationships between entities and make it easier to perform associative queries.
Low usage cost: LLM does not need to be retrained from the ground up every time, and it can be integrated with LLM empowerment methods such as Agents and LLM API to access LLM more quickly and at a lower cost.
There are still some far-fetched views in the market that believe LLM has extremely strong capabilities in handling textual information and unstructured information, and that simply importing raw data, including unstructured data, into LLM can achieve the desired results. This idea is similar to expecting a general-purpose LLM to solve math problems; without a specifically constructed mathematical ability model, most LLMs may make mistakes when dealing with simple elementary math problems. Instead, the practice of building vertical models like Crypto LLM, which are similar to mathematical ability models and image generation models, is the key to solving the practical application of LLM in the Crypto domain.
4.2. Can LLM infer content from news, Twitter, and other textual information, eliminating the need for on-chain data analysis to draw conclusions?
While LLM can obtain information from text sources such as news and social media, direct insights from on-chain data are still indispensable for several reasons:
- On-chain data is raw firsthand information, while information in news and social media may be one-sided or misleading. Direct analysis of on-chain data can reduce information bias. Although there is a risk of understanding bias when using LLM for text analysis, direct analysis of on-chain data can reduce misinterpretation.
- On-chain data contains comprehensive historical interactions and transaction records, enabling the discovery of long-term trends and patterns. On-chain data can also reveal the overall picture of the entire ecosystem, such as fund flows and relationships between parties. These macro insights contribute to a deeper understanding of the situation. News and social media information is often more fragmented and short-term.
- On-chain data is open. Anyone can verify the analysis results, avoiding information asymmetry. News and social media may not always disclose information accurately. Text information and on-chain data can be mutually verified. Integrating both can lead to more comprehensive and accurate judgments.
On-chain data analysis remains essential. While LLM's information retrieval from text sources plays a supportive role, it cannot replace direct analysis of on-chain data. Utilizing the strengths of both is necessary to achieve the best results.
4.3. Is it very easy to build blockchain data solutions based on LLM by using LangChain, LlamaIndex, or other AI tools?
Tools like LangChain and LlamaIndex provide convenience for building custom simple LLM applications, making rapid deployment possible. However, successfully applying these tools in actual production environments involves more challenges. Building an efficient and high-quality running LLM application is a complex task that requires a deep understanding of blockchain technology and the working principles of AI tools, and effective integration of them. This is an important but challenging task for the blockchain data industry.
In this process, it is essential to recognize the characteristics of blockchain data, which require high precision and verifiability. Once data is processed and analyzed by LLM, users have high expectations for its accuracy and credibility. There is a potential conflict between this and LLM's fuzzy fault tolerance. Therefore, when building blockchain data solutions, careful consideration of these two aspects is necessary to meet user expectations.
Although some basic tools are available in the market, this field is still rapidly evolving and continuously iterating. Similar to the development process in the Web2 world, from the initial PHP programming language to more mature and scalable solutions such as Java, Ruby, Python, JavaScript, Node.js, and emerging technologies like Go and Rust, AI tools are also constantly changing. Emerging GPT frameworks such as AutoGPT, Microsoft AutoGen, and the recent ChatGPT 4.0 Turbo from OpenAI, as well as GPTs and Agents, only demonstrate a part of the future possibilities. This indicates that there is still much room for development in the blockchain data industry and AI technology, requiring continuous effort and innovation.
There are two pitfalls to be particularly aware of when applying LLM:
- Unrealistic expectations: Many people believe that LLM can solve all problems, but in reality, LLM has clear limitations. It requires a large amount of computing resources, has high training costs, and the training process may be unstable. Realistic expectations of LLM's capabilities are necessary, understanding that it excels in some scenarios, such as natural language processing and text generation, but may not be suitable for other domains.
- Ignoring business needs: Another pitfall is forcibly applying LLM technology without fully considering business needs. Before applying LLM, specific business requirements must be clearly defined. It is necessary to evaluate whether LLM is the best technological choice and conduct risk assessment and control. Emphasizing the effective application of LLM requires careful consideration based on the actual situation to avoid misuse.
Although LLM has tremendous potential in many areas, developers and researchers need to be cautious and adopt an open exploratory attitude when applying LLM to find more suitable application scenarios and maximize its advantages.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






