Source: Quantum Bit

Image Source: Generated by Wujie AI
From design, coding, testing, deployment, and even operation and maintenance… the entire process of software development can now be handed over to AI!
An end-to-end AI intelligent assistant that covers the entire lifecycle of software development, making the scattered software development operations integrated and intelligent.
This AI assistant is specifically designed for the development field, avoiding issues such as unreliable general large models, untimely information, and incomplete domain tasks.

This AI assistant is named DevOps-ChatBot, developed by the Ant Codefuse project team. The installation process is simple and fast, and it can also be deployed with a single click through Docker.
For specific functions and performance of DevOps-ChatBot, please refer to the author's submission.
Addressing the Deficiencies of General Large Models
With the emergence of general large models such as ChatGPT and various vertical domain large models, the product interaction modes and user information acquisition modes in various fields are gradually changing.
However, DevOps has relatively high requirements for the accuracy of facts, timeliness of information, complexity of problems, and security of data. The problems of unreliable content generation, untimely information, and incomplete domain tasks with general large models have always existed.
Therefore, the Codefuse team initiated and open-sourced the DevOps-ChatBot end-to-end AI intelligent assistant, specifically designed for the entire lifecycle of software development:
- Using DevOps-specific knowledge base + knowledge graph enhancement + SandBox execution environment and other technologies to ensure the accuracy and timeliness of generated content, and allowing users to interactively modify code compilation and execution to ensure the reliability of answers;
- Using static analysis technology + RAG retrieval enhanced generation and other technologies to enable large models to perceive context, achieve component understanding at the code library level, modification and generation of code files at the repository project level, not just code completion at the function fragment level;
- Using comprehensive link-level Multi-Agent scheduling design, collaborative knowledge base, code library, tool library, and sandbox environment to enable large models to accomplish complex multi-step tasks in the DevOps domain;
- Using DevOps-specific domain models and evaluation data construction to support private deployment to ensure data security and high availability of specific tasks.
The Codefuse team hopes to gradually change the original development and operation habits, transforming from the traditional development and operation mode of querying information from various sources and operating on independent and scattered platforms to an intelligent development and operation mode of large model Q&A, making "there are no difficult coders in the world."
Five Core Modules
The overall architecture diagram of the DevOps-ChatBot project is as follows:
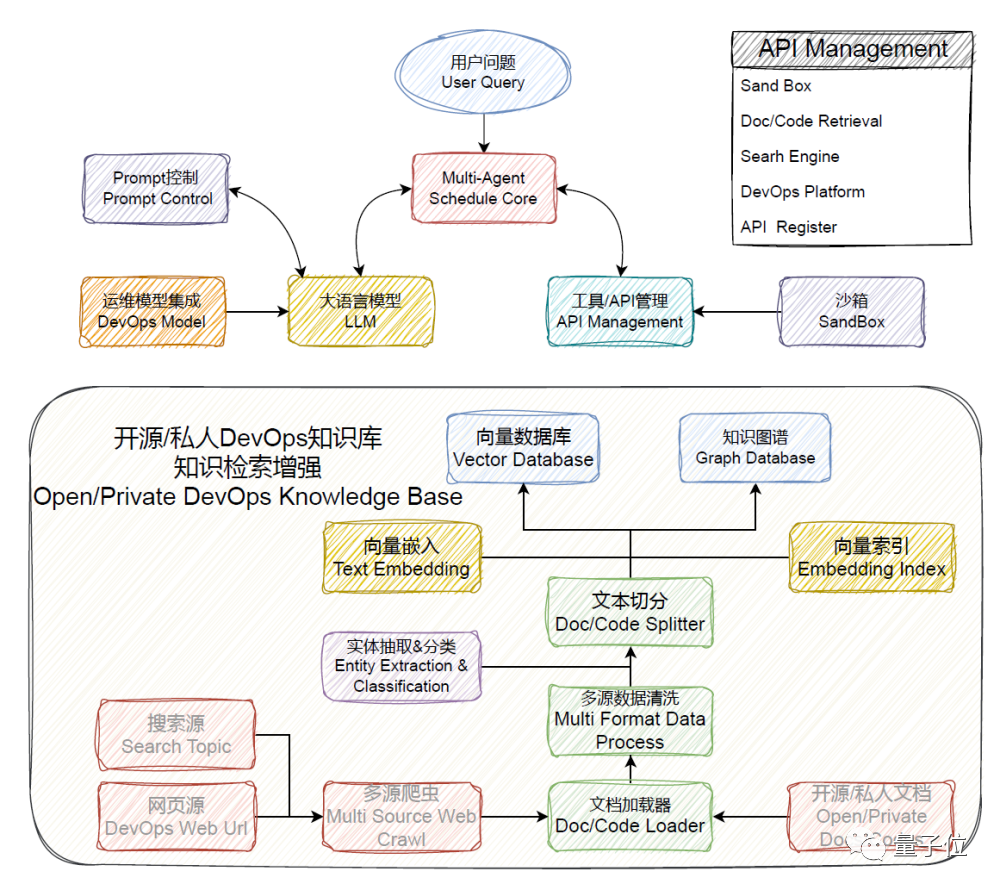
Specifically, it includes the following 9 functional modules:
- 🕷 Multi Source Web Crawl: Web crawler, providing the ability to crawl relevant information from specified URLs
- 🗂️ Data Process: Data processing module, providing document loaders, data cleaning, and text segmentation functions, processing and integrating data documents in multiple formats
- 🗄️ Text Embedding Index: Core document analysis, enabling document retrieval by uploading documents
- 📈 Vector Database & Graph Database: Vector database and graph database for data management
- 🧠 Multi-Agent Schedule Core: Multi-agent scheduling core, enabling the construction of required interactive agents through simple configuration
- 📝 Prompt Control: Prompt control and management module, defining the context management of agents
- 🚧 SandBox: Sandbox module, providing an environment for code compilation and execution
- 💬 LLM: Intelligent agent brain, supporting a range of open source models and LLM interfaces
- 🛠️ API Management: API management component, quickly compatible with related open source components and operation platforms
In addition to the assembly and coordination of the above functional modules, the DevOps-ChatBot project also has the following core differential technologies and features:
- Intelligent scheduling core: A comprehensive link-level scheduling core, multi-mode one-click configuration
- Whole repository code analysis: Repository-level code understanding, project file-level code writing and generation
- Enhanced document analysis: Document knowledge base combined with knowledge graph retrieval and enhanced reasoning
- Domain-specific knowledge: DevOps-specific knowledge base, self-service one-click construction of domain-specific knowledge base
- Domain model compatibility: DevOps domain small models, compatibility with DevOps peripheral platforms
Intelligent Scheduling Core
When dealing with complex problems, we can use the ReAct process to select, call, and execute tool feedback, achieving multi-round tool usage and multi-step execution.
However, for more complex scenarios, such as the development of complex code, a single LLM agent is inadequate.
The research team hopes to build a scalable and easy-to-use multi-agent framework that can assist in daily office work, data analysis, development and operation, and various general tasks through simple configuration.
The multi-agent framework of this project incorporates excellent designs from multiple frameworks, such as the message pool in metaGPT and the agent selector in autogen.
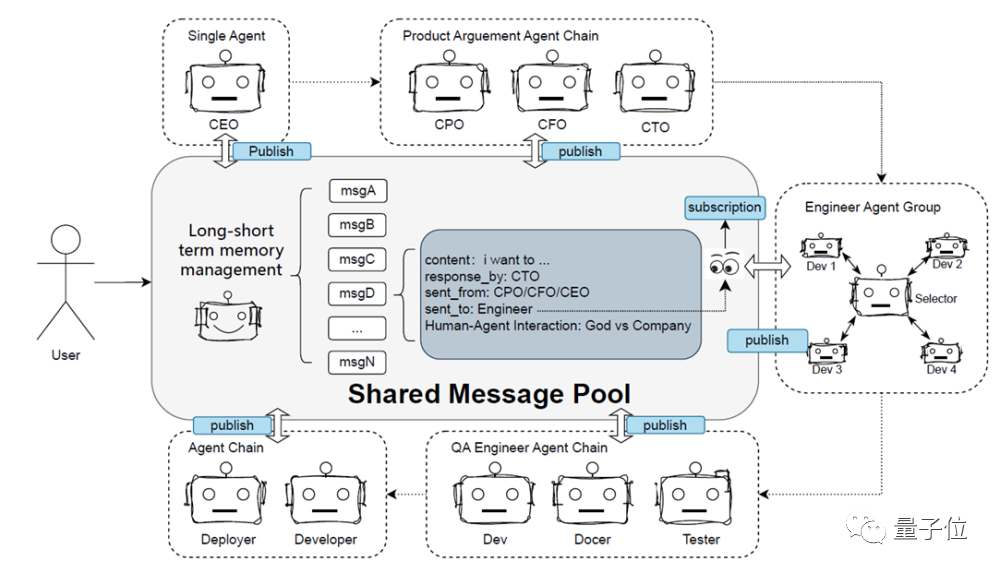
The core elements of the multi-agent framework in DevOps-ChatBot include the following 6 aspects:
- Agent Communication: Effective information exchange between agents is crucial for context management and improving question-and-answer efficiency. It includes two communication modes: a concise and intuitive chain dialogue and a message pool framework inspired by metaGPT.
- Standard Operation Process (SOP): Defines the input and output scope of agents and SOP identifiers, such as Tool, Planning, Coding, Answering, finished, and standardizes the parsing and processing of LLM-generated results.
- Plan and Executor: Enhances the use of large models, agent scheduling, and code generation.
- Long-short term memory Management: To simulate the collaboration process of human teams, a specialized agent responsible for content summarization (similar to a meeting assistant) is added to summarize and extract more effective information from long-term memory.
- Human-agent interaction: In complex scenarios, humans intervene in the interaction process with agents and provide feedback, enabling large models to accurately understand human intent and complete tasks more effectively.
- Prompt Control and Management: Responsible for coordinating and managing prompt interactions between agents, improving system complexity control and interaction efficiency. Input and output are structured using Markdown for clear and standardized result display, facilitating reading and parsing.
In actual operations, users can combine multiple agents to achieve a complete and complex project launch scenario (Dev Phase), such as the requirement chain (CEO), product demonstration chain (CPO, CFO, CTO), engineering group chain (selector, developer 1~N), deployment chain (developer, deployer), etc.
Whole Repository Code Analysis
Currently, large models are mainly used for code generation, repair, and component understanding tasks, facing the following challenges:
- Code training data lags behind, and frequent updates to open-source/private repositories result in untimely data information.
- Large models cannot perceive code context and code repository dependency structure.
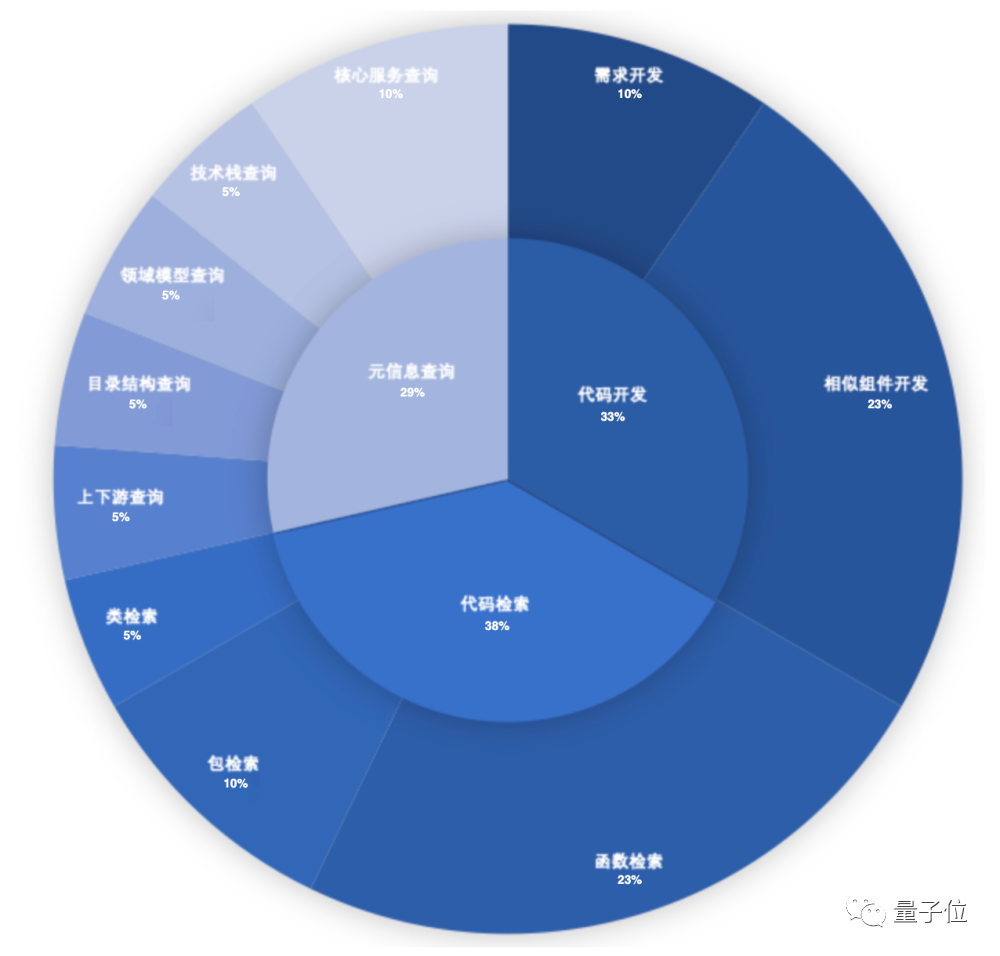
The research team has summarized the main problems encountered in development. From the following figure, it can be seen that understanding existing code libraries, dependency packages, code retrieval, and metadata queries take up more time during development:
To address these issues, the team uses program analysis to obtain the logical structure of the code and store it in a knowledge graph. Then, through RAG iterative queries, necessary contextual information is enhanced, combined with multi-agent role-playing, achieving an organic integration of large models and code libraries.
The overall framework for this part is as follows:
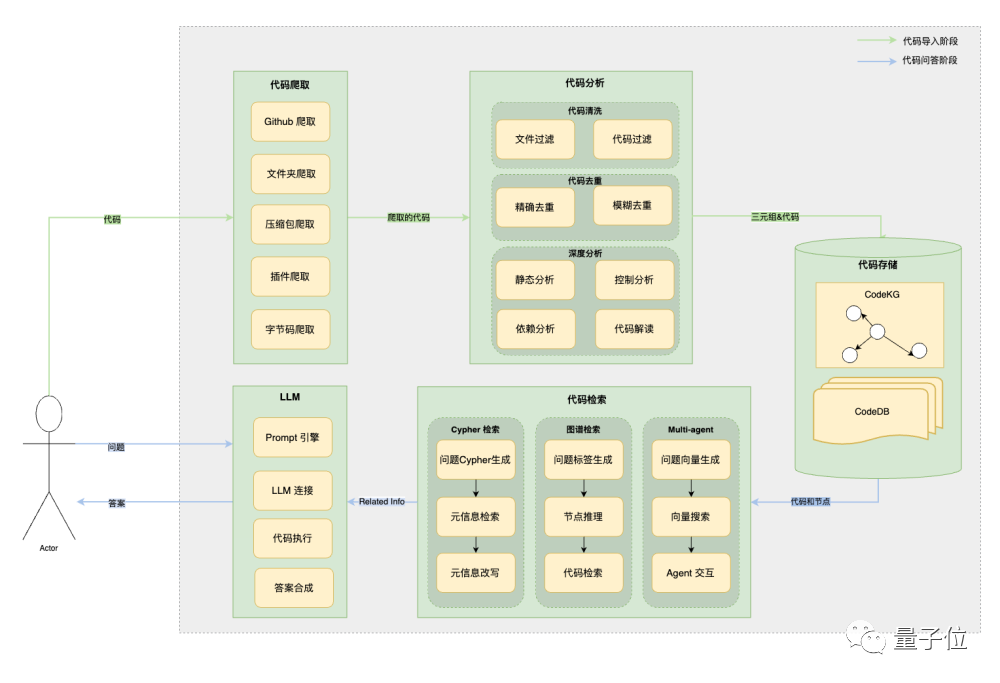
- Code Structure Analysis: Cleans and deduplicates valuable code sections from the original code. Then, through static analysis, it excavates the dependency graph between the codes in the code library. Additionally, it uses the understanding ability of large models to interpret the code, serving as an important supplement in the generated structured information graph.
- Code Retrieval Generation: Provides three different retrieval modes. Cypher retrieval generation is mainly for users to understand the code library structure (e.g., querying the number of classes, etc.), while graph retrieval is mainly for users to retrieve code when the question contains specific class and method names.
At the same time, the team is also exploring iterative code repository searches through multi-agent modes to obtain contextual information, while other agents are responsible for summarizing information and result generation in stages.
Enhanced Document Analysis
Large models are prone to generating unreliable answers when it comes to professional domain knowledge Q&A (e.g., medical, communication) and private knowledge Q&A (private domain data).
The most intuitive solution is to enhance the model's knowledge by training it with specific/private domain data, but training large models is costly.
Therefore, the research team chooses to enhance retrieval generation by retrieving data relevant to the question from the knowledge base and inputting it into the large model as additional knowledge. This ensures the reliability and timeliness of results while avoiding training costs.
The core issue to be addressed in this module is how to search more accurately. To this end, the research team has proposed the following architecture:
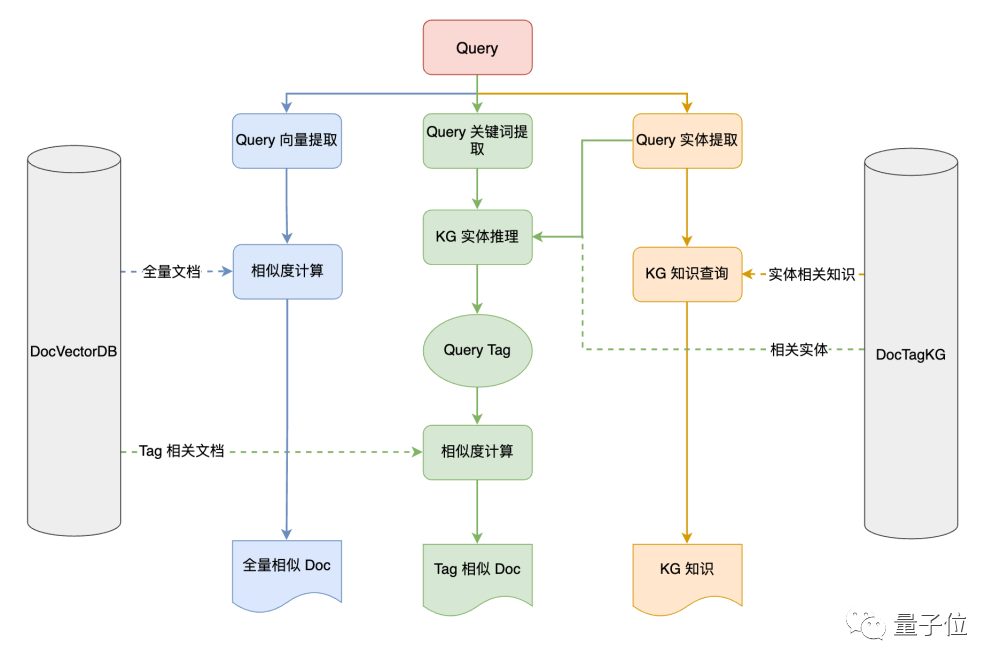
The entire DocSearch contains three retrieval pathways, and users can choose the retrieval pathway themselves or select all three to obtain different results.
- Traditional Document Vector Database Query: The document vector database is the most mainstream method for constructing knowledge bases. Using Text Embedding models to vectorize documents and store them in a vector database, this project can choose different retrieval strategies to extract corresponding knowledge from the knowledge base.
- Knowledge Graph Query: This project uses the Nebula graph database to store and manage the knowledge graph, supporting the import of existing knowledge graphs for knowledge retrieval. It also supports automatic extraction of entities and relationships by large models, uncovering various complex relationships in the data.
- Knowledge Graph Reasoning + Vector Data Query: This project also provides a fusion search of both. It first extracts tags for each document, combines the relevant tags in the user's question to construct related tags in the graph, and finally retrieves documents related to the original question based on the tag set in the document vector database.
Knowledge Base Construction and DevOps Knowledge Base
As mentioned earlier, the means of knowledge base outsourcing and enhanced retrieval generation can effectively solve the problem of proprietary/private domain knowledge Q&A. The next core issue is how to better construct the knowledge base.
When constructing a knowledge base, one often faces the following problems:
- Inconsistent formats and varying quality among different data sources
- How to automatically identify and eliminate erroneous, duplicate, or irrelevant data
- Knowledge base construction relies on professional knowledge
- Knowledge bases need regular updates to maintain the accuracy and timeliness of information
Based on this, the research team has proposed the following overall architecture:
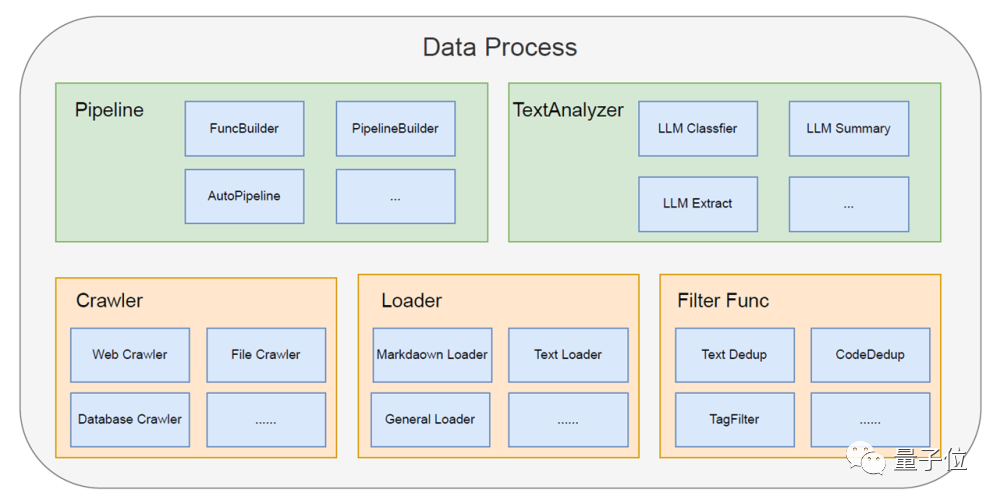
- Crawler: Implements data collection to ensure timely data updates.
- Loader: Imports heterogeneous data from multiple sources, flexibly addressing diverse data needs.
- Filter Func: Filters and cleans data to ensure the accuracy and efficiency of subsequent analysis.
- TextAnalyzer: Intelligently analyzes data, transforming complex text data into structured (including knowledge graph) and easily understandable information.
- Pipeline: Connects the entire process, achieving end-to-end automation from data input to clean output.
The research team will focus on data collection and construction in the DevOps domain, while also hoping to provide assistance for the standardized data acquisition, cleaning, and intelligent processing process for more private knowledge base construction.
Platform and Model Compatibility
With the emergence of Large Language Models (LLM), we have witnessed a transformation in problem-solving approaches, such as intelligent customer service systems shifting from relying on small-scale model fine-tuning and fixed rules to more flexible agent interactions.
The research team hopes to integrate and be compatible with surrounding open-source DevOps platforms, enabling conversational interaction-driven completion of specific tasks (data queries, container operations, etc.) through API registration, management, and execution.
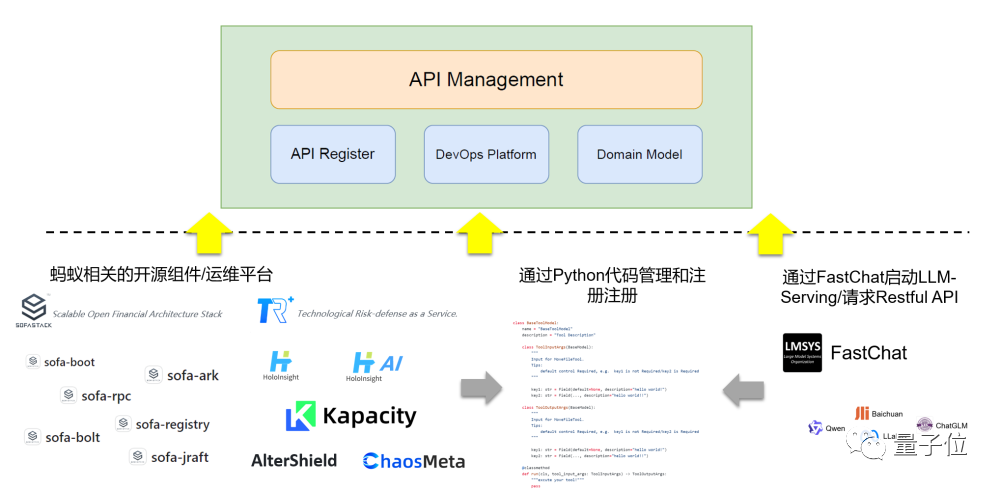
To quickly make this project compatible with related open-source components and operations platforms, we have created a BaseToolModel class template in Python. By defining properties and methods such as Toolname, Tooldescription, ToolInputArgs, ToolOutputArgs, and run, tools can be quickly integrated:
- By using FastChat to start the private model's reasoning service or other Restful-style APIs, such as Qwen2.0, Wenxin Yiyuan, etc., registration can be completed to enable scheduling for LLM.
- It is also possible to register APIs from Ant Group's related open-source projects and operations platforms to enable LLM to perform related operations through simple dialogue.
The currently encapsulated tool list includes: k-sigma anomaly detection, code retrieval, document retrieval, duckduckgo search, Baidu OCR recognition, stock information query, weather query, and time zone query.
Future Outlook
The DevOps framework is still in its early stages and there are many areas that need improvement. The research team plans to focus on the following core areas for future development:
- Multi-agent scheduling core: Automating the construction of agent chains
- Enhanced document analysis: Providing multiple correction methods and knowledge graph retrieval methods
- Whole repository code analysis: Refining code parsing and extraction functions, enriching code graph schema
- Knowledge base construction: Building knowledge base data for different vertical domains
- Platform & model compatibility: Integration with related open-source projects and operations platforms' APIs
Feature Showcase
Driven by these five core modules, DevOps-ChatBot has the following capabilities.
Firstly, there is text knowledge base management:
- Text loading, text vectorization service, and vector retrieval service for knowledge bases
- Providing functions for creating, managing, and downloading multiple knowledge bases
- Support for real-time URL content crawling using a web crawler
In addition to text knowledge bases, DevOps-ChatBot also supports the upload and management of knowledge graph and code knowledge base files.
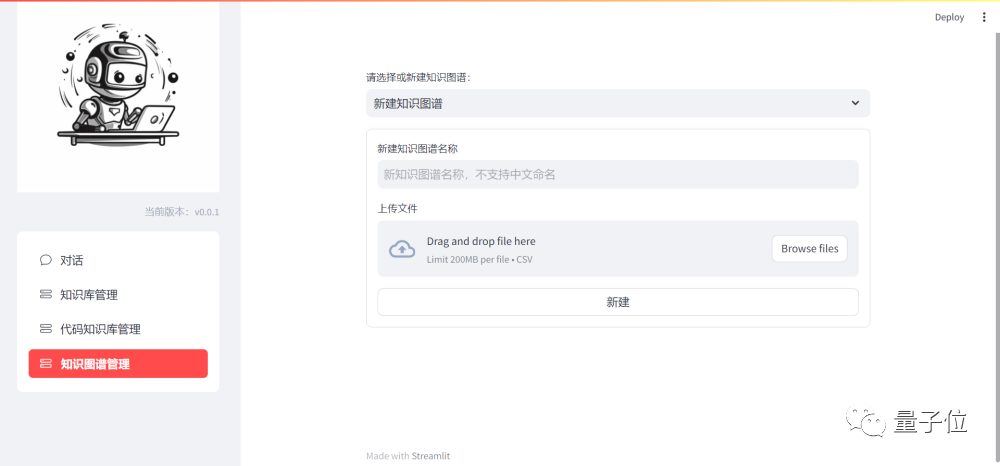
Furthermore, the development team has encapsulated some agent scenarios, such as chatPhase, docChatPhase, searchChatPhase, codeChatPhase, etc., to support knowledge base Q&A, code Q&A, tool invocation, code execution, and other functions.

In addition to application in DevOps, DevOps-ChatBot is also applicable in other domains!
Under the scheduling of multiple agents, DevOps-ChatBot can extend into many interesting applications.
The following applications can be built through the module assembly of this project:
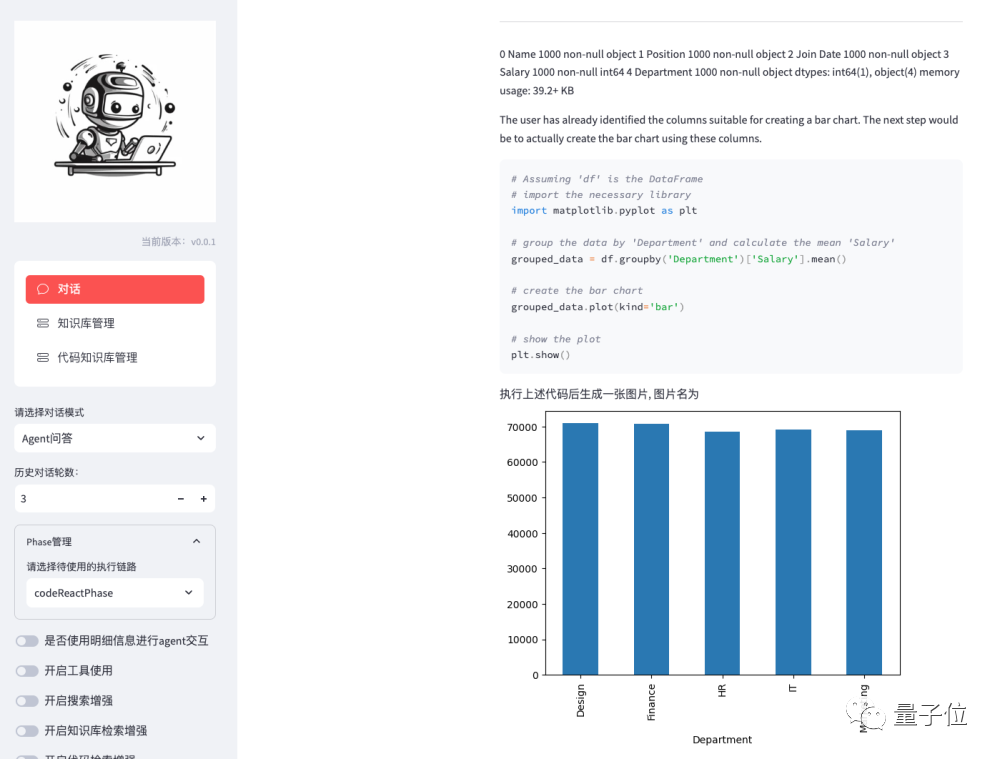
Code Interpreter
Simply upload a data file, and DevOps-ChatBot will automatically perform data analysis:
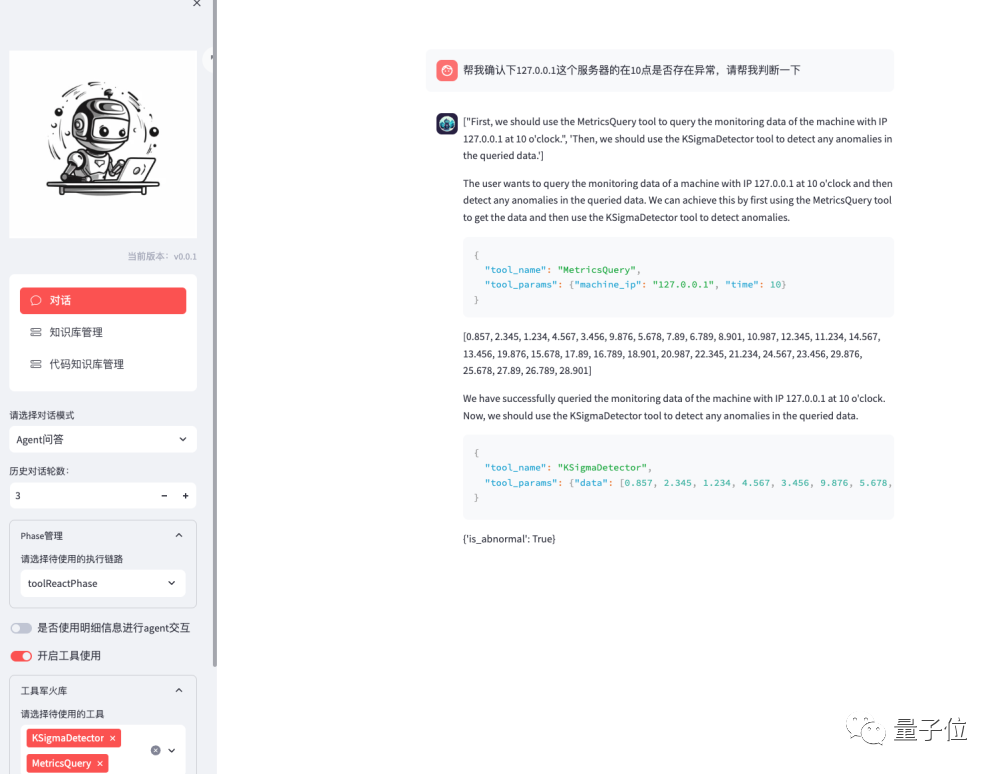
Tool Usage
For example: Querying the basic time series of a server, passing it to a monitoring tool, and performing analysis:
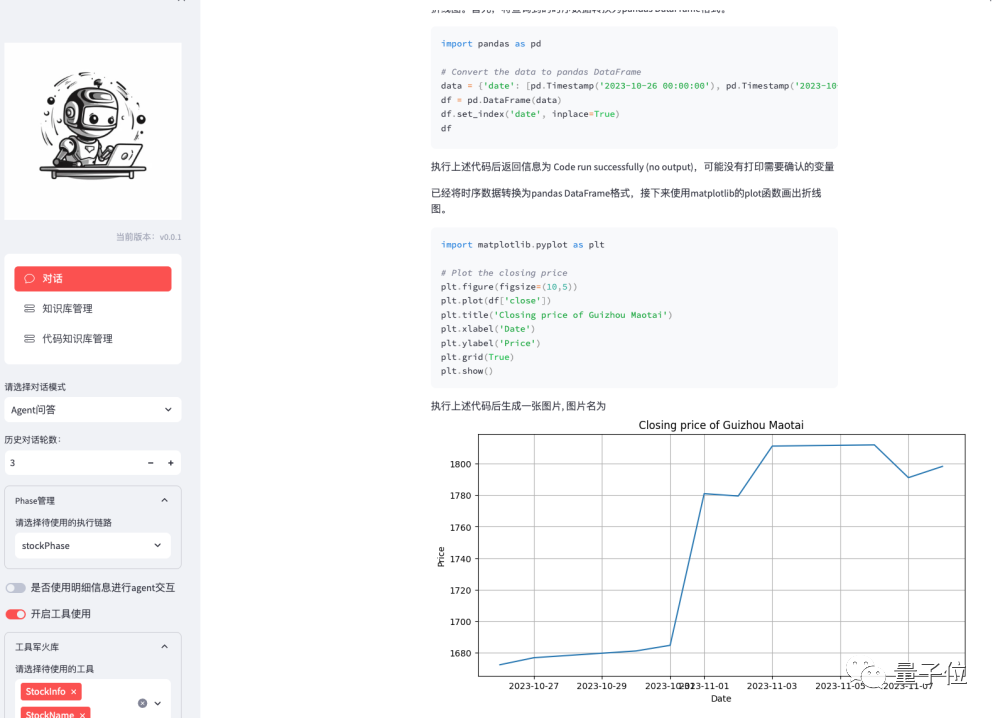
Intelligent Stock Analysis (Tool + Code Interpreter)
Users can obtain detailed information about specific stocks, including historical stock price charts, market performance, and potential market trends, through simple natural language queries.
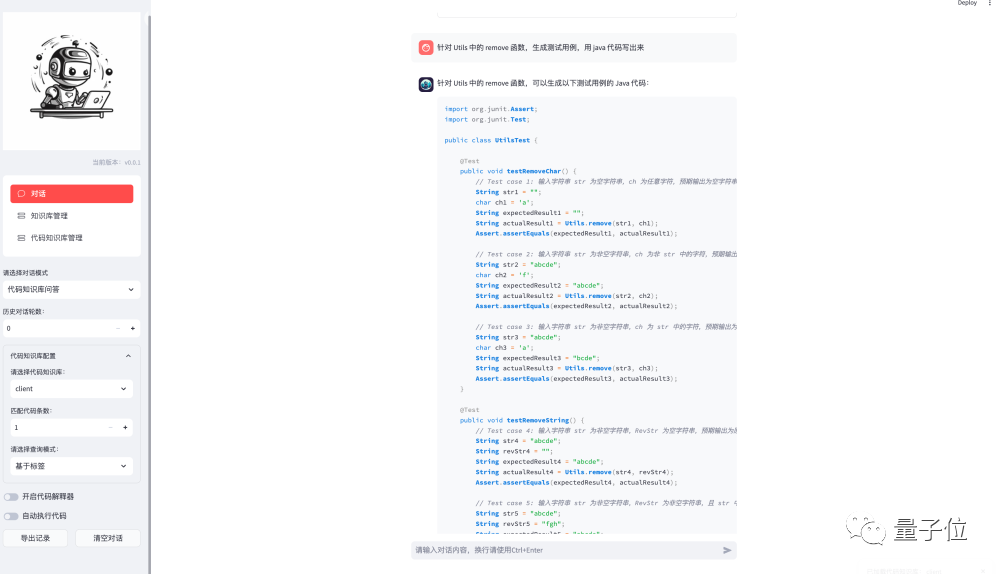
Generating Test Cases
DevOps-ChatBot can generate test cases for a method in the code repository.
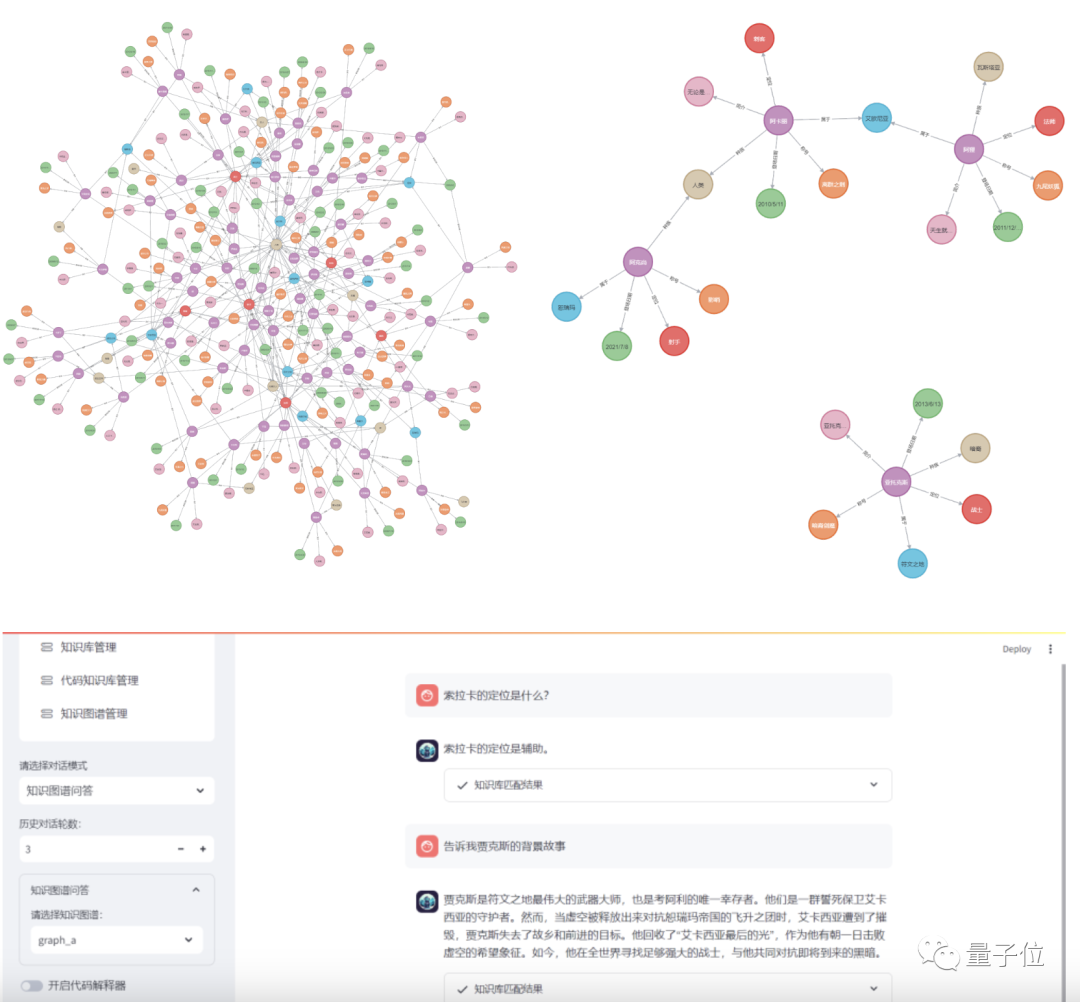
Player Savior (Knowledge Base Q&A)
In addition to these application scenarios, DevOps-ChatBot can also answer questions related to specific online games, including hero information, appearance times, and affiliated city-states.
For example: The knowledge graph of heroes in the game League of Legends
One More Thing
The Codefuse team has released an open-source project related to large models in the DevOps domain called DevOpsGPT, which is mainly divided into three modules, with DevOps-ChatBot being one of them in this article.
In addition to this, there are two other modules, DevOps-Model and DevOps-ChatBot, which are exclusive large models and intelligent assistants in the DevOps domain, respectively.
The team's goal is to truly integrate large models to improve efficiency and cost savings in the DevOps domain, including development, testing, operations, monitoring, and other scenarios.
The team hopes that practitioners in the field will contribute their expertise to make "there are no difficult coders in the world" a reality, and will also regularly share experiences and experiments in the LLM4DevOps domain.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。








