Blockchain provides a way to break the need for a single decision maker or arbitrator, as it can achieve consensus among large groups.
Video link: "Ben Fielding & Harry Grieve: Gensyn – The Deep Learning Compute Protocol"
Host: Dr. Friederike Ernst, Epicenter Podcast
Speakers: Ben Fielding & Harry Grieve, Co-founders of Gensyn
Edited & Translated by: Sunny, Deep Tide TechFlow
Blockchain AI computing protocol Gensyn announced on June 12th that it has completed a $43 million Series A financing led by a16z.
Gensyn's mission is to provide users with access to computing power equivalent to owning a private computing cluster, and it is crucial to achieve fair access, avoiding control or shutdown by any central entity. At the same time, Gensyn is a decentralized computing protocol focused on training machine learning models.
Looking back to the end of last year, Gensyn founders Harry and Ben's podcast with Epicenter delved into computing resource surveys, including AWS, local infrastructure, and cloud infrastructure, to understand how to optimize and utilize these resources to support the development of AI applications.
At the same time, they also discussed in detail the design concepts, goals, and market positioning of Gensyn, as well as the various constraints, assumptions, and execution strategies they faced in the design process.
The podcast introduced the four main roles in the Gensyn off-chain network, explored the characteristics of the Gensyn on-chain network, and the importance of Gensyn tokens and governance.
In addition, Ben and Harry also shared some interesting AI popular science to help everyone gain a deeper understanding of the basic principles and applications of artificial intelligence.

Blockchain as the trust layer for decentralized AI infrastructure
The host asked Ben and Harry why they decided to combine their rich experience in AI and deep learning with blockchain.
Ben stated that their decision was not made overnight, but over a relatively long period of time. Gensyn's goal is to build a large-scale AI infrastructure, and in researching how to achieve maximum scalability, they realized the need for a trustless layer.
They needed to integrate computing power without relying on centralized new vendor access, otherwise they would encounter administrative expansion limitations. To address this issue, they began exploring verifiable computing research, but found that this always required a trusted third party or judge to check the computation.
This limitation led them to turn to blockchain. Blockchain provides a way to break the need for a single decision maker or arbitrator, as it can achieve consensus among large groups.
Harry also shared his philosophy, expressing strong support for free speech and concern about censorship.
Before turning to blockchain, they were researching federated learning, a method where you train multiple models on distributed data sources and then combine them to create a meta-model that can learn from all data sources in the field of deep learning. They were working with banks on this approach. However, they quickly realized that the bigger issue was obtaining the computing resources or processors to train these models.
To maximize the integration of computing resources, they needed a decentralized coordination method, which is where blockchain comes into play.
Market computing resource survey: AWS, local infrastructure, and cloud infrastructure
Harry explained the different computing resource choices for running AI models, depending on the model's scale.
Students may use AWS or local machines, while startups may choose on-demand AWS or cheaper reserved options.
But for large-scale GPU demands, AWS may be limited by cost and scalability, and organizations often choose to build internal infrastructure.
Research shows that many organizations are striving to scale up, with some even choosing to purchase and manage GPUs themselves. Overall, purchasing GPUs seems to be more cost-effective in the long run than running on AWS.
The choice of machine learning computing resources includes cloud computing, running AI models locally, or building their own computing clusters. Gensyn's goal is to provide access to computing power equivalent to owning a private cluster, and crucially, to achieve fair access that cannot be controlled or shut down by any central entity.

Discussion of Gensyn's design concepts, goals, and market positioning
The host asked how Gensyn differs from previous blockchain computing projects, such as Golem Network.
Harry explained that Gensyn's design concept is mainly considered along two axes:
- The sophistication of the protocol: Unlike general computing protocols like Golem, Gensyn is a fine-grained protocol focused on training machine learning models.
- Scalability of verification: Early projects often relied on reputation or less tolerant Byzantine fault-tolerant replication, which did not provide enough confidence for machine learning results. Gensyn aims to leverage the learning experience of cryptographic protocols and apply it specifically to machine learning to optimize speed and cost, while ensuring a satisfactory level of verification.
Harry added that when considering the properties the network must have, it needs to be tailored to machine learning engineers and researchers. It needs to have a verification part, but crucially, in terms of allowing anyone to participate, it needs to be resistant to censorship and neutral to hardware.
Constraints, assumptions, and execution in the design process
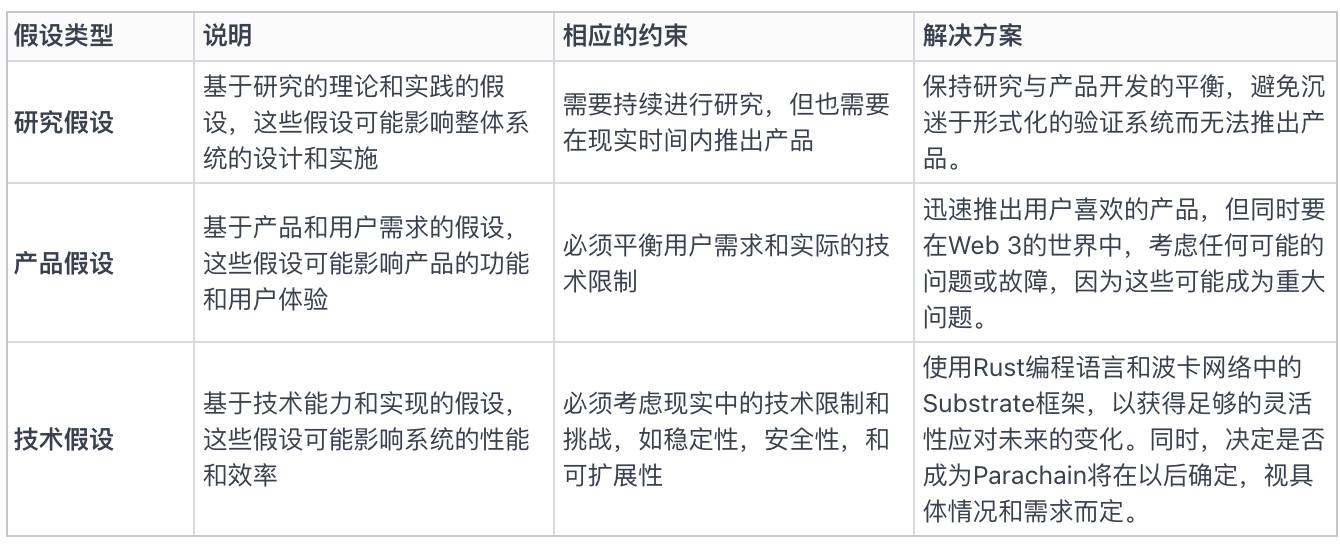
In the design process of Gensyn's platform, Ben emphasized the importance of system constraints and assumptions. Their goal is to create a network that can transform the entire world into an AI supercomputer, and for this, they need to find a balance between product assumptions, research assumptions, and technical assumptions.
As for why they built Gensyn as their own first-layer blockchain, their reason was to maintain greater flexibility and decision-making freedom in key technological areas such as consensus mechanisms. They hope to be able to prove their protocol in the future and do not want to impose unnecessary restrictions in the early stages of the project. In addition, they believe that in the future, various chains will be able to interact through a widely accepted information protocol, so their decision also aligns with this vision.
The four main roles in the Gensyn off-chain network
In this Gensyn economic discussion, four main roles were introduced: submitters, workers, validators, and reporters. Submitters can submit various tasks to the Gensyn network, including generating specific images or developing AI models that can drive cars.
Submitter submits tasks
Harry explained how to use Gensyn to train models. Users first define the desired outcome, such as generating images based on text prompts, and then build a model that takes the text prompts as input and generates the corresponding images. Training data is crucial for the model's learning and improvement. Once the model architecture and training data are prepared, users submit them to the Gensyn network along with hyperparameters such as learning rate schedules and training duration. The result of this training process is the trained model, which users can host and use.
When asked about how to choose untrained models, Harry proposed two methods.
The first is based on the concept of popular base models, where large companies like OpenAI or Midjourney build base models, and users can then train these base models with specific data.
The second option is to build the model from scratch, different from the base model approach.
In Gensyn, developers can use methods similar to evolutionary optimization to submit various architectures for training and testing, continuously optimizing to build the desired model.
Ben provided a deep perspective on base models from their point of view, believing it to be the future of the field.
As a protocol, Gensyn hopes to be used by DApps implementing evolutionary optimization techniques or similar methods. These DApps can submit individual architectures to the Gensyn protocol for training and testing, building the ideal model through iterative refinement.
Gensyn aims to provide a pure machine learning computing foundation, encouraging the development of an ecosystem around it.
While pre-trained models may introduce bias, as organizations may use proprietary datasets or conceal training process information, Gensyn's solution is to open up the training process rather than eliminate the black box or rely on full determinism. By collectively designing and training base models, we can create global models without bias from any specific company's dataset.
Worker (Solver)
For task allocation, one task corresponds to one server. However, a model may be split into multiple tasks.
Large language models are designed to fully utilize the maximum hardware capacity available at the time. This concept can be extended to the network, considering the heterogeneity of devices.
For specific tasks, such as validators or workers, they can choose to take on tasks from the Mempool. From those who express willingness to take on the task, a worker is randomly selected. If the model and data cannot fit a specific device, but the device owner claims it can, fines may occur due to system congestion.
Whether a task can run on a machine is determined by a verifiable random function, which selects a worker from the available worker subset.
Regarding verifying worker capabilities, if a worker does not claim the computational power they have, they will not be able to complete the computational task, which will be detected when submitting proof.
However, task size is a concern. If tasks are set too large, it may lead to system issues, such as denial of service attacks (DoS), where workers claim to complete tasks but never do, wasting time and resources.
Therefore, determining task size is crucial, taking into account factors such as parallelization and optimizing task structure. Researchers are actively studying and exploring the best methods based on various constraints.
Once the test network is launched, real-world observations will be considered to observe the system's operation in the real world.
Defining the perfect task size is challenging, and Gensyn is prepared to adjust and improve based on real-world feedback and experience.
Verification mechanism and checkpoints for on-chain large-scale computing
Harry and Ben indicated that verifying the correctness of computational tasks is a significant challenge, as it does not have determinism like a hash function, so it cannot be simply verified through hashing. The ideal solution is to apply zero-knowledge proofs to the entire computation process. Currently, Gensyn is working to achieve this capability.
Currently, Gensyn has introduced a hybrid approach using checkpoints to verify machine learning computations through probabilistic mechanisms and checkpoints. By combining random audit schemes and gradient space paths, a relatively robust check can be established. Additionally, zero-knowledge proofs have been introduced to enhance the verification process and are applied to the global loss of the model.
Verifier and Whistleblower
The host and Harry discussed two additional roles involved in the verification process: Verifier and Whistleblower. They detailed the specific responsibilities and roles of these two positions.
The Verifier's task is to ensure the correctness of checkpoints, while the Whistleblower's task is to ensure the accuracy of the Verifier's performance. The Whistleblower addresses the Verifier's dilemma, ensuring the Verifier's work is correct and trustworthy. The Verifier intentionally introduces errors in their work, and the Whistleblower's role is to identify and expose these errors, ensuring the integrity of the verification process.
The Verifier intentionally introduces errors to test the vigilance of the Whistleblower and ensure the effectiveness of the system. If there are errors in the work, the Verifier detects them and notifies the Whistleblower. The errors are then recorded on the blockchain and verified on-chain. Regularly, and at a rate related to the security of the system, the Verifier intentionally introduces errors to maintain the Whistleblower's engagement. If the Whistleblower identifies issues, they participate in a game called the "pinpoint protocol," through which they can narrow down the computation to a specific point in the Merkle tree of the neural network. This information is then submitted for on-chain arbitration. This is a simplified version of the Verifier and Whistleblower process, with further development and research to be conducted after the seed round.
On-chain network of Gensyn
Ben and Harry discussed in detail how the Gensyn coordination protocol works on-chain and the implementation details. They first mentioned the process of building network blocks, which involves staking tokens as part of the staking network. They then explained the relationship of these components to the Gensyn protocol.
Ben explained that the Gensyn protocol is largely based on the vanilla substrate Polkadot network protocol. They adopt the Grandpa Babe consensus mechanism based on proof of stake, and validators operate in the usual way. However, all the machine learning components previously introduced are conducted off-chain, involving various off-chain participants performing their respective tasks.
These participants are incentivized through staking, which can be done through the staking pallet in Substrate or by staking a specific amount of tokens in a smart contract. When their work is eventually verified, they receive rewards.
Challenges mentioned by Ben and Harry include balancing the staking amount, potential slashing, and reward amounts to prevent incentives for laziness or malicious behavior.
Additionally, they discussed the complexity that adding whistleblowers would bring, but their presence is crucial for ensuring the honesty of validators due to the demand for scalable computing. While they continue to explore ways to potentially eliminate whistleblowers through zero-knowledge proof technology. They stated that the current system aligns with the lite paper description, but they are actively working to simplify every aspect.
When asked if they have a solution for data availability, Henry explained that they have introduced a layer called proof of availability (POA) on top of substrate. This layer uses techniques such as erasure coding to address the limitations they encounter in the widespread storage layer market. They expressed great interest in developers who have already implemented such a solution.
Ben added that their needs involve not only storing training data but also intermediate proof data, which does not need to be stored long-term. For example, they may only need to retain it for about 20 seconds upon the completion of a specific number of block releases. However, the storage fees they currently pay on Arweave cover a range of hundreds of years, which is unnecessary for these short-term needs. They are looking for a solution that combines the guarantees and functionality of Arweave with lower costs to meet short-term storage needs.
Gensyn Tokens and Governance
Ben explained the importance of the Gensyn token in the ecosystem, playing a crucial role in staking, penalties, providing rewards, and maintaining consensus. Its primary purpose is to ensure the financial soundness and integrity of the system. Ben also mentioned the cautious use of inflation rates to pay validators and the use of game theory mechanisms.
He emphasized the purely technical use of the Gensyn token and stated that they would ensure the timing and necessity of introducing the Gensyn token from a technical standpoint.
Harry stated that they are a minority in the deep learning community, especially under the widespread skepticism of AI scholars regarding cryptocurrencies. Nevertheless, they recognize the value of cryptocurrency in both technological and ideological aspects.
However, at the launch of the network, they expect that the majority of deep learning users will primarily use fiat currency for transactions, and the conversion to tokens will seamlessly occur behind the scenes.
In terms of supply, workers and submitters will actively participate in token transactions, and they have received interest from Ethereum miners who have a large amount of GPU resources and are seeking new opportunities.
It is important to ensure the elimination of fear of cryptocurrency terms (such as tokens) among deep learning and machine learning practitioners and to separate them from the user experience interface. Gensyn sees this as an exciting use case that connects the worlds of Web 2 and Web 3, as it has economic rationality and the necessary technological support for its existence.
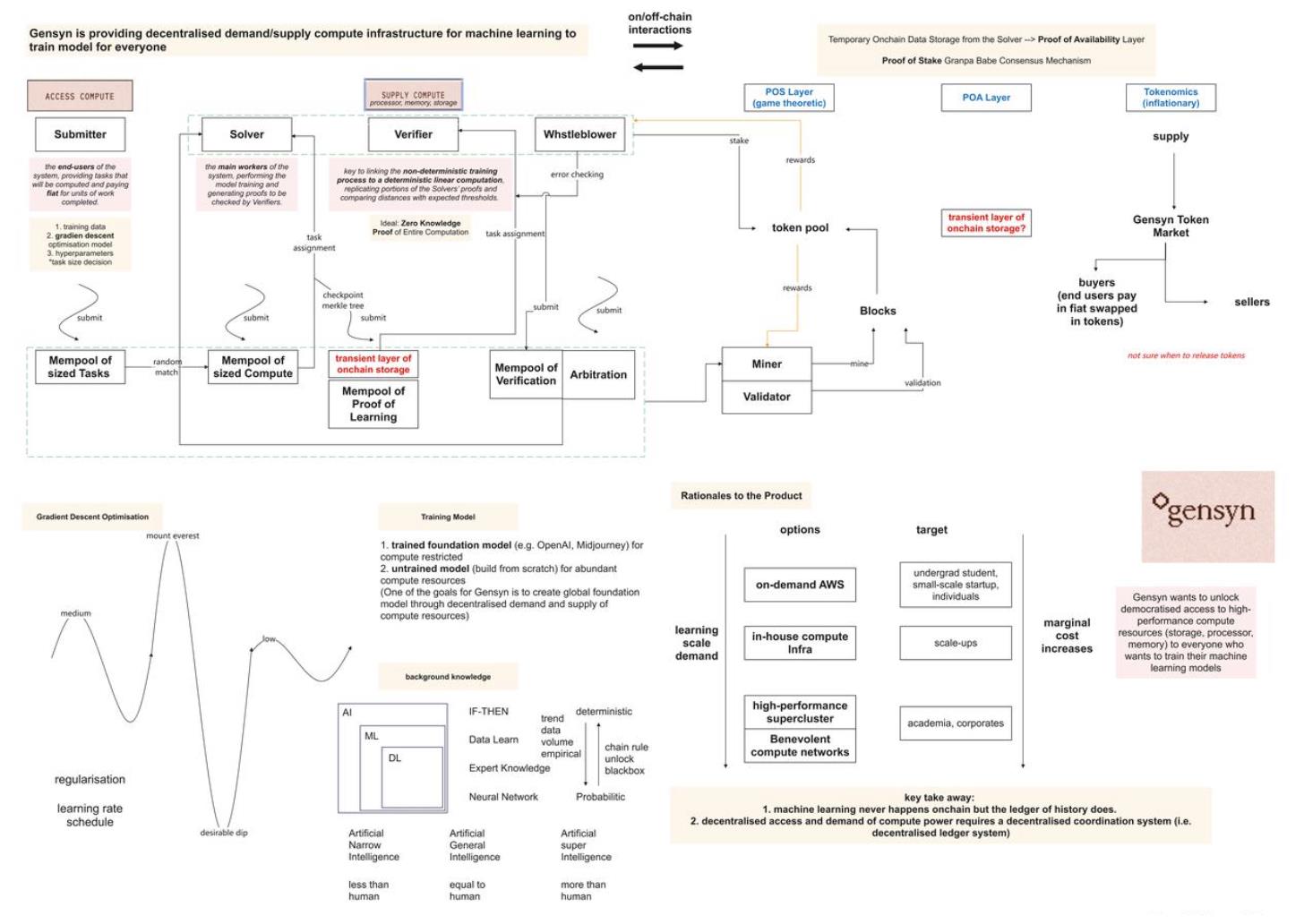
Figure 1: Operational mode of the Gensyn on-chain and off-chain network based on the podcast, if there are any errors in the operation mechanism, please provide feedback in a timely manner (Image source: Deep Tide)
Educating on Artificial Intelligence
AI, Deep Learning, and Machine Learning
Ben shared his views on the recent developments in the AI field. He believes that despite a series of small explosions in the AI and machine learning field over the past seven years, the current progress seems to be creating real impact and valuable applications that resonate with a broader audience. Deep learning is the fundamental driving force behind these changes. Deep neural networks have demonstrated their ability to surpass the benchmarks set by traditional computer vision methods. Additionally, models like GPT-3 have accelerated this progress.
Harry further explained the differences between AI, machine learning, and deep learning. He believes that these three terms are often used interchangeably, but they have significant differences. He likened AI, machine learning, and deep learning to Russian nesting dolls, with AI being the outermost layer.
- Broadly speaking, AI refers to programming machines to perform tasks.
- Machine learning, which became popular in the 1990s and early 2000s, uses data to determine the probability of decisions, rather than relying on expert systems with if-then rules.
- Deep learning builds on machine learning but allows for more complex models.
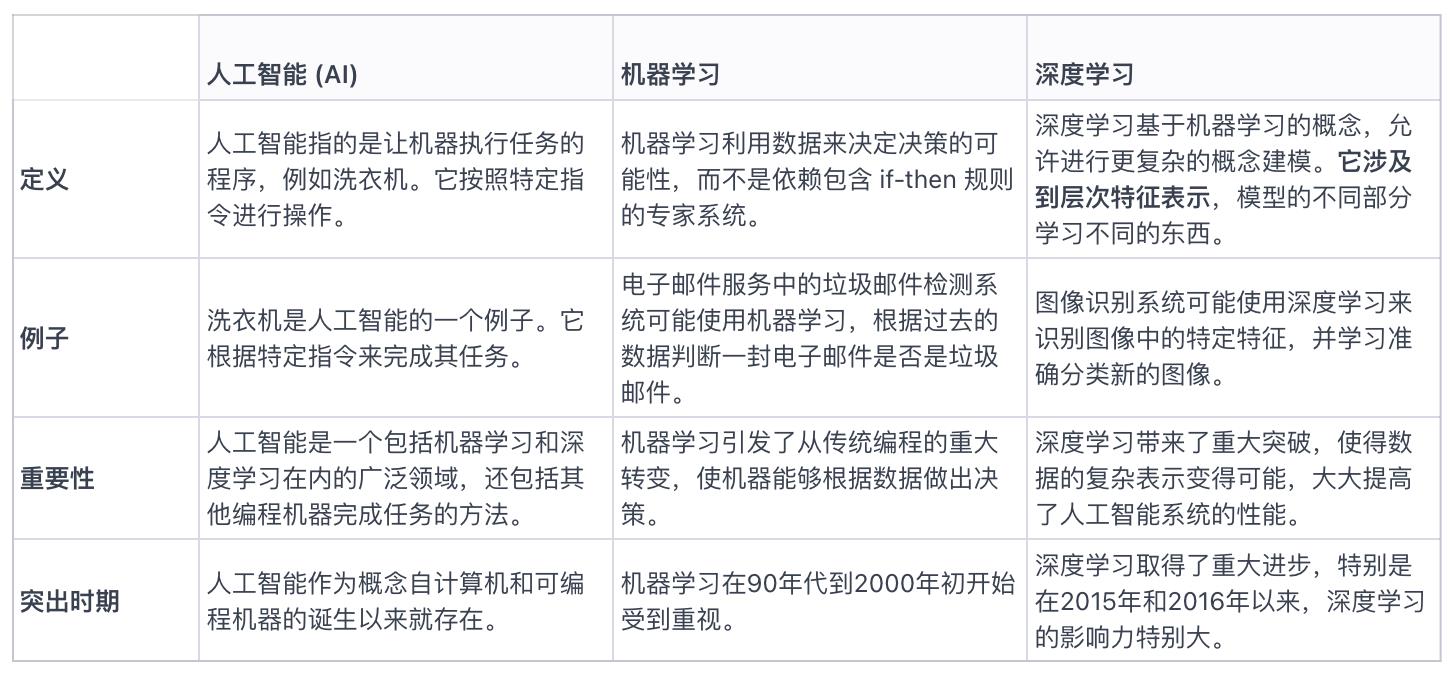
Figure 3: Differences between Artificial Intelligence, Machine Learning, and Deep Learning
Narrow AI, General AI, and Super AI
In this section, the host and guests delved into three key areas of artificial intelligence: Narrow AI (ANI), General AI (AGI), and Super AI (ASI).
- Narrow AI (Artificial Narrow Intelligence, ANI): Current artificial intelligence mainly operates in this stage, where machines are very good at performing specific tasks, such as detecting specific types of cancer from medical scans through pattern recognition.
- General AI (Artificial General Intelligence, AGI): AGI refers to machines being able to perform relatively simple tasks for humans but are challenging to reflect in computational systems. For example, enabling machines to navigate smoothly in crowded environments while making discrete assumptions about all the inputs around them is an example of AGI. AGI refers to models or systems that can perform daily tasks like humans.
- Super AI (Artificial Super Intelligence, ASI): After achieving General AI, machines may further develop into Artificial Super Intelligence. This refers to machines surpassing human capabilities due to the complexity of their models, increased computational power, unlimited lifespan, and perfect memory. This concept is often explored in science fiction and horror movies.
Additionally, the guests mentioned that the fusion of the human brain with machines, such as through brain-machine interfaces, may be a pathway to achieving AGI, but it also raises a series of ethical and moral issues.
Unraveling the Black Box of Deep Learning: Determinism vs. Probability
Ben explained that the black box nature of deep learning models is attributed to their absolute size. You are still tracking a path through a series of decision points in the network. It's just that this path is very large, making it difficult to connect the weights or parameters inside the model to their specific values, as these values are derived after inputting millions of samples. You can do this deterministically, tracking every update, but the amount of data you end up generating will be very large.
He sees two things happening:
As our understanding of the models being built increases, the nature of the black box is gradually disappearing. Deep learning is a research field that has gone through an interesting rapid period, conducting a lot of experiments that are not driven by the fundamentals of research. Instead, it's more about seeing what we can get from it. So, we put more data into it, try new architectures, just to see what happens, rather than designing this thing from first principles and knowing exactly how it works. So, there's this exciting period where everything is a black box. But he believes this rapid growth is starting to slow down, and we are seeing people re-examine these architectures and say, "Why is this effect so good? Let's delve into it and prove it." So, to some extent, this curtain is being lifted.
The other thing that may be more controversial is the shift in people's views on whether computational systems need to be entirely deterministic or if we can live in a world of probability. We as humans live in a world of probability. An example might be autonomous vehicles, where we accept that random events may occur while driving, there may be minor accidents, or the autonomous driving system may have issues. But we cannot fully accept this; we say it must be a completely deterministic process. One of the challenges in the autonomous driving industry is that they assume people will accept probabilistic mechanisms applied to autonomous vehicles, but in reality, people do not accept it. He believes this situation will change, and the controversial aspect is whether we as a society will allow probabilistic computing systems to coexist with us. He is not sure if this path will be smooth, but he believes it will happen.
Gradient Optimization: Core Optimization Method of Deep Learning
Gradient optimization is one of the core methods of deep learning and plays a crucial role in training neural networks. In neural networks, a series of layer parameters are essentially real numbers. Network training involves setting these parameters to allow data to pass through correctly and trigger the actual values expected at the end stage of the network.
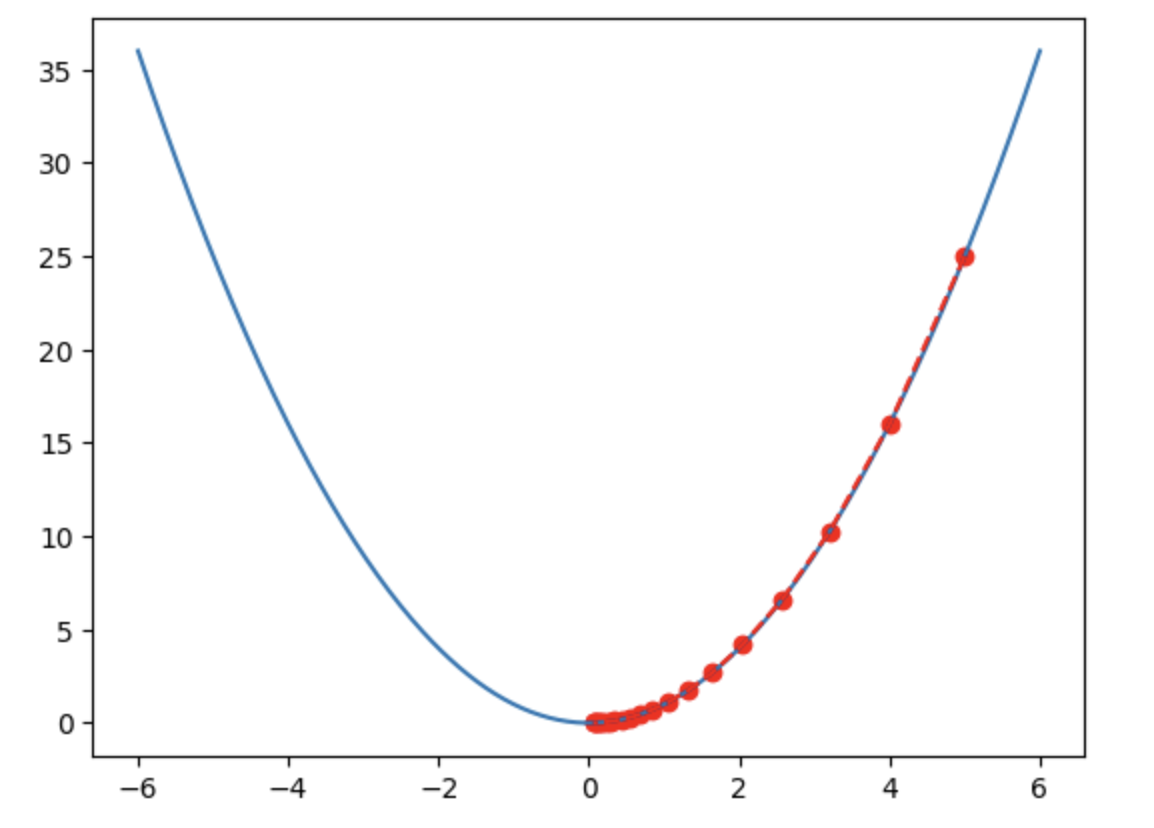
Based on the gradient-based optimization methods, there has been a significant revolution in the field of neural networks and deep learning. This method uses gradients, which are the derivatives of the network's layer parameters with respect to the error. By applying the chain rule, the gradients can be backpropagated throughout the entire hierarchical network. In this process, you can determine your position on the error surface. The error can be modeled as a surface in Euclidean space, which appears as an undulating area filled with highs and lows. The goal of optimization is to find the region that minimizes the error.
The gradient for each layer shows your position on this surface and the direction in which you should update the parameters. You can navigate on this undulating surface using the gradient to find the direction that reduces the error. The size of the step depends on the steepness of the surface. If it is steep, you will jump farther; if it is not steep, you will jump smaller. Essentially, you are navigating on this surface, looking for a trough, and the gradient helps you determine the position and direction.
This method is a breakthrough because the gradient provides a clear signal and useful direction. Compared to random jumps in parameter space, it can more effectively guide you to know where you are on the surface and whether you are on a peak, in a valley, or in a flat area.
Although there are many techniques in deep learning to solve the problem of finding the optimal solution, the real-world situation is often more complex. Many regularization techniques used in deep learning training make it more of an art than a science. This is why gradient-based optimization in practical applications is more like art than precise science.
Summary
Gensyn's goal is to build the world's largest machine learning computing resource system, leveraging idle or underutilized computing resources such as personal smartphones, computers, and other devices.
In the context of machine learning and blockchain, the records stored in the ledger are usually the computed results, i.e., the data states that have been processed through machine learning. This state can be expressed as: "I have already machine-learned this wave of data, it is valid, and it occurred at time X year X month." The main goal of this record is to express the result state, rather than detailing the computation process.
In this framework, blockchain plays an important role:
- Blockchain provides a way to record data state results. Its design can ensure the authenticity of data, prevent tampering, and repudiation.
- Blockchain has economic incentive mechanisms that can coordinate the behavior of different roles in the computing network, such as the four mentioned roles: submitters, workers, validators, and reporters.
- Through an investigation of the current cloud computing market, it is found that cloud computing is not without its merits, but various computing methods have their specific problems. Decentralized computing methods of blockchain can play a role in some scenarios, but cannot completely replace traditional cloud computing. In other words, blockchain is not a universal solution.
- Finally, AI can be seen as a means of production, but how to effectively organize and train AI belongs to the category of production relations. This includes factors such as cooperation, crowdsourcing, and incentives. In this regard, Web 3.0 provides a wealth of possible solutions and scenarios.
Therefore, we can understand that the combination of blockchain and AI, especially in data and model sharing, coordination of computing resources, and result verification, provides new possibilities for solving some problems in the training and use of AI.
References:
- https://docs.gensyn.ai/litepaper/
- https://a16zcrypto.com/posts/announcement/investing-in-gensyn/
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







