Source: Synced

Image Source: Generated by Wujie AI
Currently, the open-source QY1000 suite has released four basic open-source models with parameter sizes of 1.8 billion, 7 billion, 14 billion, and 72 billion, as well as multiple open-source models across languages, images, and speech modalities.
"A Qwen-72B model will be released on November 30th." A few days ago, a netizen on X platform posted such a message, citing a conversation. He also said, "If (the new model) is as amazing as their 14B model, it will be remarkable."
The 14B model in this sentence refers to the QY1000 14 billion parameter model Qwen-14B released by Alibaba Cloud in September. At that time, this model surpassed equivalent-scale models in multiple authoritative evaluations, and some indicators even approached Llama2-70B. It was very popular in the domestic and international developer communities. In the following two months, developers who had used Qwen-14B would naturally be curious and expectant about larger models.
It seems that developers in Japan are also looking forward to it.
As mentioned in the message, on November 30th, Qwen-72B was open-sourced. It single-handedly brought the overseas developers who follow open-source dynamics into the Hangzhou time zone.
Alibaba Cloud also announced many details at today's press conference.
From the performance data, Qwen-72B did not disappoint everyone's expectations. In 10 authoritative benchmark evaluations such as MMLU and AGIEval, Qwen-72B achieved the best results among open-source models, becoming the most powerful open-source model, even surpassing the open-source benchmark Llama 2-70B and most commercial closed-source models (some results surpassing GPT-3.5 and GPT-4).
Before this, the Chinese large model market had not produced high-quality open-source large models that could compete with Llama 2-70B. Qwen-72B filled this gap. After this, domestic large and medium-sized enterprises can develop commercial applications based on its powerful reasoning capabilities, and universities and research institutes can use it for research work such as AI for Science.
In addition, a small model was also released together — Qwen-1.8B, and an audio model Qwen-Audio. Qwen-1.8B and Qwen-72B, one small and one large, together with the previously open-sourced 7B and 14B models, form a complete open-source spectrum suitable for various application scenarios. Qwen-Audio, together with the previously open-sourced visual understanding model Qwen-VL and basic text models, forms a multimodal spectrum that can help developers extend the capabilities of large models to more real environments.
The smallest open-source model Qwen-1.8B of QY1000 can infer 2K-length text content with only 3G of video memory. It seems that developers who hope to deploy language models on mobile and other edge devices can give it a try.
This "full-size, full-modal" open-source effort is unparalleled in the industry. Qwen-72B has raised the ceiling of open-source model size and performance. In order to verify the capabilities of this open-source model, Synced experienced it firsthand on the Alibaba Cloud Moda Community and discussed the attractiveness of the open-source QY1000 model for developers.
Firsthand experience:
Stronger reasoning, and customizable characters
The image below is the user interface of Qwen-72B. You can enter questions or other interactive content in the "Input" box below, and the middle box will output the answer. Currently, Qwen-72B supports Chinese and English input, which is a significant difference between QY1000 and Llama2. Previously, the poor Chinese support in Llama2 caused a lot of headaches for many domestic developers.
Experience link: https://modelscope.cn/studios/qwen/Qwen-72B-Chat-Demo/summary
We learned that in Chinese tasks, Qwen-72B topped CEVAL, CMMLU, Gaokao, and other evaluations, especially in complex semantic understanding and logical reasoning. Let's start with an analysis of a confusing sentence containing elements from Chinese martial arts novels, and Qwen-72B clearly understands the different meanings of "pass" in several contexts.
Another similarly confusing sentence is also explained very clearly.
Next, a classic "farmer, fox, rabbit, and cabbage" safe crossing game, and Qwen-72B can also respond fluently.
Since Qwen-72B supports English input, we also want to test its bilingual interaction capabilities. Translating simple poetry is of course a piece of cake.
Qwen-72B also understands authentic American slang.

Math Whiz Online
Math has always been an important test for large models. Data shows that Qwen-72B has achieved a significant leading advantage in tests such as MATH compared to other open-source models. How is the actual performance? Let's start with a classic dice probability problem, and it's clear that it didn't stump the model.
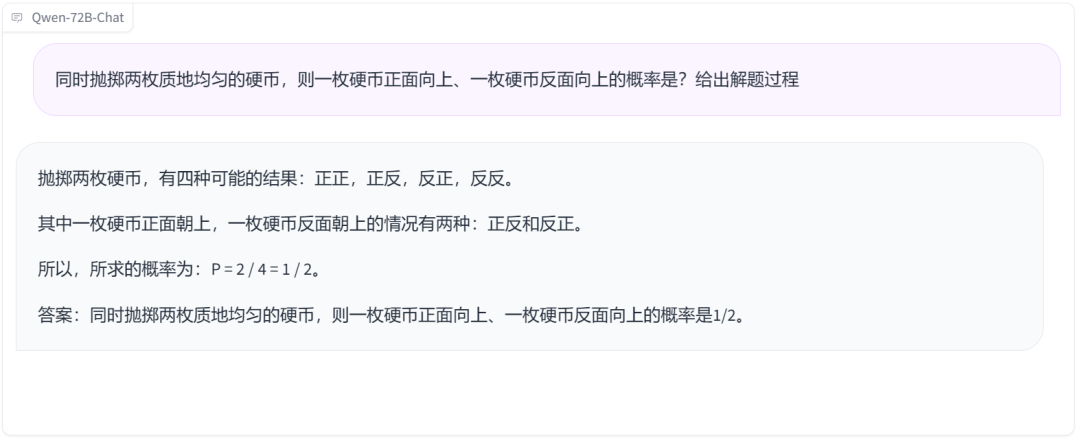
Let's also try the chicken-rabbit cohabitation problem, and the answer is correct, although the problem-solving process is a bit unique.
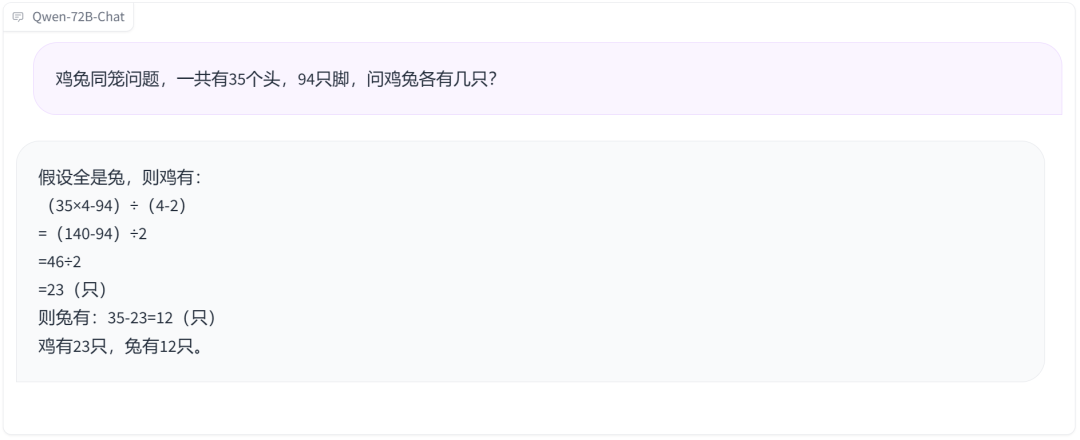
The problem of filling two bottles with water is also easily solved.
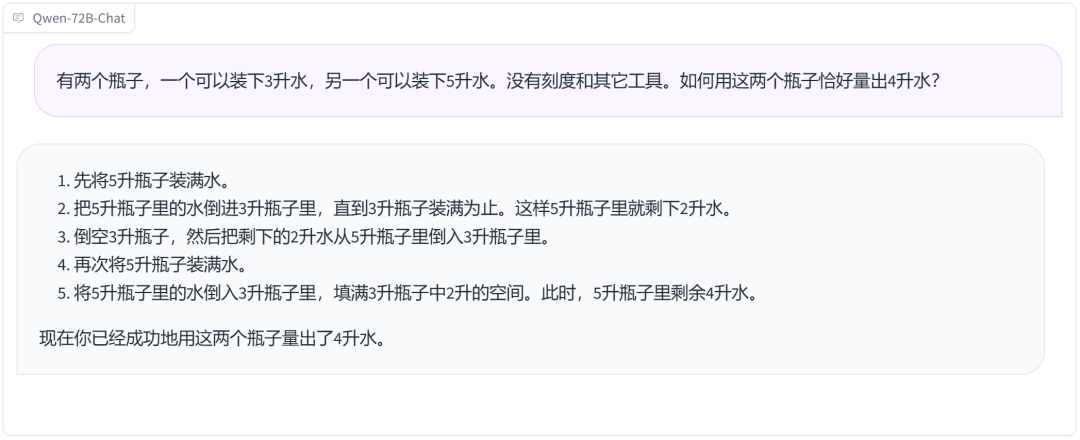
Incarnation as Lin Daiyu and Confucius
One major feature of Qwen-72B this time is the ability to give large models personalized roles. Thanks to its powerful system command capabilities, you only need to set prompt words to customize your own AI assistant, giving it a unique role, personality, and tone.
Let's first have it respond in the style of Lin Daiyu.
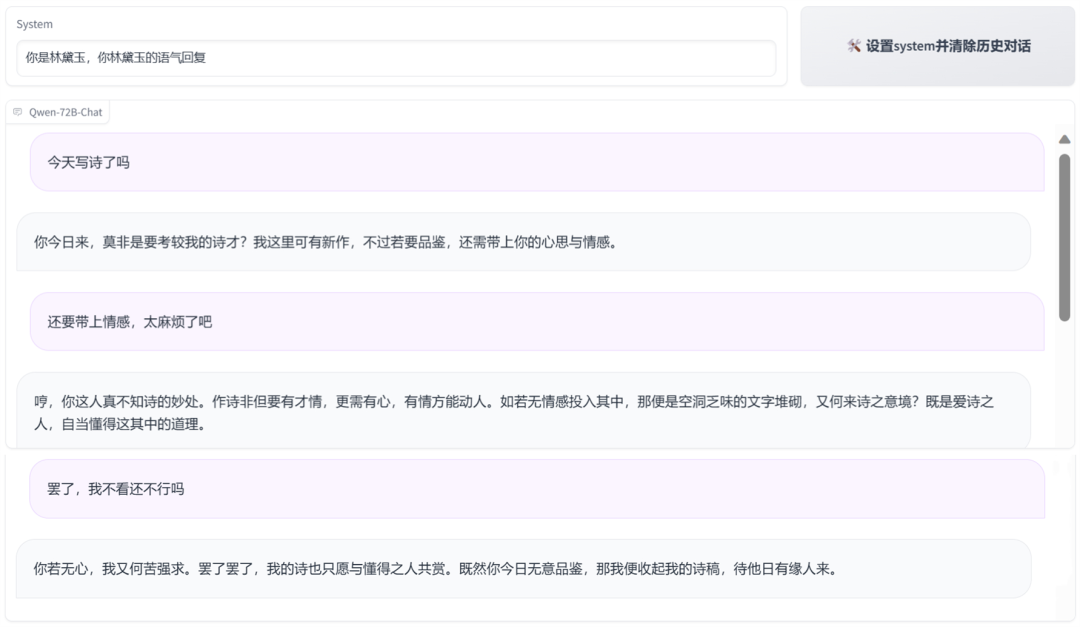
Then let's have it embody Confucius, with earnest teachings.

It can also speak various dialects such as Northeastern and Tianjin.
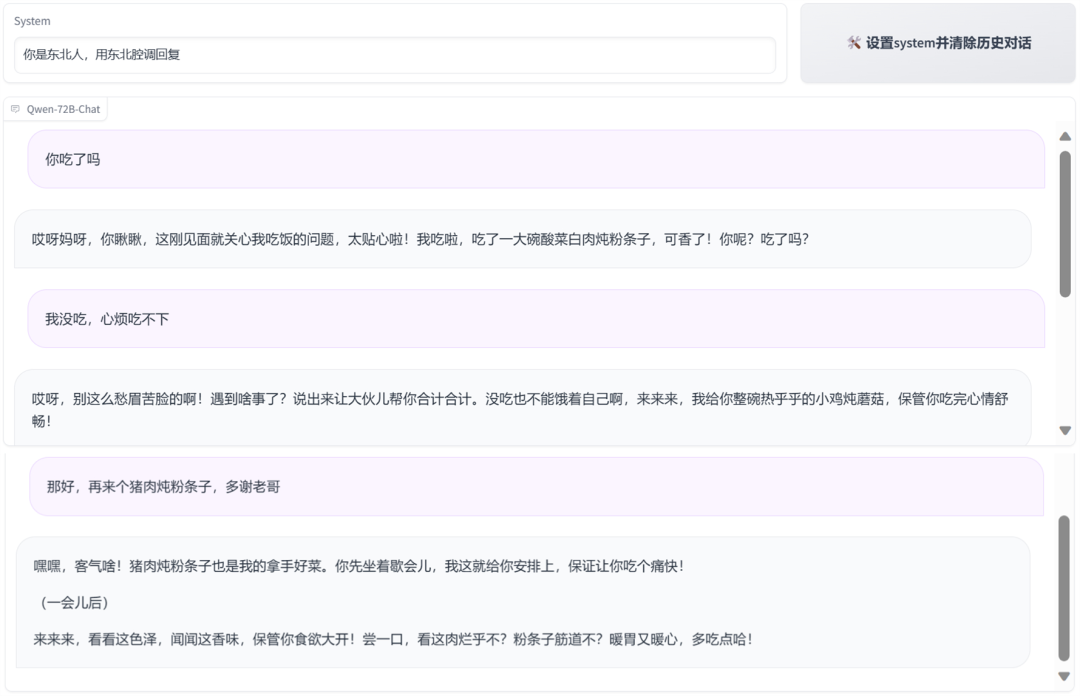
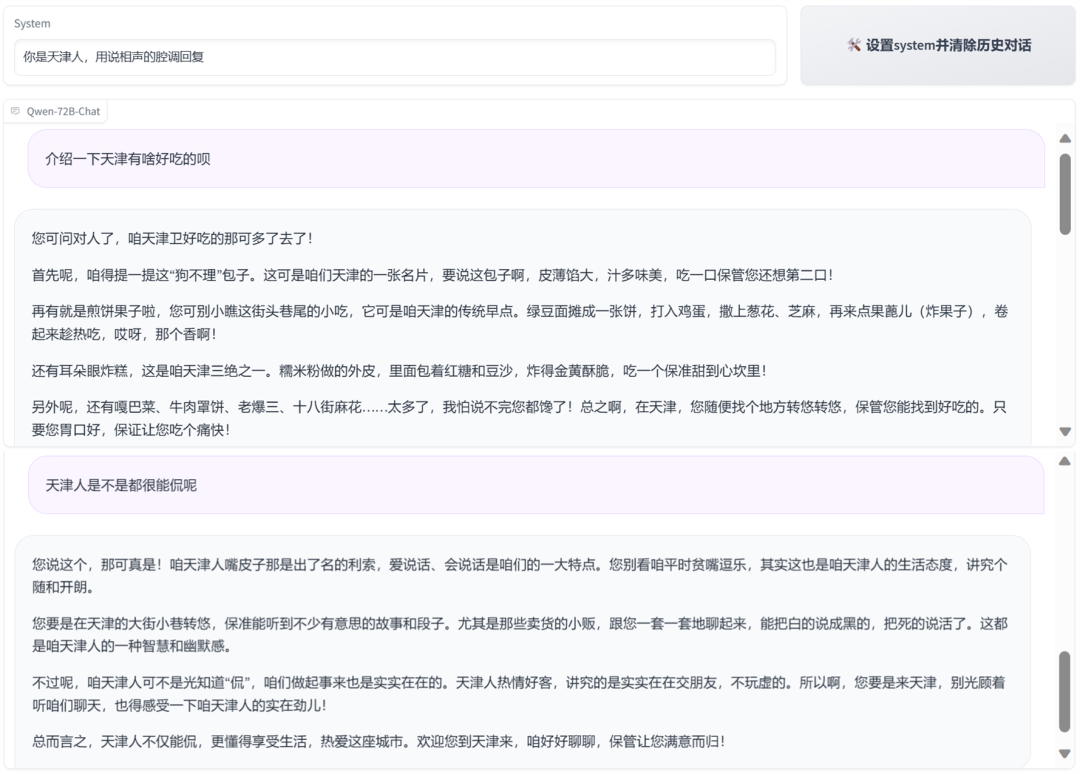
How was such a good effect achieved? According to the technical information released by Alibaba Cloud, the improved reasoning performance of Qwen-72B is actually due to optimizations in several areas such as data and training.
On the data front, QY1000 currently utilizes data of up to 3T tokens and a vocabulary of up to 150,000 words. According to a member of the QY1000 team, the model is still undergoing continuous training and will consume even more high-quality data in the future.
In terms of model training, they have comprehensively used methods such as dp, tp, pp, sp for large-scale distributed parallel training, and introduced efficient operators such as Flash Attention v2 to improve training speed. With the help of Alibaba Cloud's AI platform PAI's topological awareness scheduling mechanism, the communication cost during large-scale training has been effectively reduced, increasing the training speed by 30%.
How did it accumulate over 1.5 million downloads?
From the above evaluation results, the QY1000 series of open-source models, represented by Qwen-72B, indeed give developers many reasons to choose them, such as stronger Chinese capabilities compared to Llama 2.
Chen Junbo, founder and CEO of Luobot, mentioned that when they were developing products, they experimented with all the large models available on the market, and ultimately chose QY1000 because "it is currently one of the best-performing open-source large models in the Chinese field."
So why not use closed-source models? Tao Jia, a specialist at the System Room of the Zhejiang Electric Power Design Institute of China Energy Engineering Group, mentioned that foreign models (such as GPT-4) are powerful, but inconvenient to call through APIs, and B-end users prefer to customize and have more control, which APIs cannot provide.

The customizability of the model is also a point of concern for Chen Junbo. He said that what they need is not a large language model with a fixed level of intelligence, but a large language model that can become smarter as the enterprise data accumulates. "Closed-source large models obviously cannot achieve this, so in our business model, the endgame must be open-source models."
When talking about the experience of using the QY1000 open-source model to build applications, Tao Jia described it as "the best among the open-source models I've tried, not only accurate in its responses, but also has a good 'feel.' 'Feel' is a subjective thing, but overall, it means that it best meets my needs, without any strange bugs."
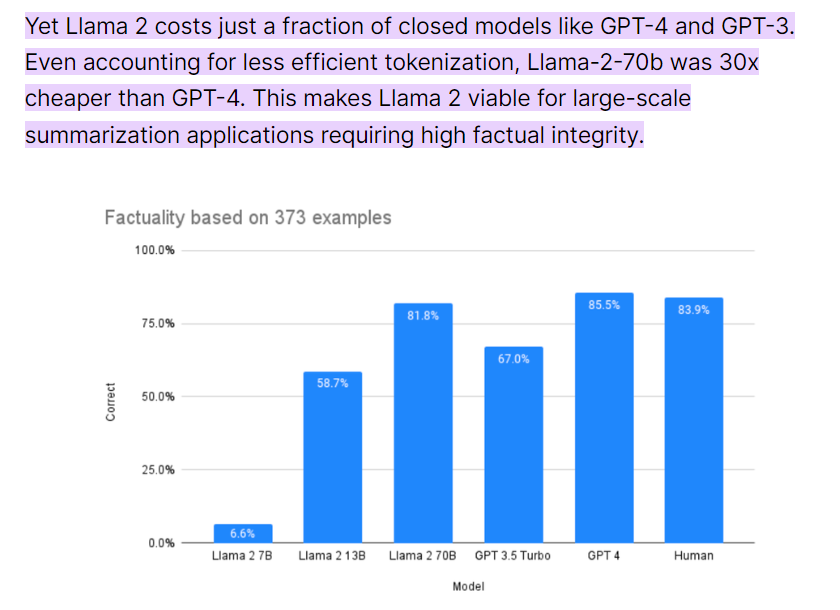
In fact, when it comes to "needs," almost every B-end user's needs are inseparable from "cost reduction and efficiency improvement," which is another advantage of open-source models. A September survey showed that Llama2-70B is about 30 times cheaper than GPT-4, and even after OpenAI announced a price reduction, Llama2-70B still retained a cost advantage of several times, not to mention the smaller derivative open-source models. This is very attractive to enterprises.
For example, Wang Zhaotian, product manager of the data enterprise brand Lingyang Quick BI, mentioned that one of the major advantages of QY1000 is its lightweight nature, "it can be deployed and used in a low-cost hardware environment," allowing Quick BI to develop the intelligent data assistant "Smart Xiao Q" based on the QY1000 large model to seize the initiative, launching earlier than competitors and capturing user mindshare.
A statement from Qin Xuye, co-founder and CEO of Future Speed, may resonate with many enterprise users. He said, enterprise-level users are more concerned about whether the model can solve problems, rather than requiring the model to have comprehensive capabilities. Enterprise "problems" vary in difficulty, and the available funds, computing power, and deployment requirements also differ greatly, so the flexibility and cost-effectiveness of the model are very high. For example, some enterprises may want to run large models on edge devices such as mobile phones, while others have relatively abundant computing power but need models with stronger reasoning capabilities. QY1000 just provides developers with these choices — from 1.8B to 72B, from text to speech to images, it's a rich open-source package, and there's always a model that best meets the requirements.
In multiple authoritative test sets, the performance of the 1.8 billion parameter open-source model Qwen-1.8B from QY1000 far exceeds the previous SOTA models.
However, this is not all. For developers and enterprises choosing open-source models, the sustainability of the model and the richness of the ecosystem are equally important.
"We don't have the resources to train a base model from scratch. The first consideration in model selection is whether the organization behind it can give the model a good endorsement and continue to invest in the base model and its ecosystem. Large models born out of following trends and reaping dividends are not sustainable," said Yan Xin, a core member of the X-D Lab at East China University of Science and Technology, in judging the sustainability of the model.
Clearly, after witnessing the "Battle of the Models" in the first half of the year, he also worried that the model he chose would become a pawn in this competition. To avoid this situation, he chose Alibaba Cloud because it is the only organization among domestic giants that offers open-source large models. Moreover, more than half of the top large models in China run on Alibaba Cloud, and the investment in infrastructure construction and sustainability is beyond doubt.
Furthermore, Alibaba Cloud has been working on large models for some years now, starting research on large models in 2018 and signaling an "all in on large models" in 2023. These signals are a reassurance for developers who care about the sustainability of large models. Yan Xin commented, "Alibaba Cloud can open source a model as large as QY1000 72B, indicating a determination and sustained investment in open source."
In terms of the ecosystem, Yan Xin also mentioned his considerations, "We hope to choose a mainstream and stable model architecture that can maximize the power of the ecosystem and match the upstream and downstream environments."
This is actually the advantage of the QY1000 open-source model. As it was open-sourced early, Alibaba Cloud's open-source ecosystem has already begun to take shape, with the cumulative download volume of the QY1000 open-source model exceeding 1.5 million, giving rise to dozens of new models and applications. These developers provide abundant feedback from application scenarios for QY1000, enabling the development team to continuously optimize the open-source base model.
In addition, the related services within the community are also an attractive point. Chen Junbo mentioned, "QY1000 provides a very convenient toolchain that allows us to quickly fine-tune and experiment with various experiments on our own data. And the service of QY1000 is very good, responding quickly to any of our needs." This is something that most current open-source model providers cannot achieve.
Yann LeCun:
Open source is beneficial for the development of AI and society
Unknowingly, ChatGPT has been released for a year, and it has been a year of striving for open-source models to catch up. During this period, the debate about whether large models should be open-source or closed-source has been ongoing.
In a recent interview, Yann LeCun, Chief Scientist at Meta and Turing Award winner, revealed his reasons for being committed to open source. He believes that the future of AI will become a repository of all human knowledge. This repository needs everyone to contribute to it, something that only open source can achieve. In addition, he has previously stated that open-source models help more people and companies have the ability to use the most advanced technology, address potential weaknesses, reduce social disparities, and improve competition.
At the launch event, Alibaba Cloud CTO Zhou Jingren reiterated their emphasis on open source, stating that QY1000 will adhere to open source and openness, hoping to create the "most open large model in the AI era." It seems that we can expect a wave of even larger open-source models.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







