
Image source: Generated by Wujie AI
The large model technology for text-to-image generation is once again making waves, now with real-time image generation.
On November 28th, the open-source large model company Stability AI officially released a new open-source text-to-image model, SDXL Turbo, and has made it publicly available on the Hugging Face platform. After users input prompt words, this tool can almost instantly generate images. Current test results show that the image generation quality is sometimes lacking, but this generation speed absolutely subverts all products currently on the market, including Midjourney, DALL-E3, bringing more room for imagination.
SDXL Turbo adopts a new technology called Adversarial Diffusion Distillation (ADD), which enables the model to synthesize image output in one step and generate real-time text-to-image output while maintaining high sampling fidelity. The paper on this technology has been publicly released. However, SDXL Turbo is not yet open for commercial use.
Research paper link: https://stability.ai/research/adversarial-diffusion-distillation
Experience link: http://clipdrop.co/stable-diffusion-turbo
Hugging Face download link: https://huggingface.co/stabilityai/sdxl-turbo
Advancements in Diffusion Models
SDXL Turbo represents a new advancement in diffusion model technology for Stability AI. It iterates on SDXL 1.0 and implements a new distillation technique for text-to-image models: Adversarial Diffusion Distillation (ADD). By integrating ADD, SDXL Turbo gains many advantages shared with Generative Adversarial Networks (GAN), such as single-step image output, while avoiding common artifacts or blurriness found in other distillation methods.
What is ADD
ADD is a new model training method that effectively samples large-scale base image diffusion models in 1-4 steps while maintaining high image quality. By using integral distillation to leverage large-scale pre-existing image diffusion models as a teacher signal and combining adversarial loss to ensure high image fidelity even in low-step states of one or two sampling steps. Analysis results show that this method is significantly superior to existing multi-step methods (GAN, latent consistency model), and achieves state-of-the-art performance with just four steps for diffusion models (SDXL). ADD is the first method to achieve single-step real-time image synthesis using base models.
Performance Advantages Compared to Other Diffusion Models
Diffusion models have achieved significant performance in synthesizing and editing high-resolution images and videos, but their iterative nature hinders real-time applications.
Latent diffusion models attempt to represent images in a computationally more feasible latent space, but they still rely on iterative applications of large models with billions of parameters.
In addition to using faster samplers for diffusion models, there is increasing research on model distillation, such as progressive distillation and guided distillation. These methods reduce the number of iterative sampling steps to 4-8, but may significantly reduce original performance. Furthermore, they require iterative training processes. Consistency models address the latter issue by implementing consistency regularization on ODE trajectories and demonstrate strong performance for pixel-based models in low-sample settings. LCM focuses on extracting latent diffusion models and achieves impressive performance in 4 sampling steps. Recently, LCM-LoRA introduced low-rank adaptive training for efficient learning of LCM modules, which can be inserted into different checkpoints of SD and SDXL. InstaFlow suggests using rectified flows to facilitate better distillation processes.
All of these methods share a common flaw: samples synthesized in four steps often appear blurry and exhibit noticeable artifacts. This problem is further exacerbated with fewer sampling steps. GANs can also be trained for independent single-step models for text-to-image synthesis. Their sampling speed is impressive, but their performance lags behind diffusion-based models. To some extent, this can be attributed to the fine balance of stable training required for adversarial objectives in GAN-specific architectures. Extending these models without disrupting the balance and integrating advances in neural network architectures is a well-known challenge.
Furthermore, the current state-of-the-art text-to-image GANs lack methods like classifier guidance, which is crucial for large-scale DM.
Approach
Our goal is to generate high-fidelity samples with as few sampling steps as possible while matching the quality of state-of-the-art models. Adversarial objectives naturally aid in fast generation, as it trains a model that outputs samples on the image manifold in a single forward step. However, attempts to extend GANs to large datasets have found that not only relying on discriminators, but also using pre-trained classifiers or CLIP networks to improve text alignment is necessary. As mentioned, over-reliance on the discriminator introduces artifacts and affects image quality. Instead, we utilize the gradient of pre-trained diffusion model through score distillation objectives to improve text alignment and sample quality. Additionally, we do not train from scratch, but use pre-trained diffusion model weights to initialize the model; it is well known that pre-training the generator network significantly improves training for adversarial loss. Finally, we adopt a standard diffusion model framework rather than using pure decoder architectures used for GAN training. This setup naturally achieves iterative refinement.

Qualitative effects of sampling steps. We demonstrate qualitative examples of sampling ADD-XL with 1, 2, and 4 steps. Single-step sampling is already of high quality, but increasing the number of steps can further improve consistency (e.g., the second prompt, the effect in the first column, clearly 4 steps are much stronger than 1 step) and attention to detail (e.g., the second prompt, the effect in the second column, likewise 4 steps are stronger). The seed in each column is constant, and we see that the overall layout is preserved in the sampling steps, allowing for rapid exploration of outputs while retaining the possibility of refinement.
To select SDXL Turbo, the research team compared multiple different model variants (StyleGAN-T++, OpenMUSE, IF-XL, SDXL, and LCM-XL) by generating outputs using the same prompts. Human evaluators were then randomly shown two outputs and asked to choose the one that best matched the prompt direction. Additional tests for image quality were also conducted using the same method. In these blind tests, SDXL Turbo was able to outperform LCM-XL's 4-step configuration in one step, and even outperformed SDXL's 50-step configuration in just 4 steps. These results demonstrate that the performance of SDXL Turbo is superior to state-of-the-art multi-step models, with significantly reduced computational requirements without sacrificing image quality.
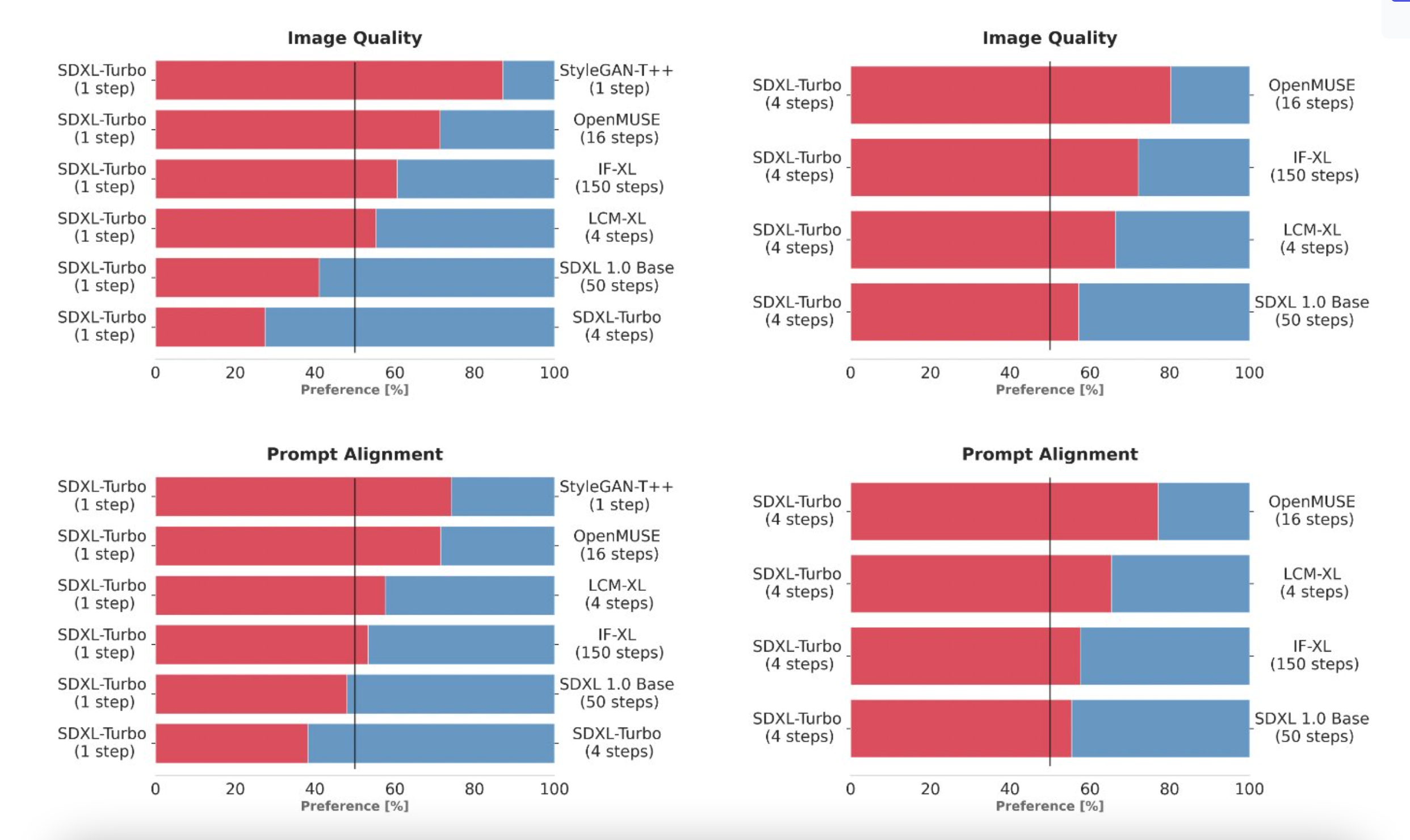
User preference study (single step). Comparing the performance of ADD-XL (1 step) with established baselines. In terms of human preference for image quality and real-time alignment, the ADD-XL model outperforms all models except for SDXL. Using more sampling steps further improves our model (bottom row).
Near Real-Time Speed
Community users have already started experiencing SDXL Turbo, and the results are amazing. Some users have run this large model using a consumer-grade 4060TI graphics card and were able to generate 512x512 images at a speed of 0.3 seconds per image. This several-fold speed improvement is opening up new creative possibilities for creators.

Link: https://twitter.com/hylarucoder/status/1729670368409903420
The speed of SDXL Turbo is so fast that users can generate images while inputting prompts. Users have also expanded the functionality to include adding reference images to generate pictures.
User-designed experience link: https://huggingface.co/spaces/diffusers/unofficial-SDXL-Turbo-i2i-t2i
In addition, SDXL Turbo has significantly improved inference speed. Using an A100 AI chip, SDXL Turbo can generate 512x512 images in 207 milliseconds (instant encoding + single denoising step + decoding, fp16), with a single UNet forward evaluation taking up 67 milliseconds.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







