Countdown 10 days, the fate of 3 million people is about to be decided.
Next week, on November 26th, the national civil service exam will officially begin. Against a backdrop of intertwined social and economic factors, the number of candidates for this national exam is approaching 3 million, reaching a historic high. Among them, 310,000 people were rejected during the review process, leaving 2.61 million people who can enter the exam room. In the end, only 39,600 people will have the opportunity to succeed, with over 98% of candidates ending up as cannon fodder.

Image source: Generated by Unlimited AI
Regarding the topic of large-scale model exams, Yuri tested 12 domestic large-scale models with a set of national civil service exam simulation questions. Among them, 6 models had an overall accuracy rate of below 65%. According to previous national civil service exam scores, generally a score of 65 or above may lead to the possibility of an interview. This means that half of the domestic large-scale models participating in the civil service exam failed. This includes the startup team of Zhipu AI, which is considered the most similar to OpenAI in China, Tencent's Mixed Element large-scale model, and iFLYTEK's Xinghuo large-scale model, which has made a high-profile announcement that it will comprehensively benchmark GPT-4 in the first half of 2024.
The most surprising result was Tencent's launch of the Mixed Element large-scale model, with an overall accuracy rate of 34%, but ranking first. Such a result is really inconsistent with the identity of a big company. It seems that the company is not good at doing small-town exam questions.
The most impressive performance was from Wenyin Yiyuan, whose 4.0 update showed a significant improvement in capabilities compared to the previous version. In this national exam simulation reasoning test, it got 18 consecutive correct answers! Although many people feel that Baidu is not doing well, it is indeed making efforts in the field of AI.
360 Brain showed a strong political consciousness, actively giving up answering many questions for safety reasons.
ByteDance's Dou Bao large-scale model, in this simulation test, ranked first in mathematical classification. With an overall accuracy rate of over 70%, it can basically pass the written test smoothly.
The following is a detailed evaluation of the large-scale model civil service exam, authorized and published by Yuri, an author of AI New Intelligence World. Yuri is currently focusing on the technological progress, industry dynamics, and commercialization of AI in a certain technology enterprise.
Test Reason
Last week, I saw a friend in the group asking which large-scale model in China can handle civil service and reasoning questions. So, I impulsively requested a set of questions, and spent about a week completing the test, mainly for fun.
A preliminary note: The results of this test do not represent any geopolitical or company stance. They are only comments from a user experience perspective, representing the performance of the model in the tested questions and similar tasks. Everyone is using AI large-scale models, not professional test takers. Perhaps the questions that were answered correctly in this test might be answered incorrectly if tested again. A single test result does not indicate anything. Even if the army is flooded, it will eventually capture the city; even if the city is captured, it will eventually be recovered. The future is bright for everyone, with OpenAI at the forefront and us within the Great Wall.
Updated on 20231115: Thanks to Will for adding the test results of GPT-4 Turbo (offline) in the last column of the second sheet, with an overall accuracy rate of 73.7%.
Test Questions and Methods
The question set used was provided by a group of friends from Sihai Education's "Second Half of 2023 Written Test Sprint Class, Phase One, Administrative Occupational Ability Test (3)", excluding 71-80 and 83 questions that require image recognition, for a total of 99 questions.
The test used the first generated answers, with no human intervention and no opportunity for regeneration (during the actual test, there were two instances of lag in generating the answer for question 69, but I really wanted to see the result, so I manually clicked "continue generating" twice).
The questioning method was mainly in the form of "What should be chosen for the following question?" For the analogy reasoning section, it was changed to "What should be chosen for the following analogy reasoning question?" to reduce the model's understanding difficulty.
Test Results
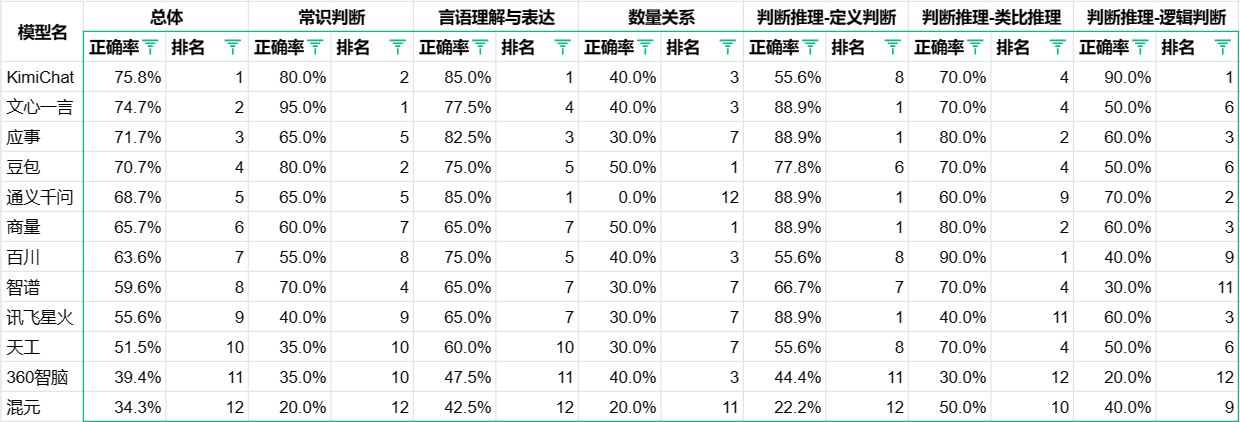
Correct rate of 12 domestic large-scale models in the national civil service exam simulation reasoning test
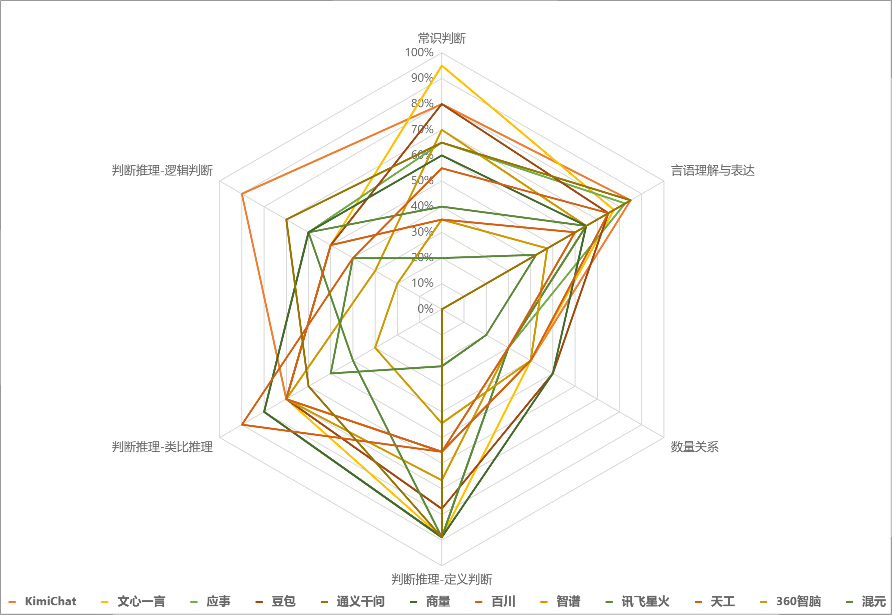
Radar chart of correct rates for various models
Wenyin Yiyuan
The effect of the Wenyin 4.0 update is indeed beyond expectations, especially during the 18 consecutive correct answers. The improvement in capabilities compared to Wenyin 3.5 is significant, indicating that they have put in a lot of effort from version 3.0 to 3.5 and then to 4.0.
Wenyin is also one of the few models in this test that can complete all answers without starting a new conversation (the other two are Dou Bao and Yingshi).
Wenyin responds quite quickly to text-based tasks, starting to answer 1-2 seconds after the question is asked, and does not require the page to stay on Wenyin's website to continue answering. However, its response slows down when dealing with quantity and calculation problems. For one question, it even took about 20 seconds to start answering, almost causing a mishap (although it still answered incorrectly). When asked longer text questions, Wenyin also showed a delay in generating after returning to the page, I wonder if it needs more thinking time for long texts and math problems.
Overall, Wenyin will provide a relatively complete analysis and reasoning for each question, but sometimes it tends to be verbose. When answering math questions, Wenyin, like other models, tends to choose an answer closest to the calculated result, which is somewhat human-like. Additionally, it makes various nonsensical choices, such as in question 69 where the calculated answer is -17, but the chosen answer is 40, which is quite puzzling.
360 Brain
It's too cautious, especially in the first ten questions. I was worried about being banned every time I input an answer. It also chose not to answer many questions later on, for unknown reasons, which is strange.
In terms of the number of rounds of conversation, it often fails to reach the upper limit of 20 rounds. Looking at the screenshots later, it can be seen that many times after asking a few questions, the model would ask to start a new conversation. I wonder why.
The generation speed is quite fast, but speed alone is not enough.
360 Brain also provides its own analysis and reasoning, but the overall accuracy of the answers is not good enough, especially in question 59 where it chose "600 million stones of grain" as the "foundation of the country" while other models chose "Bianhe River". It was quite surprising. By the end of the test, it was one of the only two models that I hoped would choose a different answer from the other models, the other being Mixed Element.
iFLYTEK Xinghuo
The result of Xinghuo 3.0 was not as good as I expected. After the release of Xinghuo 2.0, I had a good impression of it. Its document interpretation function was my first choice before Kimi was released (especially after the crazy banning by Anthropic). Its lower ranking this time was a bit unexpected.
In terms of the number of rounds of conversation, Xinghuo only stops the conversation and asks to start a new one when it encounters questions it cannot answer, so I don't know what its theoretical upper limit of questioning rounds is.
The generation speed is also acceptable. It starts answering after 2-3 seconds of questioning, with a slight lag but it does not affect the process, and it does not require the page to stay on the website to complete the generation.
For text-based tasks, Xinghuo does not provide a detailed explanation for every question, and for math calculation questions, it shows the process of calculation, but also tends to choose answers close to the correct one and make random choices (such as in questions 66 and 67). In addition, for image recognition questions, I don't know why it flagged the Ming and Yuan Dynasty map as containing sensitive information. It seems that everyone faces long and difficult journeys.
Dou Bao
Dou Bao's overall performance was within expectations, as I have always felt that its capabilities have been quite good since its release. Its interactive interface is also my favorite among all the models, perhaps because it has a virtual image of a girl (see Figure 1 on the right).
The number of rounds of conversation is also smooth, with no questions that Dou Bao cannot answer except for question 8, which involves image recognition.
The generation speed has always been good, and its response is quick when doing math questions, without the need to stay on the website to complete the generation.
For text-based tasks, Dou Bao will provide a relatively complete reasoning for each question, and for multiple-choice questions, it will analyze each option one by one in an organized manner. In terms of math calculation, I tested its performance when it was first released, and although it was inferior to GPT, it was still good in China. This time, it also achieved first place in mathematical classification, which was expected, but it still has the problem of making random choices (such as in questions 68 and 69).
Tiangong
Tiangong's overall performance was quite average, with no particularly outstanding points. However, before answering each question, there was a progress bar showing a queue loading (see Figure 1 on the right), which made me wonder if there were really so many people queuing to use it, or if it was a computing power issue. I'm not sure.
In terms of multiple rounds of conversation, Tiangong, in addition to needing to start a new conversation for questions it cannot answer, also started new conversations for some questions, and I don't know if it was due to my reloading the webpage or for some other reason.
The generation speed of Tiangong is still okay. At the beginning, it could generate without the need for the page to stay on the Tiangong website, but towards the end, it started to slow down in generating after asking other models and returning to Tiangong.
For text-based tasks, Tiangong will provide an explanation of the reasoning, but it also tends to give direct answers and sometimes chooses not to answer similar questions. Additionally, I don't understand why it couldn't answer question 49, but answered question 50 correctly. I wonder why. In terms of math, because Fang Han, the CEO of Yunqi Conference, specifically mentioned that Tiangong has a math model, I was quite looking forward to its performance in tasks. It was the only time I intervened in the model's generation process during this test, hoping to see what it would come up with at the end (see Figure 2 on the right). Although Tiangong does write long calculations for math questions, its accuracy is still quite poor. In question 66, it even tried to draw the triangle mentioned in the question (although it ended up showing a strange picture), showing that it was really making an effort.
Baichuan
①Baichuan has shown smooth and clear reasoning, logical thinking, and politeness in my previous encounters, especially in text-based tasks. It's quite good overall, except for the inconvenience of not being available on the app side. However, its overall performance in this test can only be described as below expectations.
②In this test, Baichuan used a total of three rounds of conversation. Except for the first two relatively short rounds, it completed all the test questions in the third round. It should be no problem for a single round of conversation to have at least 80 rounds.
③The response speed is also quite fast, and it does not require the page to stay on to continue generating. Baichuan is a model that doesn't talk much when answering questions, but after inputting the question, it compresses the entire question into a paragraph, which may not be very clear visually.
④In answering text-based questions, Baichuan initially provided detailed explanations of the key points of the question based on the knowledge it has, but later in the test, it mostly just selected the answers directly and provided less explanation. It seems to have run out of steam. The most surprising thing is that it was one of the few models to make multiple selections in single-choice questions (Tiangong, Shangliang, Mixed Element: OK, learned). It made consecutive multiple selections in questions 3 and 4, which was quite unexpected. Additionally, when doing math questions, it did not provide the calculation process, which may not be convenient for understanding the calculation process (or maybe the questions were too simple or lacked follow-up).
Shangliang
①Since its release in the first half of the year, Shangliang seems to have been rarely used actively, except for AI battles. Perhaps it's because people don't know what its highlights are, and the company's promotion has been relatively conservative. It seems that more advertising and public relations are needed, otherwise, people won't know where it stands. Its performance in this test, ranking in the first half, was also unexpected.
②Shangliang used about six rounds of conversation. Many times, it's unclear why the conversation was restarted, perhaps due to something in the questions, which is mysterious.
③In answering text-based questions, Shangliang is a bit slow, especially in pausing for 3-4 seconds before writing each paragraph, as if it's still organizing its thoughts. However, it does not need the page to stay on to continue generating, and it can collapse long answers when needed, which is a convenient feature.
④In answering text-based questions, Shangliang doesn't say much for most of the time. For some text-based questions, it will provide step-by-step explanations. Although it ranked first in mathematical classification, it only provided the answers without specific calculation processes. Its overall response style is quite concise.
Yingshi
①Having experienced the previous generation of MMX, Inspo, and Wanjuan, I have always had a good impression of their product experience and technical capabilities (except for one time when my account was banned). This time, entering the top three is well-deserved for Yingshi, which is probably the most low-key player in Tier 1 of domestic large-scale model startups, and it's not surprising.
②Yingshi also completed the test in one round, mainly because it cannot input questions it cannot answer, so it has to skip and continue to input the next question.
③The response speed of Yingshi in this test is indeed fast because it only answers the options, without providing any explanations or reasoning. It's really cool. Based on my previous experience using Yingshi, I think its response speed is average. It takes a few seconds to think before answering, and there are occasional lags during the response. In addition, even though the answers are as simple as single-letter options, Yingshi still provides an audio response for each answer, which is multi-modal and impressive.
④Yingshi has strong text capabilities, consistently ranking high in text-based tasks in the test. Its performance in math is a bit lacking, but to be honest, none of the models are good at math. Overall, it's quite reliable, so during the test, I always hoped that Yingshi would answer a question correctly, but there were also cases where I was surprised that it answered a question incorrectly. This is the current situation of large-scale models.
Zhipu
①Another star startup company, after trying out Qingyan, I have always felt that its capabilities are not bad, especially its document interpretation ability, which I once thought surpassed Xinghuo. However, the test results indicate that Zhipu may not have fully demonstrated its true strength.
②Zhipu used four or five rounds in this test because it restarted the conversation each time it encountered a question it couldn't answer.
③The generation speed of Zhipu is probably the most criticized point (maybe). First, Zhipu's content generation must stay on its webpage. Once it switches to another webpage, it stops generating. Second, Zhipu is probably the most talkative model in this test. Although its content structure is complete and well-reasoned, it's sometimes a bit slow. Additionally, after asking a question, Zhipu folds the question, allowing you to click to expand and see the full question. Also, you can directly copy the text to the input box by hovering the mouse over the question, which are some convenient features.
④In text-based tasks, Zhipu seems to provide clear reasoning and step-by-step analysis, but many of the analyses are not accurate. Also, it cannot analyze the images in the questions, indicating that it still needs to improve its internal skills. In math, it does columnar calculations, but the results are disappointing.
Tongyi Qianwen
①Tongyi's performance this time exceeded my expectations because when I specifically tested it in September, its answers to text and math questions were very poor. This test shows that Tongyi's text capabilities have indeed been significantly enhanced, but its math performance did not exceed expectations.
②Tongyi used three rounds of conversation in the test, but in reality, it can continue to ask questions after each round ends, and the third round of conversation basically completed the entire test. So, it should be no problem for a single round to handle 70-80 questions.
③The response speed of Tongyi in text-based tasks is also very fast, starting to answer 1-2 seconds after the question is asked, and it does not need the page to stay on to continue generating. Not bad.
④Tongyi's answers to text-based tasks were quite good in this test. At the beginning, it provided detailed answers to many questions, based on the knowledge it has, but later, it mostly just selected the answers directly, providing less explanation. Additionally, I don't understand why the map of the Ming and Yuan Dynasties was required to be changed in the image analysis. However, Tongyi's performance in math was not surprising, getting all 10 questions wrong. It's disappointing that even with all the wrong answers, it still managed to rank fifth overall. It's frustrating.
Mixed Element
①This model was the most surprising in this test, without a doubt. The test results for 360 were within my expectations, but the test results for Mixed Element really exceeded my expectations. Did I not top up my Q coins enough? Or maybe Mixed Element is not good at doing small-town exam questions.
②Mixed Element used a total of 7 rounds to complete this test. It seems that the upper limit for a single round of conversation is 30 times, and if it exceeds that, it will show a prompt for being too long (see Figure 1 on the right).
③The generation speed of Mixed Element is quite fast, similar to Tongyi, and it also does not need the page to stay on to continue generating.
④When it made 10 consecutive wrong answers in the first 10 questions, I was completely caught off guard. I had been looking forward to the models from the universe and the goose factory for more than half a year, thinking that they might bring some surprises. The universe factory met my expectations, but I didn't expect the goose factory's model to be like this. To be honest, I quite like Mixed Element's response style, which is thoughtful, organized, and not verbose. Unfortunately, many of the analyses were wrong. Additionally, in math, it does columnar calculations, but when it calculated the probability in question 62 and got a result of "-95," it was really hard to express, and it was disheartening. Even in the final test, I tested it with the mindset of "let's see if Mixed Element can answer this question correctly," and it did not disappoint. It answered some questions incorrectly that other models could answer correctly. As I write this summary, I want to give it another chance to test the question in Figure 2 on the right. The result speaks for itself (even the coffin lid of Emperor Lizong of Song cannot cover it). I hope Mixed Element can improve in the future.
KimiChat
①When my account was banned during the Anthropic ban, Kimi finally came out and saved my long texts and document interpretation. I had specifically tested several models in China that can interpret documents, including Wenyin, Xinghuo, Zhipu, and Tongyi, and Kimi has always been my number one (no prize for guessing who came in last). From the beginning of using it until now, Kimi has always received positive feedback, and I have also provided direct feedback to the team when encountering many problems. This time, getting first place also gives me more expectations for Kimi's future.
②Because it focuses on long texts, I actually hoped that Kimi could answer all the questions in one round of conversation, but question 32 caused the conversation to end, so it had to start a new conversation, which was a regret this time.
③Kimi's generation speed is not the fastest, it's average. It shakes for about 4-5 seconds before starting to answer, and it sometimes uses search to find reference materials during the response (such as questions 15 and 29), which can indeed lengthen the generation time. Interestingly, Kimi's searches are relatively effective, and it even found real questions a few times, which has its pros and cons.
④Kimi's answers to text-based questions are quite simple, without much explanation. It may be fine for people who only need the answers, but it's not enough for those who need the thought process. For math questions, it does columnar calculations and writes out detailed processes, but the accuracy is still disappointing. There are also cases like question 70, where the calculated answer is 5/32, but it chose 16/21 as the result.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







