The big model is reading, and it has never been so fast.

Image source: Generated by Wujie AI
A domestic big model startup is creating new records at the forefront of technology.
On October 30, Baichuan Intelligence officially released the Baichuan2-192K long-window large model, which raised the length of the large language model (LLM) context window to 192K tokens.
This is equivalent to allowing the big model to process about 350,000 Chinese characters at once, which is 14 times the length of GPT-4 (32K tokens, about 25,000 characters) and 4.4 times the length of Claude 2.0 (100K tokens, about 80,000 characters).
In other words, Baichuan2-192K can read the entire book "The Three-Body Problem 2" at once, making it the world's largest big model in terms of processing the longest context window. In addition, it also significantly outperforms its competitors in text generation quality, context understanding, and question-answering capabilities in multiple dimensions.
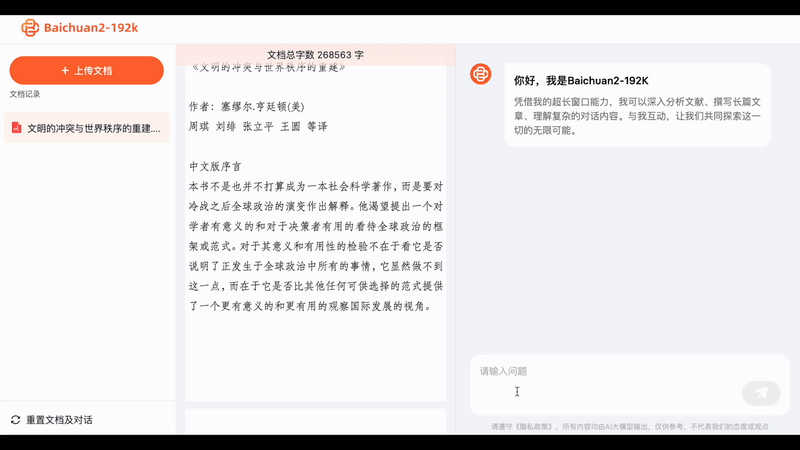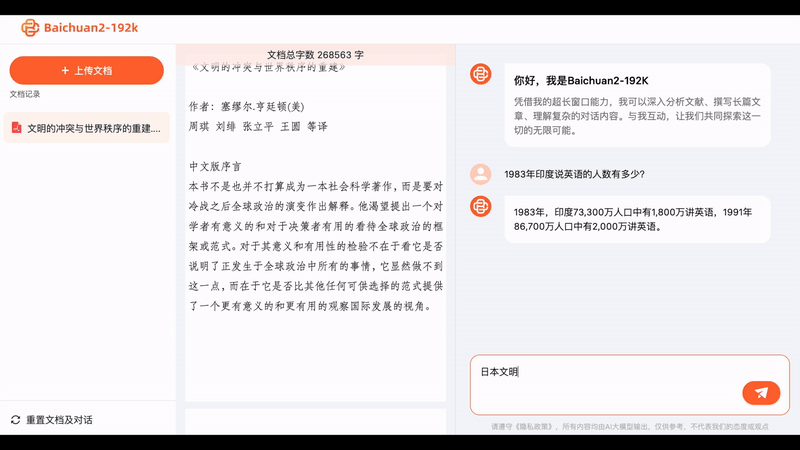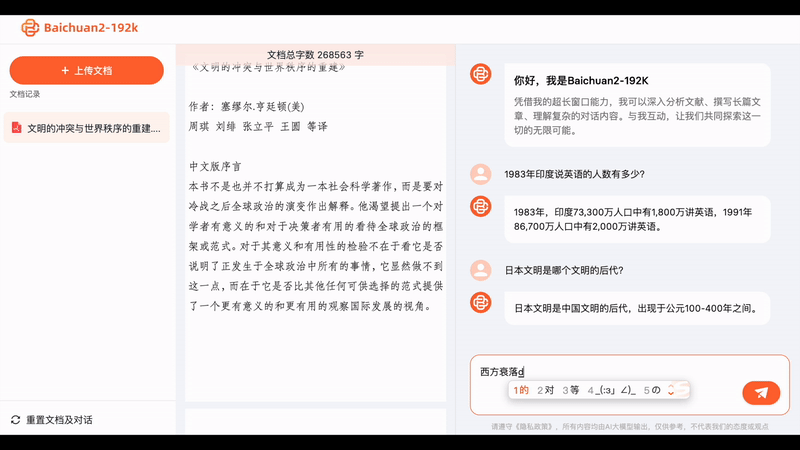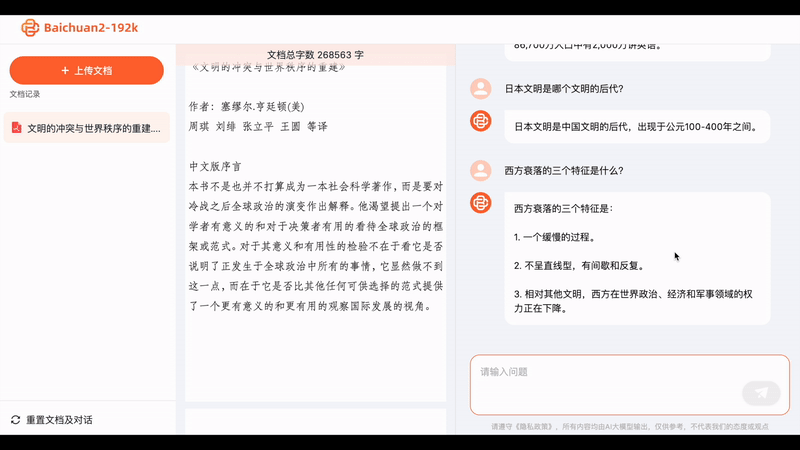
What can a big model that can understand ultra-long texts really do? Baichuan Intelligence has provided a simple demonstration.
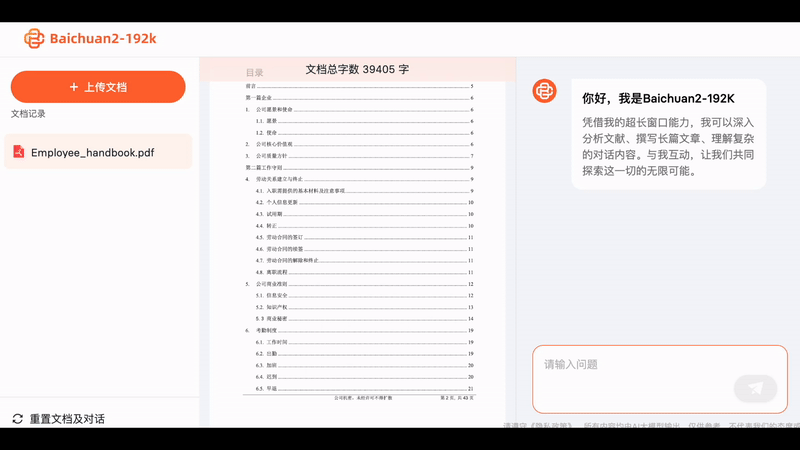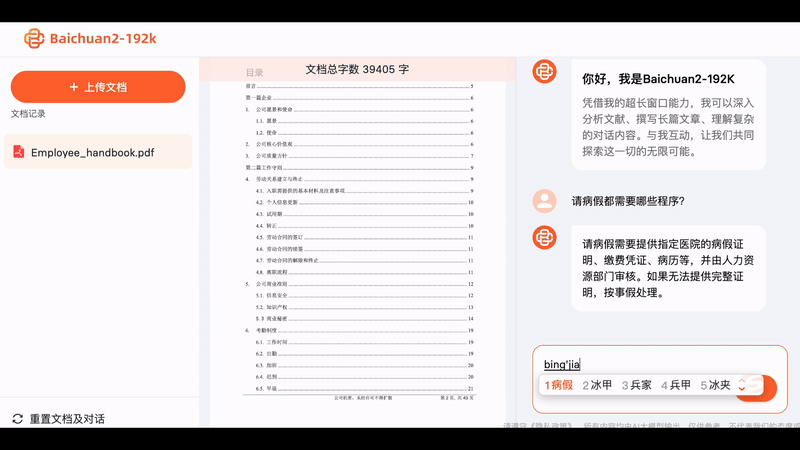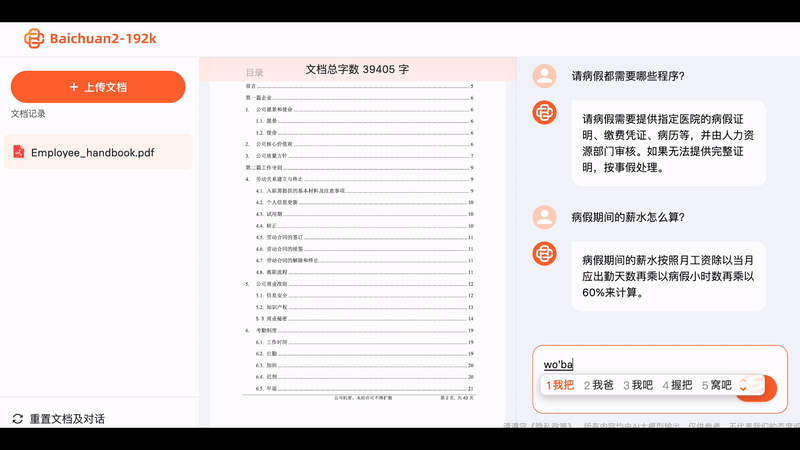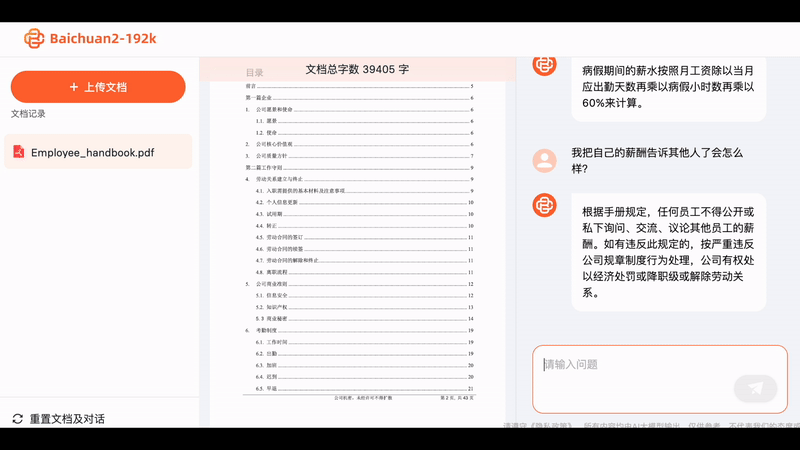
Upload the entire PDF of "The Three-Body Problem 2," and the Baichuan big model will calculate that it contains 300,000 characters. Then, if you ask any questions about this novel, the big model can provide concise and accurate answers.

Sometimes when we seek the help of AI, it's not to unleash their imagination, but to extract accurate information. With Baichuan2-192K, we can quickly interpret dozens or even hundreds of pages of contract documents, allowing AI to provide concise summaries quickly, which is essentially speed reading:
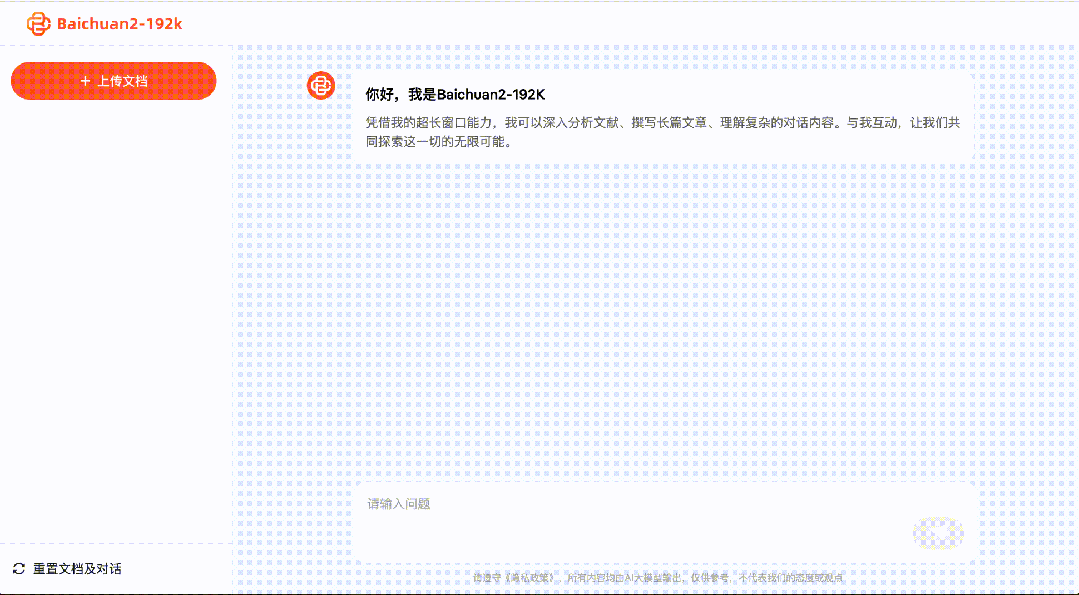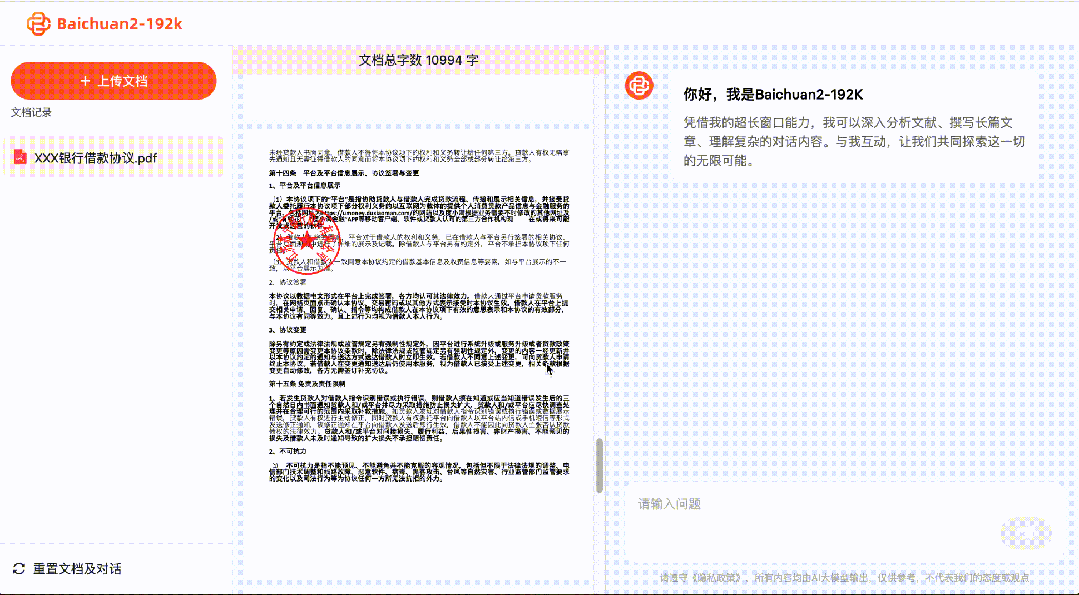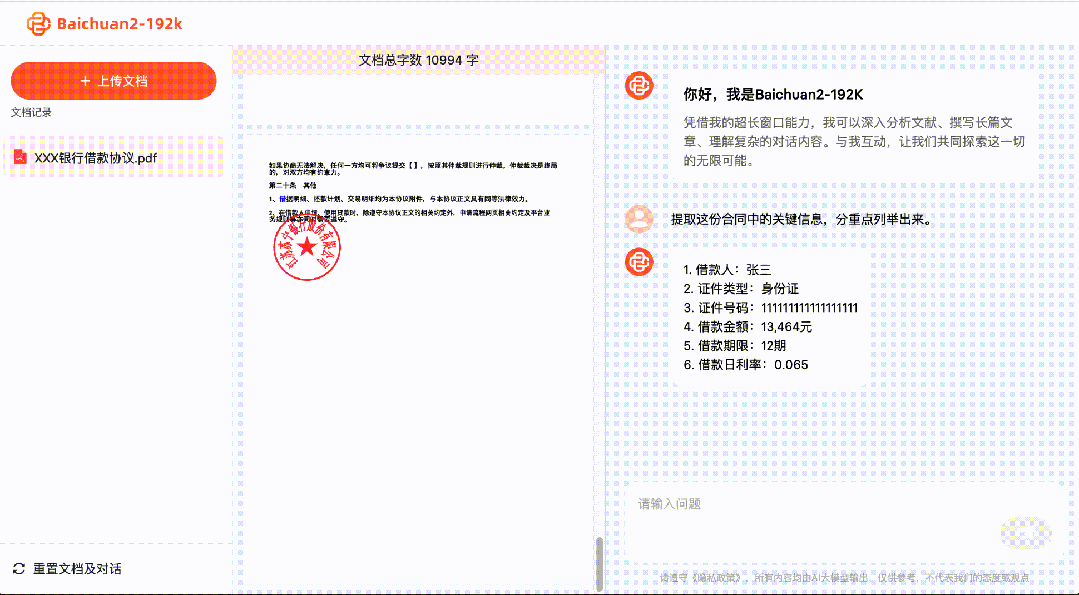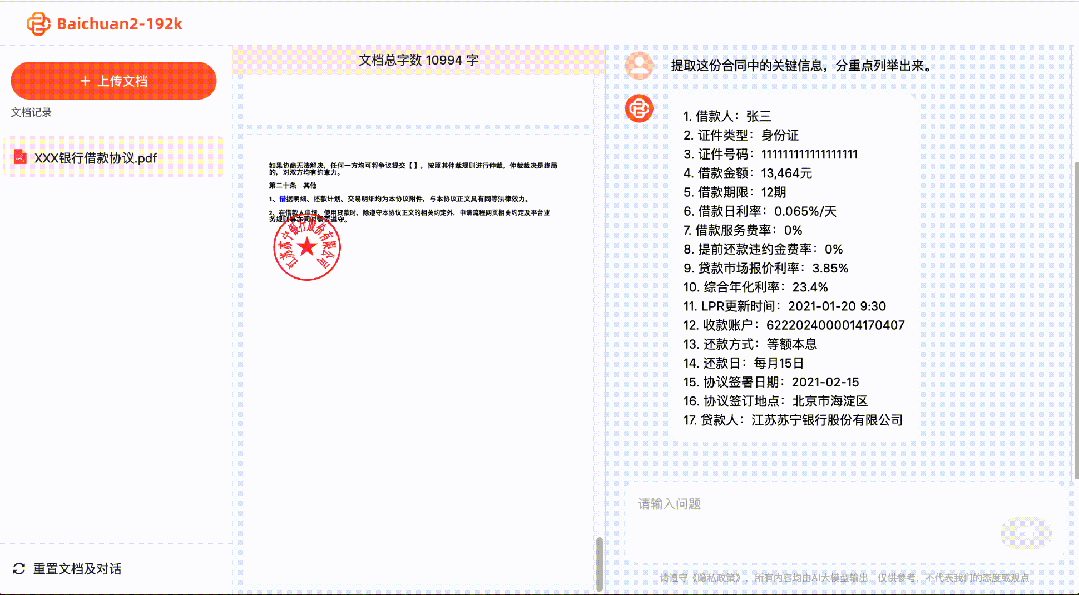
So what if I suddenly receive a new task and have a pile of documents to read?
Just upload them all together, and the Baichuan big model can easily integrate five news articles into one.
As the content that big models can understand becomes longer, the directions for application will become more diverse. It is well known that the ability to model long texts is a prerequisite for many scenarios to be applied. This time, Baichuan has taken the lead in the industry.
From tens of thousands of characters to hundreds of thousands of characters, leading startup companies are all vying for "long windows"
If you pay attention to the application of big models in text understanding, you may notice a phenomenon: initially, the texts used to evaluate model capabilities were probably some financial reports or technical reports, which usually ranged from a dozen to several dozen pages and a few tens of thousands of characters. However, the test texts gradually evolved into several hours of meeting records or long novels of several hundred thousand characters, with increasingly fierce competition and greater difficulty.

At the same time, companies claiming to understand longer contexts with big models are also attracting more attention. For example, recently, Anthropic, the company behind Claude, which claims to achieve a 100K token context window, has received billions of dollars in financing from Microsoft and Google, pushing the big model arms race to a new level.
Why are these companies all challenging long texts?
First, from an application perspective, many workers who use big models to improve productivity inevitably have to deal with very long texts, such as lawyers, analysts, consultants, etc. The larger the context window, the more extensive the tasks these people can accomplish with big models. Secondly, from a technical perspective, the more information the window can accommodate, the more information the model can refer to when generating the next character, reducing the likelihood of "hallucinations" and making the generated information more accurate, which is a necessary condition for the practical application of big model technology. Therefore, while trying to improve model performance, companies are also competing to see who can make the context window larger and thus apply it to more scenarios.
From some of the examples shown earlier, it can be seen that Baichuan2-192K performs very well in text generation quality and context understanding. Moreover, beyond these qualitative results, we can also see this from some quantitative evaluation data.
Baichuan2-192K: The longer the document, the more obvious the advantage
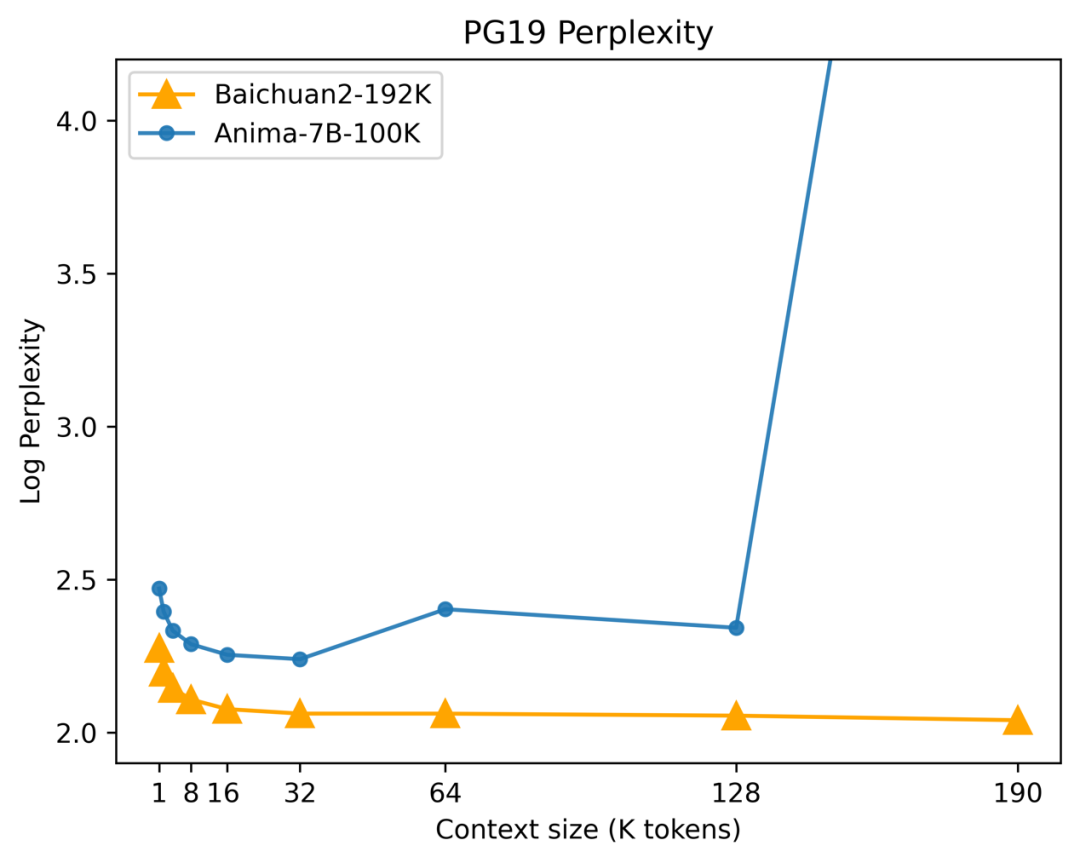
In the evaluation of text generation quality, a very important indicator is "perplexity": when we use high-quality documents that conform to human natural language habits as the test set, the higher the probability that the model generates the text in the test set, the lower the perplexity of the model, and thus the better the model.
The test set used to test the perplexity of the Baichuan big model is called PG-19. This dataset was created by researchers at DeepMind and is based on materials from the Project Gutenberg, so PG-19 has the quality of a book.
The test results are shown in the following figure. It can be seen that in the initial stage (left side of the horizontal axis, with relatively short context lengths), the perplexity of Baichuan2-192K is already at a low level. As the context length increases, its advantage becomes more and more obvious, even showing a continuous decrease in perplexity. This indicates that in scenarios with long contexts, Baichuan2-192K can better maintain book-level text generation quality.
In terms of context understanding ability, Baichuan2-192K's performance is also very impressive.
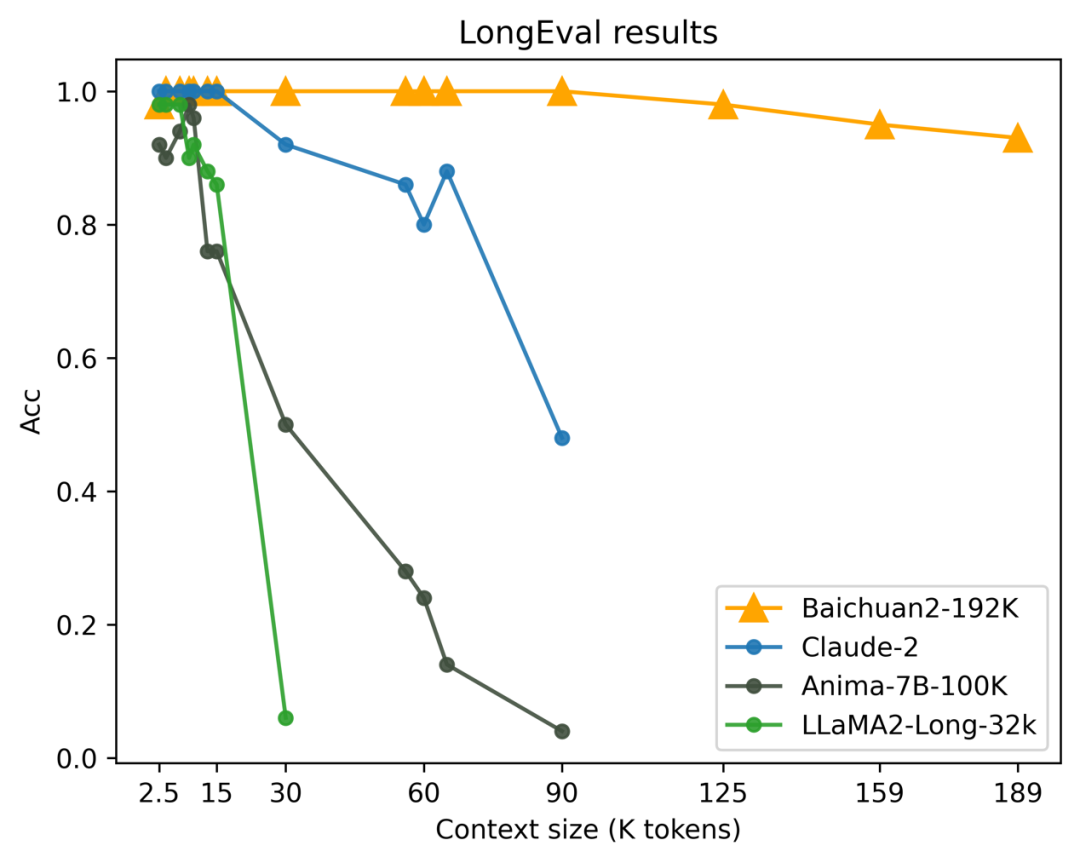
This ability is evaluated using the authoritative LongEval benchmark for long-window text understanding. LongEval is a list released by the University of California, Berkeley and other universities for evaluating models' memory and understanding of long-window content, with higher scores indicating better model performance.
From the evaluation results in the figure below, it can be seen that as the context length increases, Baichuan2-192K has consistently maintained high performance, even after the window length exceeds 100K. In comparison, the overall performance of Claude 2 deteriorates significantly after the window length exceeds 80K.
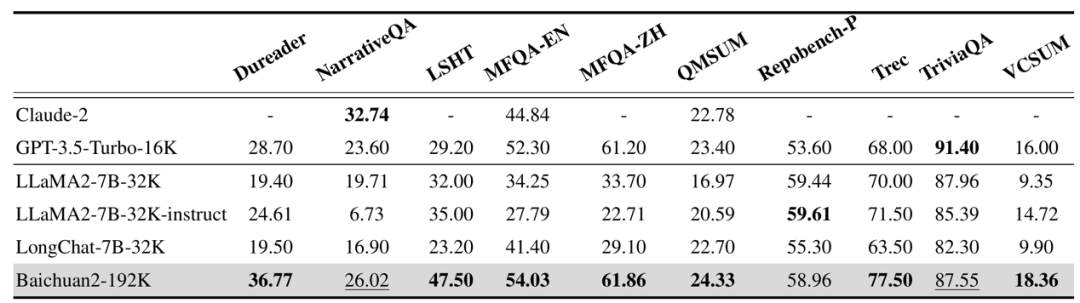
In addition, the model has undergone testing on multiple Chinese and English long-text question-answering and summarization evaluation sets such as Dureader, NarrativeQA, TriviaQA, and LSHT. The results show that Baichuan2-192K performs exceptionally well and far surpasses other models in most long-text evaluation tasks.
In short, the longer the content, the better the relative performance of Baichuan's big model.
192K ultra-long context, how did Baichuan achieve this?
Expanding the context window can effectively improve the performance of big models, which is a consensus in the artificial intelligence industry. However, an ultra-long context window means higher computational power requirements and greater pressure on memory.
To alleviate this pressure, some compromises have emerged in the industry, such as making the model smaller; allowing the model to actively discard previous text through methods like sliding windows, retaining only the attention mechanism for the latest input; and through downsampling the context or using RAG (retrieval-augmented generation), retaining only the attention mechanism for part of the input, and so on.
Although these methods can increase the length of the context window, they all have different degrees of impact on the model's performance. In other words, they all sacrifice other aspects of the model's performance in exchange for the length of the context window, such as the model's inability to answer complex questions based on the entire text, and the difficulty of considering answers across multiple texts.
With the release of Baichaun2-192K, Baichuan has achieved a balance between window length and model performance through the ultimate optimization of algorithms and engineering.
On the algorithm side, Baichuan Intelligence has proposed an extrapolation solution for dynamic position encoding of RoPE and ALiBi, which can perform different degrees of attention-mask dynamic interpolation on ALiBi_mask of different resolutions, enhancing the model's ability to model long sequence dependencies while maintaining resolution.
On the engineering side, Baichuan Intelligence has integrated all advanced optimization technologies currently available on the market, including tensor parallelism, pipelining parallelism, sequence parallelism, recomputation, and Offload functions, into its independently developed distributed training framework, creating a comprehensive 4D parallel distributed solution. This solution can automatically find the most suitable distributed strategy based on specific workloads, greatly reducing the memory usage during long-window inference.
Speed is essential in the big model battle
Established in April this year, Baichuan Intelligence can almost be said to be the fastest in terms of technological iteration among big model startups. In just six months since its establishment, the company has released four open-source and freely available big models: Baichuan-7B/13B, Baichuan2-7B/13B, as well as two closed-source big models: Baichuan-53B and Baichuan2-53B.
On average, a new big model is released every month.
The Baichuan series of big models integrates intent understanding, information retrieval, and reinforcement learning technologies, combined with supervised fine-tuning and human intent alignment, and has performed outstandingly in the fields of knowledge question-answering and text creation. These big models are highly favored in the industry: the cumulative download volume of the Baichuan series open-source models in major open-source communities has exceeded six million times; Baichuan 2 has even surpassed Llama 2 in all dimensions, leading the development of China's open-source ecosystem.
On August 31, Baichuan Intelligence became the first big model company established this year to pass the "Interim Measures for the Management of Generative Artificial Intelligence Services." On September 25, Baichuan Intelligence opened the Baichuan API interface, officially entering the B2B field and commencing the commercialization process.
It can be said that from technological research and development to implementation, Baichuan's speed is fast enough.
The recently released Baichuan2-192K has officially entered the internal testing phase and will be opened to core partners through API calls. Baichuan has stated that it has already cooperated with financial media and law firms to apply Baichuan2-192K's leading long-context capabilities to specific scenarios such as media, finance, and law, and will soon provide it to enterprise users through API calls and private deployment.
After being fully opened in the form of an API, Baichuan2-192K can be deeply integrated with a large number of vertical scenarios, playing a role in people's work, life, and learning, and greatly improving industry users' efficiency. Baichuan2-192K can process and analyze hundreds of pages of materials at once, providing significant assistance in extracting and analyzing key information from long documents, summarizing long documents, reviewing long documents, and assisting in writing long articles or reports, as well as complex programming.
Previously, Wang Xiaochuan, the founder and CEO of Baichuan Intelligence, revealed that in the second half of this year, Baichuan will launch a trillion-level big model, and next year is expected to deploy a C-end super application.
Facing the gap with OpenAI, Wang Xiaochuan admitted that in terms of ideals, we do have a gap with OpenAI. OpenAI's goal is to explore the ceiling of intelligence; they even hope to design a technology that connects 10 million GPUs. However, in terms of application, we are moving faster than the United States. The experience accumulated in the Internet era in terms of applications and ecosystems allows us to move faster and further. Therefore, Baichuan's concept of developing big models is called "slow in ideals, but fast in implementation."
From this perspective, Baichuan2-192K is an extension of this concept, and undoubtedly, the world's longest context window will accelerate the process of Baichuan Intelligence's big model technology landing.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







