
Image source: Generated by Unbounded AI
Large language models (LLMs), especially generative pre-trained transformer (GPT) models, have shown excellent performance in many complex language tasks. This breakthrough has led people to hope to run these LLMs locally on mobile devices to protect user privacy. However, even small LLMs are too large to run on these devices.
For example, a small LLaMA with 7B parameters has an FP16 version size of 14GB, while mobile devices only have 18GB of DRAM. Therefore, compressing LLMs through training time optimization (such as sparsity, quantization, or weight clustering) is a key step in deploying LLMs on devices. However, due to the model size and computational resource overhead, training time optimization for LLMs is very expensive. One of the state-of-the-art (SOTA) weight clustering algorithms, DKM, requires high computational resource demand due to the need to analyze the interactions between all weights and all possible clustering options.
Therefore, many existing LLM compression technologies, such as GTPQ and AWQ, rely on post-training optimization. In this paper, the researchers propose memory optimization techniques to achieve training time weight clustering and its application in DKM, namely eDKM.
The techniques used in this paper include cross-device tensor arrangement and weight matrix uniquification and slicing. When using eDKM to fine-tune the LLaMA 7B model and compress it to occupy only 3 bits per weight factor, the researchers achieved a reduction in decoder stack memory usage of approximately 130 times, surpassing existing 3-bit compression technologies.
Improving the Memory Efficiency of DKM
As shown in Figure 1, pruning, quantization, and normalization are popular weight optimization techniques, which optimize the original weight W to obtain the optimized weight
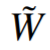
. Among these techniques, the researchers in this paper mainly focus on weight clustering, particularly the weight clustering algorithm DKM.
Weight clustering is a form of non-linear weight discretization, where the weight matrix is compressed into a lookup table and a low-precision index list for the lookup table, which modern inference accelerators can handle. DKM performs differentiable weight clustering by analyzing the interactions between weights (denoted as W) and centroids (denoted as C), making trade-offs between compression ratio and accuracy.
Therefore, using DKM for LLM compression produces high-quality results. However, the attention map generated during DKM computation is large, and the memory complexity of forward/backward propagation is O(|W||C|) (i.e., the matrix in Figure 1), which is particularly challenging for LLM compression. For example, a LLaMA 7B model requires at least 224GB of memory to compute the attention map for 4-bit weight clustering.
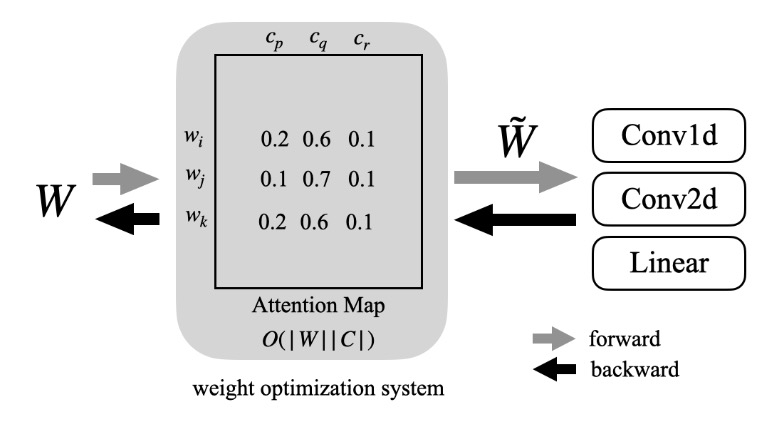
Figure 1: Overview of the weight optimization system. In DKM, a differentiable weight clustering attention map is created internally.
Therefore, the researchers need to use CPU memory to handle such large memory requirements, i.e., store the information in CPU memory first and then copy it back to the GPU when needed. However, this will generate a large amount of traffic between the GPU and CPU (slowing down the training speed) and require a huge CPU memory capacity. This means that reducing the number of transactions between the CPU and GPU and minimizing the traffic per transaction is crucial. To address these challenges, the researchers introduced two new memory optimization techniques in PyTorch.
- Cross-device tensor arrangement: Tracking tensors replicated across devices to avoid redundant copies, reducing memory usage and speeding up training.
- Weight uniquification and slicing: Utilizing the fact that there are only 216 unique values for 16-bit weights to reduce the representation of the attention map (as shown in Figure 1) and further distribute it to multiple learning models.
Cross-Device Tensor Arrangement
PyTorch uses data storage to represent tensors, where data storage is linked to the actual data layout and metadata, which is used to store the shape and type of the tensor. This tensor architecture allows PyTorch to reuse data storage as much as possible, effectively reducing memory usage. However, when a tensor is moved to another device (e.g., from GPU to CPU), the data storage cannot be reused, requiring the creation of a new tensor.
Table 1 illustrates the memory usage when tensors are moved between PyTorch devices. The tensor x0 allocated in the first row consumes 4MB on the GPU. When its view is changed in the second row, since the underlying data storage can be reused (i.e., x0 and x1 are actually the same), no additional GPU memory is needed. However, when x0 and x1 are moved to the CPU as in the third and fourth rows, although y0 and y1 can share the same data storage on the CPU, the CPU memory consumption becomes 8MB, leading to CPU memory redundancy and increased traffic from the GPU to the CPU.

Table 1: LLM fine-tuning may require using CPU memory to offload GPU memory usage. Lack of cross-device tensor management leads to redundant copies across devices (especially when the computation graph is complex), which is particularly disadvantageous for training time optimization of LLMs. For example, although x0 and x1 are the same tensors with different views, when copied to the CPU, the resulting tensors y0 and y1 do not share data storage, while x0 and x1 share data storage on the GPU.
To address this inefficiency, the researchers placed an arrangement layer as shown in Figure 2 (b), where black represents actual data storage and metadata, and gray only represents metadata. Figure 2 (a) shows the example from Table 1, where x1 shares the data layout with x0, but y0 and y1 have redundant data storage on the CPU. As shown in Figure 2 (b), by inserting the arrangement layer, the researchers avoided this redundancy and reduced the traffic from the GPU to the CPU. The researchers used the save-tensor-hook in PyTorch to implement such a swapping scheme, checking whether the same data storage has been copied.
However, using such a scheme to check for the presence of the same tensor on the target device is expensive. In the example in Figure 2 (b), the researchers did not copy x1 to the CPU, but simply returned a reference to y0 and the view operation between x1 and y0.
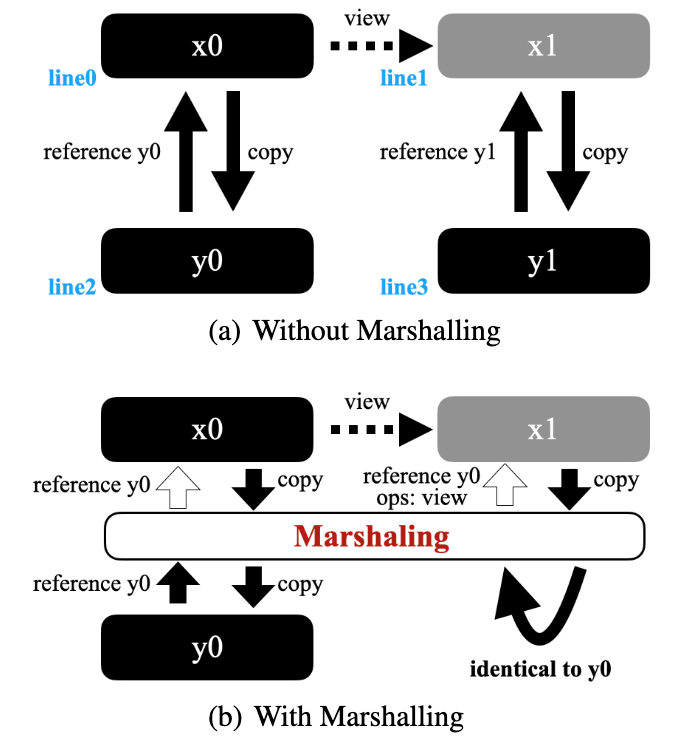
Figure 2: Applying cross-device tensor arrangement to the scenario in Table 1 can avoid redundancy on the CPU side, saving memory and traffic.
Browsing the computation graph will add extra computational cycles, and saving unnecessary copies can compensate for such overhead. Researchers found that a search within 4 hops is sufficient to detect all eligible cases in the original DKM implementation's computation graph.
Weight Uniquification and Slicing
In the training of most LLMs, weights are commonly stored using 16-bit storage (such as BF16 or FP16), which means that despite having billions of parameters in the LLM, there are only 216 unique coefficients due to the bit width. This provides an opportunity for significant compression of the attention map between weights and centroids, as shown in Figure 3.
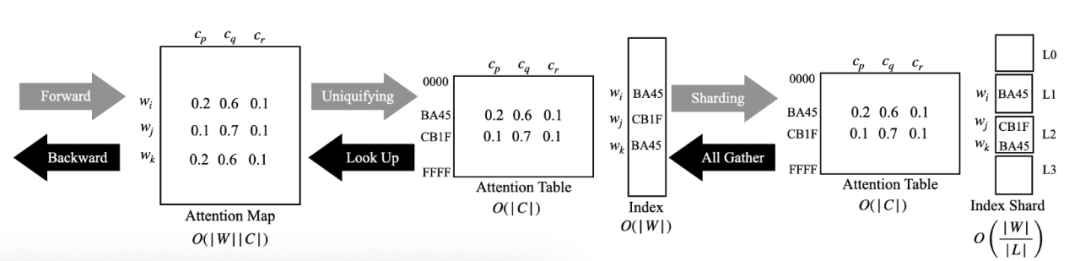
Figure 3: Weight Uniquification and Slicing
Experimental Results
LLM Accuracy
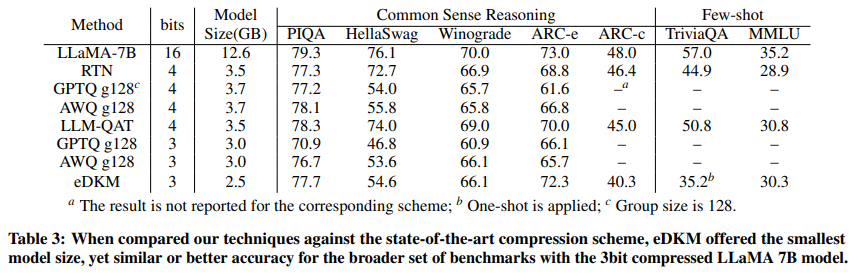
In this paper, eDKM was compared with other quantization-based compression schemes, including: RTN, SmoothQuant, GPTQ, AWQ, and LLM-QAT. For eDKM, the researchers also performed 8-bit compression on the embedding layer. The following conclusions were drawn:
- eDKM outperforms all other 3-bit compression schemes for compressing the LLaMA 7B model.
- eDKM exhibits the best accuracy in the ARC-e benchmark tests for both 3-bit and 4-bit configurations.
- In the PIQA and MMLU benchmark tests using the 4-bit compressed model, eDKM's performance is highly competitive.
Ablation Study
In the ablation study, the researchers measured the trade-off between memory usage and the forward-backward speed of 3-bit compression for an attention layer in the LLaMA 7B decoder stack. The cross-device tensor arrangement alone reduced memory usage by 2.9 times with minimal runtime overhead, while the slicing and uniquification modules saved 23.5 times and 16.4 times, respectively. When all techniques were combined, eDKM achieved approximately 130 times memory savings. Although these steps incurred additional computational and communication overhead, the runtime overhead was negligible due to the significant reduction in traffic between the GPU and CPU.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







