Source: Synced
Recently, Fudan University's Natural Language Processing Team (FudanNLP) released a comprehensive review paper on LLM-based Agents, with a total length of 86 pages and over 600 references! The authors comprehensively reviewed the current status of intelligent agents based on large-scale language models, including the background, composition, application scenarios, and the highly anticipated agent society. At the same time, the authors discussed forward-looking open issues related to agents, which are of significant value for the future development trends in related fields.

- Paper link: https://arxiv.org/pdf/2309.07864.pdf
- LLM-based Agent paper list: https://github.com/WooooDyy/LLM-Agent-Paper-List
The team members will also add a "one-sentence summary" for each related paper and welcome stars for the repository.
Research Background
For a long time, researchers have been pursuing general artificial intelligence (AGI) that is comparable to, or even surpasses, human intelligence. As early as the 1950s, Alan Turing extended the concept of "intelligence" to artificial entities and proposed the famous Turing test. These artificial intelligence entities are commonly referred to as agents. The concept of "agent" originated from philosophy, describing an entity with desires, beliefs, intentions, and the ability to take action. In the field of artificial intelligence, this term has been given a new meaning: intelligent entities with autonomy, reactivity, proactivity, and social capabilities.
Since then, the design of agents has been a focus of the artificial intelligence community. However, past work has mainly focused on enhancing specific capabilities of agents, such as symbolic reasoning or mastering specific tasks (chess, Go, etc.). These studies have focused more on algorithm design and training strategies, while neglecting the development of the inherent general capabilities of models, such as knowledge memory, long-term planning, effective generalization, and efficient interaction. It has been proven that enhancing the inherent capabilities of models is a key factor in driving the further development of intelligent agents.
The emergence of large-scale language models (LLMs) has brought hope for the further development of intelligent agents. If the development path from NLP to AGI is divided into five levels: corpus, internet, perception, embodiment, and social attributes, then the current large-scale language models have reached the second level, with text input and output on an internet scale. Based on this foundation, if LLM-based Agents are given perception space and action space, they will reach the third and fourth levels. Furthermore, multiple agents interacting and cooperating to solve more complex tasks, or reflecting social behaviors in the real world, have the potential to reach the fifth level: agent society.
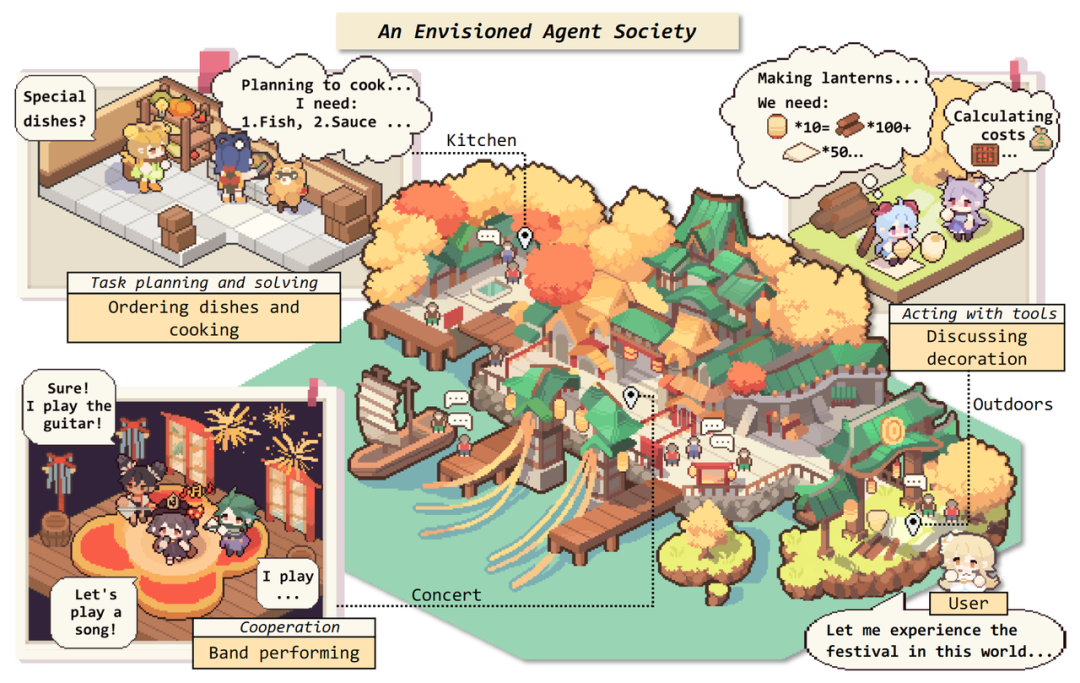
The authors envision a harmonious society composed of intelligent agents, in which humans can also participate. The scene is inspired by the Lantern Rite in "Genshin Impact".
The Birth of an Agent
What will an intelligent agent with the support of a large model be like? Inspired by Darwin's "survival of the fittest" principle, the authors proposed a general framework for intelligent agents based on large models. Just as a person needs to adapt to the environment in order to survive in society, they need cognitive abilities to perceive and respond to changes in the external environment. Similarly, the framework of intelligent agents consists of three parts: the control end (Brain), the perception end (Perception), and the action end (Action).
Control End: Usually composed of LLMs, it is the core of intelligent agents. It not only stores memory and knowledge but also performs essential functions such as information processing and decision-making. It can present the process of reasoning and planning, and effectively handle unknown tasks, reflecting the generalization and transferability of intelligent agents.
Perception End: It expands the perception space of intelligent agents from pure text to include multimodal fields such as text, vision, and hearing, enabling agents to more effectively obtain and utilize information from the surrounding environment.
Action End: In addition to conventional text output, it endows agents with embodiment and the ability to use tools, enabling them to better adapt to environmental changes, interact with the environment through feedback, and even shape the environment.
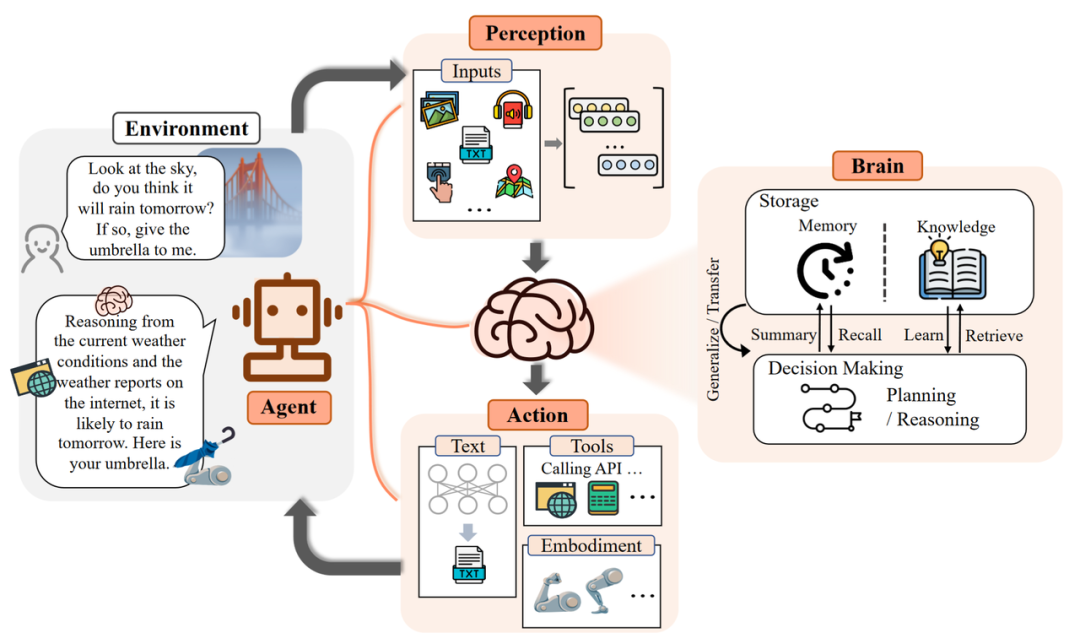
Conceptual framework of LLM-based Agent, including three components: control end (Brain), perception end (Perception), and action end (Action).
The authors used an example to illustrate the workflow of an LLM-based Agent: when a human asks if it will rain, the perception end (Perception) converts the command into a representation that LLMs can understand. Then the control end (Brain) begins reasoning and action planning based on the current weather and internet weather forecasts. Finally, the action end (Action) responds and hands the umbrella to the human.
By repeating the above process, intelligent agents can continuously receive feedback and interact with the environment.
Control End: Brain
As the most core component of intelligent agents, the authors introduced its capabilities from five aspects:
Natural Language Interaction: Language is a medium of communication containing rich information. Thanks to the powerful natural language generation and understanding capabilities of LLMs, intelligent agents can interact with the outside world through multi-turn interactions in natural language to achieve their goals. Specifically, it can be divided into two aspects:
High-quality text generation: Numerous evaluation experiments have shown that LLMs can generate fluent, diverse, novel, and controllable text. Although they perform poorly in individual languages, they generally have good multilingual capabilities.
Understanding implicatures: In addition to the explicit content, language may also convey the speaker's intentions, preferences, and other information. Understanding implicatures helps agents communicate and cooperate more efficiently, and large models have shown potential in this area.
Knowledge: LLMs trained on large-scale corpora have the ability to store massive knowledge. In addition to language knowledge, common sense knowledge and professional skill knowledge are important components of LLM-based Agents.
Although LLMs still have issues such as outdated knowledge and illusions, some existing research has alleviated these issues to a certain extent through knowledge editing or accessing external knowledge bases.
Memory: In this framework, the memory module stores the agent's past observations, thoughts, and action sequences. Through specific memory mechanisms, agents can effectively reflect and apply previous strategies, enabling them to draw on past experiences to adapt to unfamiliar environments.
There are three common methods used to enhance memory capabilities:
Extending the length limit of the Backbone architecture: Improvements are made to address the inherent sequence length limitation of Transformers.
Summarizing memory: Summarizing the memory enhances the agent's ability to extract key details from the memory.
Compressing memory: Compressing the memory using vectors or appropriate data structures can improve memory retrieval efficiency.
In addition, the method of memory retrieval is also crucial, as only by retrieving appropriate content can the agent access the most relevant and accurate information.
Reasoning & Planning: Reasoning ability is crucial for intelligent agents to make decisions, analyze complex tasks, etc. Specifically for LLMs, it is represented by a series of prompting methods such as Chain-of-Thought (CoT). Planning is a commonly used strategy when facing large challenges. It helps agents organize their thoughts, set goals, and determine the steps to achieve these goals. In specific implementation, planning can include two steps:
Plan formulation: Agents decompose complex tasks into more manageable subtasks. For example: decomposing and executing in sequence, step-by-step planning and execution, multi-path planning and selecting the optimal path, etc. In some scenarios that require domain-specific knowledge, agents can integrate with specific domain Planner modules to enhance their capabilities.
Plan reflection: After formulating a plan, reflection and evaluation of its pros and cons can be conducted. This reflection generally comes from three aspects: internal feedback mechanisms, feedback from human interaction, and feedback from the environment.
Transferability & Generalization: LLMs with world knowledge endow intelligent agents with powerful transfer and generalization capabilities. A good agent is not just a static knowledge base but should also have dynamic learning capabilities:
Generalization to unknown tasks: With the increase in model size and training data, LLMs have demonstrated remarkable capabilities in solving unknown tasks. Large models fine-tuned through instructions perform well in zero-shot testing and achieve results comparable to expert models in many tasks.
In-context learning: Large models can not only learn analogically from a small number of examples in context but also extend this capability to multimodal scenarios beyond text, providing more possibilities for the application of agents in the real world.
Continual learning: The main challenge of continual learning is catastrophic forgetting, i.e., the model is prone to lose knowledge from past tasks when learning new tasks. Intelligent agents in specific domains should try to avoid losing knowledge in general domains as much as possible.
Perception End: Perception
Humans perceive the world through multimodal means, so researchers have the same expectations for LLM-based Agents. Multimodal perception can deepen the agent's understanding of the work environment and significantly enhance its generality.
Text Input: As the most basic capability of LLMs, it is not further elaborated here.
Visual Input: LLMs themselves do not have visual perception capabilities and can only understand discrete textual content. However, visual input usually contains a wealth of information about the world, including object properties, spatial relationships, scene layouts, and more. Common methods include:
- Converting visual input into corresponding textual descriptions (Image Captioning): This can be directly understood by LLMs and has high interpretability.
- Encoding visual information: Using a paradigm of visual base models + LLMs to construct a perception module, training end-to-end through alignment operations to enable the model to understand content from different modalities.
Auditory Input: Audition is also an important part of human perception. Due to the excellent tool invocation capabilities of LLMs, an intuitive idea is that agents can use LLMs as a control hub to perceive audio information through a cascading call to existing toolsets or expert models. In addition, audio can also be represented visually through spectrograms. Spectrograms can be presented as 2D images, so some visual processing methods can be transferred to the field of speech.
Other Inputs: Information in the real world is not limited to text, vision, and hearing. In the future, the authors hope that intelligent agents will be equipped with more diverse perception modules, such as touch, smell, and other organs, to obtain richer properties of target objects. Additionally, agents should have a clear sense of the temperature, humidity, and brightness of the surrounding environment, and take more environment-aware actions.
Furthermore, agents can also be introduced to have perception of a broader overall environment: using mature perception modules such as lidar, GPS, and inertial measurement units.
Action End: Action
After the brain analyzes and makes decisions, the agent also needs to take action to adapt to or change the environment:
Text Output: As the most basic capability of LLMs, it is not further elaborated here.
Tool Usage: Although LLMs have excellent knowledge and professional capabilities, they may face challenges such as robustness and illusions when dealing with specific problems. At the same time, tools as an extension of user capabilities can provide assistance in professionalism, factualness, and interpretability. For example, using a calculator to solve mathematical problems or using a search engine to search for real-time information.
In addition, tools can also expand the action space of intelligent agents. For example, by calling expert models for speech generation, image generation, etc., to obtain multimodal ways of action. Therefore, how to make agents excellent tool users, i.e., learning how to effectively use tools, is a very important and promising direction.
Currently, the main methods of tool learning include learning from demonstrations and learning from feedback. In addition, agents can be equipped with generalization capabilities in using various tools through meta-learning, curriculum learning, and other methods. Furthermore, intelligent agents can further learn how to "self-sufficiently" create tools, thereby increasing their autonomy and independence.
Embodied Action: Embodiment refers to the ability of the agent to understand, modify the environment, and update its own state during interaction with the environment. Embodied action is considered a bridge between virtual intelligence and physical reality.
Traditional reinforcement learning-based agents have limitations in sample efficiency, generalization, and complex problem reasoning, while LLM-based Agents, by introducing rich inherent knowledge from large models, enable Embodied Agents to actively perceive and influence the physical environment like humans. Depending on the autonomy of the agent in the task or the complexity of the action, the following atomic actions can be taken:
- Observation can help intelligent agents locate themselves in the environment, perceive objects, and obtain other environmental information.
- Manipulation involves specific tasks such as grabbing and pushing.
- Navigation requires intelligent agents to change their position according to the task goal and update their own state based on environmental information.
By combining these atomic actions, agents can accomplish more complex tasks, such as embodied QA tasks like "Is the watermelon in the kitchen bigger than the bowl?" To solve this problem, the agent needs to navigate to the kitchen and determine the answer after observing the sizes of the two objects.
Due to the high cost of physical world hardware and the lack of embodied datasets, current research on embodied action is mainly focused on virtual sandbox environments such as the game "Minecraft." Therefore, on the one hand, the authors look forward to a task paradigm and evaluation standards that are closer to reality, and on the other hand, more exploration is needed in efficiently constructing related datasets.
Agent in Practice: Diverse Application Scenarios
Currently, LLM-based Agents have demonstrated remarkable diversity and powerful performance. Well-known applications such as AutoGPT, MetaGPT, CAMEL, and GPT Engineer are flourishing at an unprecedented pace.
Before introducing specific applications, the authors discussed the design principles of Agent in Practice:
- Help users break free from daily tasks and repetitive labor, reduce human work pressure, and improve task efficiency.
- No longer require users to explicitly provide low-level instructions, but can independently analyze, plan, and solve problems.
- After freeing the user's hands, try to free the brain: fully unleash potential in cutting-edge scientific fields, complete innovative and exploratory work.
Based on this, the application of agents can have three paradigms:
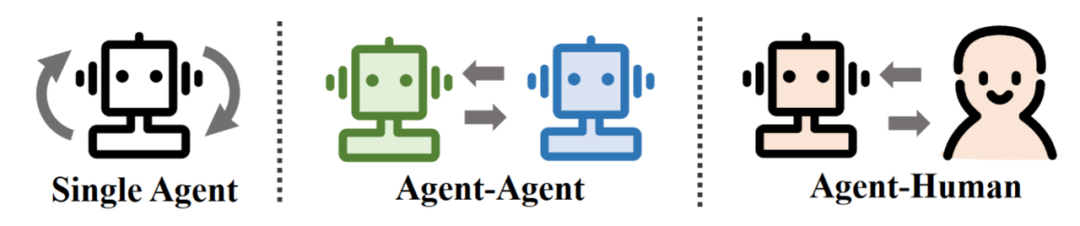
Three application paradigms of LLM-based Agent: single agent, multi-agent, human-agent interaction.
Single Agent Scenario
Intelligent agents that can accept natural language commands and perform daily tasks are currently highly valued by users and have high practical value. In the application scenarios of single intelligent agents, the authors first explained their diverse application scenarios and corresponding capabilities.
In this paper, the application of single intelligent agents is divided into the following three levels:
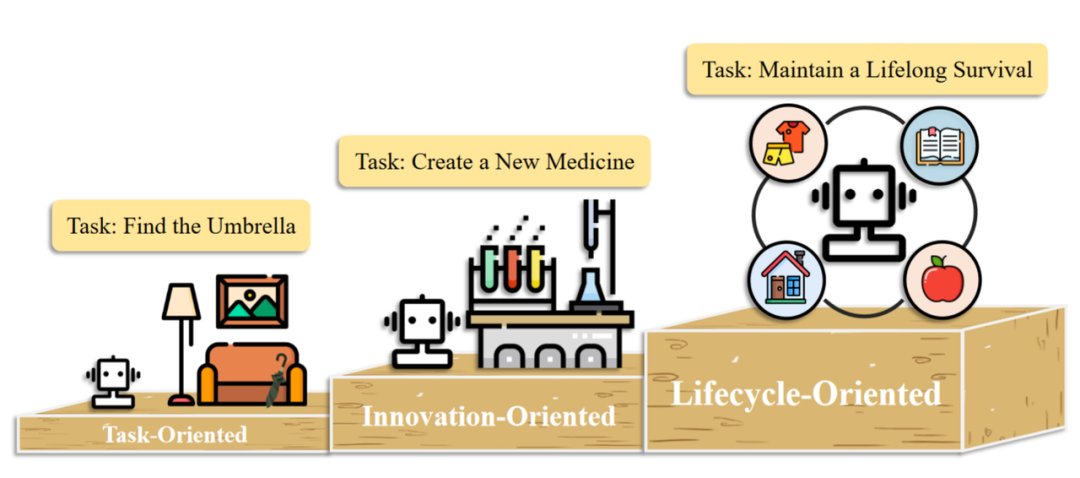
Three levels of single agent application scenarios: task-oriented, innovation-oriented, lifecycle-oriented.
- In the task-oriented deployment, agents help human users handle basic daily tasks. They need to have basic command understanding, task decomposition, and interaction with the environment. Specifically, based on existing task types, the actual application of agents can be further divided into simulating network environments and simulating life scenarios.
- In the innovation-oriented deployment, agents can demonstrate the potential for independent exploration in cutting-edge scientific fields. Although the inherent complexity of professional fields and the lack of training data pose obstacles to the construction of intelligent agents, progress has been made in fields such as chemistry, materials, and computer science.
- In the lifecycle-oriented deployment, agents have the ability to continuously explore, learn, and use new skills in an open world and survive in the long term. In this section, the authors used the game "Minecraft" as an example. Since the survival challenges in the game can be considered a microcosm of the real world, many researchers have used it as a unique platform for developing and testing the comprehensive capabilities of agents.
Multi-Agent Scenario
As early as 1986, Marvin Minsky made a forward-looking prediction. In his book "The Society of Mind," he proposed a novel theory of intelligence, suggesting that intelligence arises from the interaction of many smaller, specialized agents. For example, some agents may be responsible for pattern recognition, while others may be responsible for decision-making or generating solutions.
This idea has been concretely practiced with the rise of distributed artificial intelligence. Multi-Agent Systems, as one of the main research problems, mainly focus on how agents can effectively coordinate and collaborate to solve problems. The authors divided the interaction between multiple agents into the following two forms:
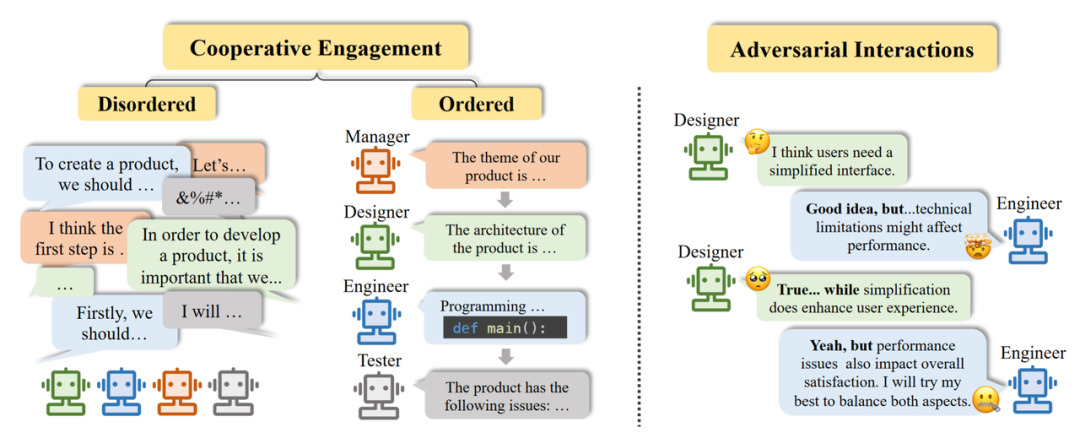
Two forms of interaction in multi-agent application scenarios: cooperative interaction, adversarial interaction.
Cooperative Interaction: As the most widely deployed type in practical applications, cooperative agent systems can effectively improve task efficiency and jointly improve decision-making. Specifically, based on different forms of cooperation, the authors further subdivided cooperative interaction into unordered cooperation and ordered cooperation.
- When all agents freely express their views and cooperate in an unordered manner, it is called unordered cooperation.
- When all agents follow certain rules, such as expressing their views one by one in a pipeline fashion, the entire cooperation process is orderly, known as ordered cooperation.
Adversarial Interaction: Intelligent agents interact in a tit-for-tat manner. Through competition, negotiation, and debate, agents abandon potentially erroneous beliefs, meaningfully reflect on their actions or reasoning processes, and ultimately improve the overall system response quality.
Human-Agent Interaction Scenario
As the name suggests, Human-Agent Interaction is the collaboration between intelligent agents and humans to complete tasks. On the one hand, the dynamic learning capabilities of agents need to be supported through communication and interaction. On the other hand, the current performance of agent systems in terms of interpretability is still insufficient, and there may be issues related to security and legality, so human participation is needed for regulation and supervision.
In the paper, the authors divided Human-Agent interaction into the following two modes:
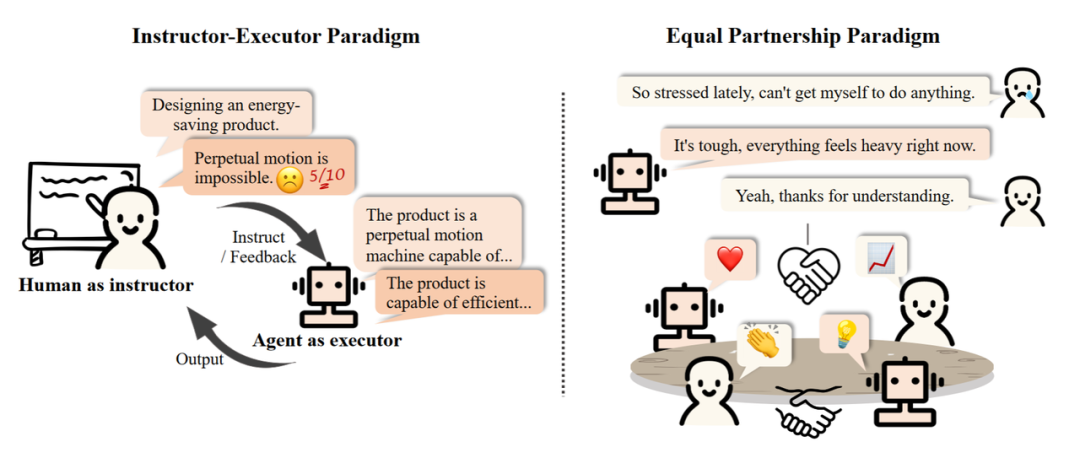
Two Modes of Human-Agent Interaction: Instructor-Executor Mode vs. Equal Partnership Mode.
- Instructor-Executor Mode: Humans act as instructors, giving instructions and providing feedback, while agents act as executors, gradually adjusting and optimizing based on the instructions. This mode has been widely used in education, healthcare, and business fields.
- Equal Partnership Mode: Research has observed that agents can demonstrate empathy in their communication with humans or participate in task execution on an equal footing. Intelligent agents show potential applications in daily life and are expected to integrate into human society in the future.
Agent Society: From Individuality to Sociality
For a long time, researchers have envisioned building an "interactive artificial society," from sandbox games like "The Sims" to the "metaverse." The definition of a simulated society can be summarized as the environment plus the individuals living and interacting within it.
In the article, the authors used a diagram to describe the conceptual framework of an agent society:
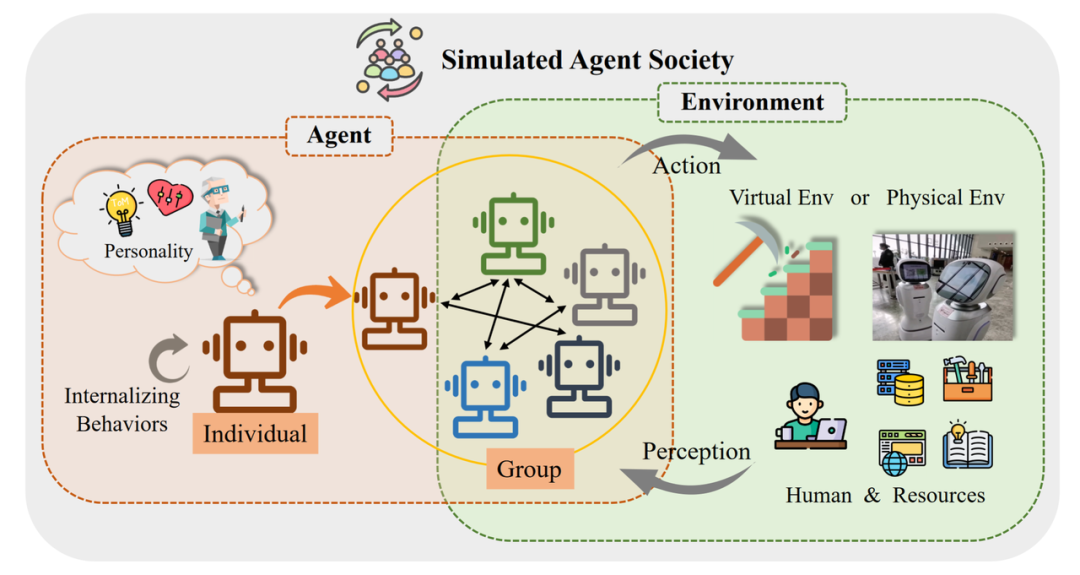
The conceptual framework of an agent society, divided into two key parts: agents and the environment.
In this framework, we can see:
Social Behavior and Personality of Agents
The article examines the performance of agents in society from external behavior and internal personality:
Social Behavior: From a social perspective, behavior can be divided into individual and collective levels:
- Individual behavior forms the basis for the operation and development of agents. This includes inputs represented by perception, outputs represented by actions, and internalized behavior of the agents themselves.
- Collective behavior refers to behavior that arises when two or more agents interact spontaneously. This includes positive behaviors represented by cooperation, negative behaviors represented by conflict, and neutral behaviors such as conformity and bystander behavior.
Personality: This includes cognition, emotion, and character. Just as humans gradually develop their own traits during the socialization process, agents also exhibit so-called "human-like intelligence," gradually shaping their personality through interaction with the group and the environment.
- Cognition: Encompasses the process of agents acquiring and understanding knowledge. Research shows that agents based on LLMs can exhibit levels of thoughtful consideration and intellectual ability similar to humans in certain aspects.
- Emotion: Involves subjective feelings and emotional states, such as joy, anger, sadness, as well as the ability to show sympathy and empathy.
- Character: Researchers have used mature assessment methods such as the Big Five personality traits and the MBTI test to explore the diversity and complexity of character portrayal in LLMs.
Simulated Social Operating Environment
The agent society is not only composed of independent individuals but also includes the environment with which they interact. The environment influences the perception, actions, and interactions of the agents. In turn, agents also change the state of the environment through their behavior and decisions. For individual agents, the environment includes other autonomous agents, humans, and available resources.
In this context, the authors discussed three types of environments:
Text-based Environment: Since LLMs primarily rely on language as their input and output format, a text-based environment is the most natural operating platform for agents. Describing social phenomena and interactions through text, the text environment provides semantic and background knowledge. Agents exist in this text world, relying on textual resources to perceive, reason, and take action.
Virtual Sandbox Environment: In the field of computing, a sandbox refers to a controlled and isolated environment commonly used for software testing and virus analysis. The virtual sandbox environment of the agent society serves as a platform for simulating social interactions and behavioral simulations. Its main features include:
- Visualization: It can use simple 2D graphics interfaces or even complex 3D modeling to depict all aspects of the simulated society in an intuitive manner.
- Scalability: It can build and deploy various scenarios (web, games, etc.) for various experiments, providing agents with a broad exploration space.
Real Physical Environment: The physical environment is a tangible environment composed of actual objects and space, where agents observe and act. This environment introduces rich sensory inputs (visual, auditory, and spatial). Unlike virtual environments, the physical space imposes more demands on agent behavior. Agents in the physical environment must adapt and generate executable motion control.
The authors provided an example to explain the complexity of the physical environment: Imagine an intelligent agent operating a robotic arm in a factory. Operating the robotic arm requires precise control of force to avoid damaging objects of different materials. Additionally, the agent needs to navigate within the physical workspace, adjust the movement path in a timely manner, and optimize the motion trajectory of the robotic arm to avoid obstacles.
These requirements increase the complexity and challenges for agents in the physical environment.
Simulation, Start!
In the article, the authors believe that a simulated society should have openness, persistence, contextuality, and organization. Openness allows agents to enter and exit the simulated society autonomously; persistence refers to the society's coherent trajectory that develops over time; contextuality emphasizes the presence and operation of subjects in specific environments; and organization ensures that the simulated society has rules and constraints similar to the physical world.
As for the significance of a simulated society, Stanford University's Generative Agents Town provides a vivid example—Agent society can be used to explore the boundaries of collective intelligence, such as when agents jointly organize a Valentine's Day party. It can also accelerate research in social science, such as observing phenomena in communication studies through simulating social networks. Additionally, research uses simulated moral decision-making scenarios to explore the values behind agents and simulates the impact of policies on society to assist decision-making.
Furthermore, the authors pointed out that these simulations may also pose certain risks, including but not limited to harmful social phenomena, stereotypes and biases, privacy and security issues, and overreliance and addiction.
Forward-looking Open Questions
In the final section of the paper, the authors also discussed some forward-looking open questions, providing food for thought for readers:
How can research on intelligent agents and large language models mutually promote and develop together? Large models have shown powerful potential in language understanding, decision-making, and generalization, becoming a key role in the construction of agents, while the progress of agents also raises higher demands for large models.
What challenges and concerns will LLM-based Agents bring? Whether intelligent agents can truly land requires rigorous security assessments to avoid harm to the real world. The authors summarized more potential threats, such as illegal use, unemployment risks, and impacts on human well-being.
What opportunities and challenges will scaling up the number of agents bring? Increasing the number of individuals in a simulated society can significantly enhance the credibility and authenticity of the simulation. However, as the number of agents increases, communication and message propagation issues become quite complex, and information distortion, misunderstanding, or illusion phenomena can significantly reduce the efficiency of the entire simulation system.
Debate on whether LLM-based Agents are the appropriate path to AGI. Some researchers believe that large models like GPT-4 have been trained on a sufficient amount of data and agents built on this basis have the potential to be the key to unlocking AGI. However, other researchers believe that auto-regressive language modeling alone cannot demonstrate true intelligence because they only respond. A more comprehensive modeling approach, such as a world model, is needed to lead to AGI.
The evolutionary history of collective intelligence. Collective intelligence is a process of gathering people's opinions and transforming them into decisions. However, simply increasing the number of agents will not necessarily produce true "intelligence." Additionally, how to coordinate individual agents to help the intelligent agent society overcome "groupthink" and individual cognitive biases.
Agent as a Service (AaaS). Due to the complexity of LLM-based Agents compared to large models themselves, it is more difficult for small and medium-sized enterprises or individuals to build them locally. Therefore, cloud providers may consider landing intelligent agents in the form of a service, known as Agent-as-a-Service. Like other cloud services, AaaS has the potential to provide users with high flexibility and on-demand self-service.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






