Authors: Li Han, Zhu Yue
Editor: Lizi
Source: Jiazi Light Year
The Miao Ya camera is on fire.
Without the need for high prices or time-consuming makeup, with only 9.9 yuan and 20 personal photos, you can use AI to generate exquisite photos comparable to "hippocampus" and "innocent blue".
With its low price and good generation effect, "Miao Ya Camera" quickly became popular after its launch.
However, this time, it's not just the product that became popular, but also the user agreement that was similar to "hegemonic terms" at the time.
According to media reports, the "authorization license" clause in the initial version of the Miao Ya camera's user agreement was controversial. In short: users authorize Miao Ya camera to use this information for free and permanently.

"This operation is actually the default option for countless domestic software and apps, but saying it openly can be considered 'bold'," said a person in charge of an internet data information security company to "Jiazi Light Year".
In the face of user doubts, Miao Ya camera quickly revised the relevant regulations and issued an apology statement on official WeChat accounts, Xiaohongshu, and other platforms, stating: "We have received feedback from users about the user agreement, and the original agreement was incorrect. We have made modifications based on the actual situation of Miao Ya for the first time. Here, we solemnly promise that the photos you upload will only be used for digital avatar creation, will not be extracted, and will not be used for identification or other purposes, and will be automatically deleted after the avatar creation is completed."
In fact, "the difficulty of balancing internet service and data security" has always been a thorny issue. The authorization issue in the Miao Ya camera user agreement is just a microcosm of the data security issue on the internet.
Wang Yi, a partner at Beijing Zhide Law Firm, who has long been focused on data compliance, and has provided data compliance services to many listed companies and well-known enterprises at home and abroad, told "Jiazi Light Year": "There are currently many infringement cases caused by 'AI face swapping' software, and the number of cases involving the infringement of personal privacy data using AI technology is also gradually increasing."
Users are in a passive position, making it difficult to ensure the security of their data. The sense of powerlessness in privacy protection is spreading from the internet era to the AI era. However, it is obvious that in the AI era, the competition for data by companies is more intense, and the challenges to the privacy and security of user data are more severe.
Large-scale model training not only requires rich datasets, but also increasingly demands high-quality data. Because it involves the interaction between humans and AI, the rights of users' personal information are difficult to protect, and technology developers and service providers also face potential compliance risks.
When the age-old problem meets new technological changes, what kind of data security battle will be fought in the era of large models?
In the balance between innovation and security, legal norms, corporate autonomy, and data security technology are providing their answers.
1. In the era of large models, new challenges for data security
Data is the nourishment for the development of AI. While people easily obtain data, discussions about data security are ongoing.
In 2013, the online dictionary Dictionary.com selected "Privacy" as the word of the year. At that time, the Prism program of the U.S. government was exposed, and Google modified its privacy policy to integrate user data from its various services. Personal privacy became the most prominent aspect of data security, with the widest impact.
Compared to the coverage of user internet habits and consumption records by the internet, the emergence of AI applications such as facial recognition, smart devices, and AI face swapping has greatly expanded the scope of personal information collection, including strong personal attribute biometric information such as faces, fingerprints, voiceprints, irises, heartbeats, and genes.
In 2017, the first criminal case of using AI to infringe on citizens' personal information was cracked in Shaoxing, Zhejiang, China, involving the illegal acquisition of over 1 billion pieces of citizens' personal information.
Du Yuejin, Chief Security Officer of 360 Group, previously stated in an interview with "Jiazi Light Year": "The security of artificial intelligence and big data must be considered together."
The emergence of generative AI and large models has posed unprecedented requirements for data and brought more prominent data security issues.
In terms of the training data volume of large models, taking OpenAI's GPT model as an example: the pre-training data volume of GPT-1 was only 5GB; by the time of GPT-2, the data volume had increased to 40GB; and the data volume of GPT-3 had directly soared to 45TB (equivalent to 1152 times the data volume of GPT-2).
It has gradually become a consensus in the market: he who has the data has the world, and data is the key to the competition of large models.
An expert from TopSec told "Jiazi Light Year": "Models need data for training. In addition to self-collection, data is also obtained through web crawling. Most of the data obtained through crawling has not been authorized by the data owner, so it can be said that most of it is unauthorized use."
In November 2022, OpenAI and GitHub jointly launched the code assistant Copilot, which was sued by programmers. The plaintiffs believed that Copilot used public repositories for training without the authorization of GitHub users.
In June of this year, OpenAI also received a 157-page lawsuit for using personal privacy data without permission.
In addition to the training phase of the model, the risk of personal privacy leakage continues to exist in the actual application phase of the model.
An expert from TopSec told "Jiazi Light Year" that generative AI not only leaks people's privacy and secrets, but also makes people transparent. "Just like the sophons in 'The Three-Body Problem,' what the questioner says will be recorded, and the data information generated from production and life will become the material for AIGC training."
As early as 2020, it was discovered that OpenAI's GPT-2 would reveal personal information in the training data. Subsequent investigations found that the larger the language model, the higher the probability of privacy information leakage.
In March of this year, several ChatGPT users saw other people's conversation records in their own chat history, including user names, email addresses, payment addresses, the last four digits of credit card numbers, and credit card expiration dates.
In less than a month, Samsung Electronics faced three data leakage incidents due to employees using ChatGPT: its semiconductor equipment measurements, yield/defect rates, and internal meeting content were uploaded to ChatGPT's servers. Subsequently, Samsung immediately banned employees from using chatbots similar to ChatGPT on company devices and intranet, and other companies that were also banned included Apple, Amazon, and Goldman Sachs, among the Fortune 500 companies.
The law firm Guantao issued the "White Paper on the Development and Regulation of Generative AI (Part Three)," explaining the particularity of large models in application. The interaction between large models and humans is different from the collection of personal information in general applications, so the disclosure of personal information is not the same as the usual "public disclosure," but more like a "passive disclosure," meaning that when a user's real personal information is excerpted in the corpus, any user can subsequently learn the relevant personal information through inquiries and other means.
This means that in the era of large models, not only has the scope of personal information leakage expanded, the process of collecting personal information has become more secretive and difficult to discern, and once infringed, it constitutes infringement against a large number of users. So, where does the leaked personal information go? What impact will it have on users?
Wang Yi, a partner at Beijing Zhide Law Firm, provided the answer to "Jiazi Light Year." He said that the personal information leakage caused by generative AI could, at the very least, infringe on the right of publicity of others, making it convenient for rumor mongers, and at worst, it could be exploited by criminals to commit crimes.
The security expert from TopSec also stated that in the current situation where all internet products or software may be embedded with AI elements, the social problems caused by AI abuse will become more and more prevalent. "Forgery will become easier, seeing is not necessarily believing, and telecom fraud and internet fraud will become increasingly complex."
In May 2023, security technology company McAfee conducted a survey of 7,054 people from seven countries and found that one-quarter of adults had experienced some form of AI voice fraud (10% occurred to themselves, and 15% occurred to people they knew), resulting in economic losses for 10% of the victims.
"Jiazi Light Year" found from the Huike News Database and public reports that there have been at least 14 cases of using AI technology to steal personal privacy for fraud across the country this year.
Most of these cases involved contacting victims through video calls, and the lifelike faces and voices made people lower their guard, quickly gaining the trust of victims by impersonating friends and relatives. The amount of fraud was mostly over tens of thousands of yuan, with the highest amount defrauded reaching as high as 4.3 million yuan.
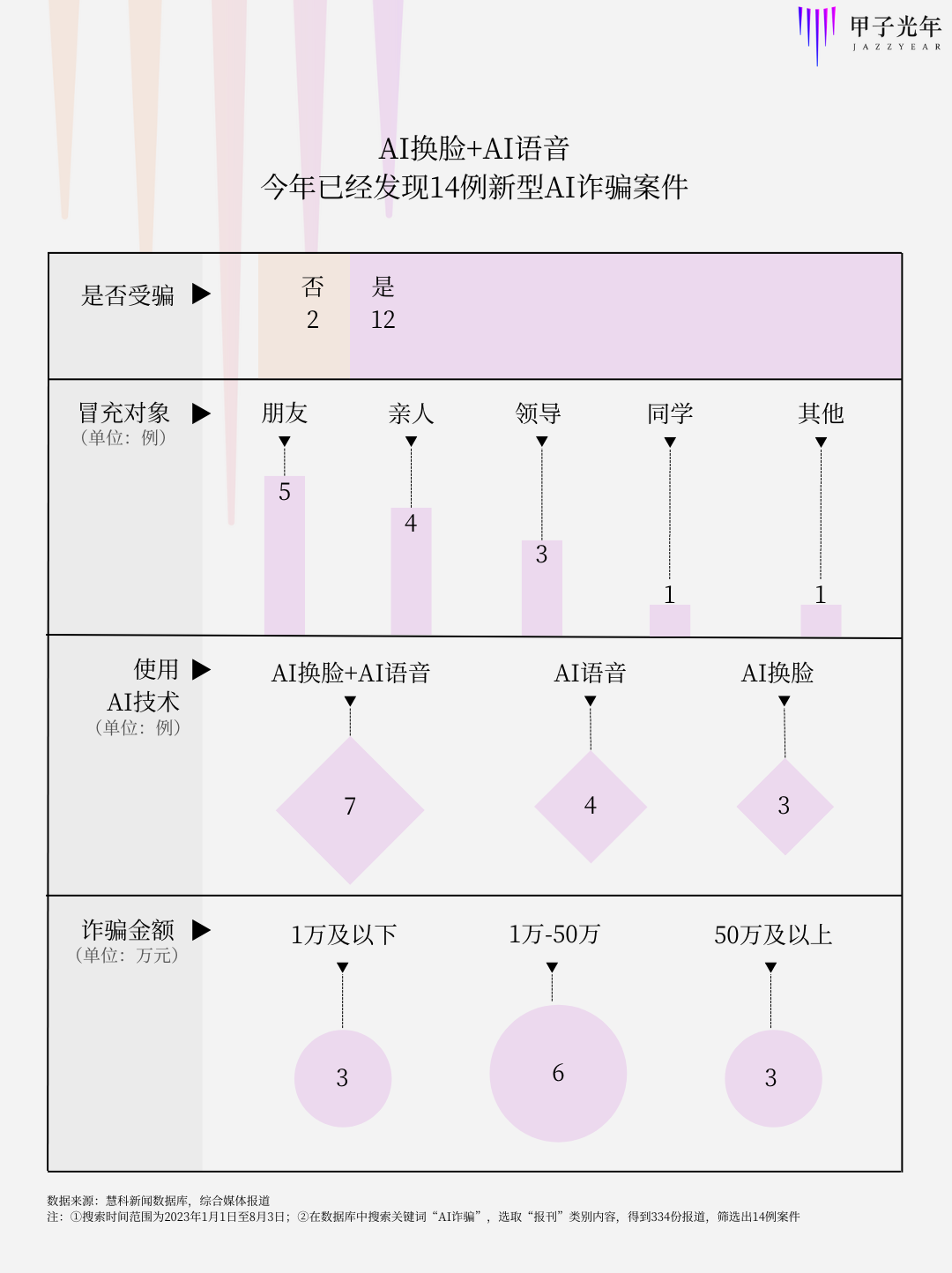
In addition, there have been numerous cases of infringement of the right of publicity caused by "AI face swapping." Wang Yi stated that although the number of such cases is gradually increasing, due to their strong concealment and being minor infringements, many cases have not gone to court. Even if they have been tried in court, the amount of compensation obtained is not high.
It can be said that ordinary people actually have very few options when facing personal privacy infringements using AI technology.
2. Stringent legislative attitudes are not the only solution to regulation
Technological development and legal regulation always go hand in hand. If data security has become the inevitable question of the era of artificial intelligence, then law and regulation are the key to the answer.
In April of this year, the Stanford Institute for Human-Centered Artificial Intelligence (Stanford HAI) released the "2023 Artificial Intelligence Index Report." Through research on legislative records from 127 countries, the report showed that the number of bills passed containing "artificial intelligence" increased from 1 in 2016 to 37 in 2022. After analyzing parliamentary records involving artificial intelligence in 81 countries, researchers found that the number of mentions of artificial intelligence in global legislative procedures has increased nearly 6.5 times since 2016.
Different from the "age-old" data security issues such as information plagiarism and privacy infringement, due to the interaction between humans and AI, the era of large models faces more urgent challenges in data security—difficulties in responding to the rights of personal information.
How to accurately identify the personal information collected during the interaction process? How to delineate the boundary between user services and model training? Faced with new challenges in data security, personal information security, and network security in the era of large models, new regulatory methods are urgently needed.
On July 13, 2023, the Cyberspace Administration of China issued the "Interim Measures for the Management of Generative Artificial Intelligence Services" (hereinafter referred to as the "Interim Measures," which will be implemented on August 15, 2023), which clearly stipulates the service norms for providers of generative artificial intelligence services.
In the relevant regulations concerning personal information security, the "Interim Measures" stipulates:
- Article 9: Providers should bear the responsibility of network information content producers in accordance with the law and fulfill the obligation of network information security. When it involves personal information, they should bear the responsibility of personal information processors in accordance with the law and fulfill the obligation of personal information protection. Providers should sign service agreements with users who register for their generative artificial intelligence services (hereinafter referred to as users) to clarify the rights and obligations of both parties.
- Article 11: Providers should fulfill the obligation to protect the input information and usage records of users in accordance with the law, should not collect unnecessary personal information, should not illegally retain input information and usage records that can identify the identity of users, and should not illegally provide the input information and usage records of users to others. Providers should promptly accept and process requests from individuals regarding the access, copying, correction, supplementation, and deletion of their personal information in accordance with the law.
As the detailed rules are gradually implemented and the implementation date approaches, many service providers are conducting self-inspections and self-assessments. It is understood that due to the lack of standardized data collection and usage processes, the Apple App Store has already removed multiple AIGC-related software. The urgency of data standardization is evident.
In addition to data security, the regulation of technology inevitably involves the contradiction between "development and regulation." Wang Yi, a partner at Beijing Zhide Law Firm, told "Jiazi Light Year": "How to deal with the contradiction between the two is a strategic choice for different countries."
Compared to the "Draft Measures for the Management of Generative Artificial Intelligence Services (Solicitation of Comments)" released on April 11, the "Interim Measures" has made significant changes.
The "Interim Measures" deleted the regulatory requirements for the research and development entities and changed the mandatory requirement in the "Draft Measures" that "the generated content should be true and accurate" to a non-mandatory requirement to "improve the accuracy and reliability of the generated content," and added requirements to enhance the transparency of generative artificial intelligence services.
"The regulatory authorities have deleted or relaxed many clauses in the 'Draft Measures.' From the changes in the draft before and after legislation, it can be seen that our country still prioritizes development," said Wang Yi.
In the balance between regulation and development, the modification of this regulation is not without reason. Because legislative regulation is not achieved overnight, an overly stringent legislative attitude may become a constraint on technological development. In Europe, some technology practitioners have expressed concerns about this issue.
After the launch of ChatGPT, European countries have gradually tightened their regulation of OpenAI. After Italy announced the ban on ChatGPT, Germany, France, Spain, and other countries also indicated that they are considering stricter regulation of AI chatbots due to data protection considerations.
On June 14, the latest draft of the "Artificial Intelligence Act" passed by the European Union also embodies the previous stringent legislative attitude. The Act clearly stipulates transparency and risk assessment requirements for "base models" or powerful AI systems trained on large amounts of data, including conducting risk assessments before the daily use of AI technology.
Is the speculation about the risk higher than the reality? The stringent legislative attitude of the European Union has attracted many complaints from European venture capital and technology companies.
On June 30, top executives from 150 major technology companies, founders, CEOs, and venture capitalists from across Europe jointly signed an open letter to the European Commission, warning that the legislative proposal for AI is overly restrictive.
"The approach to regulating generative artificial intelligence and applying strict compliance logic through legislation is bureaucratic because it cannot effectively achieve its purpose. In a situation where we know very little about real risks, business models, or the application of generative artificial intelligence, European law should be limited to articulating broad principles based on risk," the open letter pointed out. The legislative proposal will jeopardize Europe's competitiveness and technological sovereignty and will not effectively address the challenges we may face now and in the future.
Similarly, an official from Japan previously stated that Japan is more inclined to adopt rules that are more lenient than those of the European Union to manage AI because Japan hopes to use the technology to promote economic growth and become a leader in advanced chips.
"The greatest insecurity is not developing." A stringent legislative attitude is not the only solution to regulatory policies, and businesses and legislators should not be adversaries but should seek to be allies in ensuring data security and technological development.
For example, in the United States, technology giants such as Google, Microsoft, OpenAI, and Meta are actively building security barriers. On July 21, seven AI companies, including Google, Microsoft, OpenAI, and Meta, participated in a summit at the White House and made "eight commitments" on AI technology and research, including security, transparency, and risk. On July 26, Microsoft, Google, OpenAI, and Anthropic, four AI technology giants, announced the establishment of an industry organization called the "Frontier Model Forum" to ensure the safety and responsibility of advanced AI development.
On August 3, the Cyberspace Administration of China issued the "Management Measures for Compliance Audits of Personal Information Protection (Solicitation of Comments)," which further detailed and implemented the relevant requirements for compliance audits of personal information processors in the "Personal Information Protection Law," further improving the self-regulation of personal information processors in China.
Faced with potential compliance risks in an uncertain technological ecosystem, technology developers and service providers need to clearly define the legal paths and regulatory bottom lines for obtaining data. Only then can trainers of large models and service providers let down their guard and operate in a larger space.
Standing at the crossroads of technological change, how to balance the needs of data security and technological development and formulate more systematic and targeted regulatory rules is also a new challenge for legislators in various countries.
3. How to balance innovation and security?
"Regulation, if not moving forward, will face the risk of AI being abused; if acting hastily, it will lead to a crisis in the industry."
On July 25, Dario Amodei, Co-founder and CEO of Anthropic, Stuart Russell, Professor at the University of California, Berkeley, and Yoshua Bengio, Professor at the University of Montreal, attended a hearing on artificial intelligence held by the U.S. Senate Judiciary Committee. At the meeting, they unanimously agreed that AI needs regulation, but too much regulation is not good.
Faced with the challenge of large models to privacy data, what other solutions do we have in the game between innovation and security?
Strengthening data security protection may be the most obvious answer. Du Yuejin, Chief Security Officer of 360 Group, previously stated in an interview with "Jiazi Light Year": "Data security should not focus on what is collected, but on how the collected data is used and protected."
Privacy computing has become the optimal solution for data privacy protection in recent years. Compared to traditional encryption technology, privacy computing can analyze and compute data without revealing the original data, enabling data sharing, interoperability, computation, and modeling.
By making data "usable but invisible," it also avoids the risk of personal data leakage or improper use. This technology has already been implemented in highly sensitive fields such as healthcare, finance, and government.
In the era of large models, privacy computing is also applicable. Yan Shu, Deputy Director of the Cloud Computing and Big Data Research Institute of the China Academy of Information and Communications Technology, expressed this view at two events in July, stating that privacy computing can meet the privacy protection needs of large model prediction stages.
Specifically, different approaches to privacy computing, including trusted execution environments (TEE) and secure multi-party computation (MPC), can be combined with large models. For example, deploying TEE in the cloud and encrypting input data for inference, then decrypting it internally and performing inference, or using secure multi-party computation during the model inference stage to enhance privacy protection capabilities. However, it is worth noting that privacy computing will inevitably affect the performance of model training and inference.
In addition to strengthening data security protection, there is another method to solve privacy security issues from the source of data—synthetic data.
Synthetic data refers to the generation of virtual data based on real data samples using AI technology and algorithm models, and therefore does not contain users' personal privacy information.
With the popularity of large models, synthetic data has also received increasing attention, and the protection of privacy is a strong driving force behind research on synthetic data.
"Synthetic data solves three challenges—quality, quantity, and privacy," said Yashar Behzadi, Founder and CEO of the synthetic data platform Synthesis AI, in an interview with the technology media "VentureBeat." "By using synthetic data, companies can clearly define the training data sets they need, minimize data biases to the greatest extent, and ensure inclusivity without infringing on user privacy."
Sam Altman, Co-founder and CEO of OpenAI, also has high expectations for synthetic data.
According to the Financial Times, at an event held in London in May, when asked if he was concerned about regulatory authorities investigating potential privacy infringements by ChatGPT, Sam Altman was not particularly concerned and believed that "all data will soon be synthetic."
In the field of synthetic data, Microsoft has been very active this year. In May, Microsoft described a synthetic data set called TinyStories, generated by GPT-4, in a paper titled "TinyStories: How Small Can Language Models Be and Still Speak Coherent English?" It only contains words that a four-year-old can understand, and using it to train a simple large language model can generate fluent and grammatically correct stories.
In June, Microsoft argued in a paper titled "Textbooks Are All You Need" that AI can be trained using synthetic Python code, and this code performs quite well in programming tasks.
In the AI community, it is no longer surprising to use synthetic data for training large models. The global IT research and consulting firm Gartner predicts that by 2030, the volume of synthetic data will far exceed real data and become the main source of data for AI research.
Outside of technology, the data market is also gradually becoming clear. Wang Yi, a partner at Beijing Zhide Law Firm, told "Jiazi Light Year" that there are now data exchanges that have established a corpus area and listed related corpus data products (including text, audio, images, and other multimodal data, covering fields such as finance, transportation, and healthcare), making it convenient for technology providers and service providers to collaborate on procurement.
In Wang Yi's view, the legal and compliant use of data for large models requires generative AI service providers to first classify and categorize the data, distinguishing different data types such as personal data, business data, and important data, and then conducting legal reviews of the data sources based on the different ways these data are used, in accordance with the corresponding laws.
Regarding regulation, in order to balance data security and the development of AI, Wang Yi stated that the regulation of AI needs to prioritize different aspects: the focus should be on the regulation at the application layer, especially content regulation and personal information security. Secondly, there should be regulation at the foundational and model layers, and relevant deep synthesis algorithms should be urged to complete filing procedures in a timely manner. Lastly, attention should be paid to whether the subjects of the technology itself are involved overseas, which may involve issues such as data export and export control.
During every period of technological change, expectations and fears always go hand in hand, and the calls for development and regulation have always been equally strong.
Currently, the development of large models is still in its early stages, and the outbreak at the application layer has not yet been realized. However, AI will not stop, and how to steer its direction and balance security and innovation may be a continuous theme in the development of AI.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







