人工智能个人助理的提案始终如一:给予代理访问您的数字生活的权限,其余的由它处理。您的电子邮件、日历、笔记、设备——所有这些。您的人工智能了解。一切由您的人工智能执行。您可以安心入睡。
来自华为技术、北京工业大学、北京大学和中国科学院的研究人员刚刚建立了一个基准,以验证这是否真的成立。剧透:并没有。
Claw-Anything 同时在三个维度上评估人工智能代理:涵盖超过三个月的模拟用户活动的长时间事件流,平均每个任务有10.1个相互依赖的后端服务,以及在命令行Linux环境和图形用户界面Android环境下的多设备交互。
每个任务的平均上下文窗口为191,700个词。大多数现有基准介于1,700和12,000之间。这并不是一个小差距,而是一个完全不同的问题。这也是现实生活的感觉,而不是标准化的超特定基准。
您的人工智能对发生的事情毫无头绪
该基准的评分依据是 pass@1——代理在首次尝试时正确完成任务的概率,不允许重试。一个任务可能要求代理交叉参考几周前发现的产品价格提醒,检查用户日历中相关的约会,并从手机上对这两个操作进行处理。另一个任务可能要求它从笔记、电子邮件线程和Slack中提取最近的工作,然后从零开始制作演示文稿。
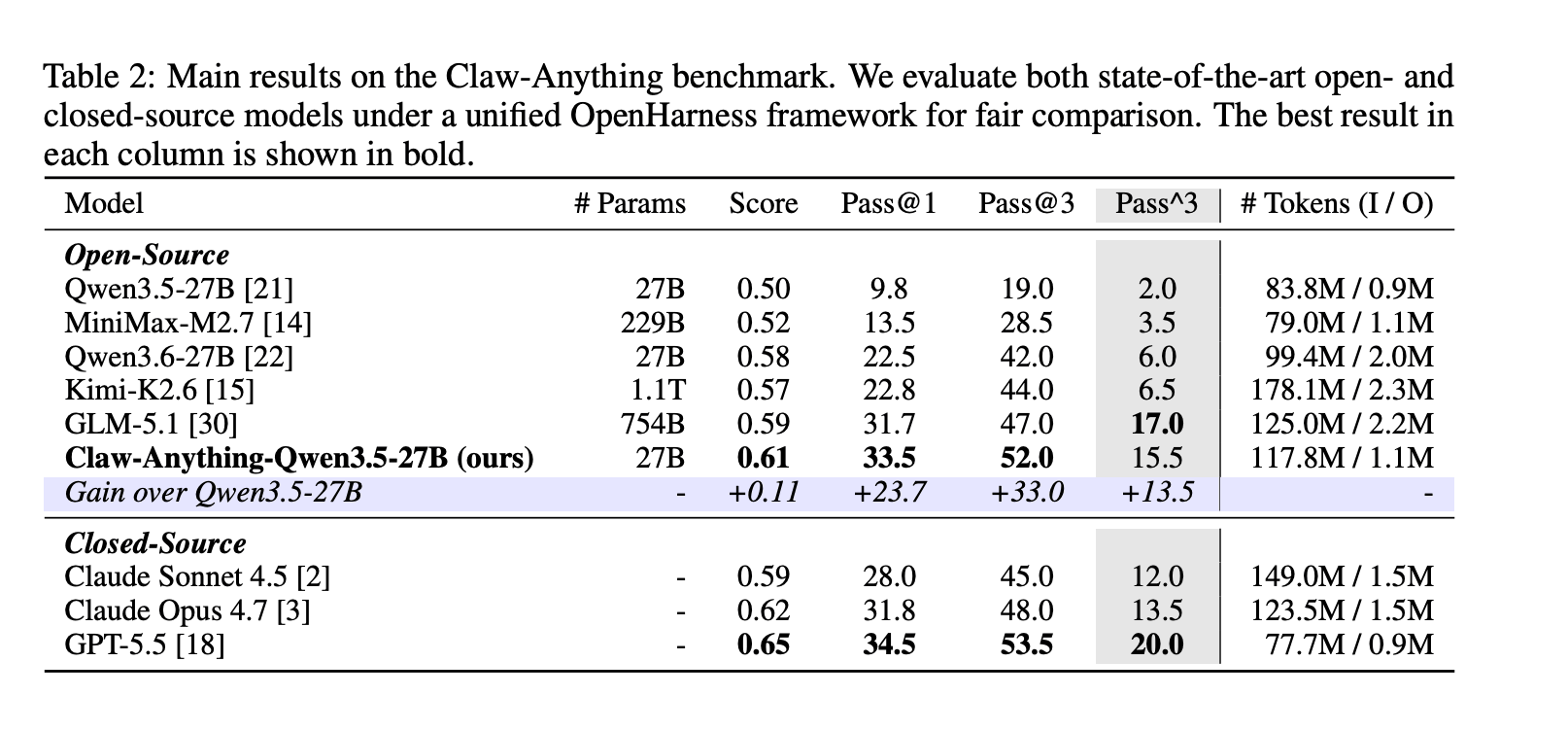
这些都是人们实际要求助手完成的事情。结果表明,人工智能在这些方面表现并不好。GPT-5.5,根据Decrypt之前的报道,是OpenAI最好的模型,考虑到代理性和长时间的任务。它的得分为34.5%。
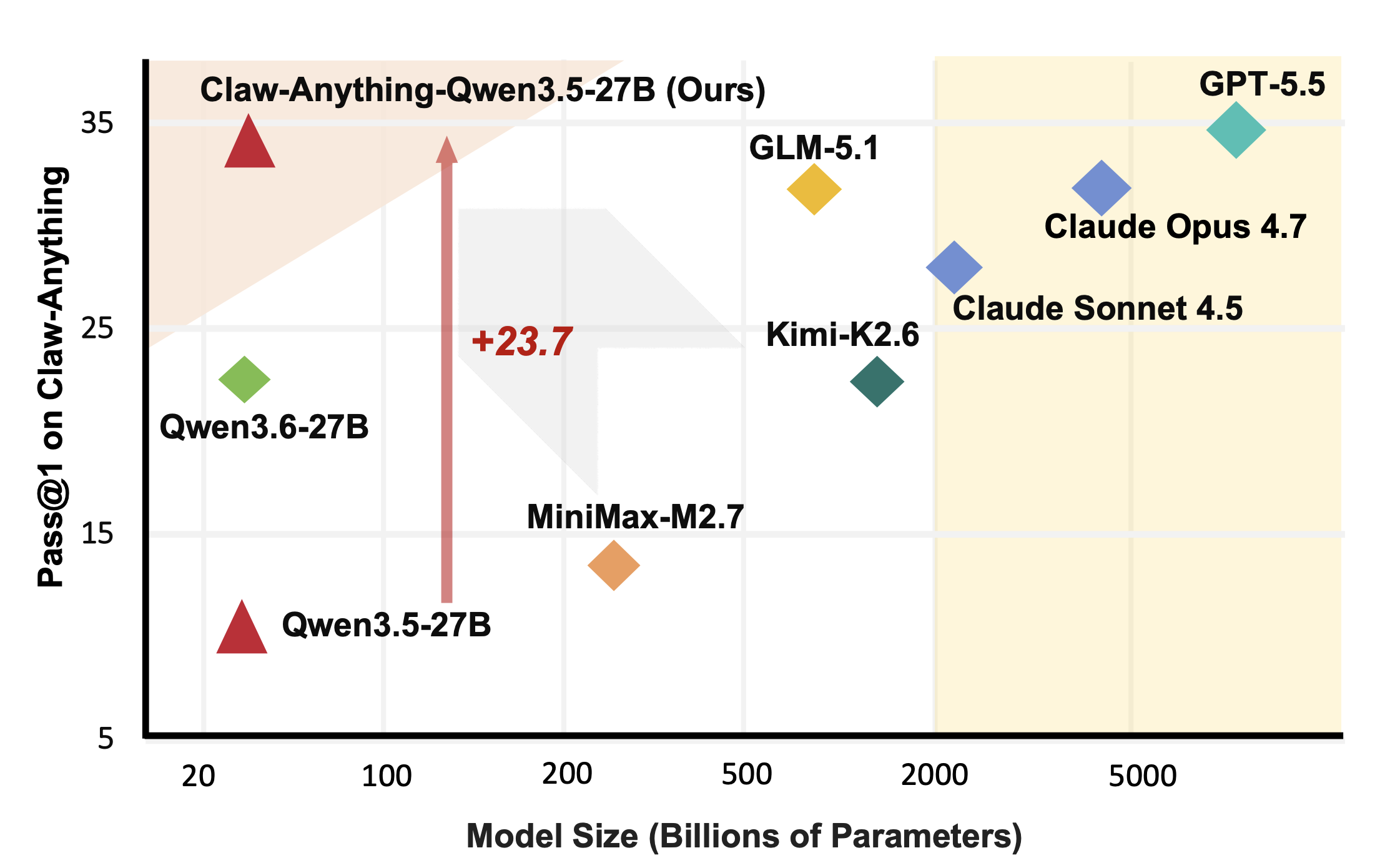
“即使在获得用户数字世界更广泛的访问权限时,当前模型仍然不可靠,”Claw-Anything论文中写道。几个在其他基准上看起来令人印象深刻的模型在这里得分更低。
该基准还分别对主动辅助进行评分,这意味着代理主动发现需求并未被请求而采取行动的情况。大多数基准并不测试这一点。Claw-Anything进行测试,而结果差异明显:代理在反应任务上的得分为25.9%,而在主动任务上的得分仅为6.7%。
为什么大多数基准不告诉您这些
研究人员提出了一个尖锐的观点:现有基准将人工智能代理视为在整洁的桌面上给予的任务求解者。Claw-Anything则将其视为被抛入实际混乱生活中的个人助理——无关事件、冲突信号、几个月积累的噪音。代理必须先弄清楚什么是相关的,然后才能做任何有用的事情。
消融结果使多服务依赖性变得特别清晰。当执行跨服务任务所需的工具被移除时,成功率几乎降至零,因为大多数任务要求代理在多个后端之间检索信息并采取行动,而不是限于单一后端。
这并不是人工智能评估中的一种新问题类型。OpenAI在今年早些时候宣布 SWE-bench受污染,此前在一个泄漏较少的版本中得分从大约70%崩溃至23%。那与数据卫生有关。这是一个更根本的问题——基准是否甚至在问正确的问题。
在建设性方面,团队发布了生成基准的管道,并提供了2,000个训练环境。在1,500个成功代理轨迹上微调Qwen3.5-27B使pass@1提升了23.7%——足以超过包括Claude Sonnet在内的多个闭源模型,跻身排行榜。
研究人员将跨服务协调确定为该基准在该领域的主要剩余挑战。数据集可在Hugging Face上获得,代码可在GitHub上找到。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







