人工智能公司不断推销自主的 网站可靠性工程师代理——人工智能替代人类调查生产事故。Datadog 在真实故障上进行了实际基准测试,而最好的人工智能模型尚未能超过他们应该替代的工程师。
该基准是 ARFBench(异常推理框架基准),这是 Datadog 和卡内基梅隆大学的联合项目。基于 63 个真实生产事故,提取自工程师在紧急情况下的 Slack 交流——750 道多项选择题,涵盖 142 个监控指标和 538 万个数据点,每道问题均经过人工验证。没有合成数据。没有教科书场景。
“每年由于系统故障造成的损失高达万亿美元,”研究人员写道。基准测试人工智能是否真的能帮助改变这种情况。
“尽管这种基于问题的分析在事故响应中起着核心作用,但目前尚不清楚现代基础模型是否能够可靠地回答工程师在实践中提出的时间序列问题,”论文中写道。
问题分为三个层级。层级一:此图表中是否存在异常?层级二:它何时开始,严重程度如何,是什么类型?
层级三——最难的——需要跨指标推理:这个图表是否引发了另一个图表中的问题?这就是人工智能的短板。GPT-5 在层级三问题上的 F1 分数仅为 47.5%,该指标会惩罚通过选择最常见类别来操控答案的模型。
“尽管这种基于问题的分析在事故响应中起着核心作用,但目前尚不清楚现代基础模型是否能够可靠地回答工程师在实践中提出的时间序列问题,”研究人员写道。
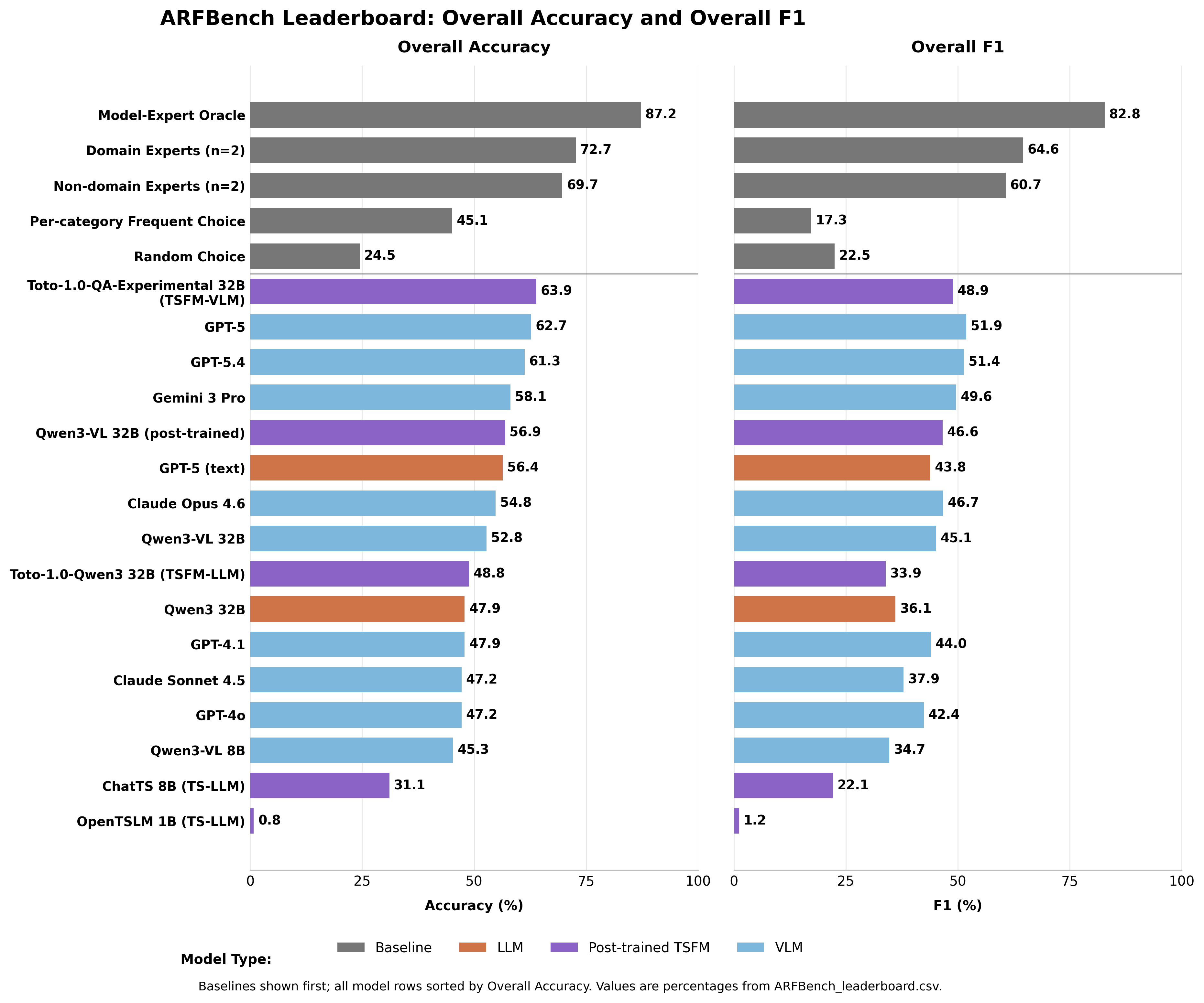
每个模型的表现对比
GPT-5 在所有现有模型中表现最佳,准确率为 62.7%——而随机猜测的得分为 24.5%。Gemini 3 Pro 得分 58.1%。Claude Opus 4.6: 54.8%。Claude Sonnet 4.5: 47.2%。
领域专家得分 72.7% 准确率。非领域专家——Datadog 的时间序列研究人员,缺乏广泛的可观测性经验——仍然达到了 69.7%。
没有任何人工智能模型超过这两个人工基线。
图像由 Decrypt 基于 ARFBench 排行榜 CSV 构建
实际上在完整排行榜中排名第一的模型是 Datadog 自己的混合模型:Toto——他们内部的时间序列预测模型——与 Qwen3-VL 32B 组合。Toto-1.0-QA-Experimental 的准确率为 63.9%,超越了 GPT-5,同时使用的参数远少于其一部分。在异常识别方面,它在 F1 上超越了所有其他模型至少 8.8 个百分点。
一个专门构建的领域模型,在可观测性数据上进行训练,在这个特定任务上超越一个前沿通用系统是预期的结果。这正是关键所在。
最有价值的发现并不是哪个模型得分最高。
“我们观察到领先模型与人类专家之间存在显著不同的错误特征,表明它们的优势是互补的,”研究人员写道。模型会产生幻觉、遗漏元数据,并失去领域上下文。人类会误读精确的时间戳,偶尔在复杂指令上出现失误。这些错误几乎不会重叠。
构建一个理论上的“模型-专家神谕”——一个完美的裁判,始终在人工智能和人类之间选择正确答案——得到 87.2% 的准确率和 82.8% 的 F1。远高于任何一个单独的模型。
这不是一个产品。这是一个 经过文档记录的目标——基于真实紧急情况,而不是策划的数据集——量化了人类与人工智能合作的表现可以有多好。排行榜在 Hugging Face 上实时更新。GPT-5 的得分为 62.7%。最高限度为 87.2%。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





