4-17%. This is the prompt cache read rate of Claude Code over the past month. The normal level is 97-99%.
This means that when you restore a previous session, Claude Code does not reuse the previously processed context but instead processes everything from scratch each time, consuming 10 to 20 times the typical quota. You think you are continuing a conversation, but in reality, you are starting a completely new, full-priced conversation each time.
This figure comes from independent developer ArkNill's proxy monitoring tests. By setting up a transparent proxy, he recorded every request between Claude Code and the Anthropic API and discovered at least two client cache bugs that caused the API server to be unable to match cached conversation prefixes, forcing a complete token reconstruction each round.
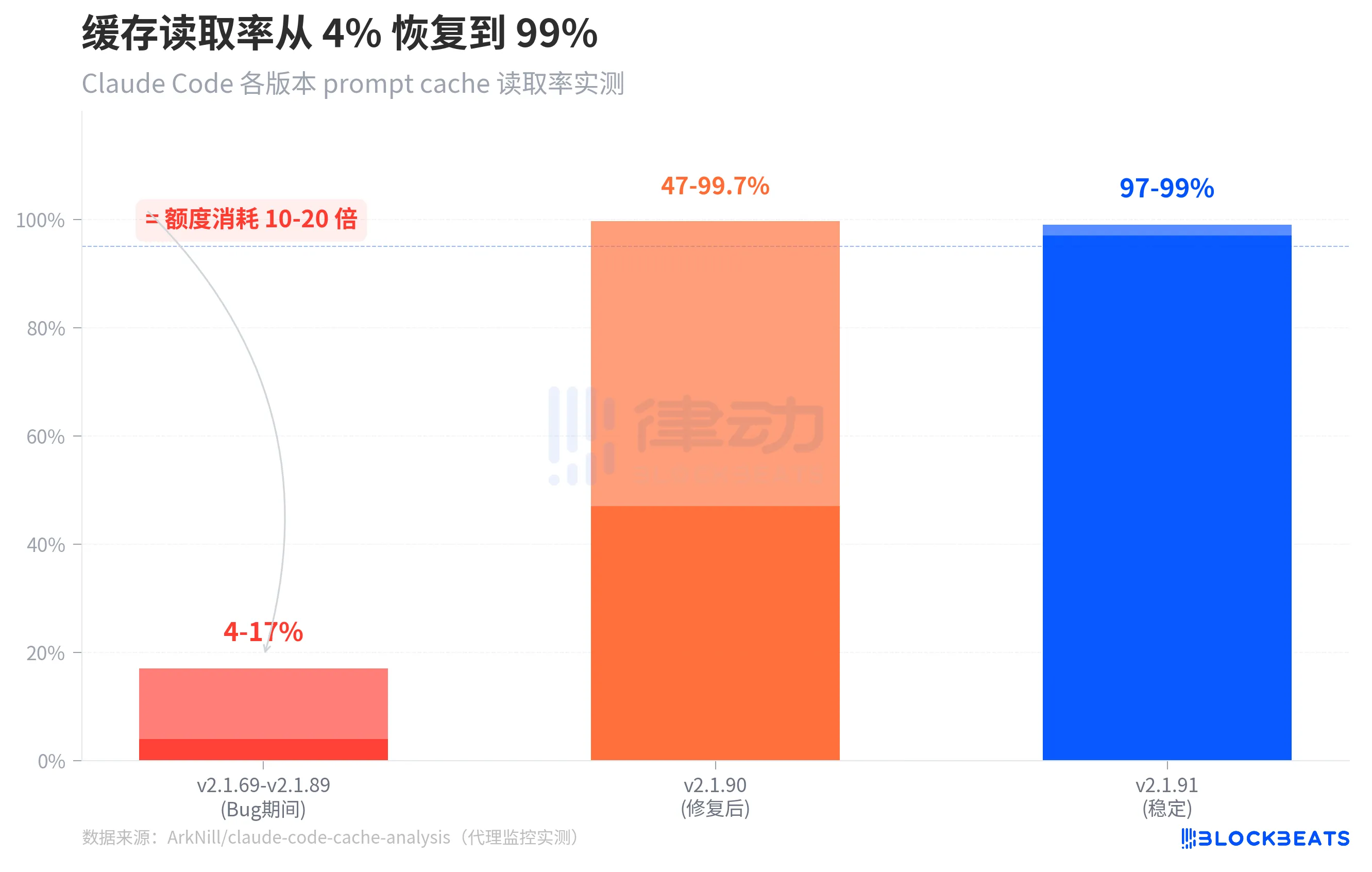
The above image shows a comparison of cache read rates over three stages. During the period from v2.1.69 to v2.1.89 (i.e., the bug existence period), the cache read rate of the standalone version was only 4-17%. After v2.1.90, which fixed one of the critical bugs, the cold start cache read rate returned to 47-99.7%. By v2.1.91, the cache read rate under stable operation was restored to 97-99%.
It is worth noting a detail in the chart: the range of v2.1.90 is very large (47% to 99.7%), because when a session is just restored, the cache still needs to be "warmed up," resulting in lower hit rates in the initial rounds, but quickly returning to normal levels. In the bug version, this warming up never happens—the cache read always remains at the 14,500 tokens of system prompts, with all conversation history being charged at full price every time.
28 Days, 20 Versions
This bug was not introduced by one update and fixed by another. According to the release records from the npm registry, the version v2.1.69 that introduced the bug was released on March 4, and the version v2.1.90 that fixed the bug was released on April 1. There was a gap of 28 days, spanning 20 versions.
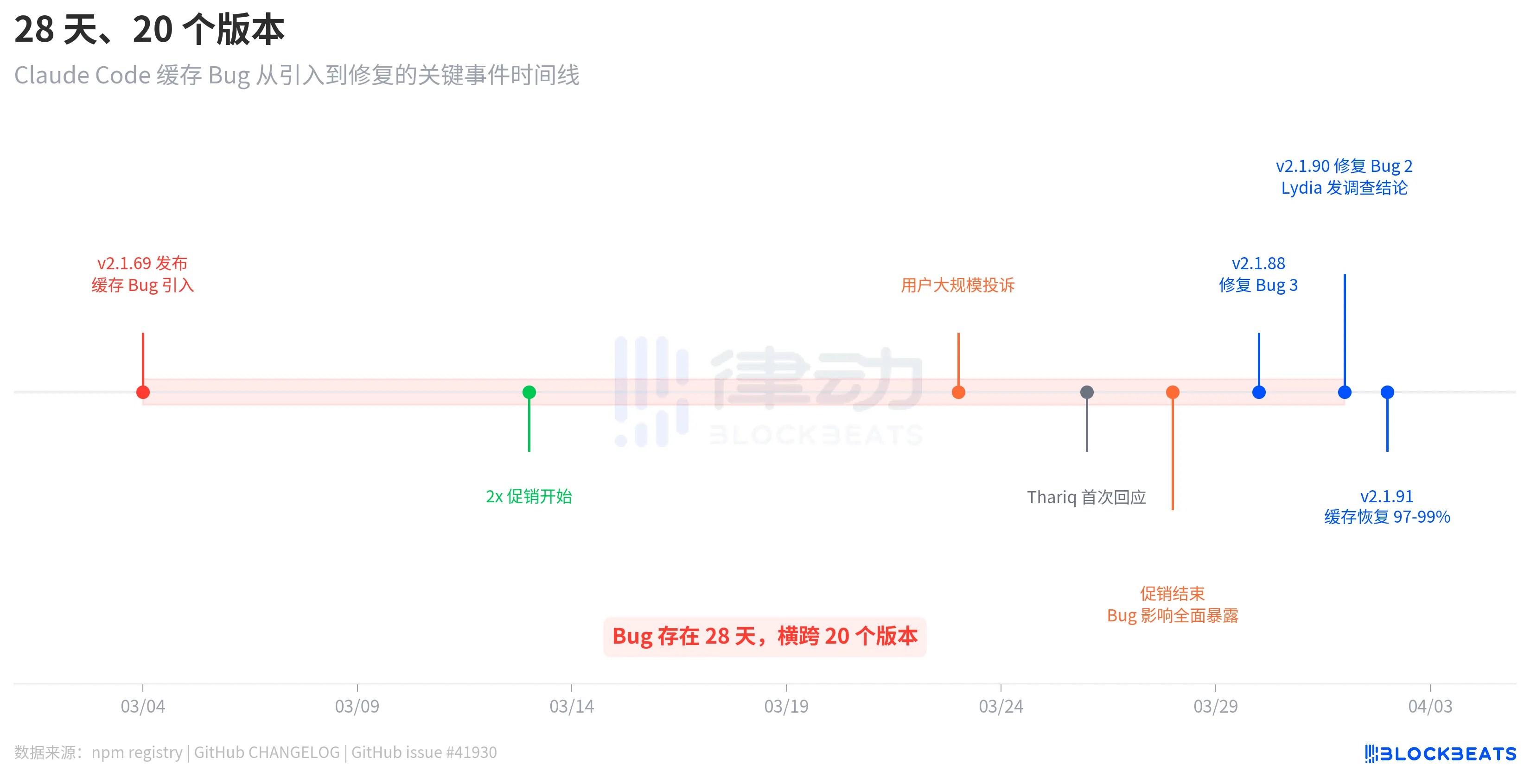
The timeline reveals an intriguing detail. After the bug was introduced on March 4, users did not immediately complain on a large scale. It was only on March 23 that complaints concentrated and erupted, nearly three weeks later. The reason is that, according to the analysis of GitHub issue #41930, from March 13 to 28, Anthropic had launched a double quota promotion (doubling in off-peak hours), which objectively masked the impact of the bug. After the promotion ended, the consumption caused by the cache bug returned to the normal billing baseline, and users' quotas "evaporated" instantly.
Anthropic's response was not quick. On March 26, three days after the explosion of user complaints, engineer Thariq Shihipar announced on his personal X account that the limits during peak hours (weekdays from 5 am to 11 am PT) had been tightened. On March 30, Anthropic acknowledged on Reddit that "the speed at which users are reaching their limits far exceeds expectations," stating it had become the highest priority for the team. It was not until April 1 that team member Lydia Hallie released the formal investigation conclusions.
Throughout the process, Anthropic did not release any blog posts, did not send email notifications, and did not update the status page. All official communication was completed solely through personal social media posts by engineers and a few Reddit comments.
How Much Did You Pay, and How Long Can You Use It?
GitHub issue #41930 collected hundreds of user reports. The most extreme case is a Max 20x subscription user ($200/month), whose 5-hour rolling window was completely exhausted in just 19 minutes. A Max 5x user ($100/month) reported that their 5-hour window was used up in 90 minutes. According to The Letter Two, other users claimed that a simple "hello" consumed 13% of their session quota. One Pro user ($20/month) said on Discord that their quota "runs out every Monday and resets on Saturday," allowing them to use it normally for only 12 days in 30 days.
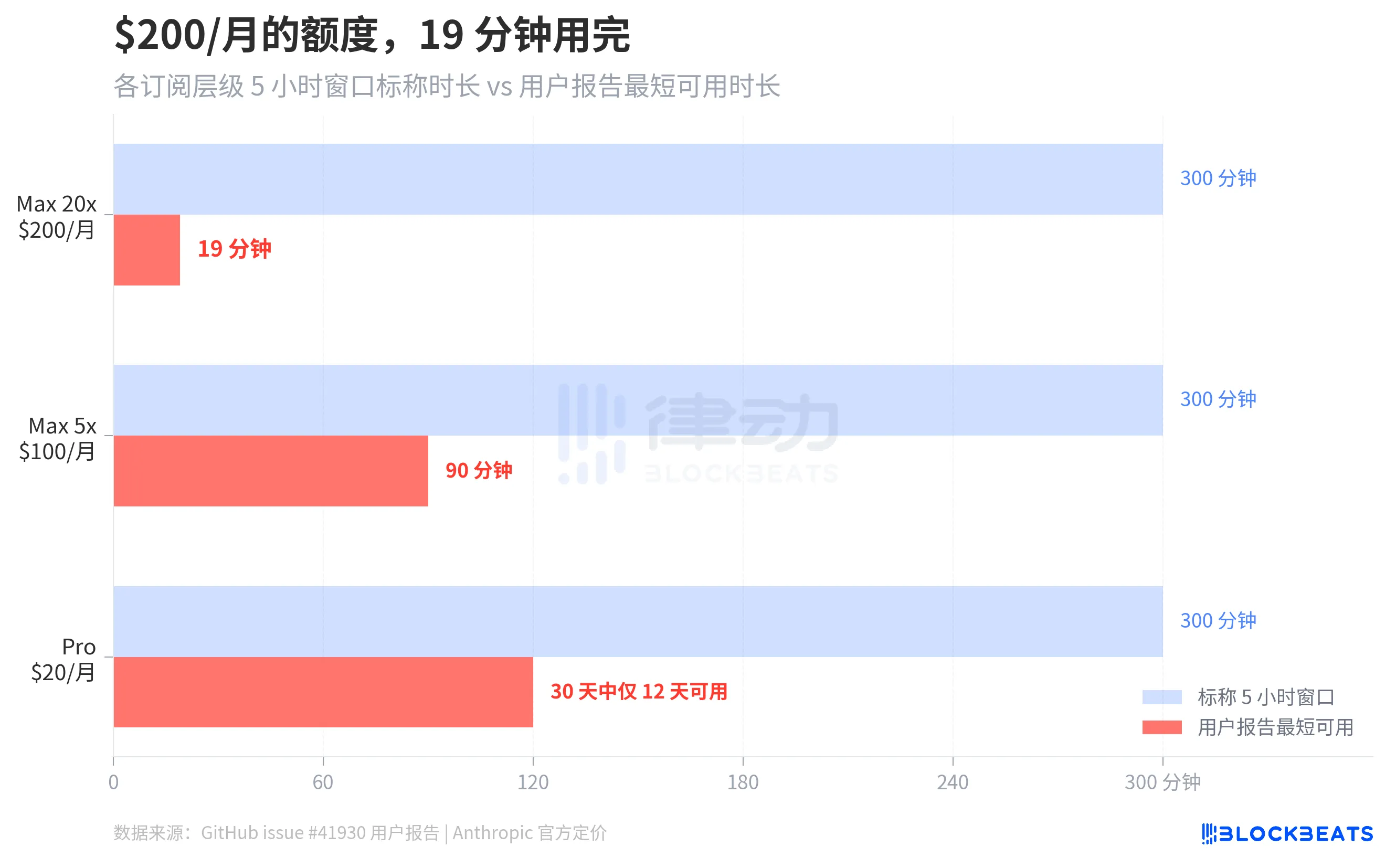
According to ArkNill's benchmark tests, on the bug version v2.1.89, the 100% quota of the Max 20x plan would be exhausted in about 70 minutes. He also calculated the per-session cost of a --resume operation for a 500K token context session, which is approximately $0.15, because the system fully replays the entire context.
"You're Holding It Wrong"
Lydia Hallie's investigation conclusion confirmed two points: first, the peak hour limits have indeed been tightened, and second, the consumption of sessions with 1 million tokens of context has increased. She stated that the team fixed several bugs but emphasized "no single bug caused overcharging."
She then provided four cost-saving suggestions:
1. Use Sonnet 4.6 instead of Opus (Opus consumes at about twice the rate);
2. Reduce reasoning intensity or turn off extended thinking when deep reasoning is not needed;
3. Do not restore long sessions that have been idle for more than an hour; start a new one instead;
4. Set the environment variable CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000 to limit the context window size.
No mention was made of any form of limit reset or compensation.
AI podcast host Alex Volkov summarized this response as "You're holding it wrong," pointing out that Anthropic itself set 1 million tokens of context as the default, promoted Opus as the flagship model, and highlighted extended thinking as a selling point, yet now advises paying users not to use these features.
The statement "there is no overcharging" also conflicts with Claude Code's own update records. Just the day before Lydia released her response, v2.1.90 fixed a caching regression bug that had existed since v2.1.69: when using --resume to restore a session, requests that should hit the cache would trigger a full prompt cache miss and be charged at full price. Lydia's response did not mention this confirmed billing anomaly.

In contrast, OpenAI's Codex previously also experienced similar quota anomaly consumption issues. OpenAI's approach was to reset user quotas, reissue credits, and announced in March the removal of the usage limit for Codex. Anthropic's approach was to advise users to downgrade models, turn off features, limit context, and attribute the responsibility to the users' usage methods.
Anthropic sells subscriptions for "the strongest model + the largest context + the highest reasoning capability," charging fees from $20 to $200 per month. A 28-day cache bug caused paying users' quotas to evaporate at 10-20 times the normal rate, while the official response was to tell you to use it sparingly.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






