原文作者: @BlazingKevin_ ,Blockbooster研究员
1. Agent Skill 的诞生背景与演进
2025 年的 AI Agent 赛道正处于从“技术概念”向“工程落地”跨越的关键分水岭。在这个进程中,Anthropic 关于能力封装的探索,意外地促成了一次行业级的范式转移。
2025 年 10 月 16 日,Anthropic 正式推出了 Agent Skill。起初,官方对这一特性的定位表现得极为克制——它仅仅被视作提升 Claude 在特定垂直任务(如复杂代码逻辑、特定数据分析)表现的辅助模块。
然而,市场和开发者的反馈远超预期。大家很快发现,这套将“能力模块化”的设计在实际工程中展现出了极高的解耦性和灵活性。它不仅降低了 Prompt 调优的冗余度,还极大地提升了 Agent 执行特定任务的稳定性。这种体验,迅速在开发者社区引发了连锁反应。短时间内,包括 VS Code、Codex、Cursor 在内的头部生产力工具与集成开发环境(IDE)纷纷跟进,陆续完成了对 Agent Skill 架构的底层支持。
面对生态的自发扩张,Anthropic 捕捉到了这一机制的底层通用价值。2025 年 12 月 18 日,Anthropic 做出了一个具有行业里程碑意义的决定:正式将 Agent Skill 发布为开放标准。
紧接着,在 2026 年 1 月 29 日,官方正式发布了 Skill 的详尽使用手册,从协议层面彻底打通了跨平台、跨产品复用的技术壁垒。 这一系列动作标志着 Agent Skill 已经彻底褪去了“Claude 专属附属品”的标签,正式演变为整个 AI Agent 领域中一种通用的底层设计模式。
至此,一个悬念呼之欲出:这个让大厂与核心开发者纷纷拥抱的 Agent Skill,究竟在底层工程上解决了什么核心痛点?它与当前大热的 MCP 之间,又有着怎样的本质区别与协同关系?
为了彻底厘清这些问题,并最终将其落脚于加密行业投研的实际构建中,本文将层层递进地展开以下探讨:
- 概念解析:Agent Skill 的本质及其基础架构构建。
- 基础工作流:揭示其底层运转逻辑与执行流。
- 进阶机制:深入剖析 Reference与 Script两大高级用法。
- 实战案例:解析 Agent Skill 与 MCP 的本质差异,并演示在 Crypto 投研场景下的组合应用。
2. 什么是 Agent Skill 及其基础构建
到底什么是 Agent Skill?用最通俗的话来讲,它其实就是一份大模型可以随时翻阅的“专属说明文档”。
在日常使用 AI 时,我们经常会遇到一个痛点:每次开启新对话,都要把长长的要求重新粘贴一遍。而 Agent Skill 就是为了解决这个麻烦而生的。

举个实际的例子:假设你想做一个“智能客服” Agent,你可以在 Skill 里明确写下规矩:“遇到用户投诉,第一步必须先安抚情绪,并且绝对不能随意做出赔偿承诺。” 再比如,你经常需要做“会议总结”,你可以直接在 Skill 里定好模版:“每次输出会议总结时,必须严格按照‘参会人员’、‘核心议题’、‘最终决定’这三个板块来排版。”
有了这份“说明文档”,你就不需要每次对话都去重复那一长串的指令了。大模型在接到任务时,会自动去翻阅对应的 Skill,立刻就知道该用什么标准来干活。
当然,“说明文档”只是一个为了方便大家理解的简化比喻。实际上,Agent Skill 能做的事情远比单纯的格式规范要强大得多,它的那些“杀手级”高级功能我们会在后面的章节详细拆解。但在起步阶段,你完全可以把它当成一份高效的任务说明书。
接下来,我们就用“会议总结”这个大家最熟悉的场景,来看看究竟该怎么动手创建一个 Agent Skill。整个过程并不需要复杂的编程知识。
根据目前主流工具(如 Claude Code)的设定,我们需要在电脑的用户目录下找到(或新建)一个叫 .claude/skill 的文件夹,这里就是存放所有 Skill 的“大本营”。
第一步,在这个目录里创建一个新文件夹。这个文件夹的名字,就是你这个 Agent Skill 的名字。 第二步,在刚刚建好的文件夹里,创建一个名为 skill.md 的文本文件。
每一个 Agent Skill 都必须有这么一个 skill.md 文件。它的作用就是告诉 AI:我是谁,我能干什么,以及你该怎么按我的要求工作。打开这个文件,你会发现它清晰地分成了上下两部分:

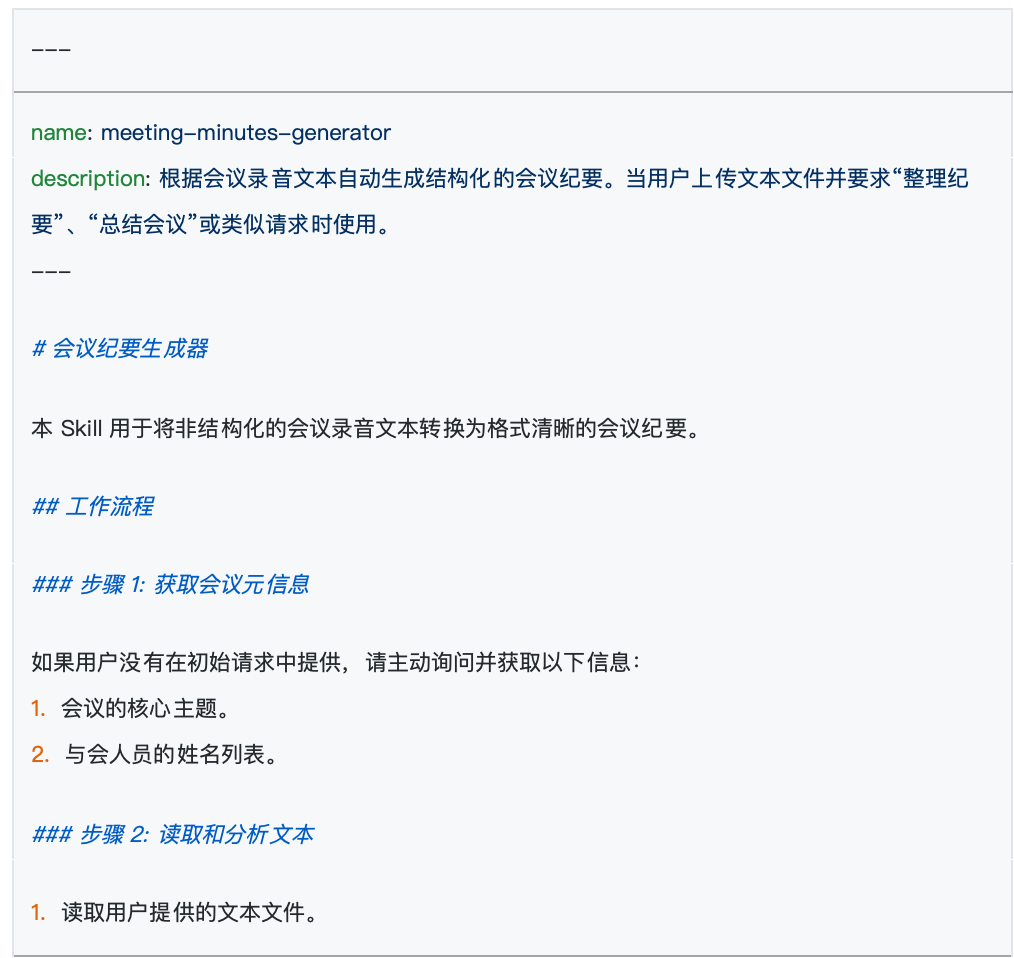
在文件的最开头,通常是被两段短横线 --- 包起来的区域。这里面只写两个核心属性:name 和 description。
name:就是这个 Skill 的名字,必须和外面的文件夹名字一模一样。description:这是极其重要的一环。它负责向大模型解释这个 Skill 的具体用途。AI 在后台会持续扫描所有 Skill 的描述,以此来判断当前用户的提问到底该用哪一个 Skill 来解答。 因此,写一段精准、全面的描述,是确保你的 Skill 能被 AI 准确唤醒的大前提。
短横线下方剩下的部分,就是写给 AI 看的具体规则了。官方把这部分叫做“指令”。 这就是你发挥的地方,你要在这里详细描述模型需要遵循的逻辑。比如在会议总结的例子里,你就可以在这里用大白话规定:“必须提炼出参会人员名单、讨论的议题以及最终落实的决定”。

把这几步做完,一个简单但非常实用的 Agent Skill 就诞生了。
不过,一个真正好用的 Skill,往往始于周密的前期设计。在键盘上敲下第一行字之前,先清晰地定义目标、范围和成功标准,会让你的构建过程事半功倍。
构建 Skill 的第一步,其实不是去想“我能让 AI 搞出什么花样”,而是要反问自己:“我到底需要解决日常工作中的什么重复性问题?” 建议一开始先具体定义出 2 到 3 个这个 Skill 应该覆盖的明确场景。

其次,是定义成功的标准。你怎么知道自己写出的 Skill 好不好用?在动手前,给它设定几个能衡量的标准。比如定量的标准可以是“处理速度是否变快了”,定性的标准可以是“它提取的会议决定是不是每次都足够精准没有遗漏”。
3. Agent Skill 的基础运行工作流
在了解了 Agent Skill 的基本面貌后,我们不禁要问:在实际运行中,这套“说明文档”究竟是如何发挥作用的?
如果你最近体验过像 Manus AI 这样的产品,你大概率经历过这样的场景:当你抛出一个特定问题时,AI 并没有立刻开始“长篇大论”或产生幻觉,而是敏锐地意识到“这件事归某个特定的 Agent Skill 管”。于是,它会在界面上弹出一个提示,询问你是否允许调用该 Skill。
当你点击“同意”后,AI 便像换了一个人一样,严格按照预设的规矩完美输出结果。
这个看似简单的“申请-同意-执行”的交互背后,其实隐藏着一套极为精巧的底层运行工作流。为了彻底讲清楚这套机制,我们需要先明确整个流程中参与交互的“三个核心角色”:
- 用户:发起任务请求的人。
- 客户端工具(如 Claude Code 等):负责调度和统筹的“中间人”。
- 大语言模型:负责理解意图和生成最终结果的“大脑”。
当我们向系统输入一段需求(例如:“帮我总结一下今天早上的项目例会”)时,这三个角色之间会发生如下的四步精密协作:
第一步:轻量级扫描(传递元数据)
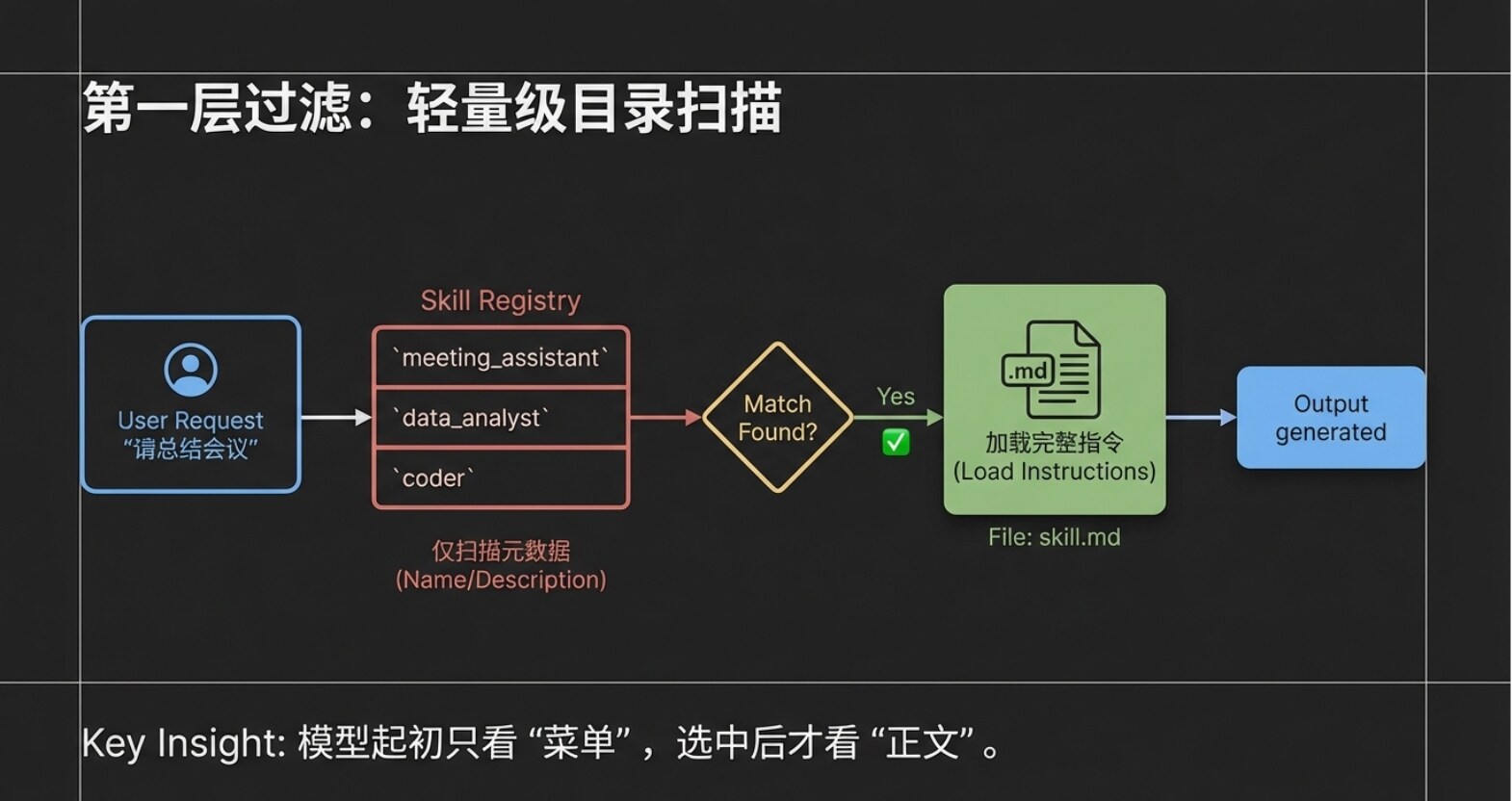
用户输入请求后,客户端工具(Claude Code)不会一股脑地把所有说明文档都扔给大模型。相反,它只会把用户的请求,连同当前系统中所有 Agent Skill 的“名称”和“描述”(也就是我们上一章提到的 Metadata 元数据层),打包发送给大模型。 你可以想象一下,哪怕你安装了十几个甚至几十个 Skill,此时大模型拿到的也仅仅是一份“轻量级的目录”。这种设计极大地节省了模型的注意力,避免了信息的相互干扰。
第二步:精准的意图匹配 大模型在收到用户请求和这份“Skill 目录”后,会进行快速的语义分析。它发现用户的诉求是“总结会议”,而目录中恰好有一个名叫“会议总结助手”的 Skill,其描述完美契合该任务。 此时,大模型会把这个匹配结果告诉客户端工具:“我发现这个任务可以用‘会议总结助手’来解决。”
第三步:按需加载完整指令 得到大模型的反馈后,客户端工具(Claude Code)才会真正进入“会议总结助手”的专属文件夹,去读取那个完整的 skill.md 正文。 请注意,这是一个极其关键的设计:只有在此时,完整的指令内容才会被读取,而且系统只读取这一个被选中的 Skill。 其他未被命中的 Skill 依然安静地躺在目录里,不会占用任何资源。
第四步:严格执行与输出响应 最后,客户端工具会将“用户的原始请求”和“会议总结助手完整的 skill.md 内容”一起发送给大模型。 这一次,大模型不再是做选择题,而是进入了执行模式。它会严格遵循 skill.md 里定下的规矩(比如:必须提取参会人员、核心议题、最终决定),生成高度结构化的响应,并交由客户端工具展示给用户。
4. 核心机制一:按需加载与 Reference
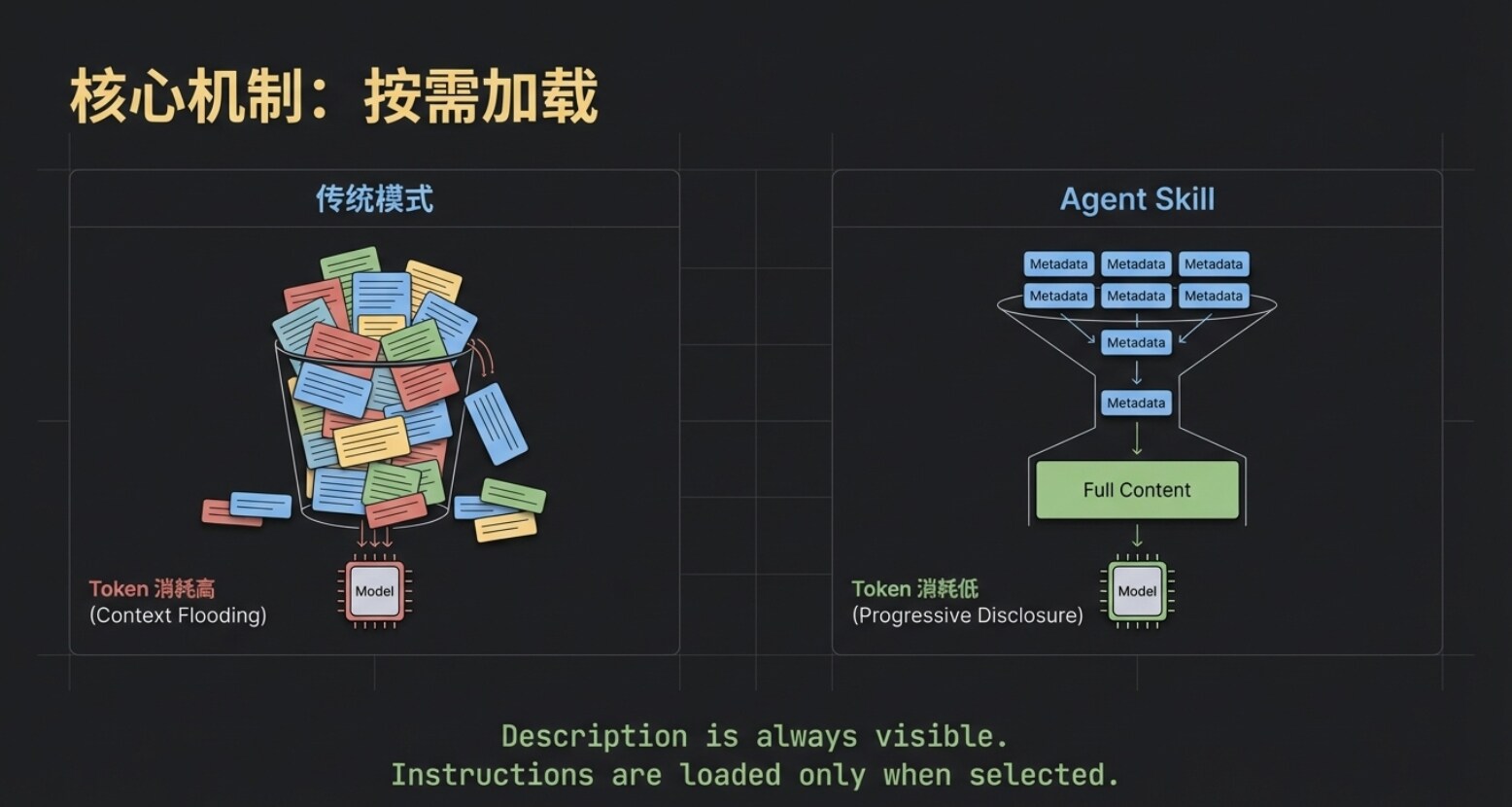
上一章的工作流,引出了 Agent Skill 的第一个核心底层机制——按需加载。
虽然所有 Skill 的名称和描述始终对大模型可见,但具体的指令内容,只有在该 Skill 被精准命中后,才会被真正拉取到模型的上下文中。
这就极大地节省了宝贵的 Token 资源。试想一下,哪怕你同时部署了“爆款文案”、“会议总结”、“链上数据分析”等十几个大体量的 Skill,模型最初也只需做一次极低消耗的“目录检索”。只有在选中目标后,系统才会把那份对应的 skill.md 喂给模型。这种“按需加载”,就是 Agent Skill 保持轻量和高效的第一层密码。
然而,对于追求极致效率的进阶用户来说,仅仅做到第一层按需加载还不够。
随着业务的深入,我们往往希望 Skill 变得更加聪明。以“会议总结助手”为例,我们希望它不仅能简单复述议题,还能提供增量的洞察价值:当会议决定要花钱时,它能直接在总结里标注是否符合集团的财务合规;当涉及到外部合作时,它能自动提示潜在的法务风险。这样一来,团队在看总结时,一眼就能扫到关键的合规预警,免去了二次查阅规章制度的繁琐。
但这在工程上带来了一个致命矛盾:Skill 要想具备这种能力,前提是必须把冗长的《财务规定》和《法律条文》全都塞进 skill.md 文件里。这会导致核心指令文件变得无比臃肿。哪怕今天开的只是一场纯技术的早会,模型也被迫要加载数万字的财务和法律“废话”,这不仅造成了 Token 的严重浪费,还极易引发模型的“注意力涣散”。
那么,能不能在按需加载的基础上,再实现一层“按需中的按需”呢?比如,只有当会议内容真真切切聊到了“钱”,系统才把财务规定掏出来给模型看?
答案是肯定的。Agent Skill 体系中的 Reference 机制,正是为此而生。

Reference 的本质,是条件触发的外部知识库。我们来看看它是如何优雅地解决上述痛点的:
- 建立外部参考文件:首先,我们在该 Skill 的目录下新增一个独立文件,也就是术语中的 Reference。我们将它命名为
集团财务手册.md,里面详细列明了各项报销标准(例如:住宿补贴 500 元/晚,餐饮费人均 300 元/天等)。 - 设定触发条件:接着,回到核心的
skill.md文件中,新增一条专门的“财务提醒规则”。我们可以用自然语言明确约定:“仅在会议内容提及钱、预算、采购、费用等字眼时触发。触发后,需读取集团财务手册.md文件。请根据该文件内容,指出会议决定中的金额是否超标,并明确相应的审批人。”
完成设定后,当我们在下一次会议中复盘预算分配时,一场精妙的动态协作就开始了:
- 客户端工具扫描并向你申请使用“会议总结助手” Skill(完成第一层按需加载)。
- 模型在阅读会议记录时,敏锐地捕捉到了“预算”相关的字眼,立刻触碰了我们在
skill.md中埋下的规则。 - 此时,系统会向你发起第二次请求:“是否允许读取
集团财务手册.md?”(完成第二层按需加载:Reference 动态触发)。 - 授权通过后,模型将会议内容与动态引入的财务标准进行交叉比对,最终输出一份不仅包含“参会人员、议题、决定”,更挂载了“财务合规预警”的高质量总结。
请务必记住 Reference 的核心特征:它是严格受条件约束的。反过来说,如果今天你们开的是一场探讨代码逻辑的技术复盘会,全场与钱毫无关系,那么这份 集团财务手册.md 就会安静地躺在硬盘里,绝不会占用哪怕一个 Token 的算力资源。
5. Script与渐进式披露机制
讲完了解决信息过载的 Reference 机制,接下来我们进入 Agent Skill 的另一个杀手级能力:代码执行(Script)。
对于一个成熟的 Agent 来说,仅仅会“查资料”和“写总结”是不够的,能直接上手把活儿干了,才是真正的自动化闭环。这就是 Script 的用武之地。
继续拿我们的“会议总结助手”举例。总结写完后,通常还需要把它同步到公司的内部系统。为了实现这最后一步,我们在 Skill 的文件夹里新建一个 Python 脚本,命名为 upload.py,里面写好了对接公司服务器的上传逻辑。
接着,我们回到核心的 skill.md 文件中,追加一条明确的指令:“当用户提到‘上传’、‘同步’或‘发送到服务器’等字眼时,你必须运行 upload.py 脚本,将生成的总结内容推送到服务器。”
当你对 AI 说:“总结写得不错,帮我同步到服务器吧。”
客户端工具会立刻向你申请执行这个 upload.py 文件。但请注意一个极其关键的底层逻辑:在这个过程中,AI 并没有去“读取”这串代码的内容,它仅仅是去“执行”了它。
这意味着,哪怕你的 Python 脚本里写了一万行极其复杂的业务逻辑,它对大模型上下文的消耗也几乎是零。AI 就像在使用一个“黑盒”工具,它只关心怎么启动这个工具,以及最后有没有成功,至于盒子里是怎么运作的,它毫不在意。
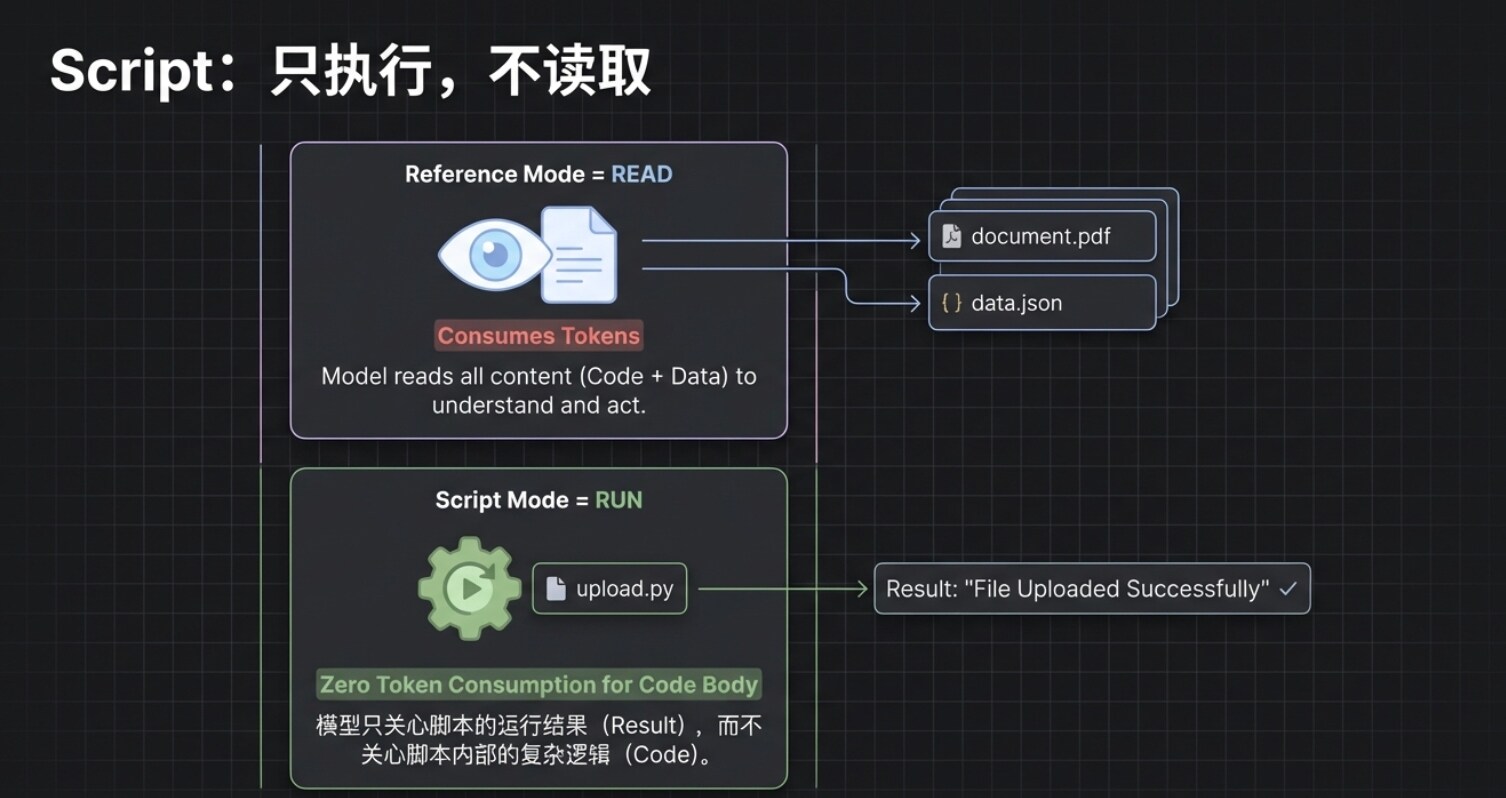
这就引出了 Reference 和 Script 这两大高级功能在机制上的本质区别:
- Reference(读): 它是把外部文件的内容“搬”到模型的脑子里(上下文)作为参考,因此会消耗 Token。
- Script(跑): 它是在外部环境中直接被触发运行,只要你把运行方法交代清楚,它就不会占用模型的上下文。
当然,这里有一个避坑指南:在写 skill.md 时,你必须把脚本的触发条件和执行命令解释得绝对清楚。如果 AI 遇到模糊的指令不知道该怎么跑,它可能就会“退而求其次”,试图去偷看代码内容来寻找线索,这时候你的 Token 可就要遭殃了。所以,写 Skill 的铁律是:尽可能把规则定义得清晰无死角。
讲到这里,我们其实已经把 Agent Skill 的所有核心组件拼图都找齐了。是时候停下来,站在全局视角做个总结了。
如果你仔细回味整个加载过程,你会发现 Agent Skill 的设计哲学,其实是一种极其精密的渐进式披露机制。为了极致地节省算力并保持高效,它的系统被严格划分为了三层,每一层的触发条件都步步收紧:
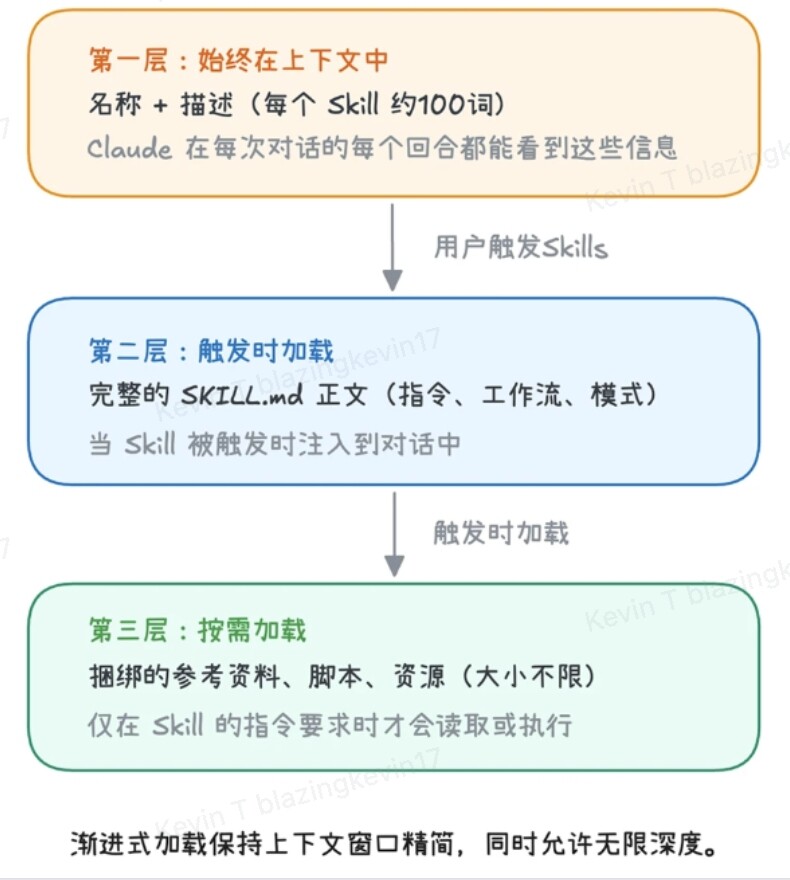
- 第一层:元数据层(始终加载) 这里存放着所有 Agent Skill 的
name和description。它就像是大模型的“常驻目录”,极度轻量。大模型每次接单前都会先扫一眼这里,完成初步的路由匹配。 - 第二层:指令层(按需加载) 对应
skill.md里的具体规则。只有当第一层确认了任务归属,AI 才会“翻开”对应的这一层,把具体的规矩加载进脑子里。 - 第三层:资源层(按需中的按需加载) 这是最深、也是最庞大的一层。它包含了三个核心组件:
- Reference: 比如
集团财务手册.md,只有当对话触发了特定条件(如提到“钱”),才会被读取。 - Script: 比如
upload.py,只有当需要执行特定动作(如“上传”),才会被运行。 - Asset: 比如生成研报时需要用到的公司 Logo 图标、专属字体、特定的 PDF 模板等。它们也只在最终生成产物的那一刻才被调用。
6.Agent Skill 与 MCP 的本质区别及组合实战
聊完了 Agent Skill 的高级用法,很多对 AI 底层协议有所了解的读者可能会产生一种强烈的既视感:Agent Skill 的 Script 机制,怎么看都和最近大热的 MCP非常相似。本质上,它们不都是让大模型去连接和操作外部世界吗?
既然功能存在重叠,在构建 Crypto Research 工作流时,我们到底该选哪一个?
针对这个问题,Anthropic 官方曾用一句非常经典的话点明了两者最核心的本质区别:
"MCP connects Claude to data. Skills teach Claude what to do with that data."(MCP 负责将 Claude 连接到数据;而 Skill 负责教 Claude 如何处理这些数据。)
这句话可谓一语中的。MCP 本质上是一条“数据管道”,它负责标准化地向大模型供给外部信息(比如查询某条链上的最新区块高度、拉取交易所的实时 K 线、读取本地的投研 PDF)。而 Agent Skill 本质上是一套“行为准则(SOP)”,它负责规范大模型拿到这些数据后该怎么干活(比如规定投研报告必须包含代币经济学模型、规定输出的结论必须带有风险提示)。
这时可能会有极客提出反驳:“既然 Agent Skill 也能跑 Python 代码,我直接在 Script 里写一段连接数据库或调用 API 的逻辑不就行了吗?Agent Skill 完全可以把 MCP 的活儿一起干了!”
确实,在工程实现上,Agent Skill 也能去拉取数据。但是极其别扭且不专业。
这种“不专业”体现在两个致命维度上:
- 运行机制与状态保持:Agent Skill 的脚本是“无状态”的,每次触发都是一次独立的执行,跑完即焚。而 MCP 是一个独立运行的长期服务,它可以保持与外部数据源的持久化连接(比如下文会提到的 WebSocket 长链接),这是单纯的脚本根本做不到的。
- 安全性与稳定性:让 AI 每次都去裸跑一个拥有最高系统权限的 Python 脚本,存在极大的安全隐患;而 MCP 提供了标准化的隔离环境和鉴权机制。
因此,在构建高阶的 Crypto Research 体系时,最强大的解法绝不是二选一,而是“MCP 供水,Skill 酿酒”——将两者强强联合。
为了让大家直观感受到这种组合的威力,我们以 Web3 开发者 Cryptoxiao 构建的 opennews-mcp 为例,拆解如何利用 API 增强型 Skill 打造一个全自动的加密新闻情报中心。
这类 Skill 的核心逻辑是:将 MCP 提供的离散 API 能力,通过 Skill 的指令编排,封装成一个面向最终投研目标的智能 Agent。
该体系赋予了 AI 四大核心模块能力:
模块一:新闻源发现
这是 AI 理解该工具能力边界的入口。通过 discovery.py 中的工具,AI 可以动态地了解到它能从哪些渠道获取信息。

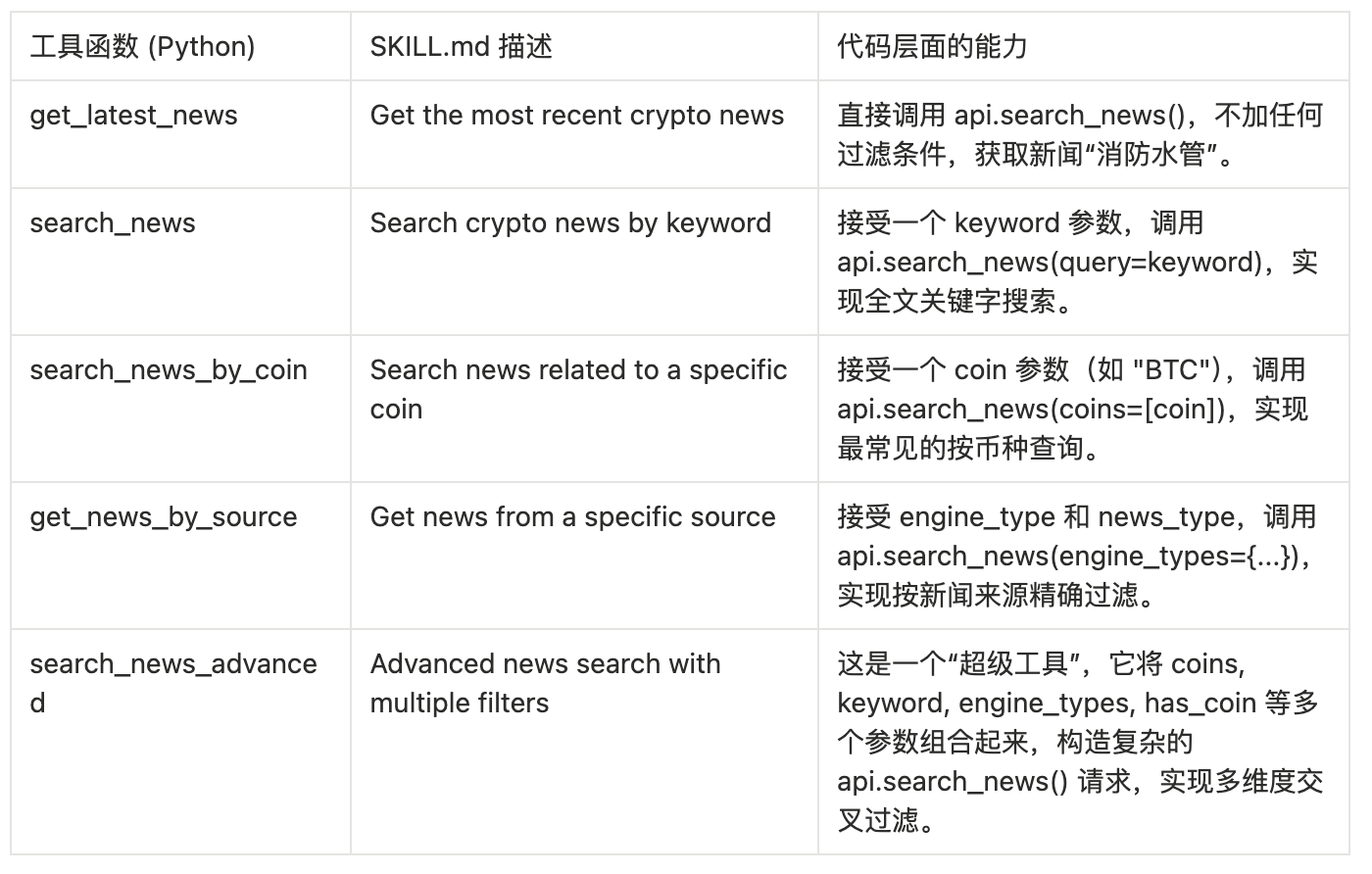
模块二:多维度新闻检索
这是最核心的查询模块,由 news.py 实现,提供了从简单到复杂的多种新闻检索方式。
模块三:AI 赋能的分析与洞察
这部分工具利用了 6551.io 后端已经完成的 AI 分析结果,让 AI Agent 可以直接查询“观点”而非仅仅是“事实”。

关键洞察:AI Agent 调用这些工具时,它并不知道 MCP 服务器在内部执行了“获取-再过滤”的两步操作。对 AI 来说,它只是调用了一个能直接返回“高分新闻”或“利好新闻”的神奇工具,极大地简化了 AI 的工作流。
模块四:实时新闻流
这是 opennews-mcp 的“杀手级”能力,由 realtime.py 实现,赋予了 AI 监听实时事件的能力。

当这些基于 MCP 驱动的工具被写进 Agent Skill 的指令流后,你的 AI 就正式从一个“通用陪聊助理”蜕变成了一个“华尔街级别的 Web3 分析师”。它可以全自动执行以往需要研究员耗费数小时的复杂工作流:
工作流示例一:新币种快速尽职调查 (DD)
- 指令下达:用户输入“深度调研一下刚刚上线的 @NewCryptoCoin 项目。”
- 基础摸底:Agent 自动调用
opentwitter.get_twitter_user获取官方推特数据。 - 背书交叉验证:调用
opentwitter.get_twitter_kol_followers,穿透分析有哪些头部 KOL 或 VC 已经悄悄关注了该项目。 - 全网舆情搜索:调用
opennews.search_news_by_coin检索媒体报道与公关动作。 - 信噪比过滤:调用
opennews.get_high_score_news将无价值的快讯剔除,仅精读高分长文。 - 输出研报:Agent 根据 Skill 中预设的研报格式,输出一份包含“基本面、社区筹码结构、媒体热度及 AI 综合评级”的标准尽调报告。
工作流示例二:实时事件驱动的交易信号发现
- 指令下达:用户输入“帮我全天候盯盘,寻找‘零知识证明(ZK)’赛道的突发交易机会。”
- 部署哨兵:Agent 调用
opennews.subscribe_latest_news建立 WebSocket 长连接,精准监听内容包含 “ZK” 或 “Zero-Knowledge Proof” 且关联具体代币的新闻流。 - 捕捉利好:当系统捕获到某项目(如 SomeCoin)在 ZK 技术取得突破的高权重利好新闻,且情绪指标判定为 Long 时,立刻阻断休眠。
- 社区情绪共振测试:Agent 毫秒级调用 Twitter 搜索工具,查阅多位 ZK 领域核心 KOL 是否在同步发酵该事件。
- 警报触发:若满足“媒体首发+社区共振”的条件,Agent 立即向用户推送高确定性的 Alpha 交易警报。
至此,通过 Agent Skill 规范行为逻辑,结合 MCP 贯通数据大动脉,一套高度自动化、专业化的 Crypto Research 工作流便彻底闭环了。
关于BlockBooster
BlockBooster 是一家面向数字时代的新一代另类资产管理公司。我们运用区块链技术,投资、孵化并管理数字时代的核心资产——从 Web3 原生项目到真实世界资产 (RWA)。作为价值共创者,我们致力于发掘并释放资产的长期潜力,为我们的合作伙伴与投资人在数字经济的浪潮中捕获卓越价值。
免责声明
本文/博客仅供参考,代表作者的个人观点,并不代表BlockBooster的立场。本文无意提供:(i) 投资建议或投资推荐;(ii) 购买、出售或持有数字资产的要约或招揽;或 (iii) 财务、会计、法律或税务建议。持有数字资产,包括稳定币和NFT,风险极高,价格波动较大,甚至可能变得一文不值。您应根据自身的财务状况,仔细考虑交易或持有数字资产是否适合您。如有具体情况方面的问题,请咨询您的法律、税务或投资顾问。本文中提供的信息(包括市场数据和统计信息,若有)仅供一般参考。在编写这些数据和图表时已尽合理注意,但对其中所表达的任何事实性错误或遗漏概不负责。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





