This report is written by Tiger Research. Most people use AI every day without ever thinking about where the data is flowing. The question raised by Nesa is: what happens when you start to face this issue?
Key Points
- AI has become part of daily life, but users often overlook how data is transmitted through central servers
- Even the acting director of the US CISA inadvertently leaked sensitive documents to ChatGPT
- Nesa reconstructed this process through pre-transfer data transformation (EE) and cross-node splitting (HSS-EE), ensuring that no single party can view the original data
- Academic certification (COLM 2025) and practical deployment in enterprises (Procter & Gamble) have given Nesa a first-mover advantage
- The critical question remains whether a broader market will choose decentralized privacy AI over conventional centralized APIs
1. Is Your Data Safe?

Source: CISA
In January 2026, Madhu Gottumukkala, the acting director of the US Cybersecurity and Infrastructure Security Agency (CISA), uploaded sensitive government documents to ChatGPT, simply to summarize and organize contract-related materials.
This leak was neither detected by ChatGPT nor reported to the government by OpenAI. Instead, it was captured by the agency's own internal security systems, prompting an investigation for violating security protocols.
Even the US's top cybersecurity officials are using AI daily, and even inadvertently uploading confidential materials.
We all know that most AI services store user inputs in encrypted form on central servers. But this encryption is inherently reversible. In cases of legitimate authorization or emergencies, the data can be decrypted and disclosed, while users remain completely unaware of everything happening behind the scenes.
2. Privacy AI for Everyday Use: Nesa
AI has become part of everyday life—summarizing articles, writing code, drafting emails. What is truly concerning is that, as the aforementioned case demonstrates, even confidential documents and personal data are handed over to AI with little risk awareness.
The core issue is that all this data has to go through the service provider's central server. Even if encrypted, the decryption keys are held by the service provider. On what basis can users trust this arrangement?
User input data can be exposed to third parties through various channels: model training, security reviews, legal requests. In the enterprise version, organizational admins can access chat records; in the personal version, data may also be handed over under legitimate authorization.

Since AI is deeply embedded in everyday life, it is time to seriously examine privacy issues.
Nesa is a project designed to fundamentally change this structure. It builds a decentralized infrastructure that enables AI reasoning without having to trust data to a central server. User inputs are processed in an encrypted state, and no single node can view the original data.
3. How Nesa Solves the Problem
Imagine a hospital using Nesa. Doctors want AI to analyze patients' MRI scans to detect tumors. In existing AI services, the images are sent directly to OpenAI or Google's servers.
When using Nesa, the images undergo a mathematical transformation before leaving the doctor's computer.
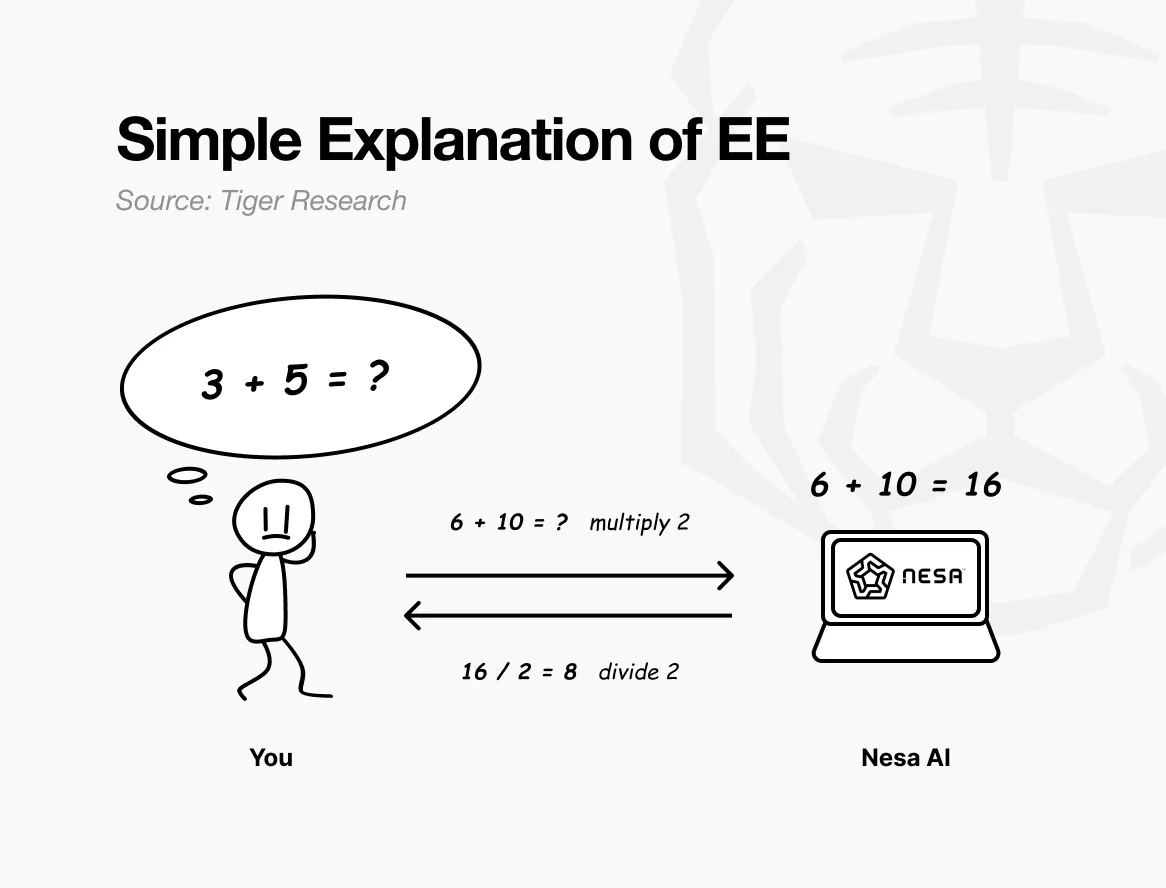
To put it simply: suppose the original question is “3 + 5 = ?” If sent directly, the recipient would clearly know what you are calculating.
However, if before sending, you multiply each number by 2, the recipient would see “6 + 10 = ?” and return 16. You then divide by 2 to get 8—exactly the same as the answer to the original question. The recipient performed the calculation but never knew your original numbers were 3 and 5.
This is precisely what Nesa's equivariant encryption (EE) achieves. Data undergoes mathematical transformation before transmission, and the AI model computes based on the transformed data.
The user then applies the inverse transformation, and the result matches perfectly with what would have been obtained using the original data. Mathematically, this property is known as equivariance: whether the transformation is done first or the calculation is done first, the final result remains the same.
In practice, the transformation is far more complex than simple multiplication—it is specifically tailored to align with the internal computation structure of the AI model. Because the transformation perfectly aligns with the model's processing flow, accuracy is not compromised.
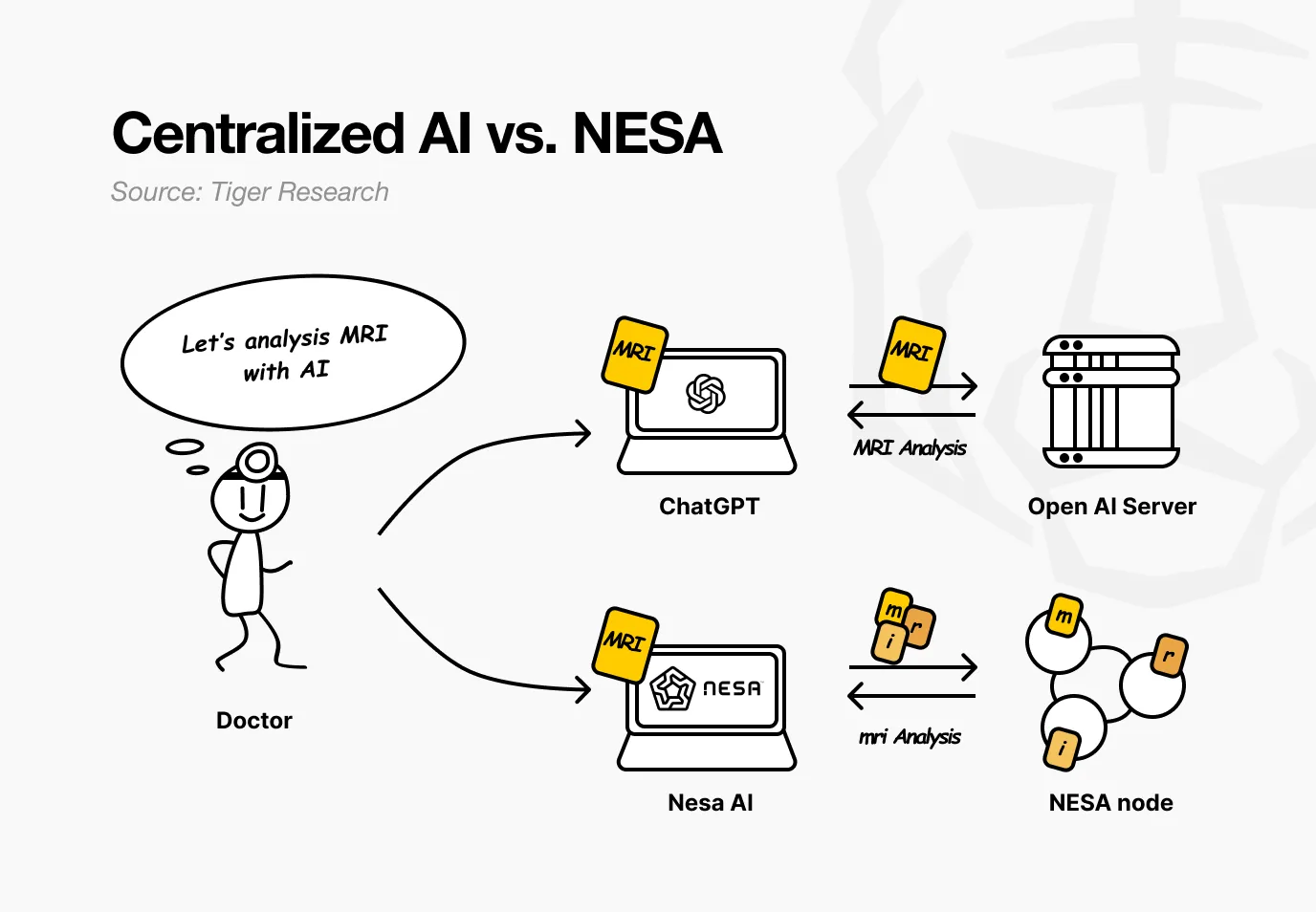
Back to the hospital scenario. For the doctor, the entire process changes in no way—uploading images, receiving results, everything remains the same. What changes is that no intermediary node can see the patient's original MRI.
Nesa takes it a step further. While EE alone prevents nodes from viewing original data, the transformed data still fully exists on a single server.
HSS-EE (Homomorphic Secret Sharing on Encrypted Embedding) further splits the transformed data.
Continuing with the earlier analogy. EE can be thought of as applying multiplication rules before sending the test paper; HSS-EE is like tearing the transformed test paper in half—sending the first part to node A and the second part to node B.
Each node can only answer its segment and cannot see the complete problem. Only when the two parts' answers are combined can the complete result be obtained—and only the original sender can perform this merging operation.
In brief: EE transforms data so that the original content is not visible; HSS-EE further splits the transformed data so that it never appears in its entirety anywhere. Privacy protection achieves double reinforcement.
4. Will Privacy Protection Slow Down Performance?
Stronger privacy often means slower performance—this has been a long-standing principle in the field of cryptography. The most well-known fully homomorphic encryption (FHE) is 10,000 to 1,000,000 times slower than standard computation, making it fundamentally unsuitable for real-time AI services.
Nesa's equivariant encryption (EE) takes a different path. Returning to the mathematical analogy: multiplying by 2 before sending and dividing by 2 after receiving involves negligible cost.
Different from FHE, which transforms the entire problem into a completely different mathematical system, EE simply adds a lightweight transformation layer on top of existing computation.
Performance benchmark data:
- EE: Less than 9% increase in latency on LLaMA-8B, with accuracy matching the original model, exceeding 99.99%
- HSS-EE: 700 to 850 milliseconds per inference on LLaMA-2 7B
Additionally, MetaInf, the meta-learning scheduler, further optimizes overall network efficiency. It evaluates model size, GPU specifications, and input features to automatically select the fastest inference method.
MetaInf achieves an 89.8% selection accuracy, being 1.55 times faster than traditional ML selectors. This achievement has been published at the COLM 2025 main conference and recognized in the academic community.
The above data comes from controlled testing environments. But more importantly, Nesa's inference infrastructure has been deployed and running in practical enterprise environments, validating its production-level performance.
5. Who is Using It? How is It Used?

There are three ways to access Nesa.
The first is the Playground. Users can directly select and test models on the webpage without any development background. You can actually experience the complete process of inputting data and viewing the outputs of various models.
This is the quickest way to understand how decentralized AI reasoning works in practice.
The second is the Pro subscription. For $8 a month, it includes unlimited access, 1,000 fast inference credits per month, customizable model pricing control, and model feature page displays.
This tier is designed for individual developers or small teams looking to deploy and monetize their models.
The third is the Enterprise version. This is not a publicly priced plan but a customized contract. It includes SSO/SAML support, optional data storage areas, audit logs, fine-grained access control, and annual contract billing.
The starting price is $20 per user per month, but actual terms must be negotiated based on scale. It is tailored for organizations integrating Nesa into internal AI processes, providing API access and organizational-level management features through independent agreements.
In summary: Playground is for exploration and experience, Pro is suitable for individual or small team development, and Enterprise aims at organization-level deployment.
6. Why Are Tokens Necessary?
Decentralized networks have no central manager. The entities running servers and validating results are distributed around the world. This naturally raises the question: why would anyone want to keep their GPU running continuously to handle AI reasoning for others?
The answer is economic incentives. In the Nesa network, this incentive is the $NES token.
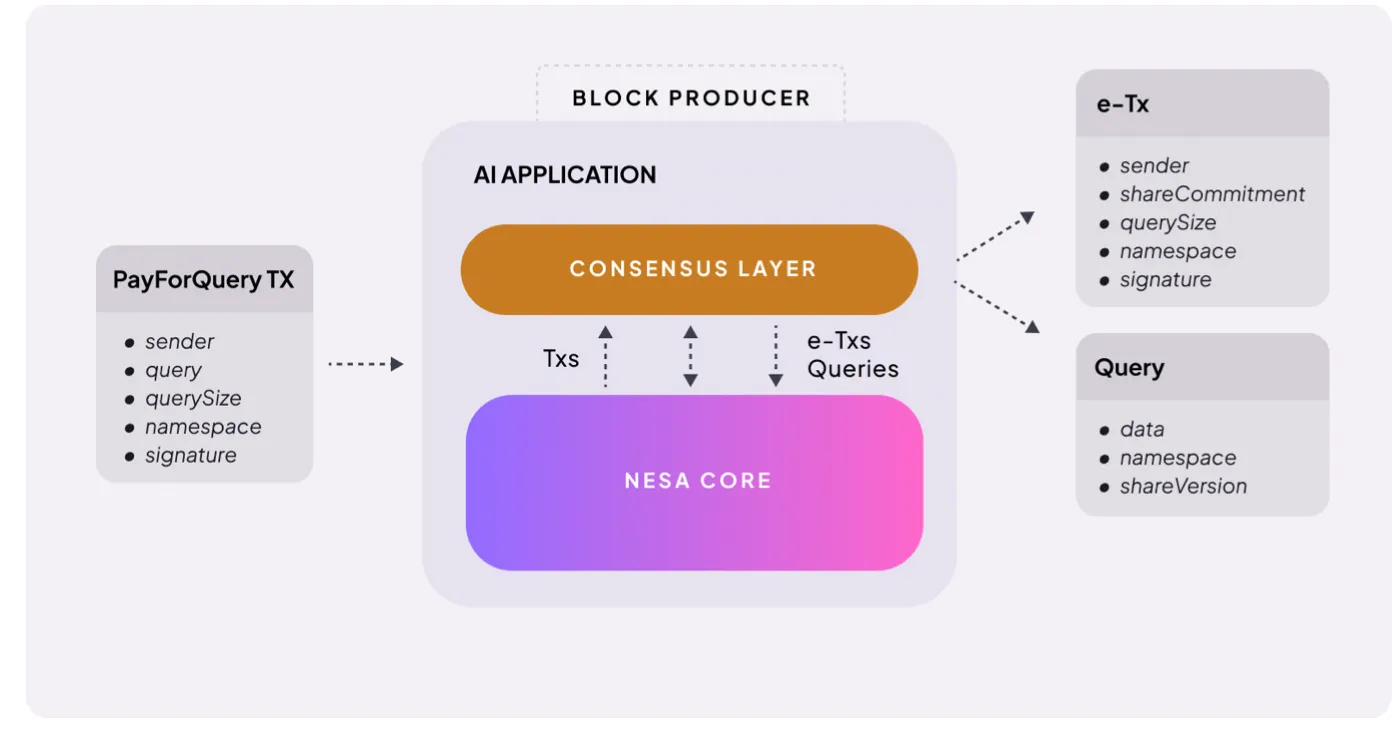
Source: Nesa
The mechanism is very straightforward. When users initiate an AI reasoning request, they need to pay a fee. Nesa refers to this as PayForQuery, consisting of a fixed fee for each transaction plus a variable fee proportional to the amount of data.
The higher the fee, the higher the processing priority—this is akin to gas fees on blockchains.
The recipients of these fees are the miners. To participate in the network, miners must stake a certain amount of $NES—prior to being assigned tasks, they must put their tokens at risk.
If a miner returns an incorrect result or fails to respond, penalties are deducted from the staked amount; if they process accurately and promptly, they receive higher rewards.
$NES also serves as a governance tool. Token holders can submit proposals and vote on core network parameters like fee structures and reward ratios.
In summary, $NES serves three roles: as a payment method for inference requests, as collateral and rewards for miners, and as proof for participation in network governance. Without tokens, nodes will not run; without nodes, privacy AI is not feasible.
It is worth noting that the operation of the token economy relies on certain prerequisites.
Inference demand must be sufficiently robust for miner rewards to be meaningful; when rewards are meaningful, miners will stay; sufficient miners are needed to maintain network quality.
This is a virtuous cycle driven by demand, which maintains supply. But initiating this cycle is often the most challenging phase.
Enterprise clients such as Procter & Gamble are already using the network in production environments, which is a positive signal. However, as the network expands, it remains to be seen whether the balance between token value and mining rewards can be maintained.
7. The Necessity of Privacy AI
The problem Nesa attempts to address is clear: to change the structural dilemma of user data exposure to third parties when using AI.
The technical foundation is solid and reliable. Its core encryption technologies—equivariant encryption (EE) and HSS-EE—are derived from academic research. The inference optimization scheduler MetaInf has been published at the COLM 2025 main conference.
This is not just a simple citation of papers. The research team directly designed the protocol and implemented it within the network.
In decentralized AI projects, there are very few that can validate their own cryptographic primitives at an academic level and deploy them in functioning infrastructures. Large enterprises like Procter & Gamble are already running inference tasks on this infrastructure—an encouraging signal for early-stage projects.
That said, the limitations are also evident:
- Market Scope: Preference for institutional clients; regular users are unlikely to pay for privacy at the moment
- Product Experience: Playground resembles a Web3/investment tool interface rather than an everyday AI application
- Scalability Validation: Controlled benchmarking doesn't equate to production environments with thousands of concurrent nodes
- Market Timing: The demand for privacy AI is genuine, but the demand for decentralized privacy AI has yet to be validated; enterprises still tend to prefer centralized APIs
Most companies still prefer using centralized APIs, and the threshold for adopting blockchain-based infrastructures remains high.
We are in an era where even the director of US cybersecurity might upload classified documents to AI. The demand for privacy AI exists and will only continue to grow.
Nesa has academically validated technology and practical running infrastructure to meet this demand. Despite the limitations, its starting point is already ahead of other projects.
When the privacy AI market truly opens up, Nesa will undoubtedly be one of the first names mentioned.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






