法国人工智能初创公司Mistral,常常被视为在美国巨头和中国新兴企业主导的领域中的欧洲黑马,刚刚迎头赶上:它在周二发布了迄今为止最雄心勃勃的版本,给开源竞争对手带来了压力。(在这种情况下,甚至没有资金。)
这个4个模型的系列涵盖了口袋大小的助手到6750亿参数的最先进系统,所有模型都在宽松的Apache 2.0开源许可证下发布。这些模型可以公开下载—任何拥有适当硬件的人都可以在本地运行、修改、微调或在其上构建应用程序。
旗舰产品Mistral Large 3采用稀疏的专家混合架构,每个token仅激活6750亿总参数中的410亿。这个工程选择使其在前沿重量级中表现出色,同时在接近400亿参数的计算配置下进行推理。
Mistral Large 3是在3000个NVIDIA H200 GPU上从零开始训练的,并在LMArena排行榜上首次亮相时位列开源非推理模型的第二名。
与DeepSeek的基准竞争讲述了一个复杂的故事。根据Mistral的基准测试,其最佳模型在多个指标上超过DeepSeek V3.1,但在LMArena上落后于更新的V3.2几个点。
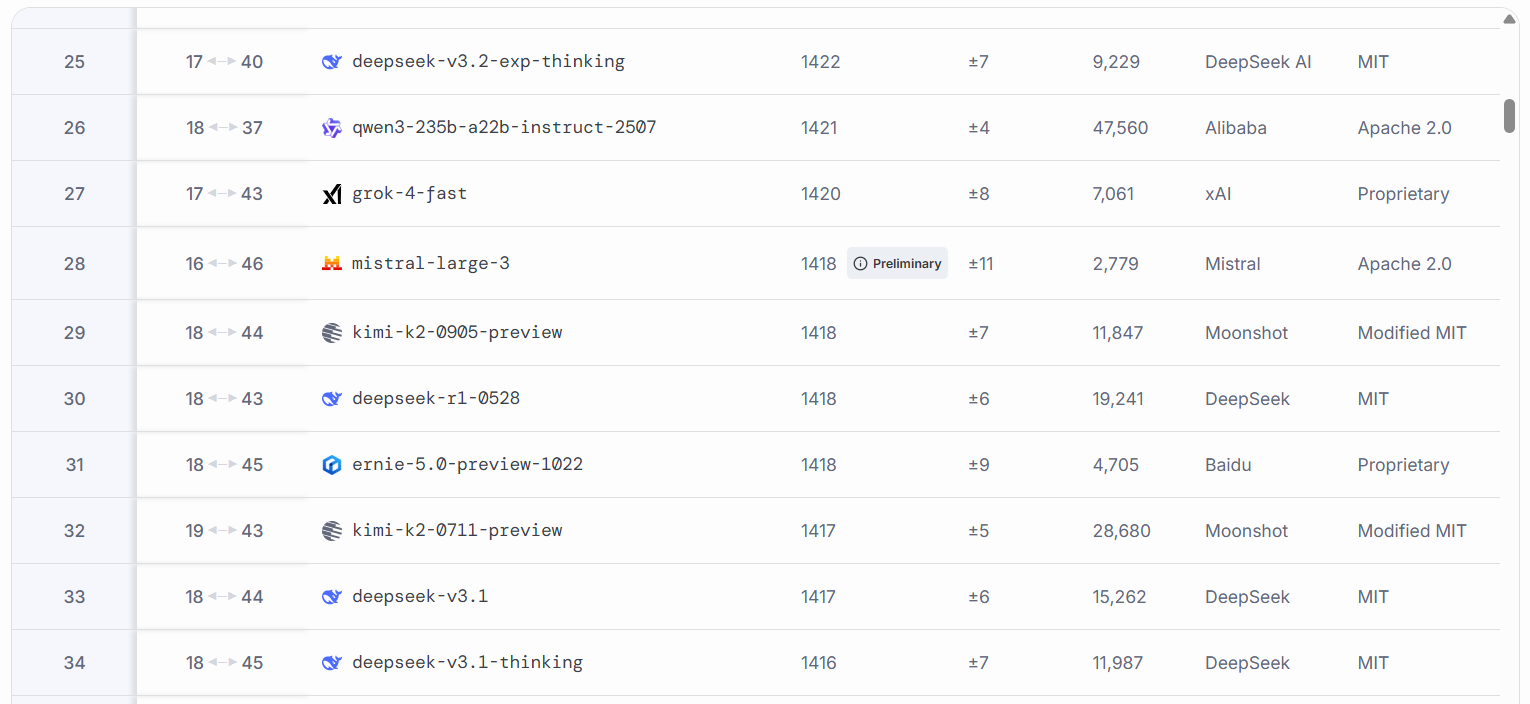
在一般知识和专家推理任务中,Mistral系列表现不俗。DeepSeek在原始编码速度和数学逻辑方面略有优势。但这也是可以预期的:此次发布不包括推理模型,因此这些模型的架构中没有嵌入思维链。
较小的“Ministral”模型对开发者来说更具趣味性。三种尺寸—3B、8B和14B参数—每种都有基础和指令变体。所有模型都原生支持视觉输入。3B模型引起了AI研究者Simon Willison的关注,他指出它可以通过WebGPU完全在浏览器中运行。
如果你想尝试这个,可以通过这个Hugginface空间在本地加载并使用你的网络摄像头作为输入进行交互。
一个大约3GB文件的合格视觉能力AI为需要效率的开发者或甚至爱好者打开了可能性:无人机、机器人、离线运行的笔记本电脑、车辆中的嵌入式系统等。
早期测试显示整个系列存在个性分裂。在一次快速测试中,我们发现Mistral 3 Large在对话流畅性方面表现良好。有时它的格式风格类似于GPT-5(类似的语言风格和对表情符号的偏好),但节奏更自然。
Mistral 3 Large在审查方面也相对宽松,使其在选择ChatGPT、Claude或Gemini时成为快速角色扮演的更好选择。
对于自然语言任务、创意写作和角色扮演,用户发现14B指令变体表现相当不错,但并不特别出色。Reddit上的r/LocalLLaMA线程指出了重复问题和偶尔对训练数据中继承的固定短语的过度依赖,但该模型生成长篇内容的能力是一个不错的优点,尤其是考虑到其大小。
运行本地推理的开发者报告称,3B和8B模型在创意任务上有时会循环或产生公式化的输出。
也就是说,3B模型非常小,可以在智能手机等弱硬件上运行,并可以针对特定目的进行训练/微调。目前在这一特定领域唯一的竞争选项是谷歌的Gemma 3的最小版本。
企业采用已经在推进中。汇丰银行周一宣布与Mistral达成多年合作伙伴关系,将在其运营中部署生成性AI。该银行将在自己的基础设施上运行自托管模型,将内部技术能力与Mistral的专业知识相结合。对于在GDPR下处理敏感客户数据的金融机构来说,拥有开放权重的总部位于欧盟的AI供应商的吸引力不言而喻。
Mistral与NVIDIA合作开发了一个NVFP4压缩检查点,使Large 3能够在其八张最佳显卡的单个节点上运行。NVIDIA声称Ministral 3B在RTX 5090上每秒大约处理385个token,在Jetson Thor上用于机器人应用时每秒超过50个token。这意味着该模型在推理时非常高效且快速,能够更快地给出答案而不牺牲质量。
根据公告,优化推理的Large 3版本即将推出。在此之前,DeepSeek R1和其他中国模型如GLM或Qwen Thinking在明确推理任务上仍保持一定的差异化。但对于希望获得前沿能力、开放权重、在欧洲语言中具备多语言优势,并且不受中国或美国国家安全法约束的企业来说,选择从零扩展到了一个。
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







