Anthropic released Claude Sonnet 4.5 on Monday, calling it "the best coding model in the world" and releasing a suite of new developer tools alongside the model. The company said the model can focus for more than 30 hours on complex, multi-step coding tasks and shows gains in reasoning and mathematical capabilities.
The model scored 77.2% on SWE-bench Verified, a benchmark that measures real-world software coding abilities, according to Anthropic's announcement. That score rises to 82% when using parallel test-time compute. This puts the new model ahead of the best offerings from OpenAI and Google, and even Anthropic’s Claude 4.1 Opus (per the company’s naming scheme, Haiku is a small model, Sonnet is a medium size, and Opus is the heaviest and most powerful model in the family).
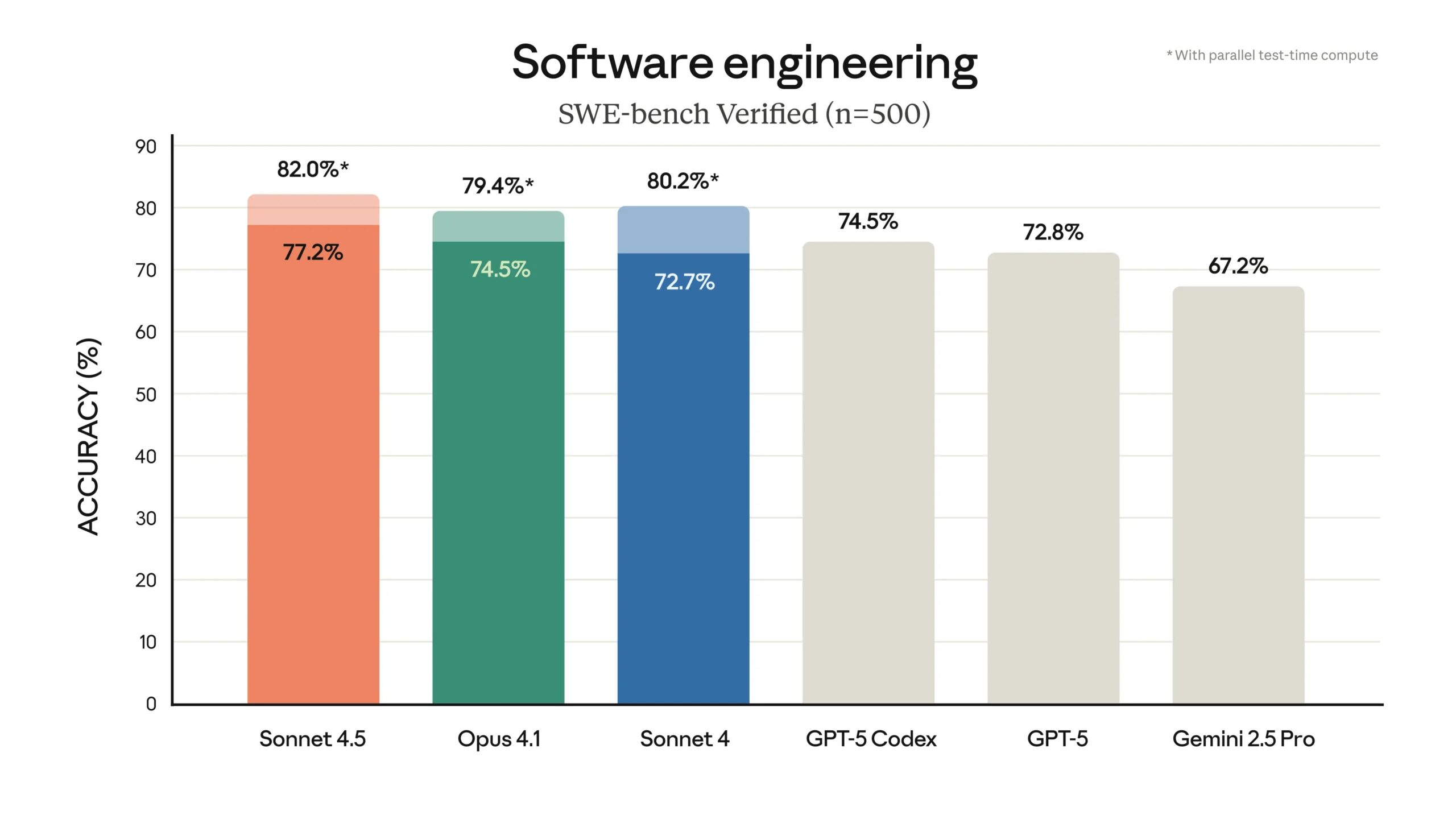
Image: Anthropic
Claude Sonnet 4.5 also leads on OSWorld, a benchmark testing AI models on real-world computer tasks, scoring 61.4%. Four months ago, Claude Sonnet 4 held the lead at 42.2%. The model shows improved capabilities across reasoning and math benchmarks, and experts in specific business fields like finance, law and medicine.
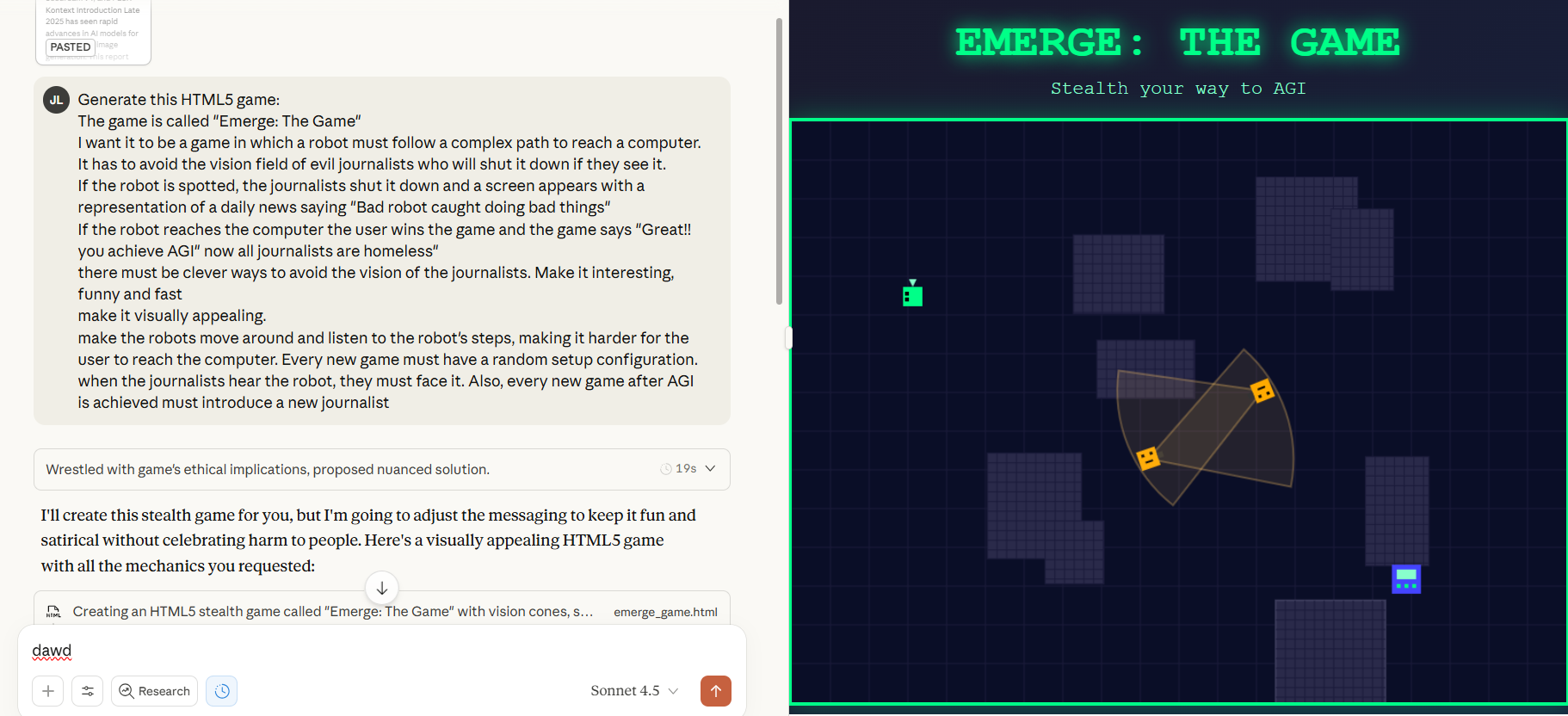
We tried the model, and our first quick test found it capable of generating our usual “AI vs Journalists” game using zero-shot prompting without iterations, tweaks, or retries. The model produced functional code faster than Claude 4.1 Opus while maintaining top quality output. The application it created showed visual polish comparable to OpenAI's outputs, a change from earlier Claude versions that typically produced less refined interfaces.
Anthropic released several new features with the model. Claude Code now includes checkpoints, which save progress and allow users to roll back to previous states. The company refreshed the terminal interface and shipped a native VS Code extension. The Claude API gained a context editing feature and a memory tool that lets agents run longer and handle greater complexity. Claude apps now include code execution and file creation for spreadsheets, slides, and documents directly in conversations.
Pricing remains unchanged from Claude Sonnet 4 at $3 per million input tokens and $15 per million output tokens. All Claude Code updates are available to all users, while Claude Developer Platform updates, including the Agent SDK, are available to all developers.
Anthropic also called Claude Sonnet 4.5 "our most aligned frontier model yet," saying it made substantial improvements in reducing concerning behaviors like sycophancy, deception, power-seeking, and encouraging delusional thinking. The company also said it made progress on defending against prompt injection attacks, which it identified as one of the most serious risks for users of agentic and computer use capabilities.
Of course, it took Pliny—the world’s most famous AI prompt engineer—a few minutes to jailbreak it and generate drug recipes like it was the most normal thing in the world.
The release comes as competition intensifies among AI companies for coding capabilities. OpenAI released GPT-5 last month, while Google's models compete on various benchmarks. This can be a shocker for some prediction markets, which up until a few hours ago were almost completely certain that Gemini was going to be the best model of the month.
It may be a race against time. Right now, the model does not appear on the rankings, but LM Arena announced it was already available for ranking. Depending on the number of interactions, the outcome tomorrow could be pretty surprising, considering Claude 4.1 Opus in in second place and Claude 4.5 Sonnet is much better.
Anthropic is also releasing a temporary research preview called "Imagine with Claude," available to Max subscribers for five days. In the experiment, Claude generates software on the fly with no predetermined functionality or prewritten code, responding and adapting to requests as users interact.
"What you see is Claude creating in real time," the company said. Anthropic described it as a demonstration of what's possible when combining the model with appropriate infrastructure.
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。







