本文将解析一个关键技术突破:通过高性能 GPU 与零知识证明的结合,我们正在让以太坊的运行效率提升数百乃至上千倍。这不仅解决了区块链长期存在的性能瓶颈,也为未来的 Web3 基础设施提供了可行的技术路径。
如果你曾好奇:为什么以太坊运行缓慢、交易成本居高不下?又或者你正关注下一代区块链技术的关键驱动因素?那么,本文将为你提供清晰的答案。
问题本质:区块链为何像堵车的高速公路?
可以将以太坊想象为一条高速公路。如今,所有用户和应用都在争抢有限的车道资源,导致网络拥堵、交易处理缓慢、Gas 费居高不下。
传统的解决思路无非两种:
修更多的车道 —— 也就是构建 Layer 2 网络(例如 Rollups)
让车辆更小 —— 也就是对交易数据进行压缩
但如果有一种方式,可以“瞬移”车辆,而非继续在车道中挤兑呢?这正是零知识证明(Zero-Knowledge Proofs, ZKPs)带来的范式革新。它的核心思路是:无需传输所有交易数据本身,仅通过生成一个数学证明,即可验证交易的真实性。换句话说,我们不再需要让每辆车都驶过高速公路,而是可以直接验证“这些车确实到达了终点”。这不仅减少了数据传输负担,更让“高吞吐 + 强安全 + 去信任验证”三者得以兼容。
The Verge:以太坊的下一步演进
以太坊当前正在推进一个宏大的技术蓝图——The Verge,你可以把它理解为以太坊的“瘦身计划”。目标是:让运行以太坊节点的门槛大幅降低,就像在手机上运行一个 App 那样简单。未来,每个人都能轻松加入以太坊网络,而不必依赖一台高性能游戏电脑。
但这项计划背后有一个关键技术挑战:它需要在极短时间内完成数百万次复杂的数学运算。
这正是 Polyhedra 团队所专注的突破方向 —— 如何利用 GPU 加速大规模 ZK 计算,在保证验证安全性的同时大幅提升执行效率。
技术挑战:这组数据将颠覆你的认知
为了理解我们正在应对的复杂度,以下是以太坊当前链上操作的真实规模:
共识验证(Consensus Verification):
每个区块包含约 9,000 万次 SHA2-256 哈希计算,以及 2,048 个 BLS 数字签名验证状态转换证明(State Transition Proofs):
每个区块约需执行 50 万次 Keccak 哈希操作当前瓶颈:
基于 CPU 的零知识证明器(Prover)目前每秒仅能处理约 200 万次 Poseidon 哈希计算
真正的挑战在于——我们需要用零知识证明技术来完成上述所有运算,这无疑大幅叠加了计算复杂度。
突破点:GPU 的算力革命
众所周知,GPU 是游戏玩家和 AI 工程师的心头好。但实际上,这些图形处理单元在处理零知识证明所需的大规模并行数学计算时,展现出远超 CPU 的能力。
在 Polyhedra,我们对 ZK 证明系统进行了 GPU 原生优化,并取得了震撼性的突破性性能指标:
性能跃迁,远超预期
基础数学操作(Mersenne31 领域)提速 362 倍
复杂加密运算(BN254 椭圆曲线)提速高达 2826 倍
一项原本耗时 21 分钟 的零知识计算,现已压缩至 仅需 450 毫秒
换句话说,这相当于你每天早高峰的通勤时间从 20 分钟骤减为不到半秒。这不是渐进式优化,而是一种范式级别的计算跃迁。
为什么这项突破与你息息相关?
更低的交易成本:证明生成速度更快,意味着整体计算成本显著下降,进而带来更低的 Gas 费用。用户和网络双赢。
更强的安全性保障:还记得我们提到过以太坊年均超过 4000 万美元 的安全预算吗?通过我们的技术,轻节点也能轻松验证整条以太坊共识链,享受主网级安全保障,无需庞大资源开销。
更普及的节点运行,手机也能跑以太坊:我们在性能和效率上的持续优化,正让在普通设备上运行以太坊节点成为可能。未来,验证区块链数据或许只需一部手机即可完成。
技术核心:我们是如何做到的
1. GPU 原生设计:CUDA 优化的 Sumcheck 协议
我们基于 CUDA 构建的 Sumcheck 实现,充分发挥了 GPU 的并行计算优势:
针对数域运算(加法、乘法、幂运算)设计定制化 CUDA 内核
利用合并内存访问模式,最大化 GPU 带宽利用率(RTX 4090 实测带宽高达 1008 GB/s)
使用 warp 级原语,实现高效的归约操作(Reduction)
这一层级的深度定制让 Sumcheck 协议不再受限于 CPU 的串行瓶颈。
2. 内存为王:带宽瓶颈优化传统观点认为 ZK Prover 计算瓶颈在于算力,但我们的实证表明 —— Sumcheck 是典型的内存带宽瓶颈问题:
内存吞吐分析:带宽使用率达到理论上限的 95%+
数据结构优化:采用 Structure-of-Arrays(SoA) 替代传统 Array-of-Structures(AoS) 结构
SM 单元利用率提升:通过优化线程块配置,实现最佳硬件占用率
通过解决内存吞吐问题,我们将 ZK 计算变成了真正的高效流式任务。
3. 针对不同数域的定制化优化策略
不同的密码学字段具有不同的运算特性,我们为每个主流场量身定制了优化路径:
Mersenne31 (M31):31 位整数优化,高效模运算结构
M31ext3:扩展字段支持,兼顾多项式扩张与低开销
BN254:基于 Montgomery 算法的定制乘法器,专为 254-bit 大整数场设计
这种高度针对性的底层优化让我们的 ZK Prover 既通用又极致高效。
性能数据拆解:优化发生的地方
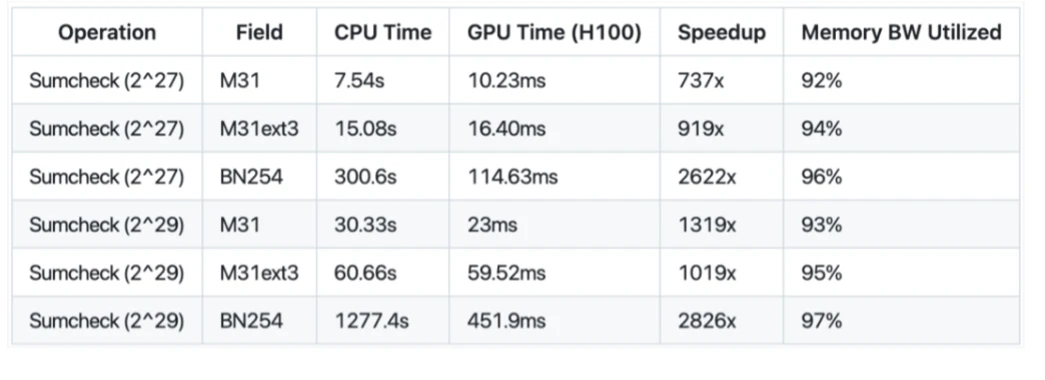
我们并非只做了“快很多”,而是将 ZK 性能推向了前所未有的高度。以下是实测性能数据:
技术架构揭秘:引擎盖下的真相
GKR 协议栈:加速的核心
我们的加速优化聚焦于 GKR(Goldwasser-Kalai-Rothblum)协议,具体包括:
线性 GKR 层:用于处理加法与乘法门
Sumcheck 协议:性能瓶颈所在,占据 CPU 总计算时间的近 50%
多项式评估阶段:在 GPU 上将计算时间从 8.4 秒 降至 9.5 毫秒
GPU 内核设计详解
第一阶段:多项式评估
在 2^n 个点上并行计算
使用 共享内存缓存系数,提高访问速度
借助 warp shuffle 实现高效归约操作
第二阶段:挑战生成
在 GPU 内部执行 Fiat-Shamir 哈希操作,避免 CPU-GPU 频繁切换
降低 CPU 与 GPU 之间的通信延迟
内存传输优化:打通数据流的“最后一公里”
我们在 CPU-GPU 交互方面也做了系统性优化,以确保带宽不成为瓶颈:
PCIe 数据吞吐优化:处理 2^{27} 个元素仅需 737 毫秒
Pinned Memory:支持“零拷贝”数据传输,减少复制成本
异步操作调度:计算与通信并行进行,最大化资源利用率
实话实说:挑战依旧存在
我们始终坚持透明——GPU 加速并非万能解法,在实际推进中,我们也遭遇了不少技术瓶颈:
1. 内存带宽已触顶
即便是 H100 拥有高达 3.35 TB/s 的带宽,在高负载下也会成为性能瓶颈
对比来看:较大的椭圆曲线域(如 BN254)比小域(如 M31)更快触顶
2. GPU 显存容量受限
RTX 4090 在处理 2^{29} 个元素时内存耗尽
实际部署时需要精细的内存调度策略,避免溢出风险
3. 域大小与性能之间的权衡

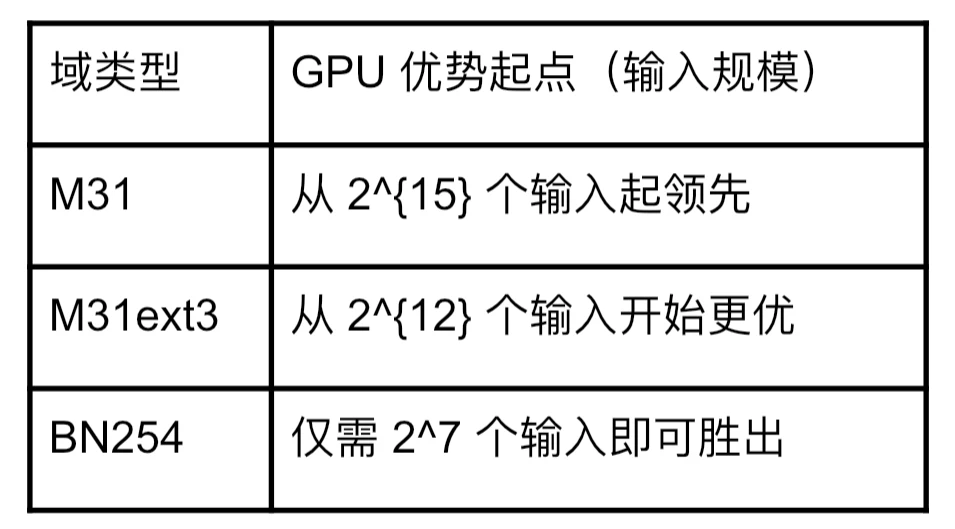
4. “GPU 优势点”对比:从何时开始超过 CPU?
跨平台性能实测
我们在不同等级的 GPU 上进行了基准测试,涵盖消费级和数据中心级硬件:
消费级 GPU
RTX 3090:内存带宽 936 GB/s,性能提升最高可达 951 倍
RTX 4090:内存带宽 1008 GB/s,性能提升最高达 1565 倍
数据中心 GPU
NVIDIA H100:带宽高达 3.35 TB/s,性能提升 最高可达 2826 倍
结论清晰明确:内存带宽是零知识证明加速的关键变量。
展望未来:我们的路线图
我们远未止步,接下来将持续攻坚以下目标:
更极致的加速:针对特定操作,目标是实现 10,000 倍 的速度提升
更广泛的硬件兼容:从高性能游戏显卡到数据中心级加速卡全覆盖
原生集成以太坊:我们正在与以太坊客户端开发团队合作,将我们的 GPU ZK 证明堆栈直接集成进 L1 层
加入这场变革浪潮!
这不仅仅是速度的提升,更是一次对区块链可达性的彻底重塑。无论你是谁,都能找到参与的方式:
核心观点回顾
我们正处在一个令人振奋的技术转折点。零知识证明与 GPU 加速的结合,不只是性能的边际提升,而是一场范式的变革。
我们正在重新定义以太坊的速度、成本与可用性边界。
关键技术成果一览:
面向生产环境的 ZK 证明实现 超 1000 倍加速
GPU 内存带宽利用率超过 95%
开源实现,随时可集成
Web3 的未来不仅是去中心化的,更是极速可达的,而且它比你想象的来得更快。
你对这些进展最感兴趣的是哪一点?欢迎在评论区留言,或在 Twitter 上与我互动,我们非常乐意深入交流这些技术细节!
未来属于速度,也属于你。下次见,持续构建,不止于快!
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。






