Anthropic finally released its long-awaited Claude 4 AI model family on Thursday, which had been put on hold for months. The San Francisco-based company, a major player in the fiercely competitive AI industry and valued at more than $61 billion, claimed that its new models achieved top benchmarks for coding performance and autonomous task execution.
The models released today replace the most powerful two of the three models in the Claude family: Opus, a state-of-the-art model that excels at understanding demanding tasks, and Sonnet, a medium-sized model good for everyday tasks. Haiku, Claude’s smallest and most efficient model, was not touched and remains on v3.5.
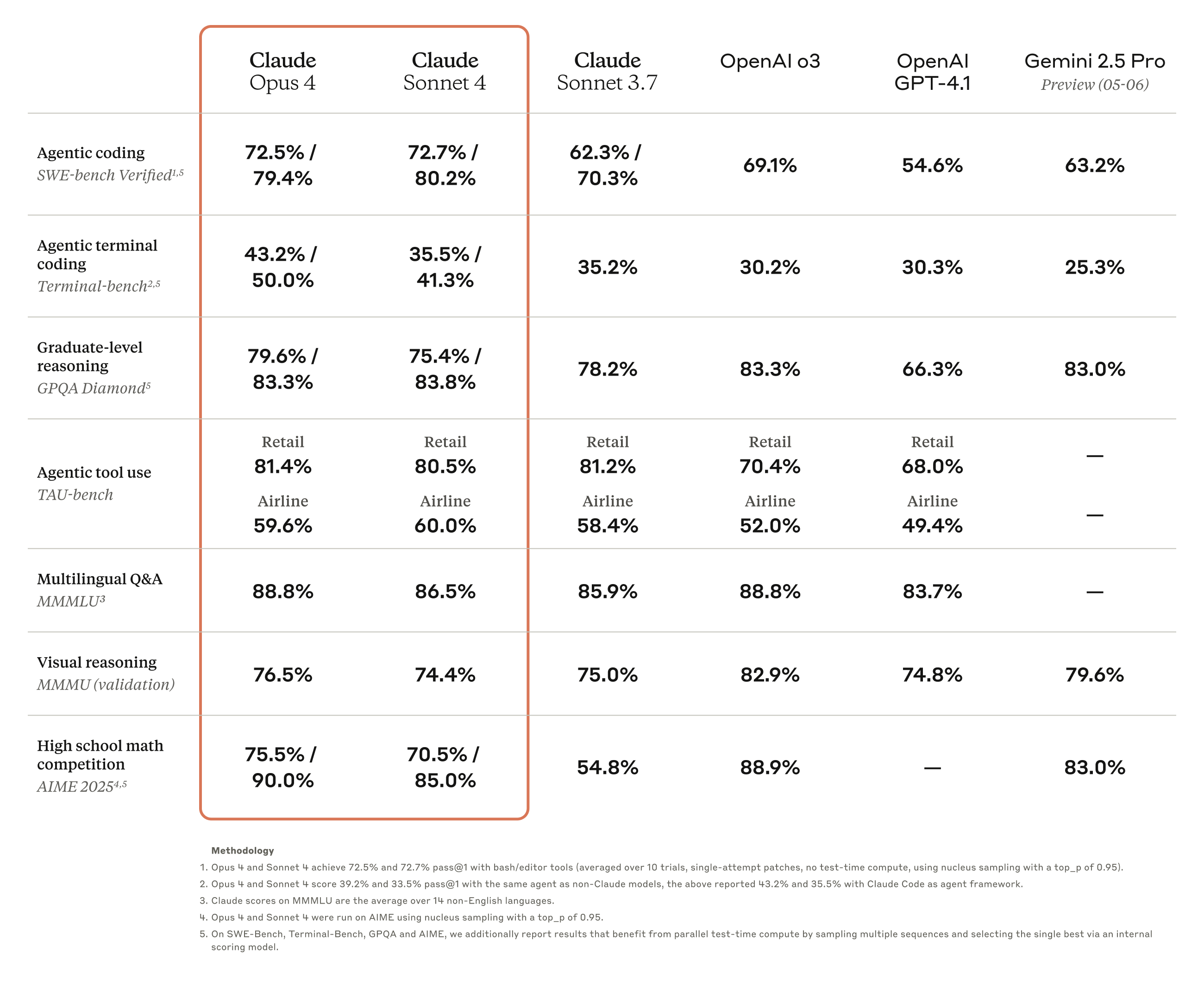
Claude Opus 4 achieved a 72.5% score on SWE-bench Verified, significantly outperforming competitors on the coding benchmark. OpenAI's GPT-4.1 managed only 54.6% on the same test, while Google's Gemini 2.5 Pro reached 63.2%. The performance gap extended to reasoning tasks, where Opus 4 scored 74.9% on GPQA Diamond (basically a general knowledge benchmark) compared to GPT-4.1's 66.3%
The model also beat its competition in other benchmarks that measure proficiency in agentic tasks, math, and multilingual queries.
Anthropic had developers in mind when polishing Opus 4, paying special attention to sustained autonomous work sessions.
Rakuten's AI team reported that the model coded independently for nearly seven hours on a complex open-source project, representing what its General Manager, Yusuke Kaji, defined as "a huge leap in AI capabilities that left the team amazed," according to statements Anthropic shared with Decrypt. This endurance far exceeds previous AI models' typical task duration limits.
Both Claude 4 models operate as hybrid systems, offering either instant responses or extended thinking modes for complex reasoning—a concept close to what OpenAI plans to do with GPT-5m when it merges the “o” and the “GPT” families into one model.
Opus 4 supports up to 128,000 output tokens for extended analysis and integrates tool use during thinking phases, allowing it to pause reasoning to search the web or access databases before continuing. The full context window that these models handle is close to 1 million tokens.
Anthropic priced Claude Opus 4 at $15 per million input tokens and $75 per million output tokens. Claude Sonnet 4 costs $3 per million input tokens and $15 per million output tokens. The company offers up to 90% cost savings through prompt caching and 50% reductions via batch processing, though the base rates remain substantially higher than some competitors.
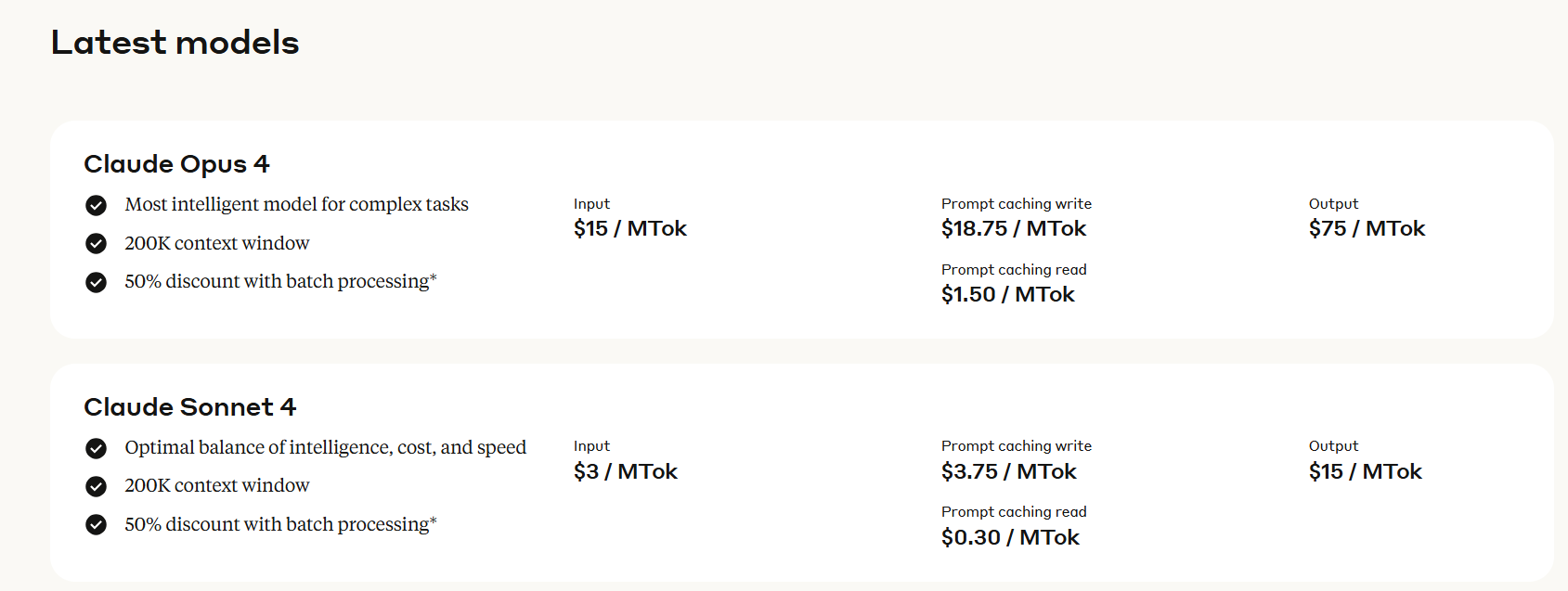
Still, this is a massive price level when compared to open-source options like DeepSeek R1, which costs less than $3 per million output tokens. The Claude 4 Haiku version—which should be a lot cheaper—has not been announced yet.
The year of AI—again
Anthropic’s release coincided with Claude Code's general availability, an agentic command-line tool that enables developers to delegate substantial engineering tasks directly from terminal interfaces. The tool can search code repositories, edit files, write tests, and commit changes to GitHub while maintaining developer oversight throughout the process.
GitHub announced that Claude Sonnet 4 would become the base model for its new coding agent in GitHub Copilot. CEO Thomas Dohmke reported up to 10% improvement over previous Sonnet versions in early internal evaluations, driven by what he called "adaptive tool use, precise instruction-following, and strong coding instincts."
This puts Anthropic in direct competition to recently announced releases by OpenAI and Google. Last week, OpenAI unveiled Codex, a cloud-based software engineering agent, and this week Google previewed Jules and its new family of Gemini models, which were also designed with extensive coding sessions in mind.
Several enterprise customers provided specific use case validation. Triple Whale CEO AJ Orbach said Opus 4 "excels for text-to-SQL use cases—beating internal benchmarks as the best model we've tried." Baris Gultekin, Snowflake's Head of AI, highlighted the model's "custom tool instructions and advanced multi-hop reasoning" for data analysis applications.
Anthropic's financial performance supported the premium positioning. The company reported $2 billion in annualized revenue during Q1 2025, more than doubling from previous periods. Customers spending over $100,000 annually increased eightfold, while the company secured a $2.5 billion five-year credit line to fund continued development.
As is usual with any Anthropic release, these models maintain the company’s safety-focused approach, with extensive testing by external experts including child safety organization Thorn. The company continues its policy of not training on user data without explicit permission, differentiating it from some competitors in regulated industries.
Both models feature 200,000-token context windows and multimodal capabilities for processing text, images, and code. They're available through Claude's web interface, the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI platform. The release includes new API capabilities like code execution tools, MCP connectors, and Files API for enhanced developer integration.
Edited by Andrew Hayward
免责声明:本文章仅代表作者个人观点,不代表本平台的立场和观点。本文章仅供信息分享,不构成对任何人的任何投资建议。用户与作者之间的任何争议,与本平台无关。如网页中刊载的文章或图片涉及侵权,请提供相关的权利证明和身份证明发送邮件到support@aicoin.com,本平台相关工作人员将会进行核查。





